なんか「Apache Arrow が良いらしいよ。」と聞いたので、早速かまってみた。
Apache Arrowってなに?
データを言語(プロジェクト)間でやり取りするときの効率化と高速化を目指すものっぽいです(ざっくり。本当は違うかも)
→ https://www.slideshare.net/MapR_Japan/apache-arrow-value-vectors-tokyo-apache-drill-meetup-20160322
そういえば、最近かかわったプロジェクトで、Ruby でデータを揃えて、 Python で機械学習する、っていうのがありまして、その時は Ruby 側で揃えたデータをファイルに書き出して、Python 側でそのファイルを読み込んで処理して、結果をファイルに書き出して、Ruby 側で読み込んで Javascript(ブラウザ)でグラフ化する、ということをしていました。
こういうところで使えそう?
ということで、ちょっとやってみます。
Ruby で Apache Arrow
gemにあるのでインストールします。
source "https://rubygems.org"
gem "rake"
gem "red-arrow"
$ bundle install --path vendor/bundler
インストール完了です。
早速使ってみましょう。
# -*- coding: utf-8 -*-
require "arrow"
class RedArrowTest
# ------------------------------------------------
def read(streamname)
input = Arrow::MemoryMappedInputStream
input.open(streamname) do |inp|
reader = Arrow::RecordBatchStreamReader.new(inp)
fields = reader.schema.fields
p "fields: #{fields.collect{|c| c.name }}"
reader.each do |r|
p [r]
end
end
end
def readfile(filename)
input = Arrow::MemoryMappedInputStream
input.open(filename) do |inp|
reader = Arrow::RecordBatchFileReader.new(inp)
fields = reader.schema.fields
p "fileds: #{fields.collect{|c| c.name }}"
reader.each do |r|
p [r]
end
end
end
# ------------------------------------------------
def write(streamname, schema, columns)
output = Arrow::FileOutputStream
output.open(streamname, false) do |oup|
writer = Arrow::RecordBatchStreamWriter.open(oup, schema) do |wrt|
recordbatch = Arrow::RecordBatch.new(schema, columns[0].count, columns)
wrt.write_record_batch(recordbatch)
end
end
end
def writefile(filename, schema, columns)
output = Arrow::FileOutputStream
output.open(filename, false) do |oup|
writer = Arrow::RecordBatchFileWriter.open(oup, schema) do |wrt|
recordbatch = Arrow::RecordBatch.new(schema, columns[0].count, columns)
wrt.write_record_batch(recordbatch)
end
end
end
# ------------------------------------------------
# sample data
def createdata
fields = [ Arrow::Field.new("name", :string),
Arrow::Field.new("age", :int8) ]
schema = Arrow::Schema.new(fields)
names = ["taro", "jiro", "hanako", "tsukiko", "saburo"]
ages = [26, 21, 24, 17, 10]
columns = [ Arrow::StringArray.new(names),
Arrow::Int8Array.new(ages) ]
return schema, columns
end
end
# ----------------------------------------------------------------
# run
ra = RedArrowTest.new
# create sample data :p
schema, columns = ra.createdata
ra.write("hoge", schema, columns)
ra.read("hoge")
# ra.writefile("hoge", schema, columns)
# ra.readfile("hoge")
どうやらファイル経由のものとメモリ経由のものがあるようです。
→ read、write がメモリ経由、readfile、writefile がファイル経由
#がしかし、いずれもファイルを生成するんだなぁこれが。。。
#内容はちょっと違うみたいだけど、、、とりあえずメモリ経由のものを使いましょう。
では実行。
$ bundle exec ruby test.rb
"fields: [\"name\", \"age\"]"
[#<Arrow::RecordBatch:0x7feaf2057500 ptr=0x7feaf30f0f90 name: [
"taro",
"jiro",
"hanako",
"tsukiko",
"saburo"
]
age: [
26,
21,
24,
17,
10
]
>]
できました。
実体は、カレントディレクトリに hoge ファイルができててそれみたいです。
Javascript で Apache Arrow
言語間でデータのやりとりができるということだったので、Ruby で作ったデータを Javascript で読み込んでみます。
Node.js って
Javascript でも使えるって書いてあったから、ブラウザサイドでもちゃちゃっと使えるんだと思ってましたが、どうやら全然違ったようです。
とりあえず Node.js をインストールします。
うちは Mac なので Homebrew でインストールします。
Node.js の各種パッケージなどを管理する nodebrew というものがあるらしく、それをインストールして Apache Arrow をインストールします。
$ brew install nodebrew
$ mkdir -p ~/.nodebrew/src
$ nodebrew install-binary latest ← nodebrew install latest でもいいらしい。
install-binary はバイナリをインストール。install はソースからインストールらしい。。
$ nodebrew list
v11.1.0
current: none
はい、インストールできました。
しかしこのままでは使えないので、設定します。
$ nodebrew use 11.1.0
use v11.1.0
~/.bash_profile にパスを追加
# Node.js
export PATH="$HOME/.nodebrew/current/bin:$PATH"
とりあえず以上で Node.js がインストールできました
ブラウザサイドでも使用できるようにしてみる
いろいろネットで探してみましたが、やはり直接ブラウザサイドで使用する方法は見つかりませんでした。代わりに、Node.js でサーバを立てて、jQuery でそのサーバにアクセスする、という方法でデータを渡している人が居られましたので、その方法を真似てみることにしました。
express で HTTPサーバ
Node.js のパッケージを使うコマンドは npm と言うようです。これを使って各種パッケージをインストールします。
どうやら、カレントディレクトリに node_modules というフォルダを作って、その中に関係するファイルを保存するっぽいです。
なので、とりあえずプロジェクトのフォルダに移動してからインストールします。
$ cd appfolder
$ npm install express
Apache Arrow もインストールしましょう。
$ npm install apache-arrow
サーバを作る
"use strict"
// apache-arrow service :p
const express = require("express");
const port = 8010;
const app = express();
app.use(express.static("./public"));
// allow CrossSiteScript
app.use(function(req, res, next) {
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Headers", "Origin, X-Requested-With, Content-Type, Accept");
next();
});
// say hello
app.get("/", (req, res) => {
res.send("Hello, world!");
});
// arrow
app.get("/input", (req, res) => {
const fs = require("fs");
const aa = require("apache-arrow");
const path = "./";
const encoding = "binary";
var filename = req.query.n;
//console.log("filename: " + filename);
// result data
var result = {};
if(filename != undefined){
try {
var adata = fs.readFileSync(path + filename);
var table = aa.Table.from([adata]);
var schema = table.schema;
var fldnames = new Array();
for(var i = 0; i < schema.fields.length; i++){
fldnames.push(schema.fields[i].name);
result[schema.fields[i].name] = new Array();
}
for(var j = 0; j < fldnames.length; j++){
var column = table.getColumn(fldnames[j]);
for(var i = 0; i < column.length; i++){
result[fldnames[j]].push(column.get(i));
//console.log(column.get(i));
}
}
} catch(ex){
// nop :p
}
}
res.json(result);
});
// run service!
app.listen(port);
では走らせます。
$ node arrow_service.js
とりあえずブラウザでアクセスしてみましょう。
ブラウザで http://localhost:8010/ にアクセスして Hello, world! が表示されれば成功です。
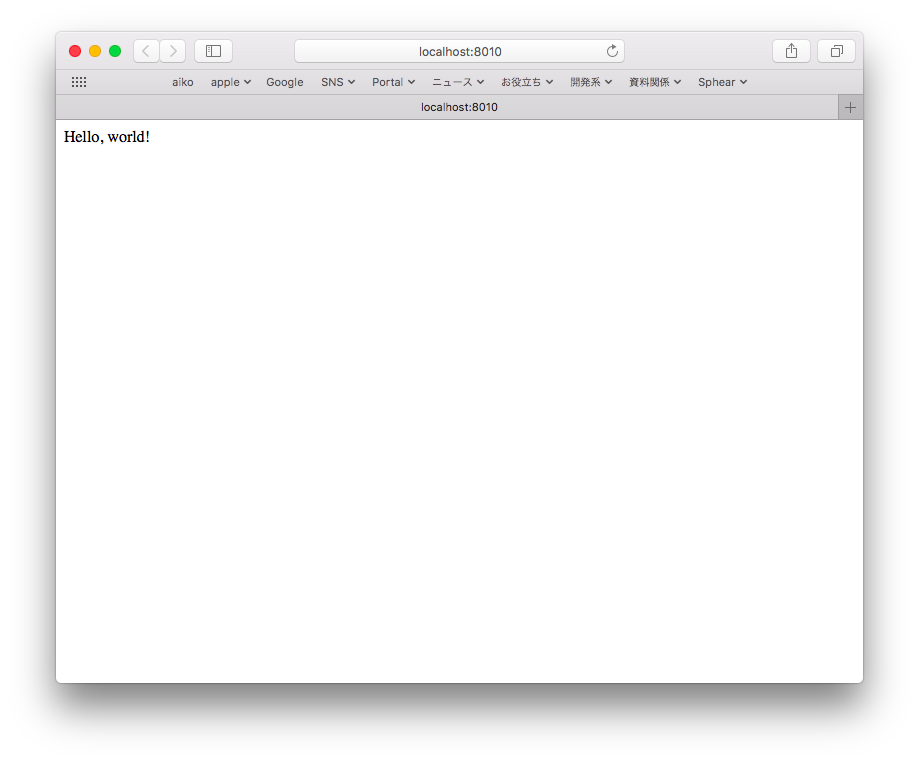
動いてますね。
では、ブラウザ側を作りましょう。
Ajaxでアクセス
jQuery を使ってアクセスをします。
とりあえず、application.js に関数を作ります。
function arrowInput(arrowname) {
var result;
$.ajax({ type: "GET",
url: "http://localhost:8010/input",
data: { n: arrowname },
async: false,
dataType: "json",
success: function(data){
result = data;
}
});
return result;
}
今回 Ajax ですが非同期ではなく同期にしました。
ここら辺はプロジェクトに合わせてごにょごにょしてみてください。
では html 側を作ります。
<html>
<head>
<title>Red Arrow Test</title>
<script type="text/javascript" src="/javascripts/jquery-3.2.1.min.js"></script>
<script type="text/javascript" src="/javascripts/application.js"></script>
</head>
<body>
<h3>Red Arrow Test</h3>
<script type="text/javascript">
var data = arrowInput("hoge");
console.log(data);
</script>
</body>
</html>
では実行してみましょう。
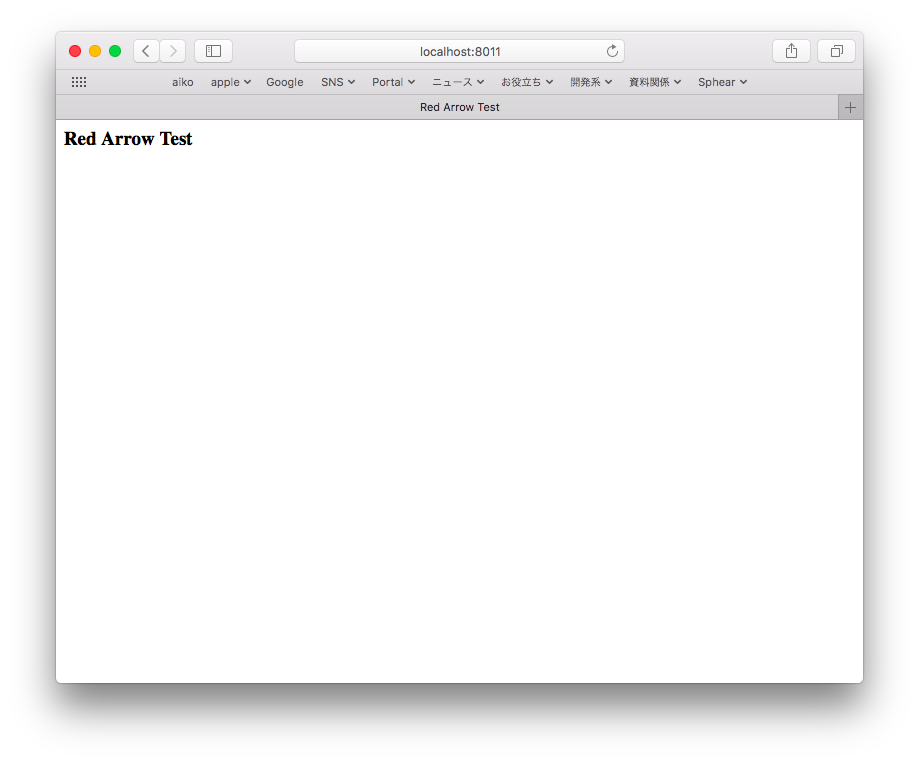
ブラウザ画面だと console.log が見れないので、右ボタン「要素の詳細を表示」でツール窓をだして、リロードすると、コンソール画面に取得した内容が表示されているはずです。
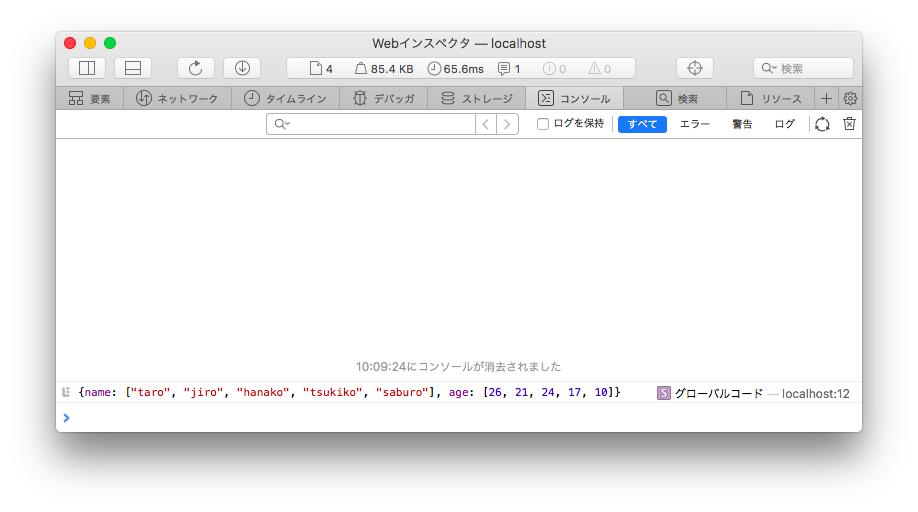
お、なんか良さげですね。
まとめ
以上で、Apache Arrow を使って Ruby で作成したデータを Javascript(ブラウザサイド) で取得することができました。
まあ本当にこういう使い方なのかはわかりませんが、確かにデータのやり取りは楽になったような気がします。もう少しかまってみようと思います。
#しかし、これ、要らなくなったデータを消すタイミング(ガベージコレクション)ってどうなんでしょうね? 手動っぽいですけど。。。
追加修正
上記Rubyプログラムの readメソッド を修正してみました。
また、Arrow 形式のデータに変換するメソッドも作成したので追加しておきます。
読み込んだデータをハッシュで返すように修正しました。
class RedArrowTest
def read(streamname)
result = Hash.new
input = Arrow::MemoryMappedInputStream
input.open(streamname) do |inp|
reader = Arrow::RecordBatchStreamReader.new(inp)
fields = reader.schema.fields
reader.each do |r|
fields.each do |fld|
result[fld.name] = Array.new if result[fld.name].nil?
result[fld.name] += r.send(fld.name).collect{|c| c}
end
end
end
return result
end
end
実行結果は以下。
$ bundle exec ruby test.rb
{"name"=>["taro", "jiro", "hanako", "tsukiko", "saburo"], "age"=>[26, 21, 24, 17, 10]}
次にハッシュデータからArrow形式のデータを作るメソッドです。
class RedArrowTest
# data -> { fieldname1 => Array, fieldname2 => Array, ... }
def create_arrow_data(data)
fldnames = data.keys
fldtypes = Array.new
fldnames.each do |fname|
v = data[fname][0]
case v.class.to_s
when "Integer"
ma = data[fname].max
mi = data[fname].min
ftype = :int64
if (mi >= 0 && ma <= 0xffffffff) ||
(mi >= (0x8000000 * -1) && ma <= 0x7fffffff)
ftype = :int32
end
if (mi >= 0 && ma <= 0xffff) || (mi >= (0x8000 * -1) && ma <= 0x7fff)
ftype = :int16
end
if (mi >= 0 && ma <= 0xff) || (mi >= (0x80 * -1) && ma <= 0x7f)
ftype = :int8
end
when "Date"
ftype = :date32
when "Time", "DateTime"
ftype = :timestamp
when "Float"
ftype = :float
when "TrueClass", "FalseClass"
ftype = :boolean
else
ftype = :string
end
fldtypes.push(ftype)
end
# create schema & columns
fields = Array.new
columns = Array.new
fldnames.each_with_index do |fname, i|
if fldtypes[i] == :timestamp
fields.push(Arrow::Field.new(fname.to_s,
Arrow::TimestampDataType.new(:second)))
obj = eval("Arrow::#{fldtypes[i].to_s.to_camel}Array.new(:second, data[fname])")
else
fields.push(Arrow::Field.new(fname.to_s, fldtypes[i]))
obj = eval("Arrow::#{fldtypes[i].to_s.to_camel}Array.new(data[fname])")
end
columns.push(obj)
end
schema = Arrow::Schema.new(fields)
return schema, columns
end
end
実行結果は以下。
# 以下のように修正してね。
ra = RedArrowTest.new
data = { :string => ["taro", "jiro", "saburo"],
:integer => [24, 21, 100024],
:time => [Time.now, Time.now, Time.now],
:date => [Date.new(2018, 11, 6), Date.new(2018, 11, 7), Date.new],
:float => [12.0, 23.2, 100024.23],
:boolean => [true, false, false]
}
schema, columns = ra.create_arrow_data(data)
ra.write("tara", schema, columns)
p ra.read("tara")
$ bundle exec ruby test.rb
{"string"=>["taro", "jiro", "saburo"], "integer"=>[24, 21, 100024], "time"=>[2018-11-07 09:34:41 +0900, 2018-11-07 09:34:41 +0900, 2018-11-07 09:34:41 +0900], "date"=>[#<Date: 2018-11-06 ((2458429j,0s,0n),+0s,2299161j)>, #<Date: 2018-11-07 ((2458430j,0s,0n),+0s,2299161j)>, #<Date: -4712-01-01 ((0j,0s,0n),+0s,2299161j)>], "float"=>[12.0, 23.200000762939453, 100024.2265625], "boolean"=>[true, false, false]}
良さげなかんじですね。
一応 Javascript(ブラウザサイド)でも確認してみましょう。
<h3>Red Arrow Test</h3>
<script type="text/javascript">
var data = arrowInput("tara"); ← tara に変更
console.log(data);
</script>
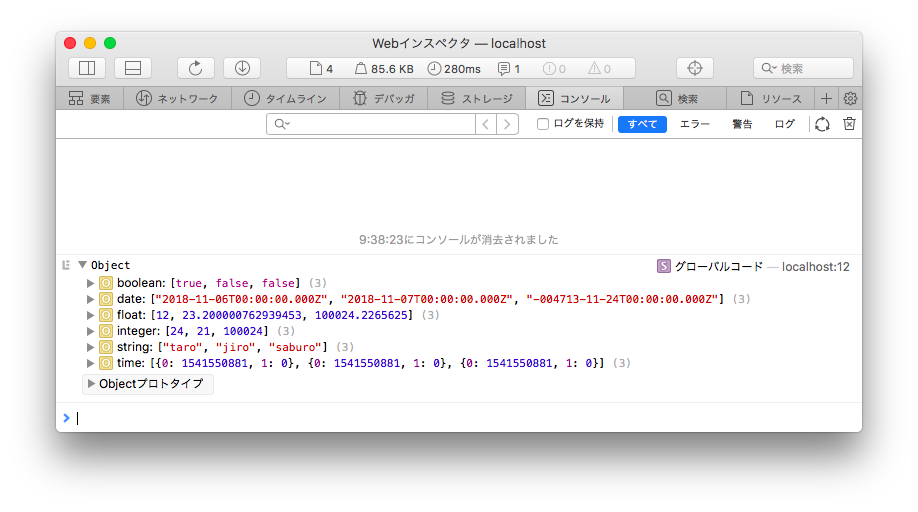
いけますねー。
とりあえず以上です。