はじめに
先日OllamaというローカルファーストなLLMサーバライブラリを教えてもらいました。
今回はOllamaをローカルに構築して、Neovimからプロンプト操作するための構築をご紹介します!
エディタの使い勝手が悪いという理由でCursorを使ってない方(筆者含む)、ぜひ試してみてください!!
↓構築後のイメージ

0. Requirements
- mac
- 本記事の内容がmac向けという意味で、mac以外でも構築自体は可能です
- メモリ16GB以上ないとキツイかもです
- homebrew
- Neovim
- version不問ですが筆者は
v0.10.0でした - パッケージマネージャも不問ですが筆者はlazy使ってます
- version不問ですが筆者は
1. Ollamaのinstall
brewで一発です
brew install ollama
install直後にollama -vなどと実行しても以下のようにエラーになりますが、次の手順で実行するollama serveが必要なだけなので問題ないです。
❯ ollama -v
Warning: could not connect to a running Ollama instance
Warning: client version is 0.3.8
2. modelの実行
後述するNeovimのプラグインではMistralというモデルを使用する必要があるため、Mistralを走らせます。1
nohup ollama serve &!
ollama run mistral
ollama serveと実行すると標準入力が奪われる感じになって面倒なのでバックグラウンド実行します
モデルのファイルサイズが5GBほどあるのでrunに少し時間かかります
3. ollama.nvimのinstall
今回は以下をinstallします
筆者はlazyを使っているので、READEMEに記載されたコードをコピペします(keymapだけ筆者の好みに直してます)。
return {
"nomnivore/ollama.nvim",
dependencies = {
"nvim-lua/plenary.nvim",
},
-- All the user commands added by the plugin
cmd = { "Ollama", "OllamaModel", "OllamaServe", "OllamaServeStop" },
keys = {
-- Sample keybind for prompt menu. Note that the <c-u> is important for selections to work properly.
{
"<leader>oo",
":<c-u>lua require('ollama').prompt()<cr>",
desc = "ollama prompt",
mode = { "n", "v" },
},
-- Sample keybind for direct prompting. Note that the <c-u> is important for selections to work properly.
{
"<leader>og",
":<c-u>lua require('ollama').prompt('Generate_Code')<cr>",
desc = "ollama Generate Code",
mode = { "n", "v" },
},
{
"<leader>os",
"<CMD>OllamaServe<CR>",
desc = "ollama serve",
mode = { "n", "v" },
},
},
---@type Ollama.Config
opts = {
-- your configuration overrides
},
}
その後Neovimを開き直すなりしてollama.nvimのinstallを完了させてください。
完了させると、<leader>oo, <leader>oG, <leader>osなどのkeymapが使えるようになっていると思います。
構築は以上で完了です!!![]()
4. 使ってみる
適当なpyファイルをカレントバッファに開いた状態で、<leader>oo実行してみます。
すると以下のようなプロンプトが開きます
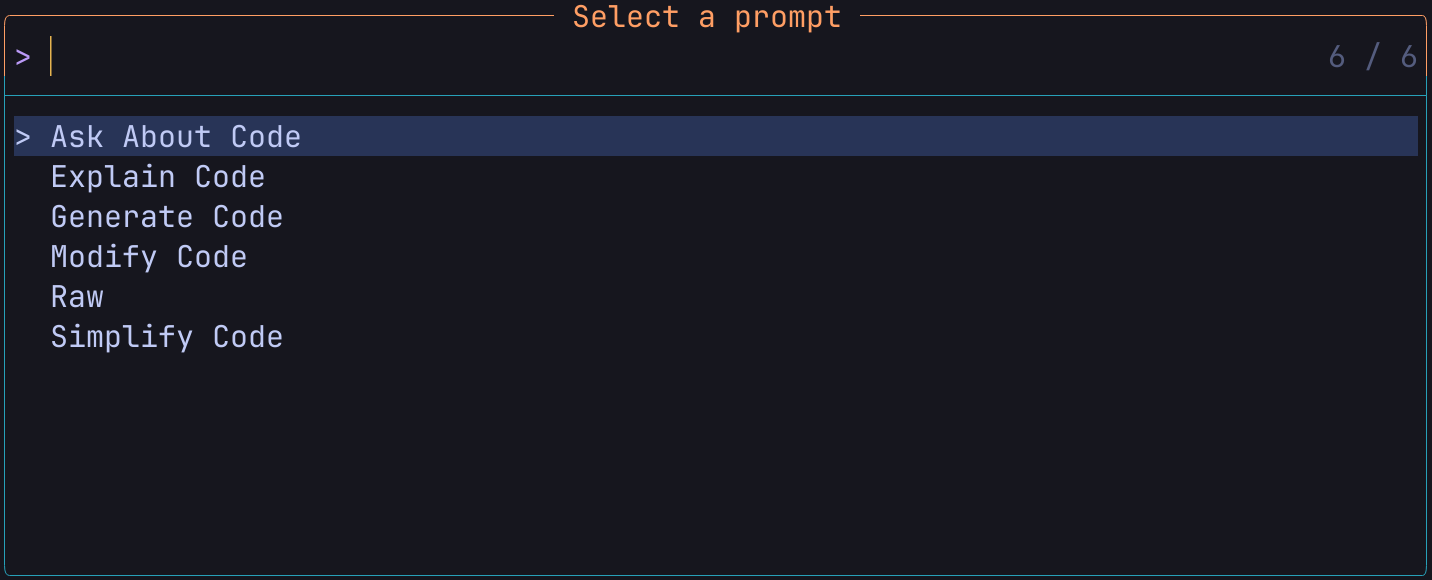
CopilotやCursorを使っている方ならお察しかと思いますが、コードの解説や生成を要求できたり、コードは関係なく単純にモデルに対してプロンプトを発行できたりします。
試しにGenerate Codeを選択して、LambdaHandlerのサンプルを作ってもらいましょう。
Generate Codeを選択すると、プロンプトが開くのでsample lambda layerと打ち込みます。
なおコードの生成プロンプトは<leader>ogのkeymapからすぐ呼び出せます
少し待つと以下のコードがカレントバッファに出力されます。
import json
from aws_lambda_lib.event import API Gateway Proxy Event, Context
def lambda_handler(proxy_event: API Gateway ProxyEvent, context: Context):
body = proxy_event.get("body")
if body is None or not isinstance(body, str):
return {
"statusCode": 400,
"headers": {"Content-Type": "text/plain"},
"body": "Error: Missing or invalid request body"
}
data = json.loads(body)
# Process the data here as per your requirements
# For demonstration purposes, let's simply echo the input
response_data = {
**data,
"response": f"Echo: {json.dumps(data)}"
}
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps(response_data)
}
では次に生成してもらったコードの解説をしてもらいます。
コードを全選択して、<leader>ooからExplain Codeを選択します。
するとこんな感じで選択したコードがプロンプトに自動入力されて回答が生成されます。
なおよく見てもらうとわかると思うのですが生成に82秒かかっているのは実行しているPCのスペックが低いからです。。。
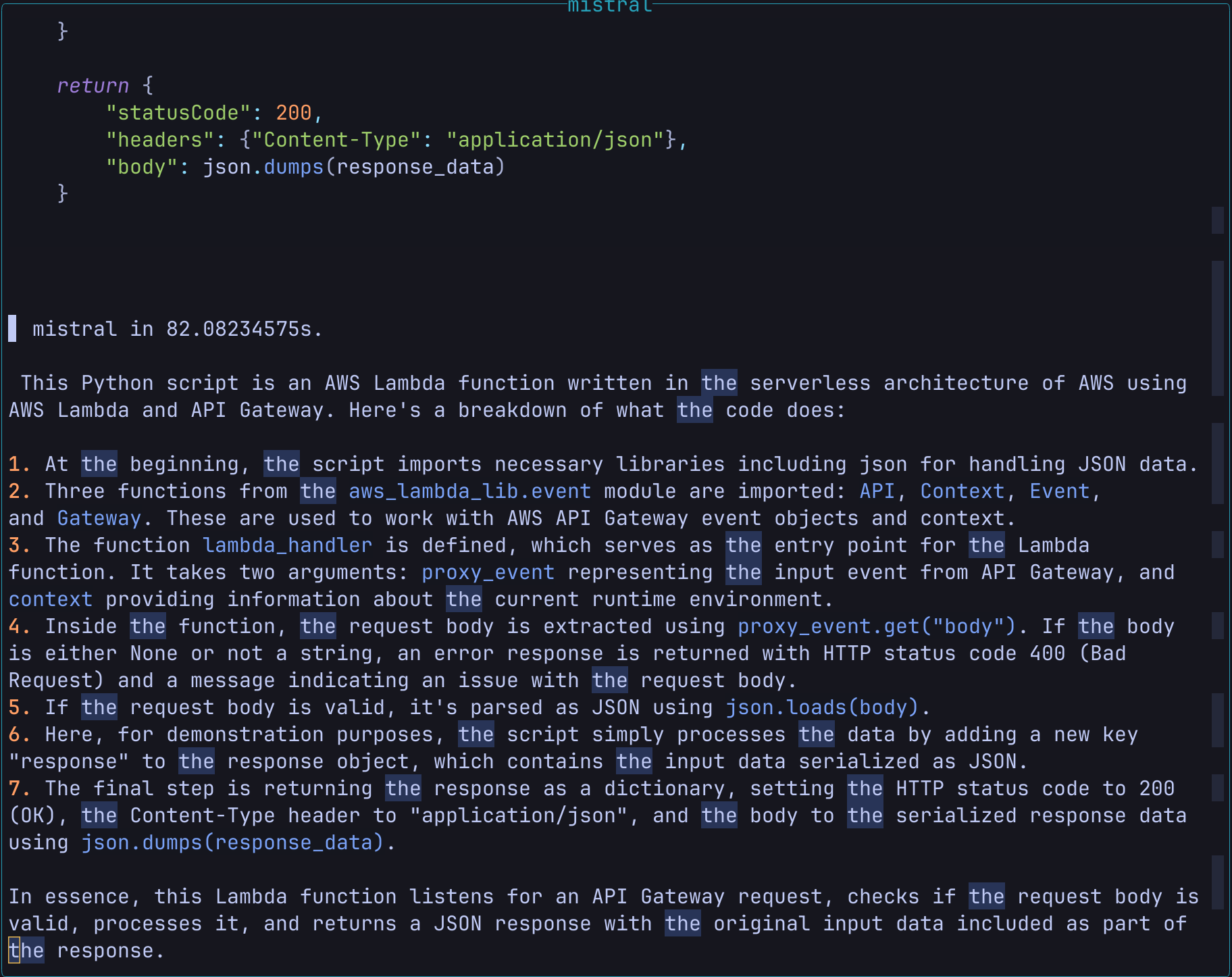
こんな感じでカレントバッファとOllamaとでインタラクティブなやり取りを行えます!!便利!!
最後に
構築してみた感想としては
- やっぱりローカルファーストのLLMって便利
- chatGPTのプラグインとかだとトークン代が気になって消極的だったけどそれが気にならないのはありがたい
- とはいえそれなりのスペックは要求される(いうても開発用PC程度あれば十分そう)から私用PCとかで気軽に動かすとバカ重かった
- Ollama自体に日本語対応モデルはあるぽいけど、neovimのプラグイン側が対応してないっぽい?ので日本人からするとそこがちょっと使いにくいかも
て感じでした!興味のある方ぜひ使ってみてください!
それでは、良いvimライフを!!
-
Ollamaで実行可能なモデルリスト
https://ollama.com/library ↩