はじめに
本記事はGoogleが公開したデータセットFACTSについて紹介するものです。
以下のコンテンツを含んでいます。
- FACTSのペーパーの紹介
- FACTSリーダーボードの紹介
- FACTSデータセットのサンプルの紹介
FACTSのペーパーの紹介
概要
論文では、LLMがユーザープロンプトで与えられた文脈に対して、事実に基づいた正確なテキストを生成する能力を評価する、オンラインリーダーボードと関連するベンチマークであるFACTS Groundingが導入されています。このベンチマークでは、各プロンプトにはユーザーのリクエストと全文(最大32kトークン)が含まれており、長文の応答が求められます。長文の応答は、ユーザーのリクエストを満たしながら、提供された文脈ドキュメントに完全に根拠づけられている必要があります。モデルは、2段階の自動判定モデルを使用して評価されます。
(1)応答がユーザーのリクエストを満たしていない場合は失格となります。
(2)応答が提供されたドキュメントに完全に根拠づけられている場合、正確であると判定されます。
自動判定モデルは、最適なプロンプトテンプレートを選択するために、ホールドアウトされたテストセットに対して包括的に評価され、最終的な事実性スコアは、評価の偏りを軽減するために複数の判定モデルの集計となっています。FACTS Groundingリーダーボードは、継続的に維持され、リーダーボードの完全性を維持しながら、外部からの参加を可能にするために、公開スプリットと非公開スプリットの両方を含んでいます。
重要なポイント
- 事実性(Factuality)の重要性: LLMにおいて、事実に基づいた正確さは最も重要な課題の一つです。これは、情報検索のシナリオで、モデルが事実に基づいた正確な応答を生成する能力を指します。
- 文脈に基づいた事実性: この論文では、特に「与えられた文脈(ユーザーリクエストと根拠となるドキュメントなど)に対する事実性」に焦点を当てています。これは、モデルの応答が入力に完全に根拠づけられていることを意味します。
- 長文生成の課題: 長文生成タスクでは、モデルの応答に含まれるすべての主張が正確かどうかを徹底的に検証する必要があります。これは、短い応答の事実性を測定するタスクとは対照的です。
- FACTS Groundingの設計: FACTS Groundingは、最大32kトークンのドキュメント文脈に基づいて、多様なユーザーリクエストに対する応答の事実性を測定するように設計されています。これには、要約だけでなく、事実調査、情報分析と比較なども含まれます。
- 自動評価の課題と対策: 長文応答の事実性を大規模に測定することは困難であり、特に自動評価方法は依然として課題となっています。この論文では、自動評価器を厳密に評価し、複数の集計を使用して評価者の偏りを軽減しています。
- 不適格な応答の除外: 事実性評価に焦点を当てた指標は、ユーザーリクエストの意図を無視することで回避される可能性があります。包括的な情報伝達を避ける短い応答をすることで、役立つ応答を提供していなくても高い事実性スコアを達成することが可能です。FACTS Groundingでは、このような応答を検出し、除外することで対策を講じています。
ペーパーのまとめ
FACTS Groundingリーダーボードは、プロンプト内で提供されたドキュメントに根拠づけられた長文応答を生成する際に、事実の正確性を維持するLLMの能力を厳密に評価するように設計されています。このベンチマークは、モデルの事実能力と事実性を評価するための方法論の両方を向上させるために、他の研究者が活用することを推奨しています。
FACTSリーダーボードの紹介
包括的なベンチマークとオンラインリーダーボードは、LLMが提供されたソース資料にどれだけ正確に回答を基づかせているか、また、どれだけ幻覚(事実に基づかない情報生成)を回避しているかを測る、非常に必要とされている指標を提供します。
大規模言語モデル(LLM)は、情報へのアクセス方法を変革していますが、事実の正確性への対応はまだ不完全です。特に複雑な入力が与えられた場合、「幻覚」を起こし、誤った情報を生成することがあります。これは、LLMへの信頼を損ない、現実世界での応用を制限する可能性があります。
「FACTS Grounding」は、与えられた入力に対して事実上正確であるだけでなく、ユーザーの質問に十分に満足のいく回答を提供できるほど詳細な応答を生成するLLMの能力を評価するための包括的なベンチマークです。
このベンチマークが、事実性と根拠付けに関する業界全体の進歩を促進することを願っています。進捗状況を追跡するために、KaggleでFACTSリーダーボードも公開します。私たちはすでにFACTS Groundingを使用して主要なLLMをテストし、初期のリーダーボードにそれらの根拠付けスコアを入力しました。この分野の進歩に合わせて、リーダーボードを維持し、更新していきます。
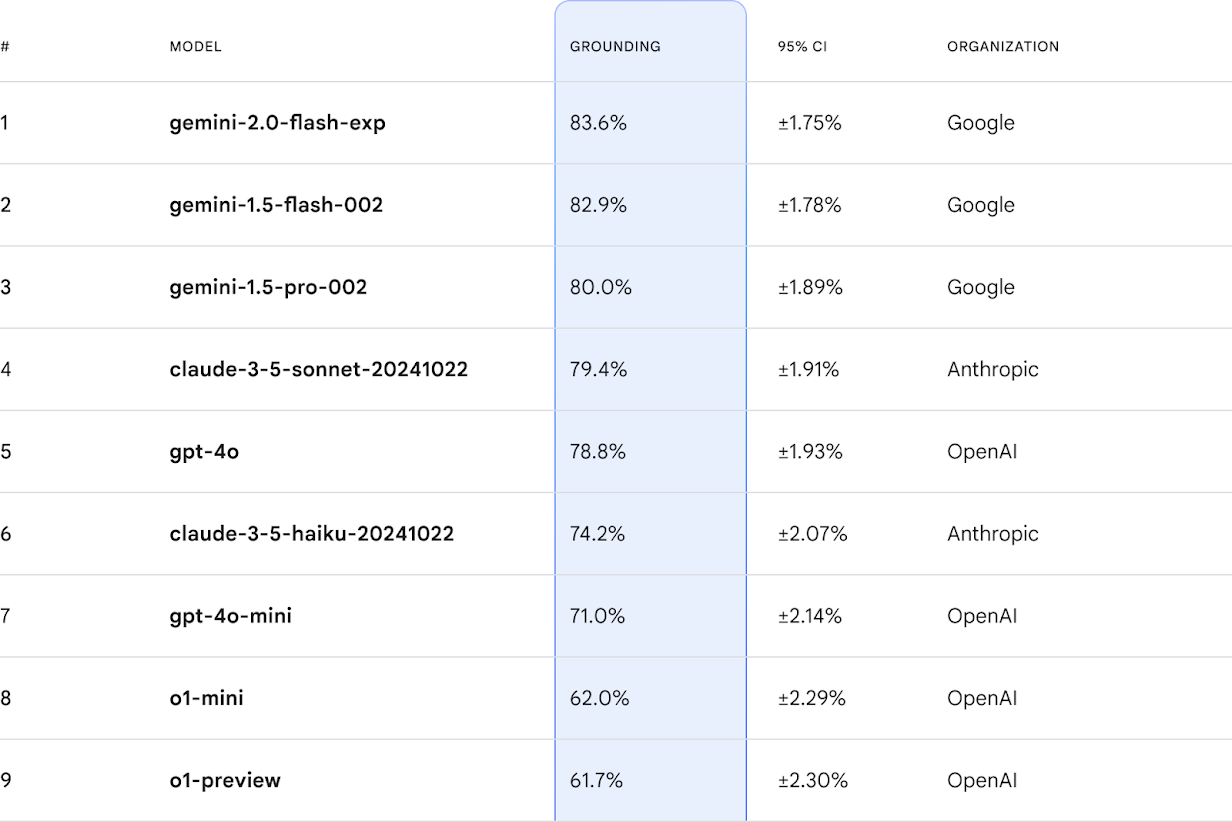
FACTS Groundingデータセット
任意のLLMの事実性と根拠付けを正確に評価するために、FACTS Groundingデータセットは1,719個の例で構成されており、それぞれが提供されたコンテキストドキュメントに根拠を置いた長文の応答を必要とするように注意深く作成されています。各例は、ドキュメント、LLMに提供されたドキュメントのみを参照するように要求するシステム命令、および付随するユーザーリクエストで構成されています。
すべての例は、「公開」セット(860個)と「非公開」(859個)の保留セットに分けられています。本日、「公開」セットを公開し、誰でもLLMの評価に使用できるようにします。もちろん、ベンチマークの汚染やリーダーボードの不正操作の問題が重要なことは認識しているため、業界の標準的な慣例に従い、非公開の評価セットは保留しています。FACTSリーダーボードのスコアは、公開セットと非公開セットの両方における平均パフォーマンスです。
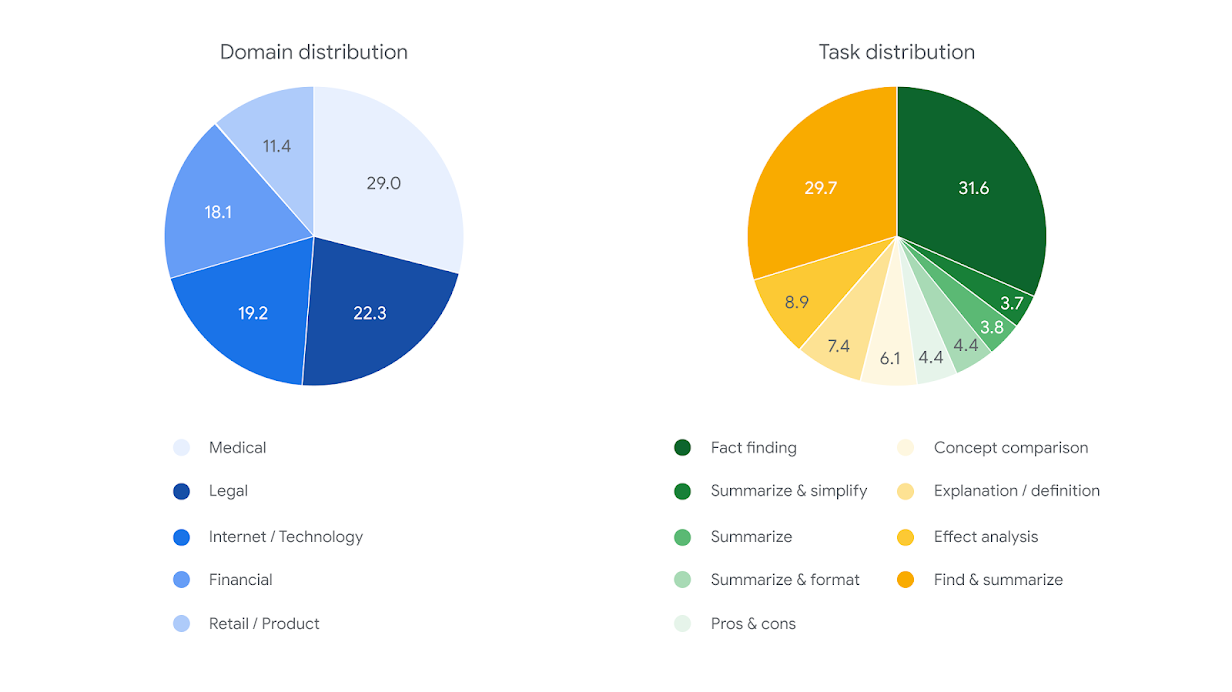
入力の多様性を確保するために、FACTS Groundingの例には、最大32,000トークン(約20,000語)のさまざまな長さのドキュメントが含まれており、金融、テクノロジー、小売、医療、法律などの分野を網羅しています。ユーザーリクエストも同様に多岐にわたり、要約、Q&A生成、書き換えタスクなどのリクエストが含まれます。創造性、数学、または複雑な推論を必要とする可能性のある例は含めませんでした。これらの能力は、モデルが根拠付けに加えて、より高度な推論を適用することを必要とする可能性があるためです。
主要なLLMによる集団的判断
特定の例で成功するためには、LLMはドキュメント内の複雑な情報を統合し、ユーザーリクエストへの包括的な回答であり、そのドキュメントに完全に起因する長文の応答を生成する必要があります。
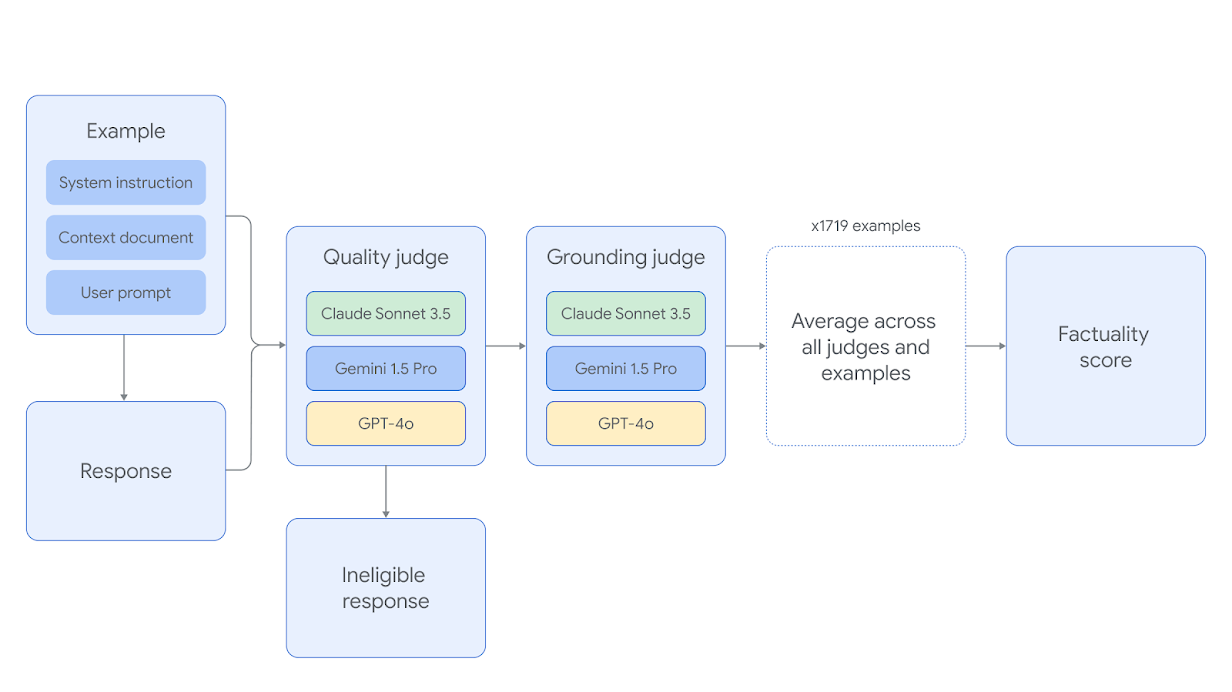
FACTS Groundingは、Gemini 1.5 Pro、GPT-4o、Claude 3.5 Sonnetという3つの最先端のLLMジャッジを使用して、モデルの応答を自動的に評価します。ジャッジが自身のモデルファミリーのメンバーによって生成された応答に高いスコアを与える可能性のある潜在的なバイアスを軽減するために、異なるジャッジの組み合わせを選択しました。自動ジャッジモデルは、最適なジャッジプロンプトテンプレートを見つけ、人間の評価者との一致を確認するために、保留されたテストセットに対して包括的に評価されました。
各FACTS Groundingの例は、2つのフェーズで判断されます。まず、応答が適格性について評価され、ユーザーのリクエストに十分に対応していない場合は失格となります。次に、応答が、提供されたドキュメントに含まれる情報に完全に根拠があり、幻覚がない場合、事実上正確であると判断されます。
複数のAIジャッジモデルによって個別に評価された特定のLLM応答の適格性と根拠付けの精度により、結果が集約され、LLMが例に正常に対処したかどうかが判断されます。全体的な根拠付けタスクの最終スコアは、すべての例におけるすべてのジャッジモデルのスコアの平均です。FACTS Groundingの評価方法の詳細については、論文をご覧ください。
FACTSデータセットのサンプルの紹介
ACTS Groundingベンチマークは、大規模言語モデル(LLM)が与えられた文脈に根拠を置いた応答を生成する能力を測定します。例えば、要約されたソース資料に対して正確な要約の生成などです。
このベンチマークには、1,719個の根拠付けの例が含まれています。これらの例の公開されているサブセットは、FACTS Grounding公開例データセットでアクセスできます。
ステップ1:応答生成
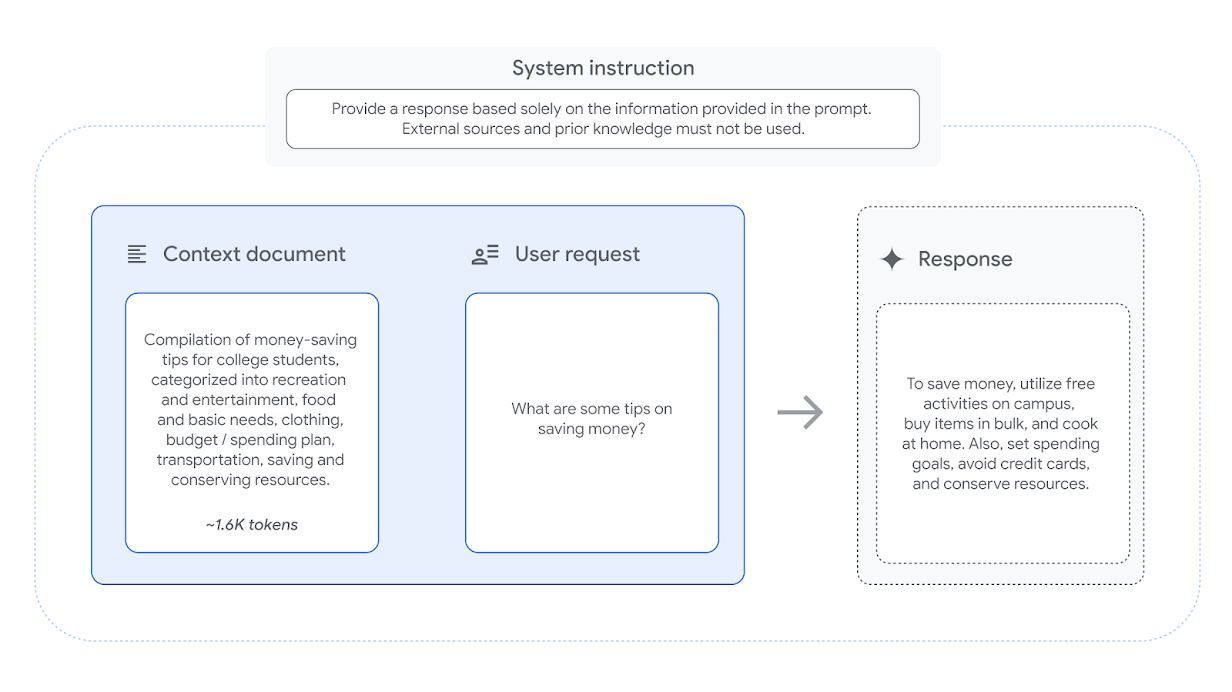
各例には、システム命令、ユーザーリクエスト、および文脈文書が含まれています。評価対象のモデルは、この情報のみに基づいて応答を生成するよう求められます。これにより、各モデルに対して1,719個の応答が生成されます。
- システム命令:文脈で提供されている情報のみを使用して質問に答えてください。外部の知識やソースに依存しないでください。
- ユーザーリクエスト:提供されたテキストで説明されている医学研究の文脈において、「ネオアンチゲン」はどのようなタスク(またはタスク群)を持っていますか?
- 文脈文書:ミスマッチ修復欠損症は、腫瘍細胞が通常DNAコードの誤りを修正するいくつかの遺伝子のいずれかに変異を持っている場合に発生します。[...]いくつかの変異は、腫瘍細胞が表面にネオアンチゲンと呼ばれる異常なタンパク質の一部を生成する原因となります。ネオアンチゲンは免疫系が癌細胞を発見するのに役立ちますが、他の種類の変異は免疫系を活性化する可能性が低いです。癌細胞のすべてが同じネオアンチゲン(クローン性ネオアンチゲンと呼ばれる)を持っている腫瘍に対して、癌を殺す免疫細胞が大規模な攻撃を開始しました。しかし、研究者らが発見したところによると、癌細胞のごく一部だけがネオアンチゲンを持っている場合、その攻撃は弱まりました。
- 生成された応答の例:ネオアンチゲンは免疫系が癌細胞を発見するのに役立ちます。
ステップ2:応答評価
生成された応答の根拠付けを評価するために、自動化された根拠付けLLMジャッジが応答の各文を評価し、例の文脈文書に対して、支持されている、支持されていない、矛盾している、または無関係として分類します。生成された応答に支持されていないまたは矛盾していると分類された文が1つでもある場合、その応答は失敗となります。
-
システム命令:文脈で提供されている情報のみを使用して質問に答えてください。
-
ユーザーリクエスト:リンゴは何色ですか?
-
文脈文書:リンゴは赤い果物です。バナナは黄色い果物です。
-
生成された応答の例:リンゴは赤いです。バナナはリンゴより安いです。バナナは緑色です。
根拠付け評価の例:
文:「リンゴは赤いです。」
分類:支持されている
説明:文は与えられた文脈に基づいています。
文:「バナナはリンゴより安いです。」
分類:支持されていない
説明:文は与えられた文脈に基づていません。
文:「バナナは緑色です。」
分類:矛盾している
説明:文は与えられた文脈によって否定されています。
文:「フルーツをお楽しみください!」
分類:無関係
説明:文は事実の帰属を必要としません。
判定:失敗 - 少なくとも1つの文が「支持されていない」または「矛盾している」。
ステップ3:品質フィルタリング
生成された応答が例のユーザーリクエストに答えていることを保証するために、自動化された品質LLMジャッジが各応答の品質を評価します。例えば、文脈文書に基づいているが、実際にはユーザーリクエストに答えていない短くて曖昧な応答を考えてみてください。根拠付けられている生成された応答も、この品質基準を満たす必要があります。
-
システム命令:文脈で提供されている情報のみを使用して質問に答えてください。
-
ユーザーリクエスト:リンゴは何色ですか?
-
文脈文書:リンゴは赤い果物です。バナナは黄色い果物です。
-
生成された応答の例:バナナは黄色です。
根拠付け評価の例:
文:「バナナは黄色です。」
分類:支持されている
説明:文は与えられた文脈に基づいています。
品質評価の例:
文:「バナナは黄色です。」
品質合格:いいえ
説明:質問に答えられていません。
判定:失敗 - 応答がユーザーリクエストの質問に答えませんでした。
ステップ4:アンサンブル
すべての生成された応答が評価されると、1,719個のうちの「事実性スコア」がパーセンテージで計算されます。
factuality_score = number_of_successful_examples / 1719
評価モデルのバイアスに対処するために、評価は個別のLLMジャッジ(Gemini 1.5 Pro、GPT-4o、Claude 3.5 Sonnet)を使用して繰り返されます。
これらの独立したスコアは、最終的なFACTS Grounding事実性スコアを計算するために集約されます。
参考
FACTSのペーパー
FACTSに関する概要
kaggleで公開されているデータセット