はじめに
Amazon Managed Streaming for Apache Kafka(以下、Amazon MSK)のKafkaクラスターに対してIBM InfoSphere Data Replication - CDC Replication(以下、IIDR CDC)を使用してDb2のデータをKafkaに送る方法を確認します。
IIDR CDCのことはよく触っているので知っていることもありますが、IIDR CDCからAmazon MSKとAWS Glue Schema Registryに対するメッセージングの方法は知らなかったのでトライしたものとなります。
特に、IIDR CDC → Amazon MSK/AWS Glue Schema Registryを起点にイベントドリブンのアーキテクチャーを検討している方に参考になる内容だと思います。
なお、試行にあたり何度もトライ&エラーしていますが、ここでは、成功した際の設定と手順と注意点(ハマりポイント)について説明します。
前提
- Apache Kafkaのバージョン:3.5.1
- Zookeeper構成(KRaft構成ではない)
- トライした時期:2024/9/13-17
- AWS環境は個人利用のもの(自費)
- Amazon MSKクラスターはパブリックアクセス可能(構築方法は後述の「実施した概要」①参照)
- Db2のバージョン:DB2 v11.1.4.5
- IIDR CDCのバージョン
- IBM InfoSphere Data Replication (IBM DB2):11.4.0.4(ビルド master_5660)
- IBM InfoSphere Data Replication (Kafka):11.4.0.4(ビルド master_5660)
- IIDR CDCのインストールディレクトリ:/opt/ibm
実施した概要

- ① Amazon MSKのクラスターを構築する(→Amazon MSKでオンプレから接続可能なKafkaクラスターの構築方法(できるだけ普通のKafkaっぽく使えるように))
- ② AWS外からJavaプログラムを使用して以下を実施(→Amazon MSKのKafkaクラスターにJavaプログラムでProduce/Consume(String形式&Avro形式))
- シンプルな文字列形式のメッセージのProduce/Consume
- AWS Glue Schema Registryの設定
- Avro形式のメッセージのProduce/Consume
- ③ AWS外からIBM Infosphere Replication CDCを使用して以下を実施(本稿で紹介)
- JSON形式でキャプチャー対象テーブルのデータをAmazon MSKに送信
- Avro形式でキャプチャー対象テーブルのデータをAmazon MSKに送信
IIDR CDCの設定ファイルについて
IIDR CDCはKafka Clientライブラリを使用してメッセージのProduce/Consumeを行います。
Kafka producer/Kafka consumerとしての振る舞いを設定するプロパティを決められたファイル内に記述するものとなっています。
また、メッセージにヘッダーをつけてトランザクションIDを付与したり、メッセージ全体の形式を制御したりすることができるKafkaカスタム操作プロセッサー (KCOP) の設定を記述する設定ファイルがあります。
これらはIIDR CDCのターゲットとなるKafka Brokerやスキーマレジストリの接続先や認証情報を記載する重要なファイルになっています。
今回の手順で登場する設定ファイルは以下の通りです。
| ファイル名 | 配置場所 | 役割 |
|---|---|---|
| kafkaproducer.properties | CDC_Kafka_instance_directory /conf/ | Kafka producerとしての設定内容 |
| kafkaconsumer.properties | 同上 | Kafka consumerとしての設定内容 |
| kcop.properties(任意) | 同上(任意) | KCOPの設定内容 |
| user-classloader.cp | 同上 | KCOPで使用するクラスパスを定義 |
CDC_Kafka_instance_directory はインストール先およびインスタンス名により可変です。
今回は以下を使用します。
/opt/ibm/InfoSphereDataReplication/ReplicationEngineforKafka/instance/KAFKAF/conf
kafkaproducer.propertiesとkafkaconsumer.propertiesはファイル名も配置場所も固定です。
KCOPの設定ファイルはファイル名も配置場所も任意で手順の中で指定するものとなりますが、便宜的にファイル名はkcop.propertiesとし配置場所はkafkaproducer.propertiesとkafkaconsumer.propertiesと同じにします。
user-classloader.cpはIIDR CDCからAvro形式でメッセージングする際に設定が必要です。
実施手順の流れ
実施手順の基本的な流れは以下の通りです。
(1) kafkaproducer.properties/kafkaconsumer.propertiesの設定
(2) kcop.propertiesの設定
(3) サブスクリプション設定
(4) リフレッシュ(ソーステーブルのデータの一括転送)
(5) ミラーリング(変更データのキャプチャー開始)
(4)、(5)はリフレッシュ後に継続的にミラーリングがなされるように実行することができます。
本稿では、リフレッシュが行えればデータの疎通は確認できたことになるためミラーリングの実行については含んでいません。
また、IIDR CDCの導入に関する手順も含んでいません。
Amazon MSK側で事前に実施しておいたほうがいいかもしれない設定
IIDR CDCによりKafkaにメッセージを送る際、デフォルトまたは指定された名称のKafkaトピックが利用されることになります。
Kafka Brokerでは、Producerがメッセージを書き込もうとしたトピックがない場合にトピックを自動作成するかエラーとするかを制御するプロパティがあります。
今回のように、特にトピック名へのこだわりなく試行したいような場合は、トピックの自動作成を有効にしておくのが良いでしょう。
- クラスターの構成変更:auto.create.topics.enable=true
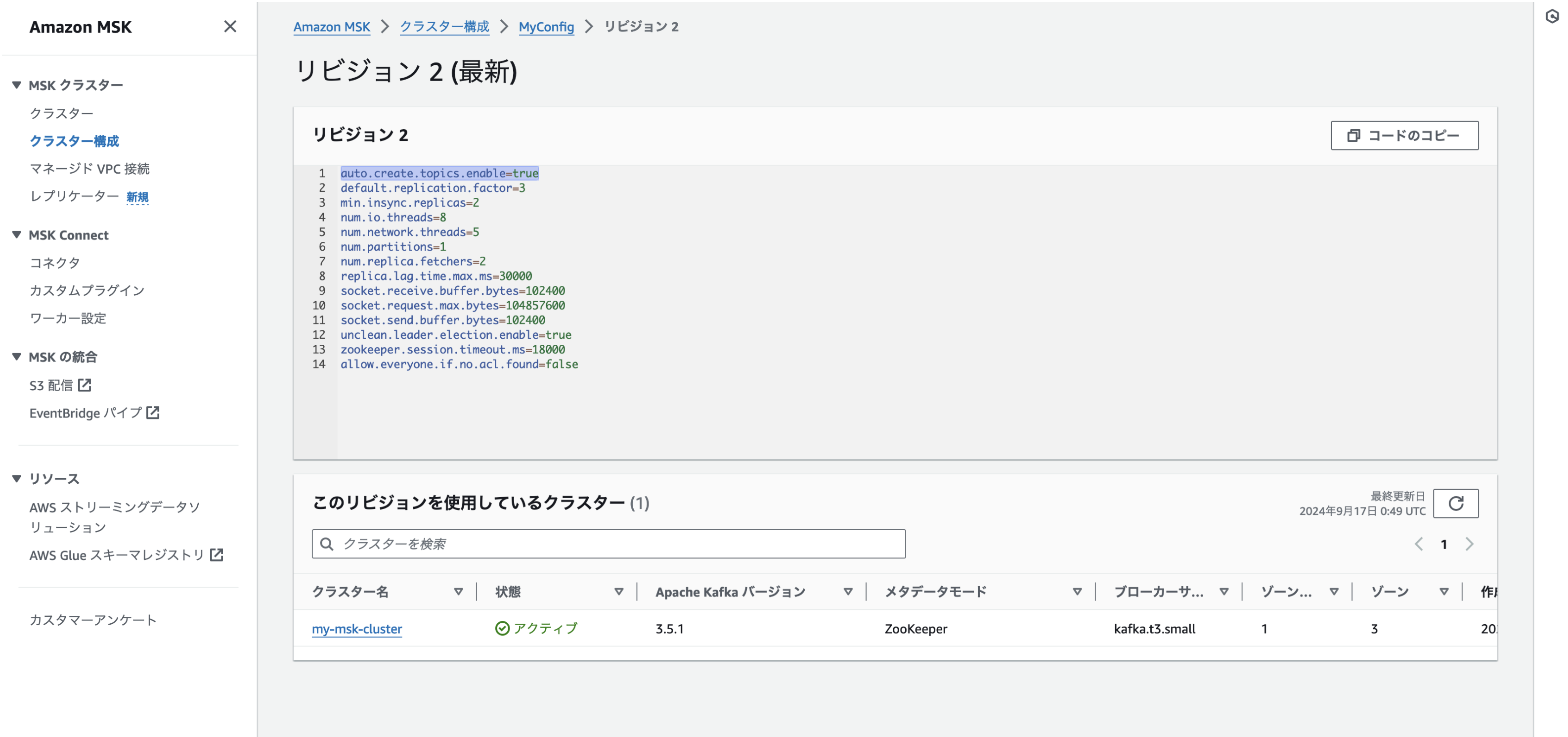

Json形式のメッセージング(AWS Glue Schema Registryを使用しない)
(1) kafkaproducer.properties/kafkaconsumer.propertiesの設定
retries=3
retry.backoff.ms=500
batch.size=65536
bootstrap.servers=b-2-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-3-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-1-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196
security.protocol=SASL_SSL
sasl.mechanism=SCRAM-SHA-512
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="my-user" password="my-password";
ssl.truststore.location=/tmp/kafka.client.truststore.jks
ssl.truststore.password=changeit
最後の2行の ssl.truststore.location と ssl.truststore.password については、トラストストアファイルの作成方法を含めて後述します。
ここはハマりポイントです。
(2) kcop.propertiesの設定
header.jcfs=ENTTYP,TIMSTAMP,CCID
上記はメッセージのヘッダーにCCIDなどの情報を付与する設定です。
この設定がなくても、kcop.properties自体がなくても今回の手順は上手くいきます。
(つまり、この設定は必須ではありません)
(3) サブスクリプション設定
サブスクリプションの作成(以下は作成後)
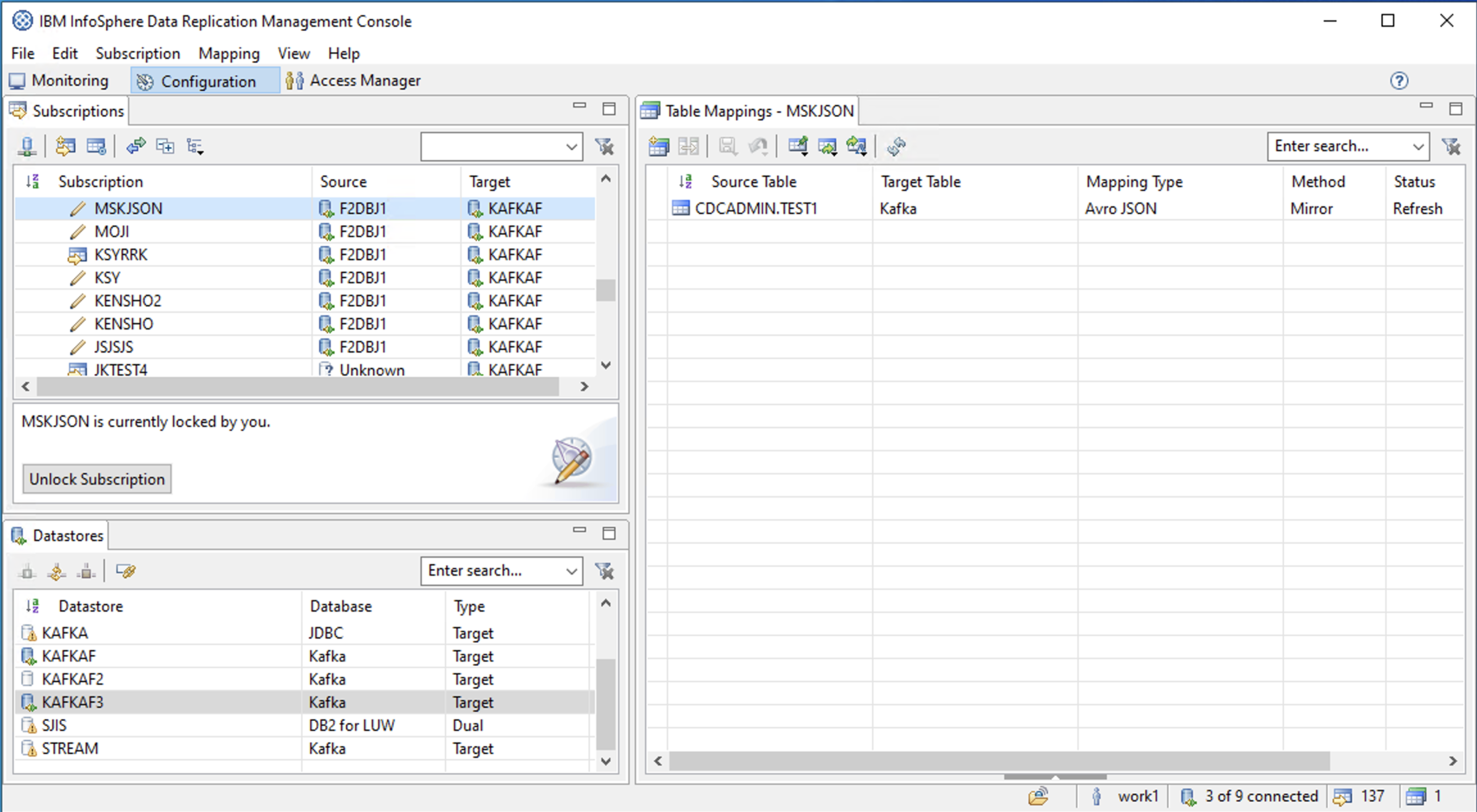
Kafka Propertiesの設定
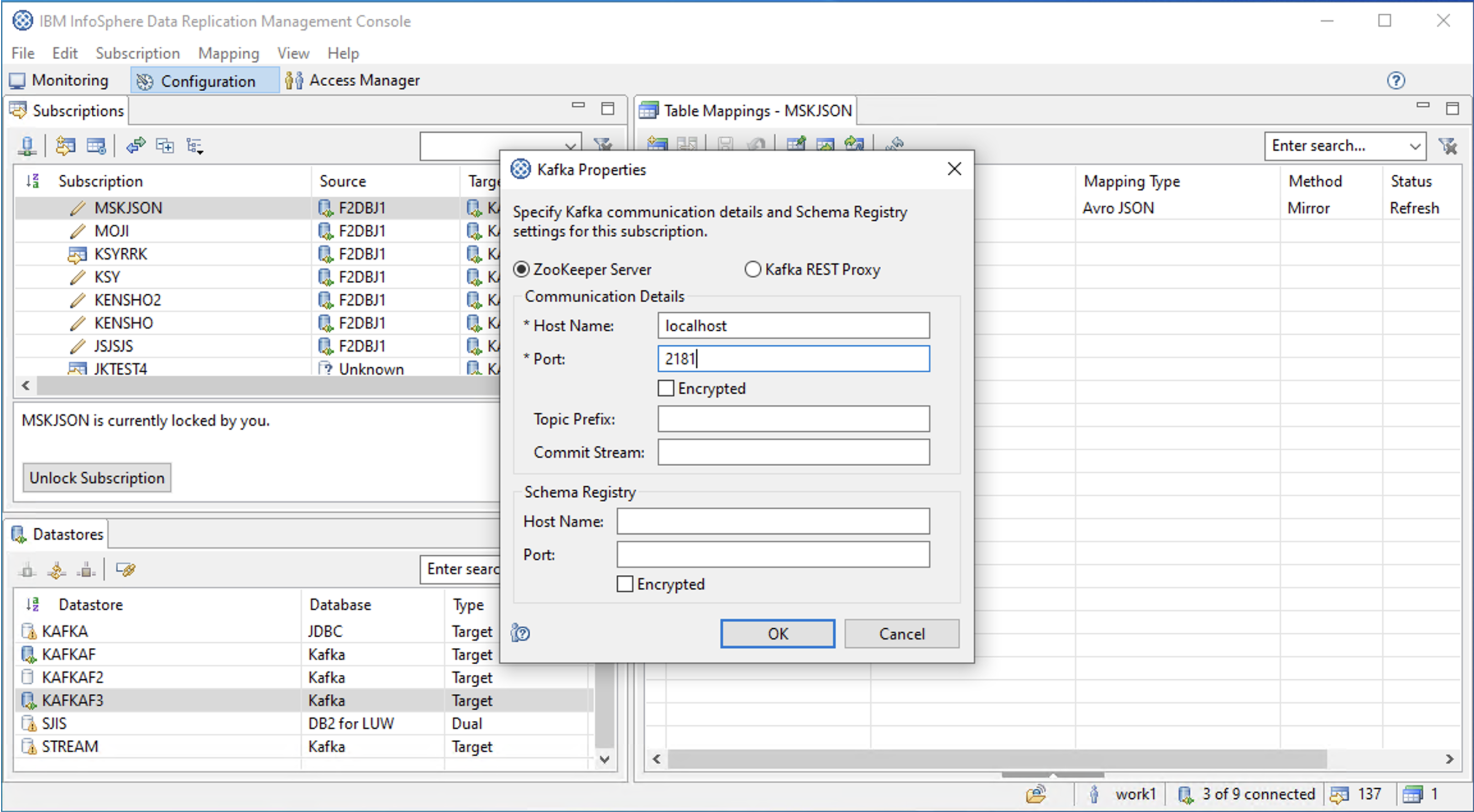
Zookeeperの「Host Name」と「Port」は必須入力欄となっています。
ただし、ここで指定する内容は便宜的なもので 内容はなんでもいいみたいです。
User Exitsの設定

# Class Name
com.datamirror.ts.target.publication.userexit.sample.kafka.KcopJsonFormatIntegrated
# Parameter(Kcop.propertiesファイルを指定) ※先頭ハイフンも必要
-file:/opt/ibm/InfoSphereDataReplication/ReplicationEngineforKafka/instance/KAFKAF/conf/kcop.properties
(上記のParameterの入力は今回は必須ではありません)
(4) リフレッシュ(ソーステーブルのデータの一括転送)
Flag for Refresh

Start Refresh
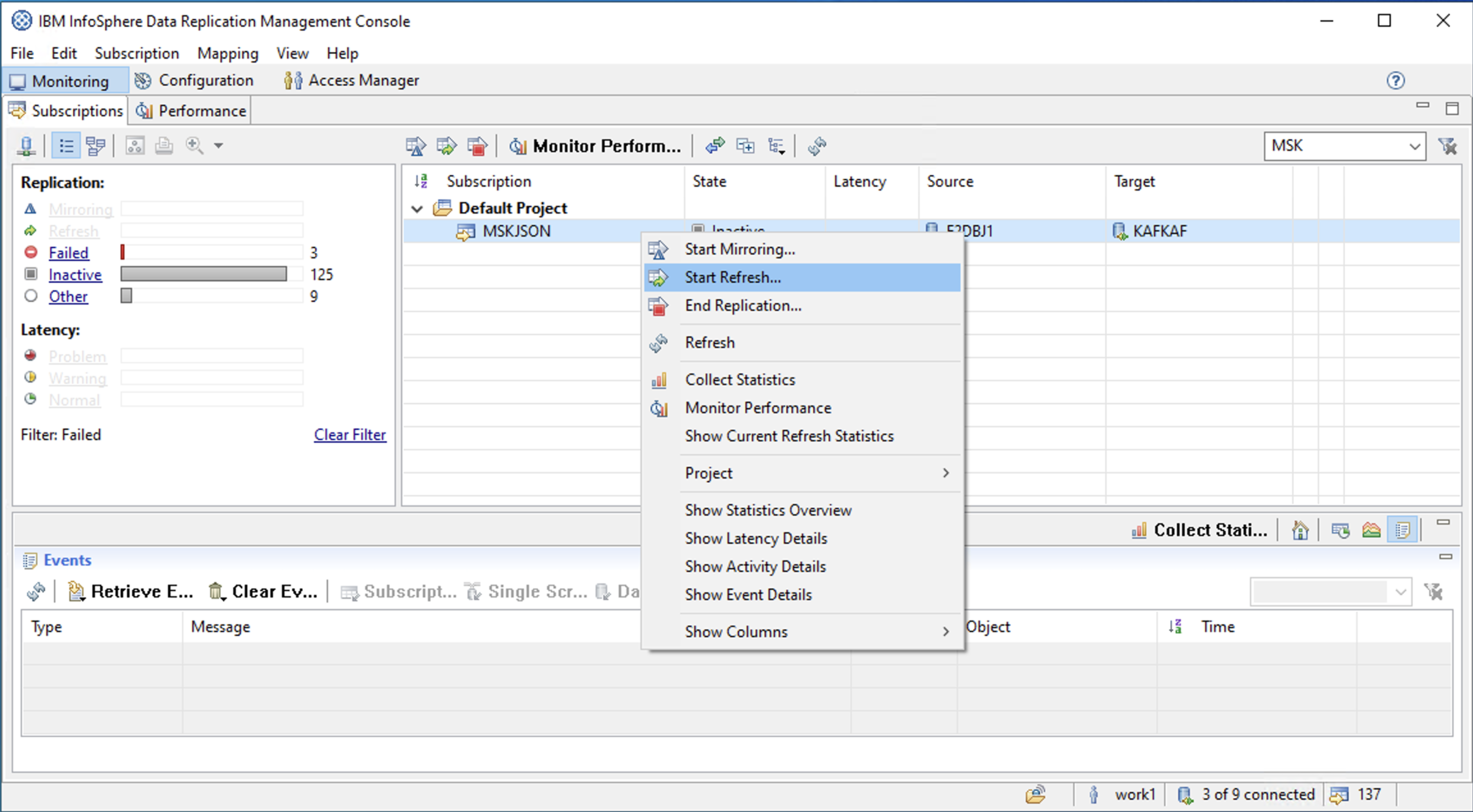
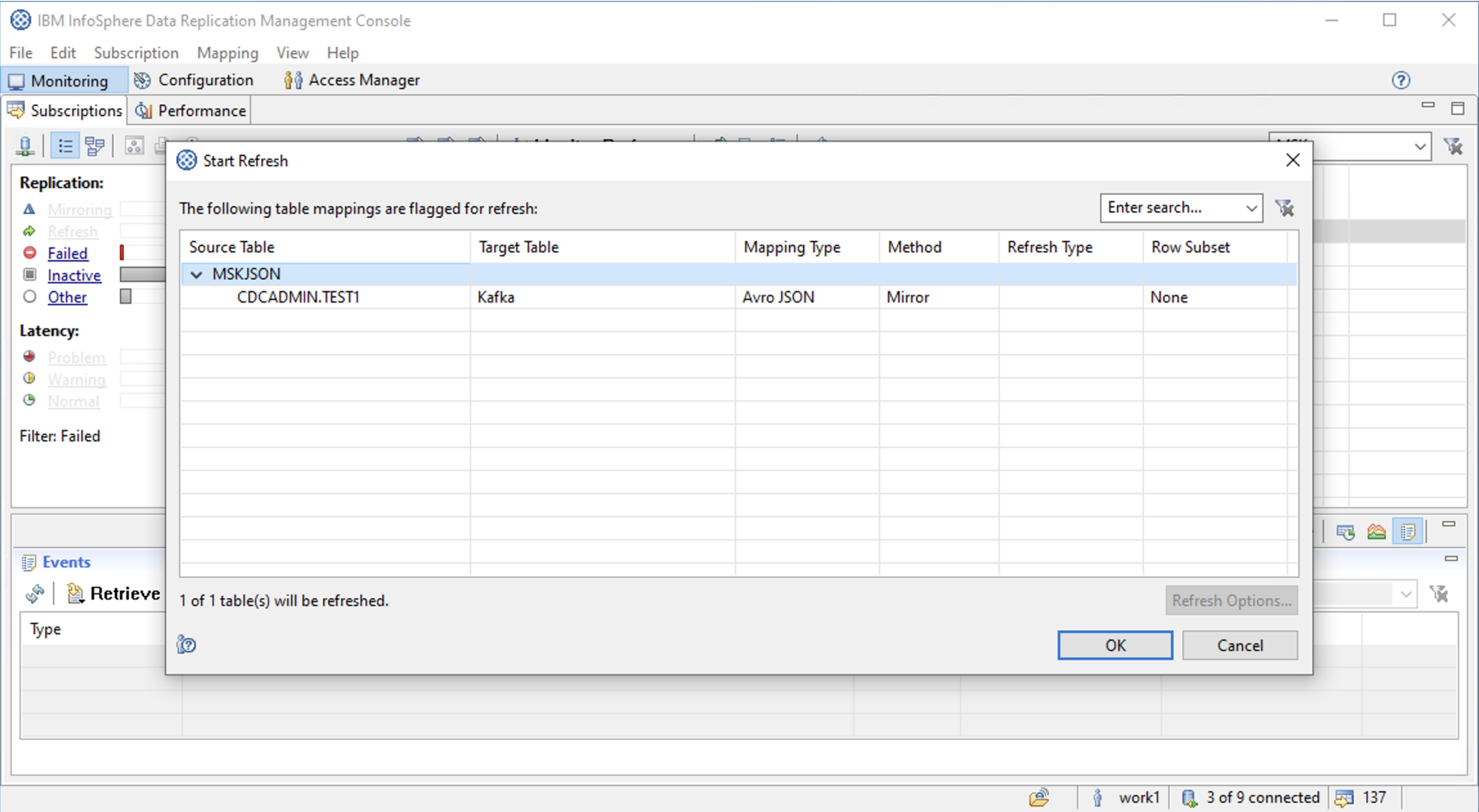
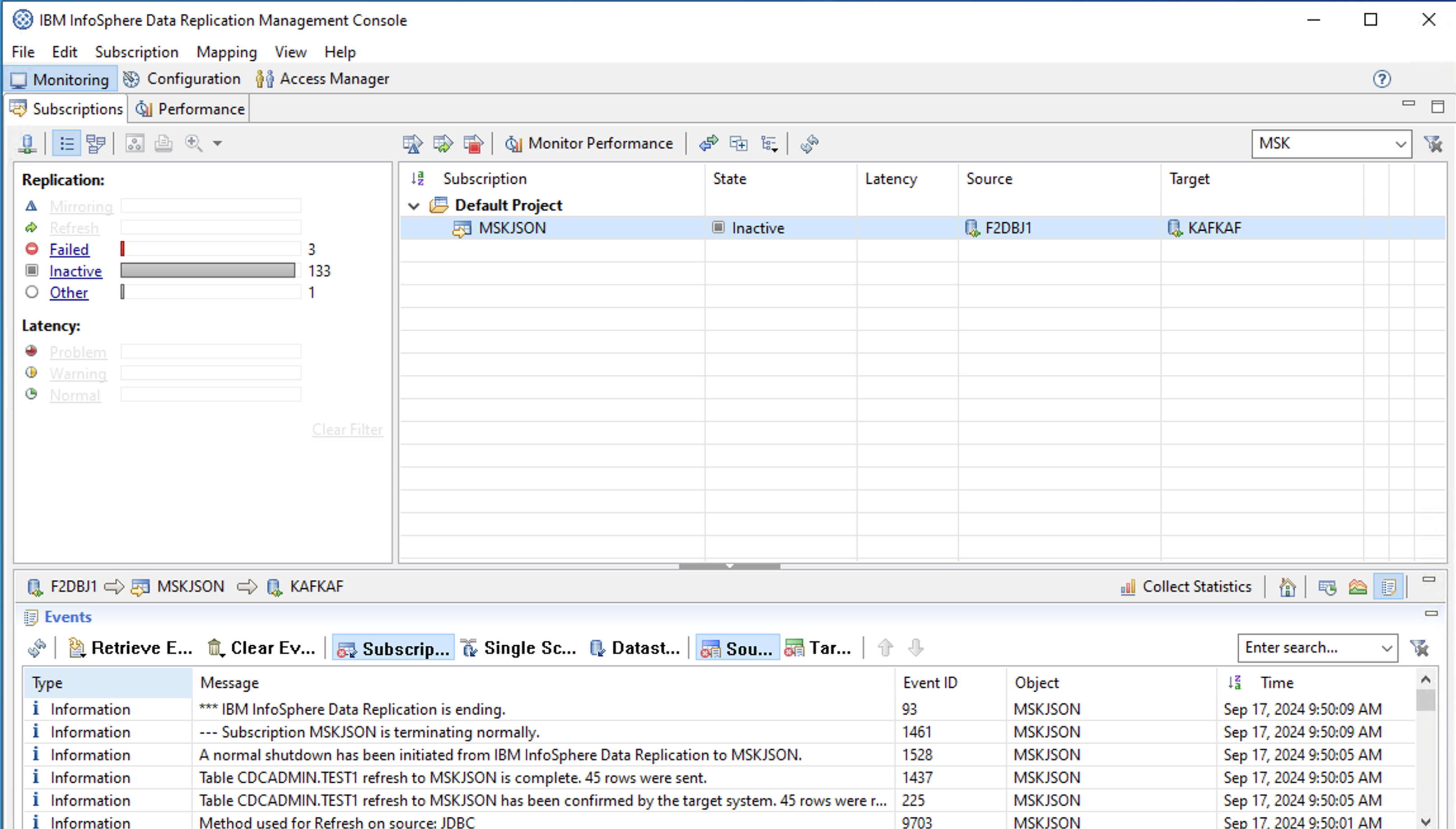
画面下部にあるEvents欄で「45 rows were sent.」というメッセージを確認できます。
リフレッシュ成功。
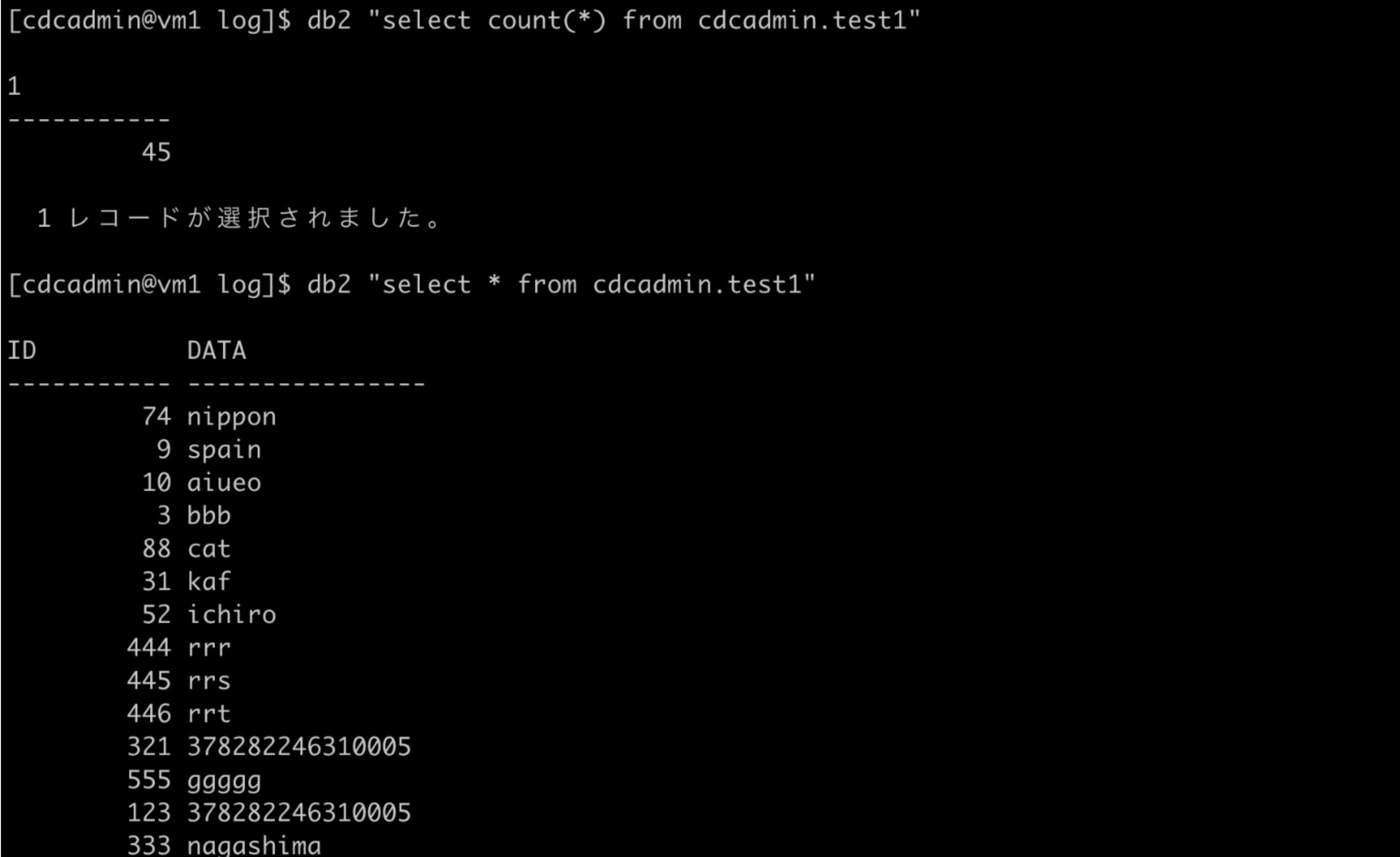
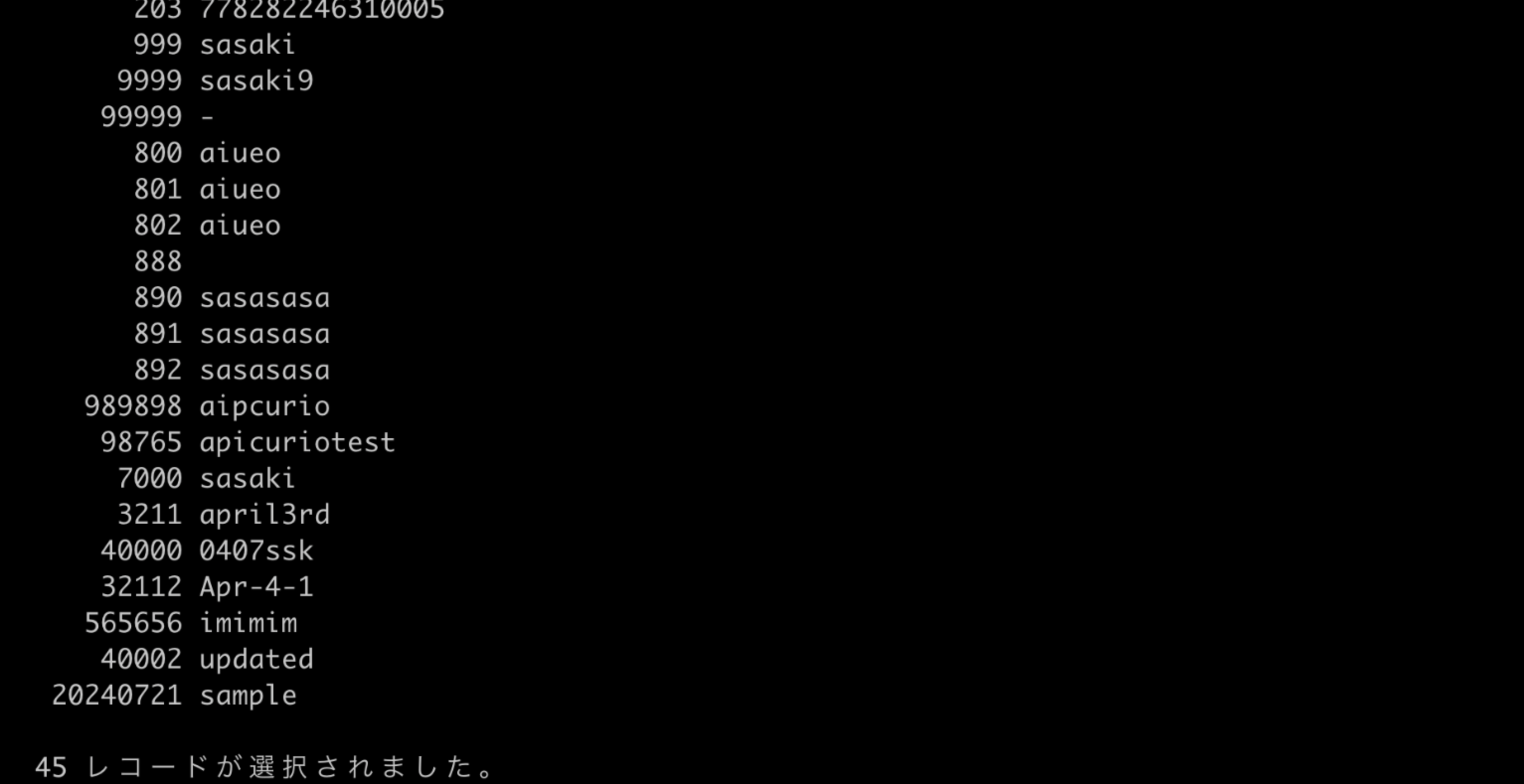
ソースのDB内容
Amazon MSKのトピック一覧をKafkaのユーティリティで確認
# /mskconfig-ssk.properties
security.protocol=SASL_SSL
sasl.mechanism=SCRAM-SHA-512
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="my-user" password="my-password";
ssl.truststore.location=/tmp/kafka.client.truststore.jks
ssl.truststore.password=changeit
./kafka-topics.sh --bootstrap-server b-2-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-3-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-1-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196 --command-config /mskconfig-ssk.properties --list
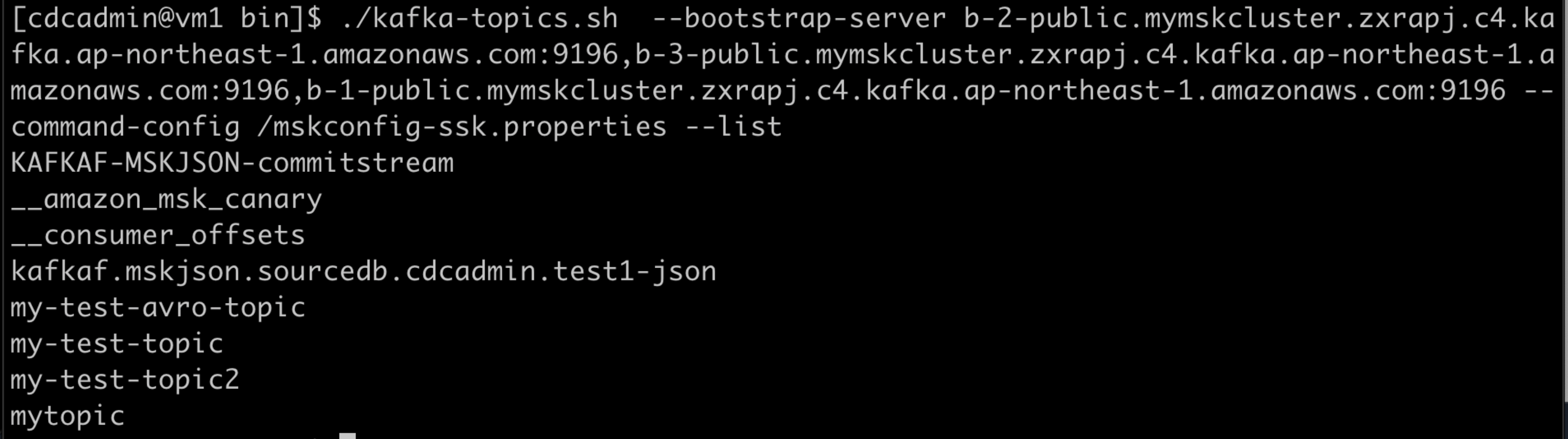
kafkaf.mskjson.sourcedb.cdcadmin.test1-jsonがIIDR CDCでのリフレッシュによって作成されたトピックです。
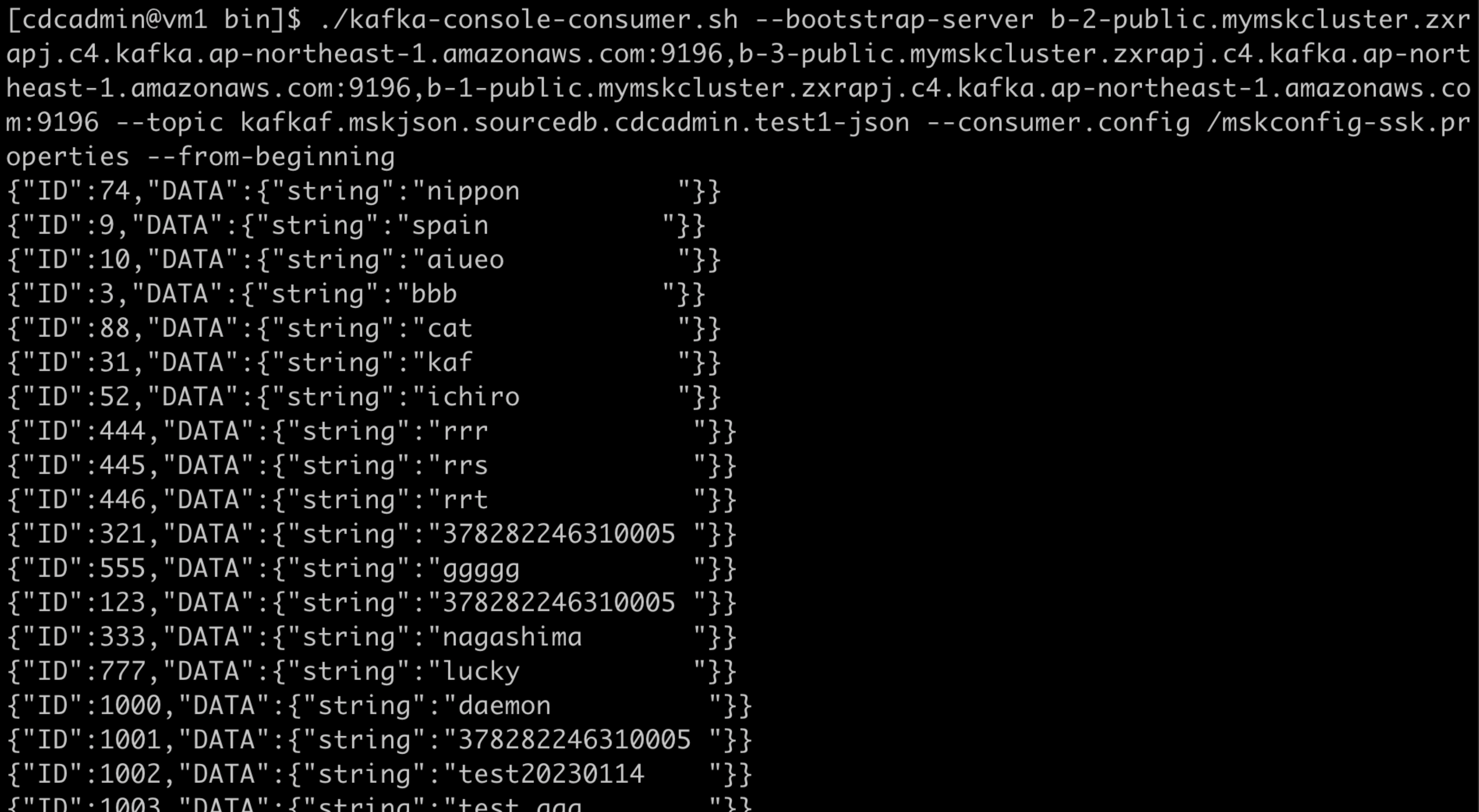
./kafka-console-consumer.sh --bootstrap-server b-2-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-3-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-1-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196 --topic kafkaf.mskjson.sourcedb.cdcadmin.test1-json --consumer.config /mskconfig-ssk.properties --from-beginning

ハマりポイント:トラストストアファイルの作成
今回IIDR CDCの接続先となるAmazon MSKのKafkaクラスターは認証方式として「SASL/SCRAM認証」を採用しています。この認証方式を採用している場合の諸々のやり方は下記の公式ドキュメントに記載があります。
参考:Sign-in credentials authentication with AWS Secrets Manager
このドキュメント内に以下のような記述があります。

Amazon MSKの認証方式には相互TLS(=mTLS)もありますが、それを採用しなくてもTLS暗号化をする以上はTLS認証の作法に準拠する必要があります。
つまり、クライアントはサーバーが提示する証明書が信頼できる認証局(CA)によって発行されたかどうかを確認できる必要があります。この確認には、クライアントが持つトラストストアが使われます。
従って上記の公式ドキュメントには以下のような手順が記載されているものと理解できます。

当初、この手順に従っていましたが、うまいきませんでした。
トライ&エラーの結果確認した失敗の原因は「IIDR CDCを導入したサーバーのJava(IIDR CDCの要件でJavaバージョンはJava8)が信頼している認証局(CA)の中に、Amazon MSK側の証明書のCAがなかったから」です。
確認したところ、Amazon MSKの証明書のCAは「Amazon Root CA」です。
少し新しめのJavaが導入されている環境のCAの中にはAmazon Root CAがありますが、IIDR CDCが搭載されているJava8の環境にはAmazon Root CAはありませんでした。
keytool -list -keystore /tmp/kafka.client.truststore.jks | grep -i amazon
Java11環境での確認結果
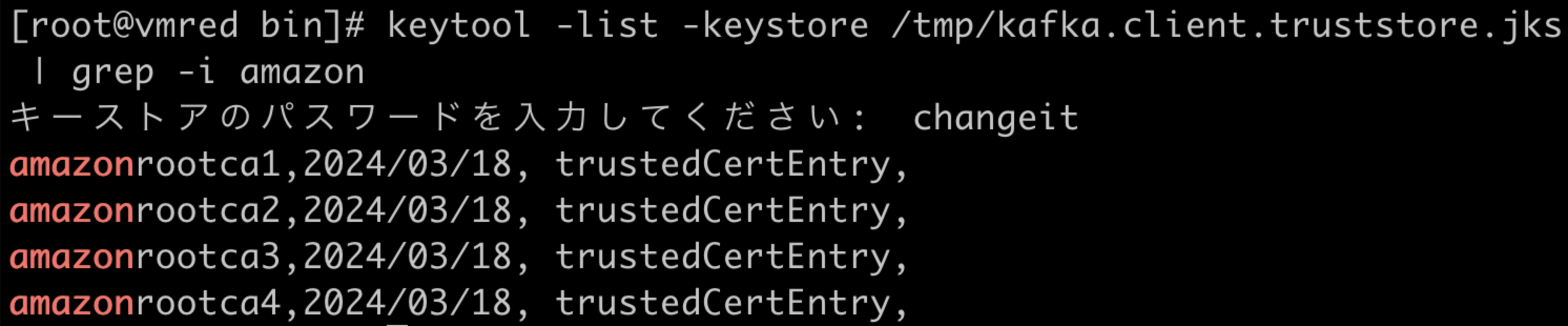
(Amazon Root CAがある)
Java8環境(IIDR CDCが導入されている環境)での確認結果

(Amazon Root CAがない)
ハマりポイントへの対応
wget https://www.amazontrust.com/repository/AmazonRootCA1.cer
wget https://www.amazontrust.com/repository/AmazonRootCA2.cer
wget https://www.amazontrust.com/repository/AmazonRootCA3.cer
wget https://www.amazontrust.com/repository/AmazonRootCA4.cer
- Amazon Root CAのインポート
keytool -import -alias amazonrootca1 -keystore /tmp/kafka.client.truststore.jks -file /home/cdcadmin/kafka/AmazonRootCA1.cer
keytool -import -alias amazonrootca2 -keystore /tmp/kafka.client.truststore.jks -file /home/cdcadmin/kafka/AmazonRootCA2.cer
keytool -import -alias amazonrootca3 -keystore /tmp/kafka.client.truststore.jks -file /home/cdcadmin/kafka/AmazonRootCA3.cer
keytool -import -alias amazonrootca4 -keystore /tmp/kafka.client.truststore.jks -file /home/cdcadmin/kafka/AmazonRootCA4.cer
keytool -import -alias amazonrootca4 -keystore /tmp/kafka.client.truststore.jks -file /home/cdcadmin/kafka/AmazonRootCA4.cer
keytool -import -alias starfieldservicesrootcertificateauthority-g2 -keystore /tmp/kafka.client.truststore.jks -file /home/cdcadmin/kafka/SFSRootCAG2.cer
インポート時のコマンド実行結果(AmzaonRootCA4のインポート実行結果のみ抜粋)は以下の通り。


上記の手順を実行した上で、kafkaproducer.propertiesとkafkaconsumer.propertiesに以下の記述を行う。
(ssl.truststore.passwordのchangeitはデフォルト設定。)
ssl.truststore.location=/tmp/kafka.client.truststore.jks
ssl.truststore.password=changeit
Avro形式のメッセージング(AWS Glue Schema Registryを使用する)
ここまでIIDR CDCからJson形式でAmazon MSKのKafkaクラスターにメッセージングする方法やハマりポイントを解説しましたが、ここからが本題です。
Json形式ではデータ型の表現が限定され、データベースのカラム毎のデータ型を厳密に伝搬することができないため、データソースとなるデータベースのデータを型を含めてデータターゲットに送りたい場合はAvro形式でのメッセージングを検討します。
以下は、IIDR CDCからのAvro形式でのメッセージング方法です。
実施手順の流れ
実施手順の基本的な流れは以下の通りです。
(1) AWS Glue Schema Registry Library Serializer / Deserializerの準備
(2) kafkaproducer.properties/kafkaconsumer.propertiesの設定
(3) kcop.propertiesの設定
(4) AWS Glue Schema Registryのアクセス権をもつIAMロールの使用
(5) サブスクリプション設定
(6) リフレッシュ(ソーステーブルのデータの一括転送)
(7) ミラーリング(変更データのキャプチャー開始)
(6)、(7)はリフレッシュ後に継続的にミラーリングがなされるように実行することができます。
本稿では、リフレッシュが行えればデータの疎通は確認できたことになるためミラーリングの実行については含んでいません。
また、IIDR CDCの導入に関する手順も含んでいません。
(1) AWS Glue Schema Registry Library Serializer / Deserializerの準備
AWS Glue Schema Registry Library Serializer / DeserializerのソースをGithubから持ってきてビルドする
参考:AWS Glue Schema Registry Library Serializer / Deserializer(Github)
wget https://github.com/awslabs/aws-glue-schema-registry/archive/refs/heads/master.zip
unzip master.zip
cd build-tools/
mvn clean install -Dcheckstyle.skip
cd ..
mvn clean install -Dcheckstyle.skip -DskipTests

依存性のあるJarコピーする
# 依存性のあるJarをコピー
cd /work/aws-glue-schema-registry-master/serializer-deserializer
mvn dependency:copy-dependencies
# 依存性のあるJarを確認(あとでファイルに記述する必要があるため確認は手順上必要)
cd target
ls dependency
annotations-13.0.jar
annotations-2.22.12.jar
apache-client-2.22.12.jar
apiguardian-api-1.1.0.jar
arns-2.22.12.jar
asm-9.1.jar
auth-2.22.12.jar
auto-value-annotations-1.8.1.jar
avro-1.11.3.jar
aws-core-2.22.12.jar
aws-java-sdk-core-1.12.660.jar
aws-java-sdk-sts-1.12.660.jar
aws-json-protocol-2.22.12.jar
aws-query-protocol-2.22.12.jar
byte-buddy-1.10.5.jar
byte-buddy-agent-1.10.5.jar
checker-qual-3.13.0.jar
checksums-2.22.12.jar
checksums-spi-2.22.12.jar
classgraph-4.8.120.jar
commons-codec-1.15.jar
commons-collections4-4.4.jar
commons-digester-2.1.jar
commons-lang3-3.8.1.jar
commons-logging-1.1.3.jar
commons-validator-1.7.jar
endpoints-spi-2.22.12.jar
error_prone_annotations-2.7.1.jar
eventstream-1.0.1.jar
everit-json-schema-1.14.2.jar
failureaccess-1.0.1.jar
glue-2.22.12.jar
guava-32.0.0-jre.jar
hamcrest-core-1.3.jar
handy-uri-templates-2.1.8.jar
http-auth-2.22.12.jar
http-auth-aws-2.22.12.jar
http-auth-spi-2.22.12.jar
http-client-spi-2.22.12.jar
httpclient-4.5.13.jar
httpcore-4.4.13.jar
identity-spi-2.22.12.jar
j2objc-annotations-2.8.jar
jackson-annotations-2.12.2.jar
jackson-core-2.12.2.jar
jackson-databind-2.12.2.jar
jackson-dataformat-cbor-2.12.2.jar
javapoet-1.13.0.jar
jimfs-1.1.jar
jmespath-java-1.12.660.jar
joda-time-2.8.1.jar
json-20231013.jar
json-utils-2.22.12.jar
jsr305-3.0.2.jar
junit-4.13.1.jar
junit-jupiter-api-5.6.3.jar
junit-jupiter-engine-5.6.3.jar
junit-jupiter-params-5.6.3.jar
junit-platform-commons-1.6.2.jar
junit-platform-engine-1.6.3.jar
kafka-clients-3.6.1.jar
kotlin-reflect-1.7.10.jar
kotlin-script-runtime-1.7.10.jar
kotlin-scripting-common-1.7.10.jar
kotlin-scripting-compiler-embeddable-1.7.10.jar
kotlin-scripting-compiler-impl-embeddable-1.7.10.jar
kotlin-scripting-jvm-1.7.10.jar
kotlin-stdlib-1.7.10.jar
kotlin-stdlib-common-1.7.10.jar
kotlin-stdlib-jdk7-1.7.10.jar
kotlin-stdlib-jdk8-1.7.10.jar
kotlinpoet-1.10.2.jar
kotlinx-coroutines-core-jvm-1.5.2.jar
kotlinx-datetime-jvm-0.3.2.jar
kotlinx-serialization-core-jvm-1.4.0.jar
listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar
lombok-1.18.26.jar
lz4-java-1.8.0.jar
mbknor-jackson-jsonschema_2.12-1.0.39.jar
metrics-spi-2.22.12.jar
mockito-core-3.3.3.jar
mockito-junit-jupiter-3.3.3.jar
netty-buffer-4.1.100.Final.jar
netty-codec-4.1.100.Final.jar
netty-codec-http-4.1.100.Final.jar
netty-codec-http2-4.1.100.Final.jar
netty-common-4.1.100.Final.jar
netty-handler-4.1.100.Final.jar
netty-nio-client-2.22.12.jar
netty-resolver-4.1.100.Final.jar
netty-transport-4.1.100.Final.jar
netty-transport-classes-epoll-4.1.100.Final.jar
netty-transport-native-unix-common-4.1.100.Final.jar
objenesis-2.6.jar
okhttp-4.9.3.jar
okio-3.4.0.jar
okio-fakefilesystem-3.2.0.jar
okio-fakefilesystem-jvm-3.2.0.jar
okio-jvm-3.4.0.jar
opentest4j-1.2.0.jar
profiles-2.22.12.jar
proto-google-common-protos-2.7.4.jar
protobuf-java-3.19.6.jar
protocol-core-2.22.12.jar
re2j-1.6.jar
reactive-streams-1.0.4.jar
regions-2.22.12.jar
scala-library-2.12.10.jar
schema-registry-build-tools-1.1.20.jar
schema-registry-common-1.1.20.jar
sdk-core-2.22.12.jar
slf4j-api-1.7.30.jar
snappy-java-1.1.10.5.jar
sts-2.22.12.jar
swiftpoet-1.3.1.jar
third-party-jackson-core-2.22.12.jar
truth-1.1.3.jar
truth-liteproto-extension-1.1.3.jar
truth-proto-extension-1.1.3.jar
url-connection-client-2.22.12.jar
utils-2.22.12.jar
validation-api-2.0.1.Final.jar
wire-compiler-4.3.0.jar
wire-grpc-client-jvm-4.3.0.jar
wire-grpc-server-generator-4.3.0.jar
wire-java-generator-4.3.0.jar
wire-kotlin-generator-4.3.0.jar
wire-profiles-4.3.0.jar
wire-runtime-4.3.0.jar
wire-runtime-jvm-4.3.0.jar
wire-schema-4.3.0.jar
wire-schema-jvm-4.3.0.jar
wire-swift-generator-4.3.0.jar
zstd-jni-1.5.5-1.jar
user-classloader.cpの記述
user-classloader.cpはKCOPのためにロードするクラスを記述するファイルです。
参考:Specifying a custom classpath for KCOPs
前述の依存性のあるJarをIIDR CDCが参照できるディレクトリに配置した上で、user-classloader.cpにコロン(;)つなぎで全Jarファイルの絶対パスを記述します。
試しましたがuser-classloader.cpを記述する際に、アスタリスク(*)を使用した記述は有効ではありませんでした。
なお、前述の「依存性のあるJar」だけでは不足しておりCDCによるリフレッシュ実行時にこのようなエラーになります。

よって、IIDR CDCのインストールディレクトリ直下にある下記2のJarファイルもuser-classloader.cpに追記します。
/opt/ibm/InfoSphereDataReplication/ReplicationEngineforKafka/lib/jackson-mapper-asl-1.9.13.jar
/opt/ibm/InfoSphereDataReplication/ReplicationEngineforKafka/lib/jackson-core-asl-1.9.13.jar
また、後述の手順で確認する「com.amazonaws.services.schemaregistry.serializers.avro.CustomerProvidedSchemaNamingStrategy」はビルドした際のtarget/schema-registry-serde-1.1.20-tests.jarの中にいるクラスのため、schema-registry-serde-1.1.20-tests.jarもuser-classloader.cpへの記述が必要になる。
user-classloader.cpの記述を有効化させるためにインスタンスの再起動を行います。
[CDC_Kafka_install_directory]/bin/dmshutdown -I [インスタンス名]
nohup [CDC_Kafka_install_directory]/bin/dmts64 -I [インスタンス名] &
(2) kafkaproducer.properties/kafkaconsumer.propertiesの設定
retries=3
retry.backoff.ms=500
batch.size=65536
bootstrap.servers=b-2-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-3-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-1-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196
security.protocol=SASL_SSL
sasl.mechanism=SCRAM-SHA-512
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="my-user" password="my-password";
ssl.truststore.location=/tmp/kafka.client.truststore.jks
ssl.truststore.password=changeit
(Json形式のときと内容変わらず)
(3) kcop.propertiesの設定
schema.registry.url=
serializer.class=com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistryKafkaSerializer
serializer.property.dataFormat=AVRO
serializer.property.region=ap-northeast-1
serializer.property.registry.named=my-registry
serializer.property.schemaAutoRegistrationEnabled=true
serializer.property.schemaNameGenerationClass=com.amazonaws.services.schemaregistry.serializers.avro.CustomerProvidedSchemaNamingStrategy
schema.registry.urlはAvro形式のメッセージングを行う際には入力必須の項目となっています。今回はAWS Glue Schema Registryを使用するため、従来のURLでのAPIエンドポイント指定をする記述が不要です。入力必須でありながら指定が不要の場合には、上記のようにプロパティの「=」の後を未入力とすることができます。
serializer.property.schemaAutoRegistrationEnabledはAWS Glue Schema Registry内にないスキーマを登録する場合は、スキーマを自動作成するか、自動作成させずにエラーとするかの振る舞いを決めるプロパティです。試行時にはスキーマ名を厳密に考慮して動作確認をしないため、基本はtrueにすべきと考えられます。
serializer.classについて、似たようなクラス名のものがあるため注意が必要です。
GlueSchemaRegistryKafkaSerializer.java ◯
GlueSchemaRegistrySerializer.java ×
前者のクラス名をプロパティに記述するようにしてください。
serializer.property.schemaNameGenerationClassはProducerがAWS Glue Schema Registryにスキーマを書き込む際に、キー部とバリュー部のそれぞれのスキーマをどのように命名するかを決定づけるプロパティです。CustomerProvidedSchemaNamingStrategyを指定することでキー部用とバリュー部用のスキーマを区別して設定できるようになります。
serializer.property.schemaNameGenerationClassを設定しない場合、キー部用のスキーマとバリュー部用のスキーマが同名で登録されることになりスキーマの互換性エラーになります。
(4) AWS Glue Schema Registryのアクセス権をもつIAMロールの使用
# AWS Glue Schema Registryのアクセス権を持つIAMロールの認証情報を取得
aws sts assume-role --role-arn arn:aws:iam::XXXXXXXXXXXX:role/MyGlueSchemaRegistryAccessRole --role-session-name test-session --profile default --region ap-northeast-1 --output json
# 取得したIAMロールの認証情報をAWSの認証情報系の環境変数にセット
export AWS_ACCESS_KEY_ID="・・・"
export AWS_SECRET_ACCESS_KEY="・・・"
export AWS_SESSION_TOKEN="・・・"
(5) サブスクリプション設定
サブスクリプションの作成

ソーステーブルの選択
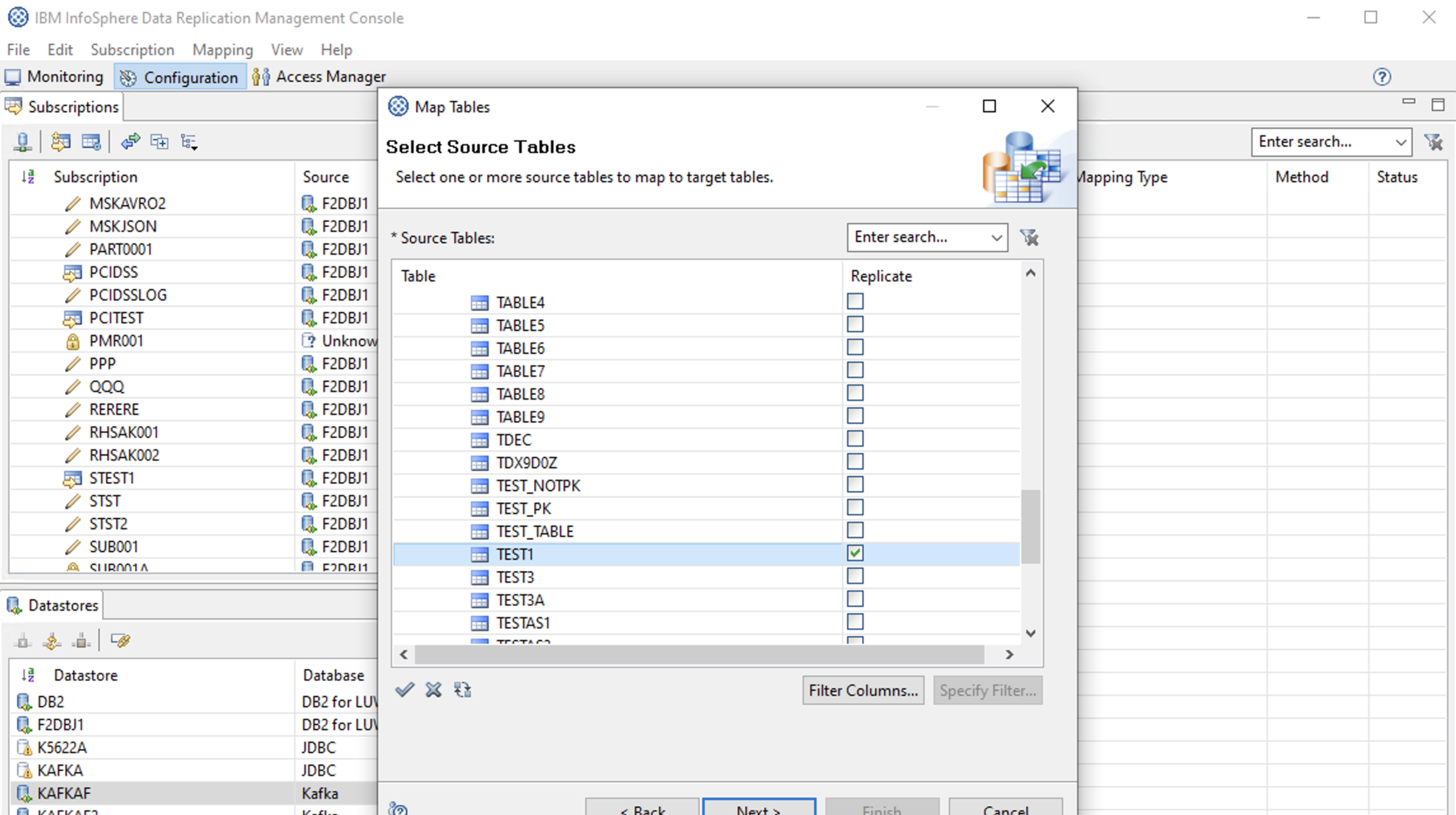
Kafka Propertiesの設定
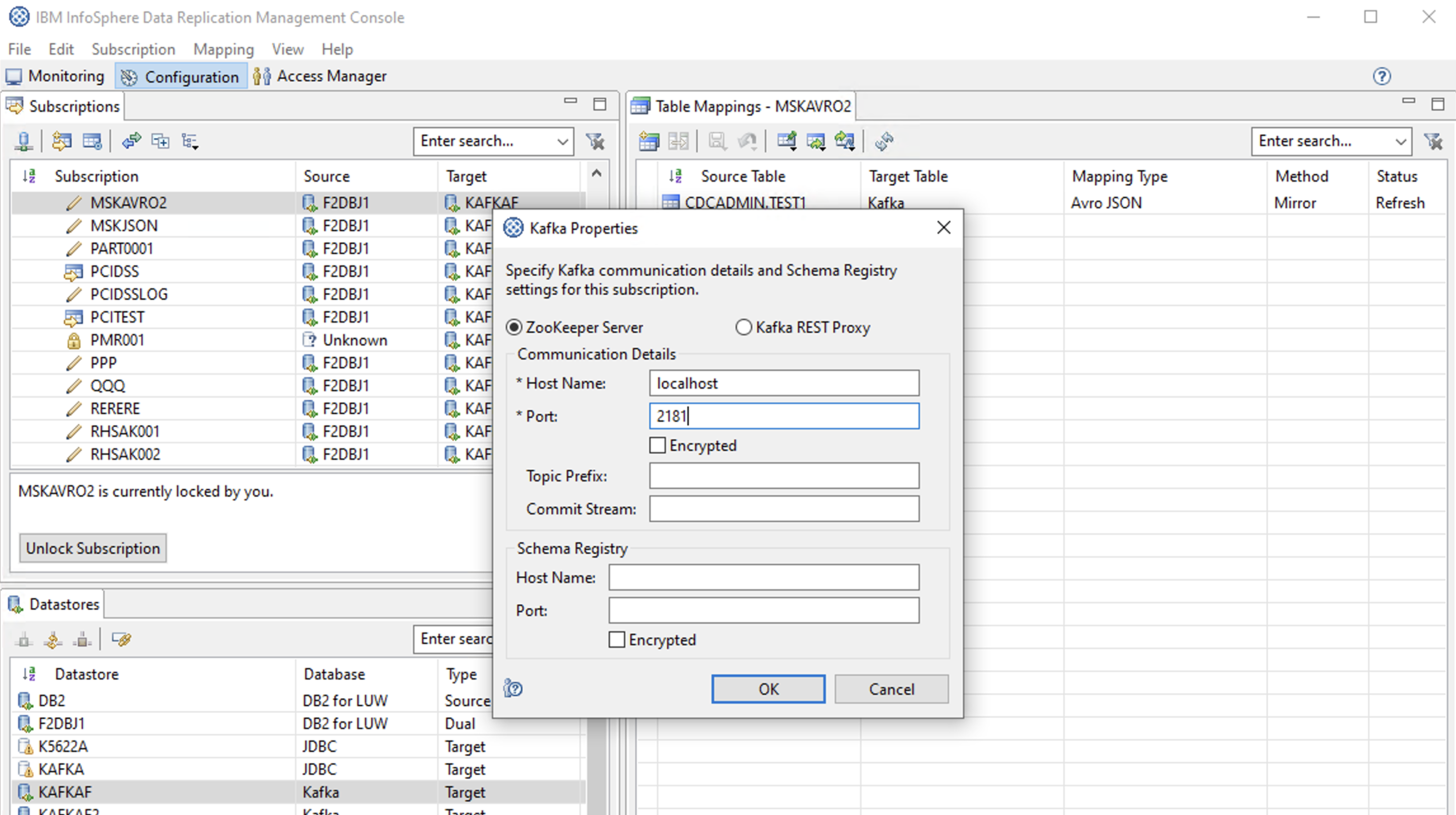
Zookeeperの「Host Name」と「Port」は必須入力欄となっています。
ただし、ここで指定する内容は便宜的なもので 内容はなんでもいいみたいです。
(再掲)
User Exitsの設定

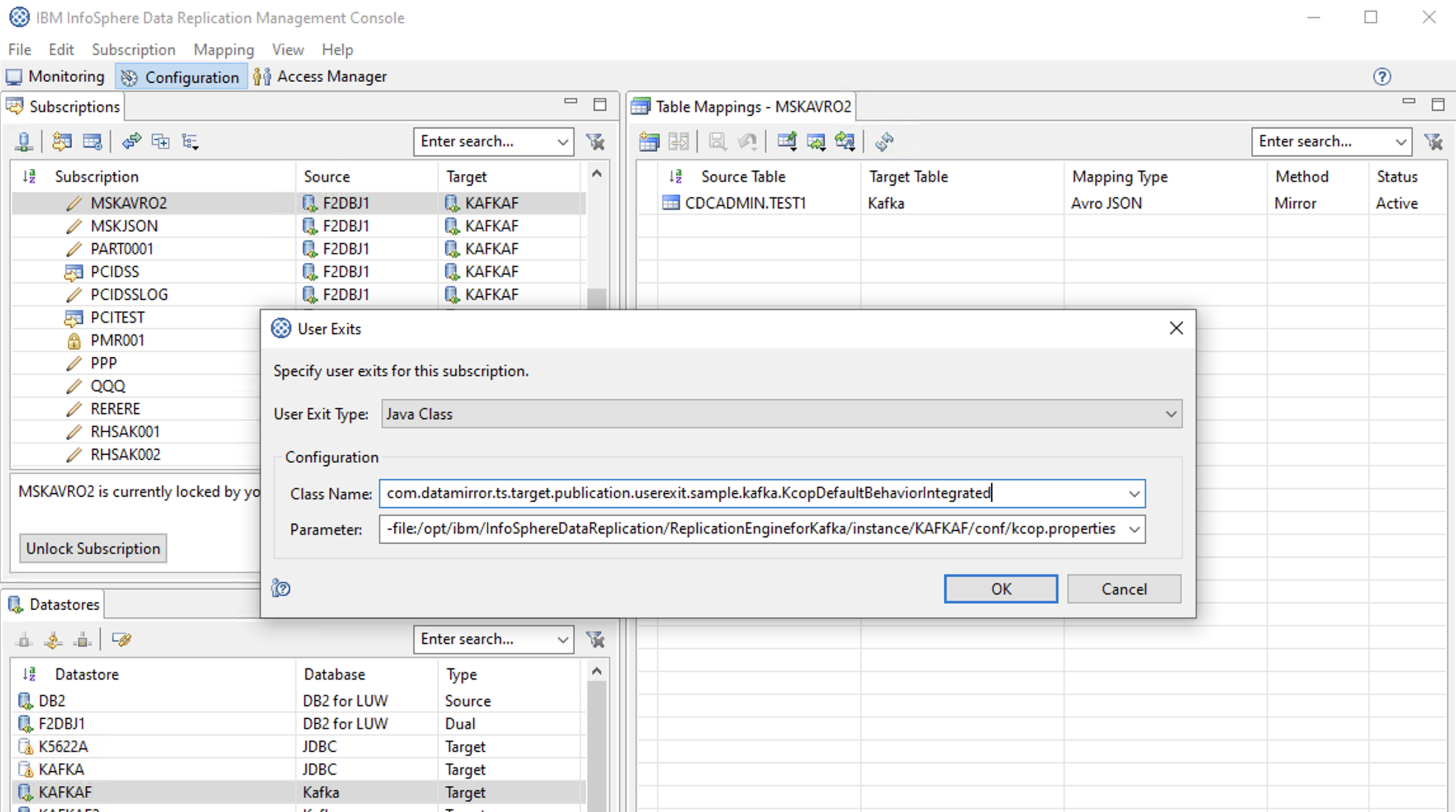
# Class Name
com.datamirror.ts.target.publication.userexit.sample.kafka.KcopDefaultBehaviorIntegrated
# Parameter(Kcop.propertiesファイルを指定) ※先頭ハイフンも必要
-file:/opt/ibm/InfoSphereDataReplication/ReplicationEngineforKafka/instance/KAFKAF/conf/kcop.properties
(6) リフレッシュ(ソーステーブルのデータの一括転送)
Flag for Refresh


Start Refresh
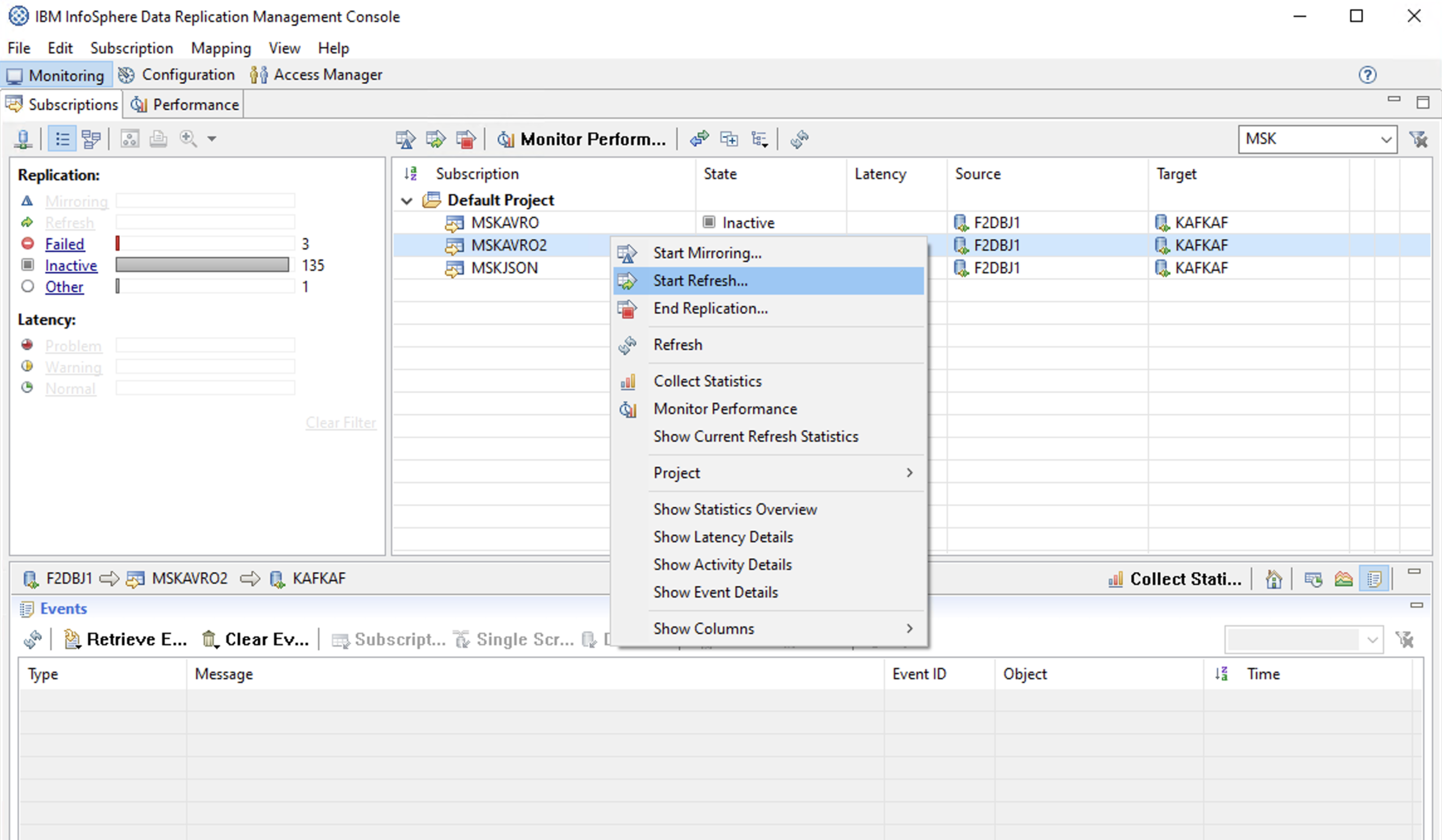
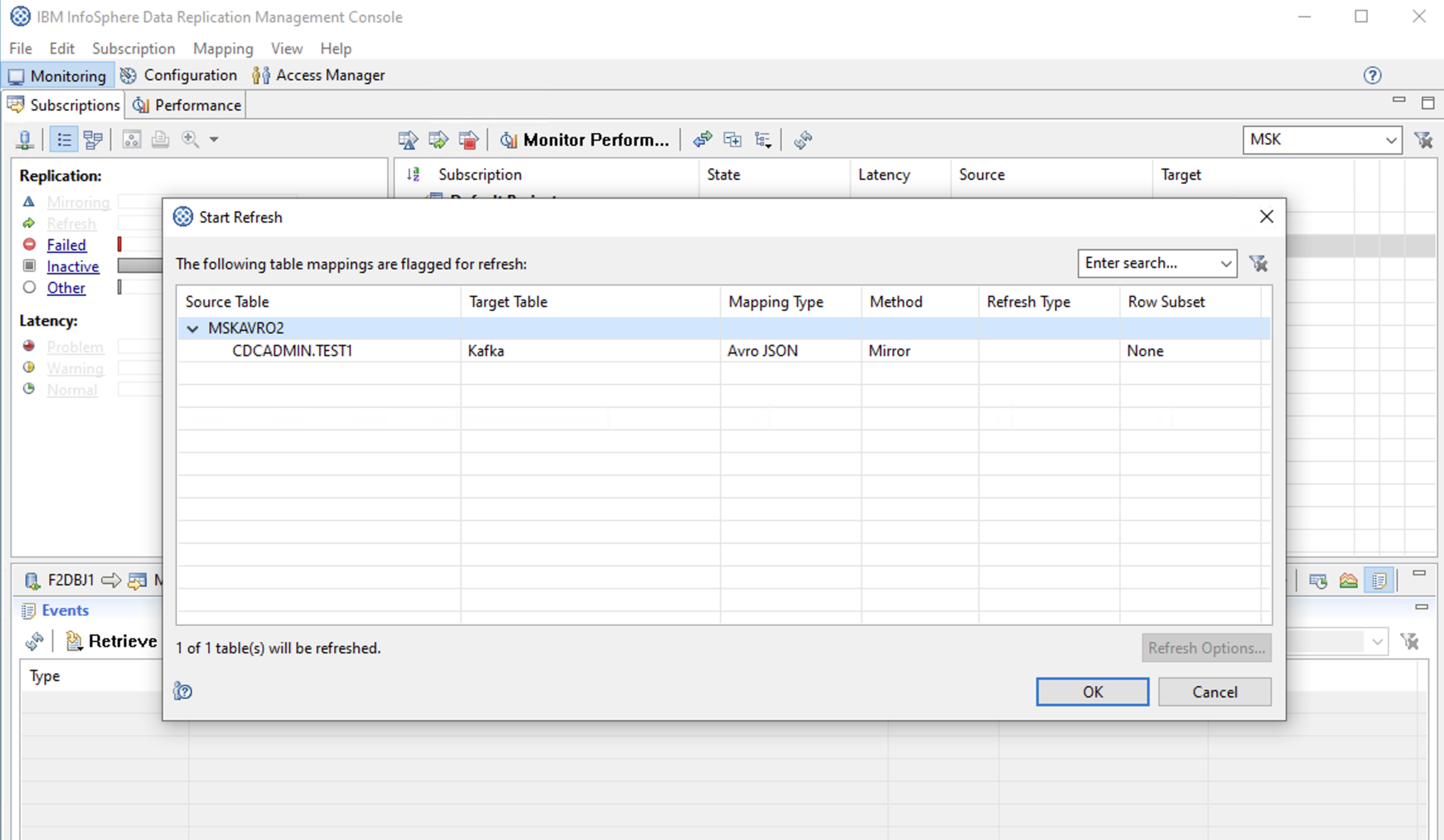
画面下部にあるEvents欄で「45 rows were sent.」というメッセージを確認できます。
リフレッシュ成功。

Amazon MSKのトピック一覧をKafkaのユーティリティで確認
# /mskconfig-ssk.properties
security.protocol=SASL_SSL
sasl.mechanism=SCRAM-SHA-512
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="my-user" password="my-password";
ssl.truststore.location=/tmp/kafka.client.truststore.jks
ssl.truststore.password=changeit
./kafka-topics.sh --bootstrap-server b-2-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-3-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-1-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196 --command-config /mskconfig-ssk.properties --list
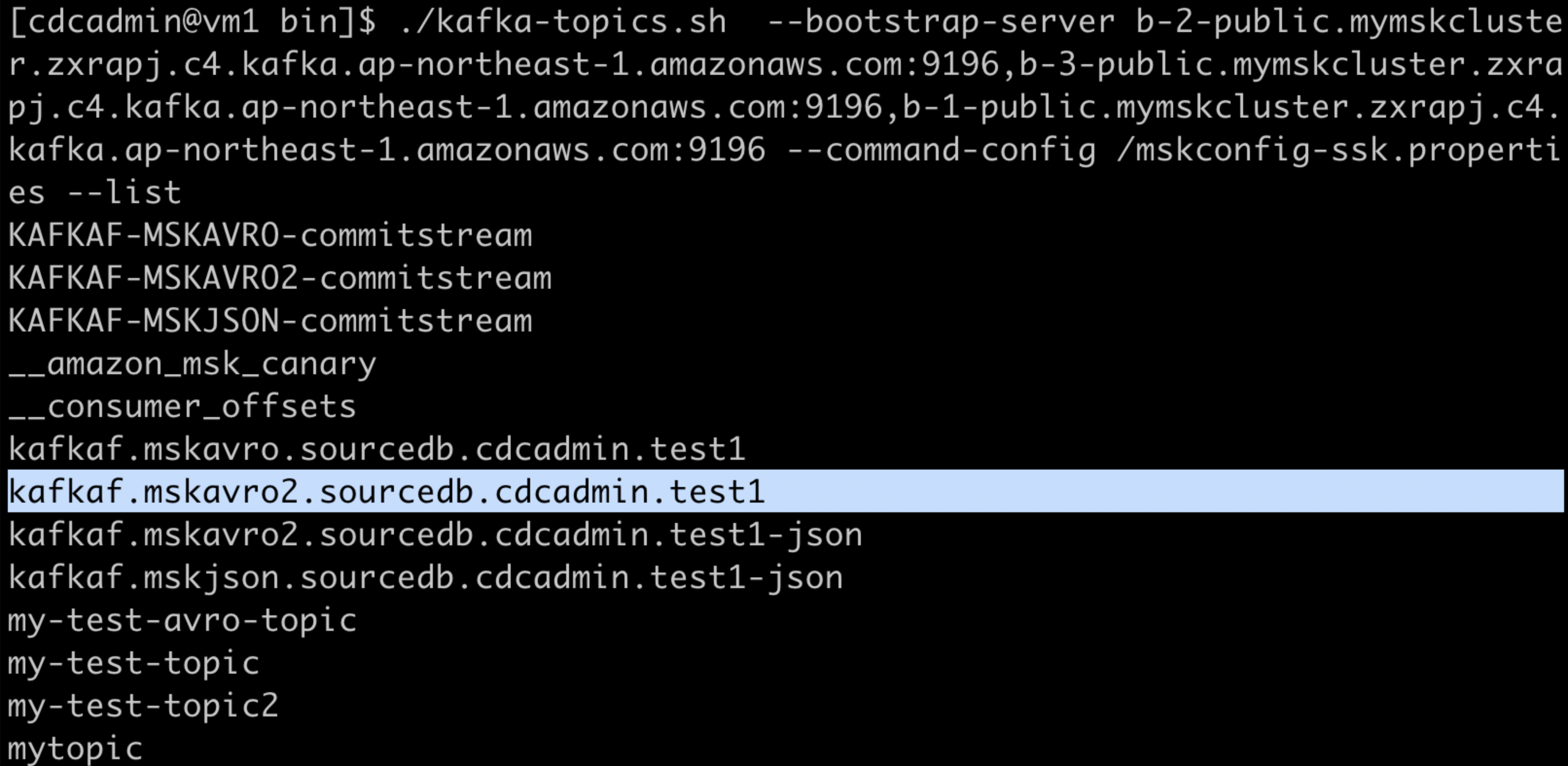
kafkaf.mskavro2.sourcedb.cdcadmin.test1がIIDR CDCでのリフレッシュによって作成されたトピックです。
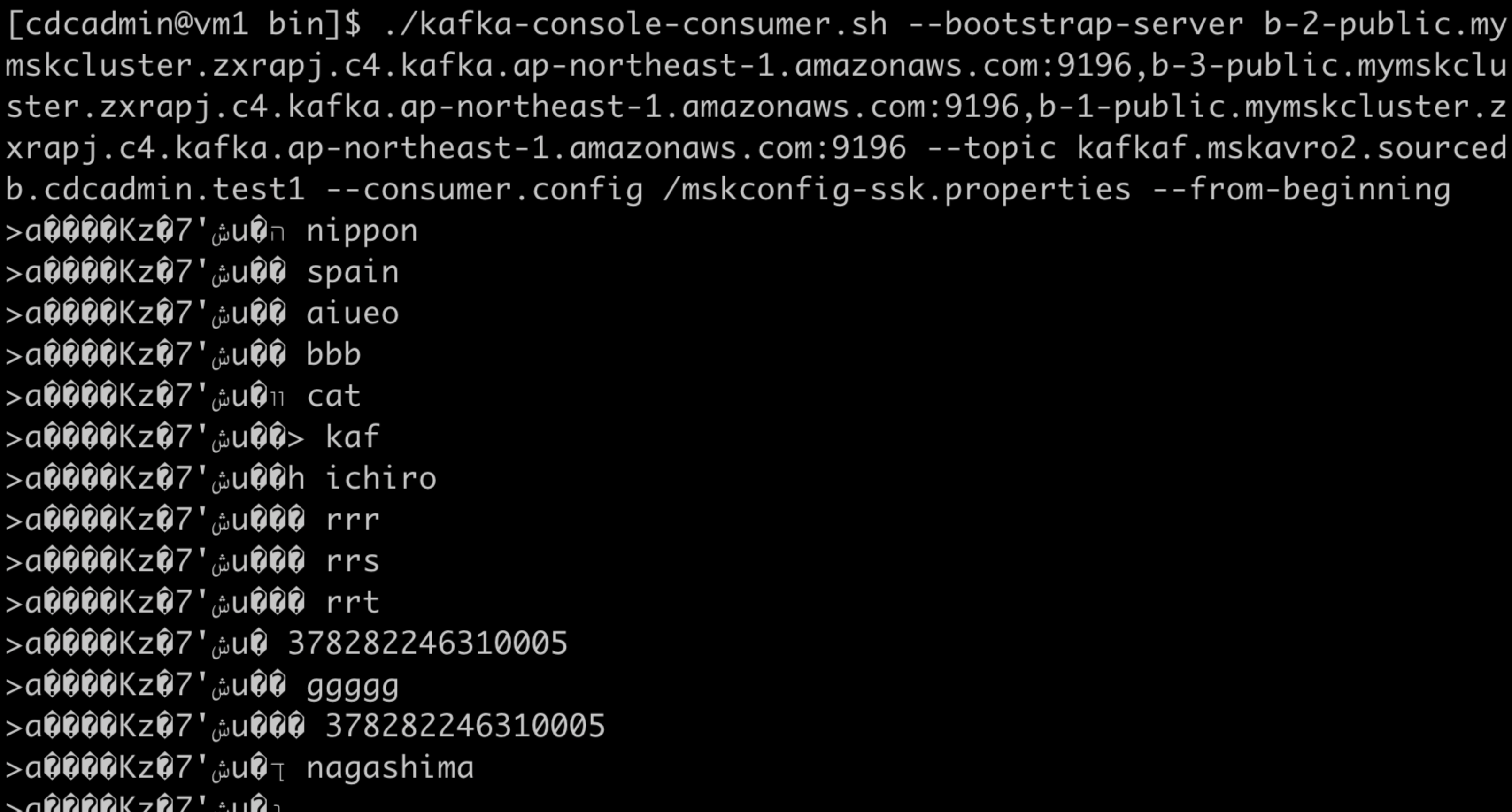
./kafka-console-consumer.sh --bootstrap-server b-2-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-3-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196,b-1-public.mymskcluster.zxrapj.c4.kafka.ap-northeast-1.amazonaws.com:9196 --topic kafkaf.mskavro2.sourcedb.cdcadmin.test1 --consumer.config /mskconfig-ssk.properties --from-beginning
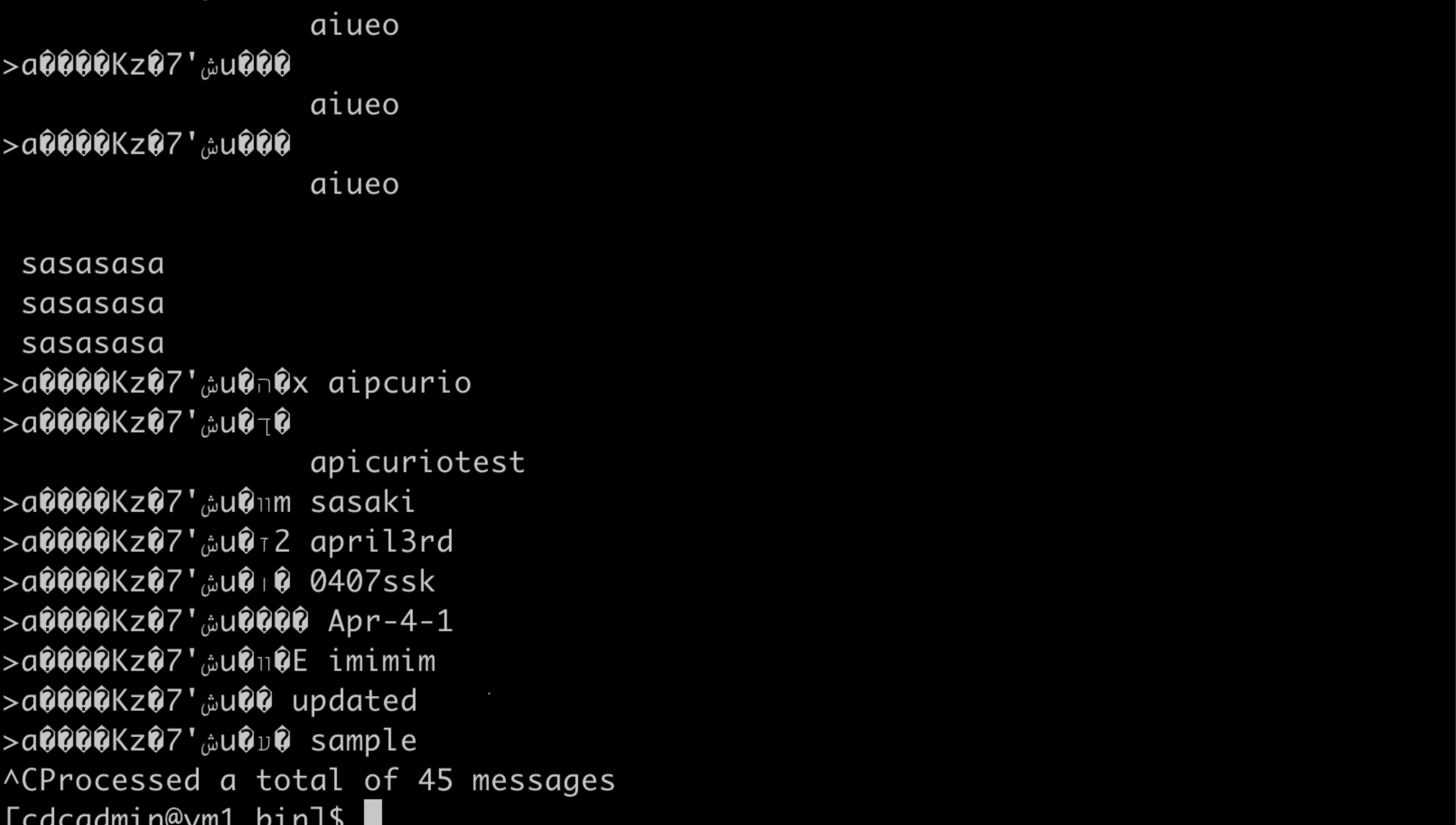
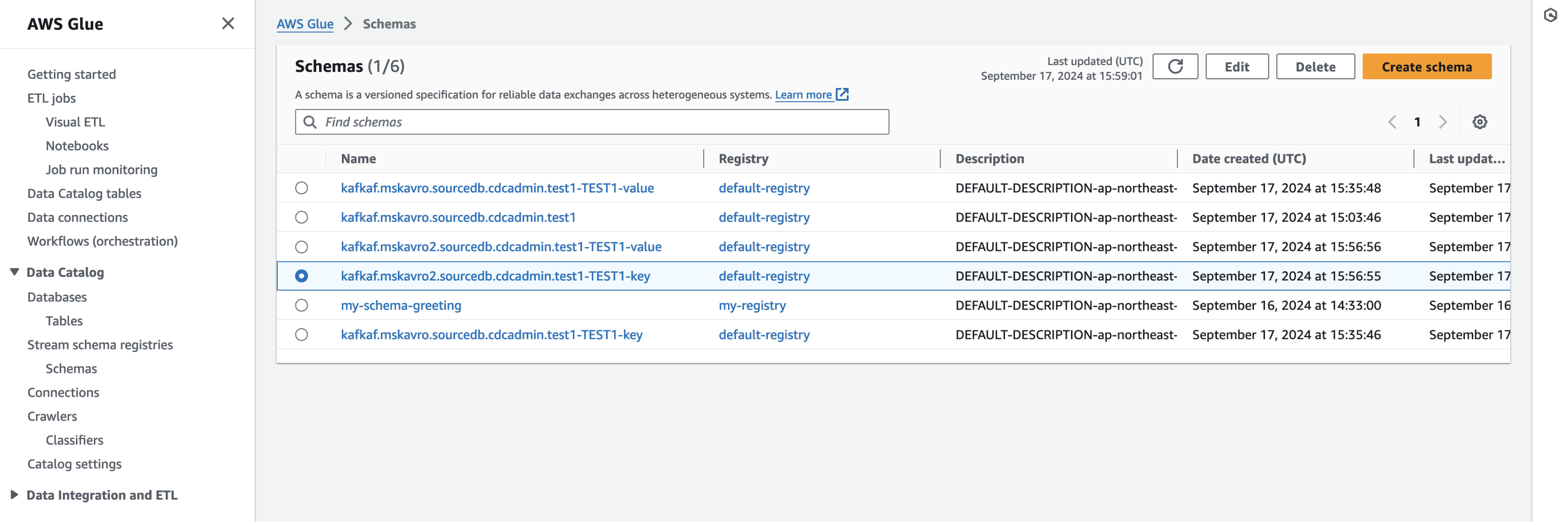
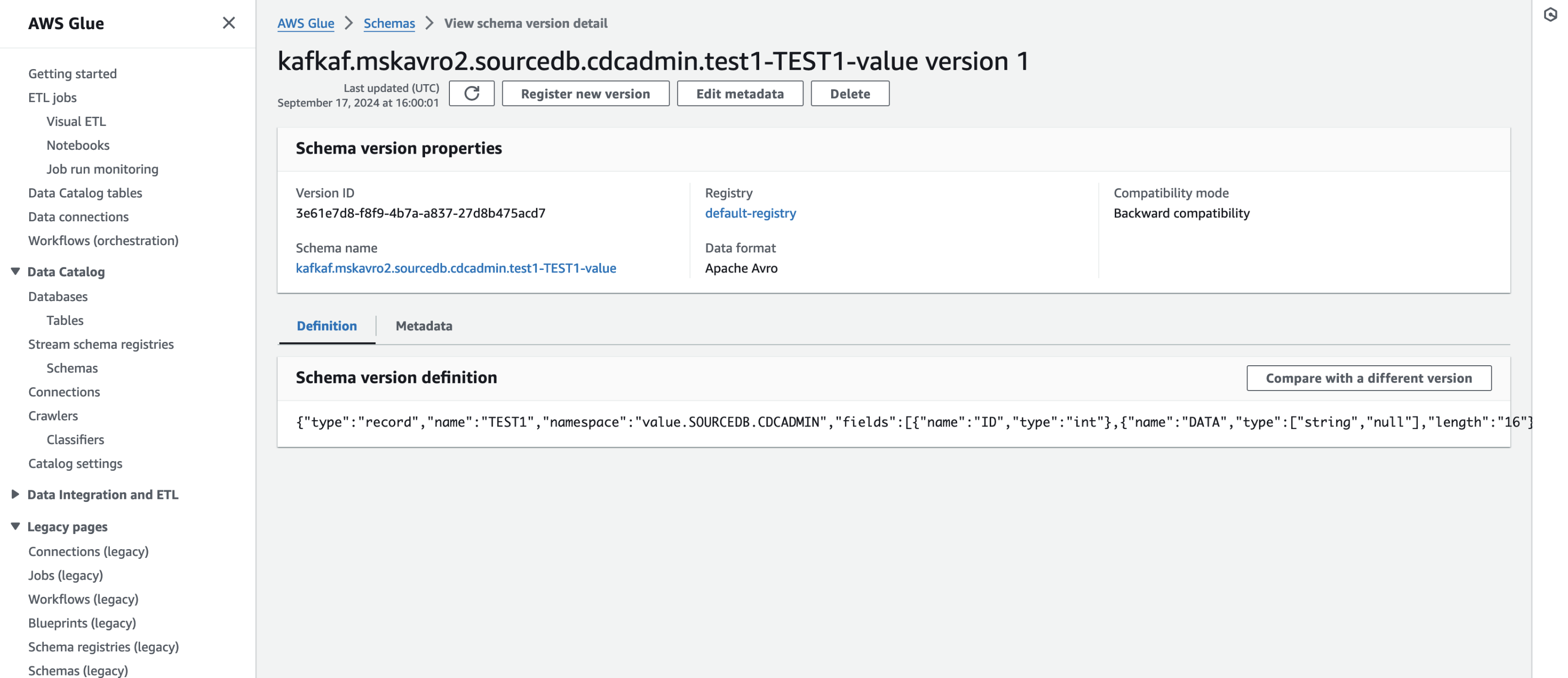
AWS Glue Schema Registryでスキーマを確認
トピック名-スキーマ名(スキーマ内のname)-key と
トピック名-スキーマ名(スキーマ内のname)-value という名前で登録されています。



おわりに
ここで紹介した内容を参考にすることで、データベースにあるデータ更新の都度、その変更内容をAmazon MSKに伝えることができます。
これにより、Amazon MSKを利用したイベントドリブンなユースケースの実装や高鮮度データを分析を実現できるようになります。
以下は、ここまでに説明した内容です。
- ① Amazon MSKのクラスターを構築する(→Amazon MSKでオンプレから接続可能なKafkaクラスターの構築方法(できるだけ普通のKafkaっぽく使えるように))
- ② AWS外からJavaプログラムを使用して以下を実施(→Amazon MSKのKafkaクラスターにJavaプログラムでProduce/Consume(String形式&Avro形式))
- シンプルな文字列形式のメッセージのProduce/Consume
- AWS Glue Schema Registryの設定
- Avro形式のメッセージのProduce/Consume
- ③ AWS外からIBM Infosphere Replication CDCを使用して以下を実施(本稿で紹介)
- JSON形式でキャプチャー対象テーブルのデータをAmazon MSKに送信
- Avro形式でキャプチャー対象テーブルのデータをAmazon MSKに送信