はじめに
本記事はQwen2.5のテクニカルレポートの要約です。
タイトル:Qwen2.5 Technical Report
概要
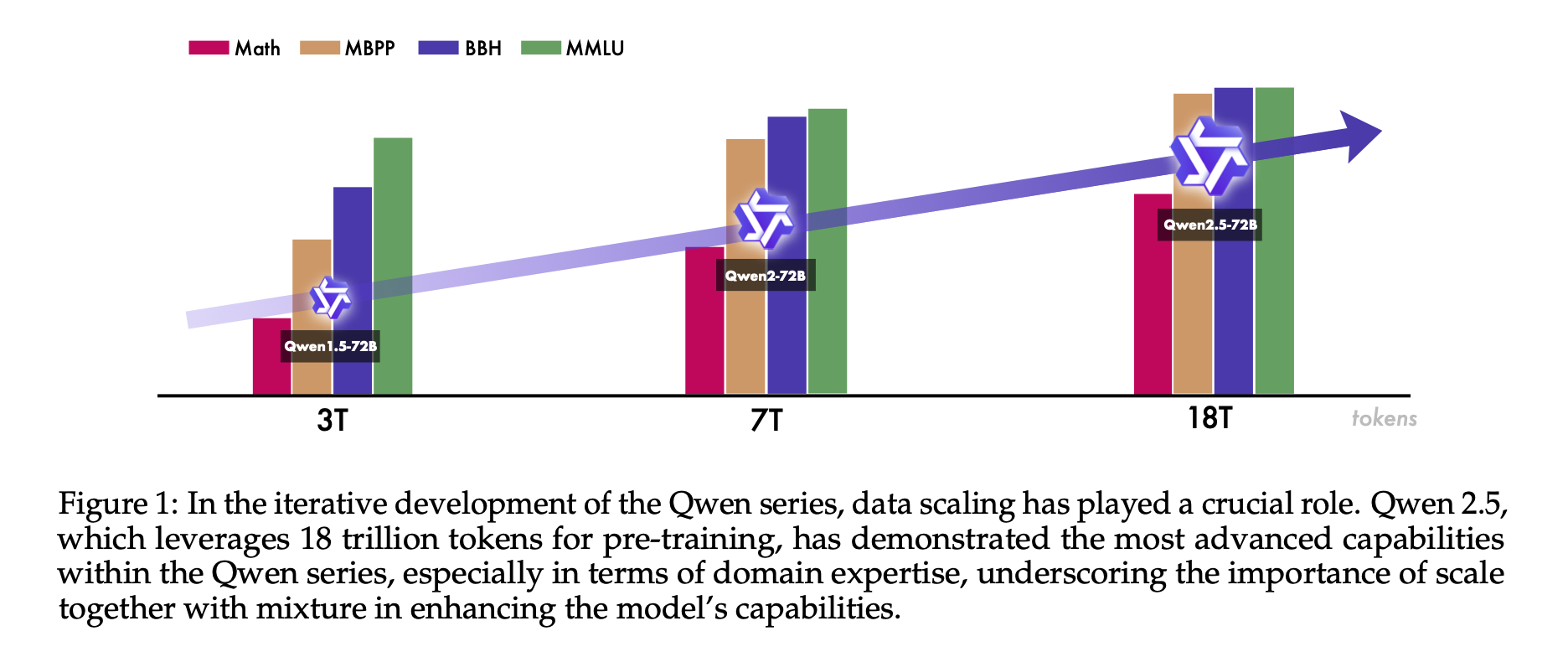
本報告では、多様なニーズに応えるために設計された包括的な大規模言語モデル(LLM)シリーズであるQwen2.5を紹介します。前バージョンと比較して、Qwen2.5は事前学習と事後学習の両段階で大幅な改善が行われました。事前学習では、高品質なデータセットの規模を従来の7兆トークンから18兆トークンに拡大し、常識、専門知識、推論能力の強化を図っています。事後学習では、100万件以上のサンプルを用いた精緻な教師あり微調整や、オフライン学習DPOやオンライン学習GRPOを含む多段階の強化学習を実施し、人間の嗜好への適合性を向上させました。これにより、長文生成、構造化データの分析、指示追従能力が著しく向上しています。
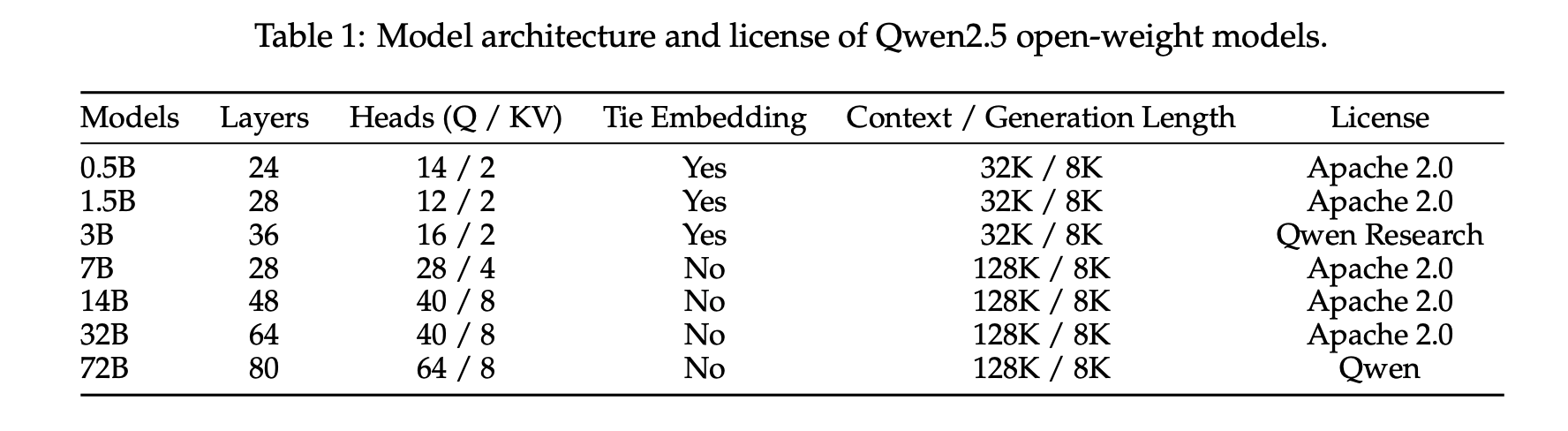
Qwen2.5 LLMシリーズは、0.5B、1.5B、3B、7B、14B、32B、72Bの各パラメータサイズで、ベースモデルと指示調整済みモデルを提供し、量子化バージョンも含め、Hugging Face HubやModelScope、Kaggleから100以上のモデルにアクセス可能です。さらに、Alibaba Cloud Model Studioでは、Mixture-of-Experts(MoE)バリアントであるQwen2.5-TurboとQwen2.5-Plusも提供されています。
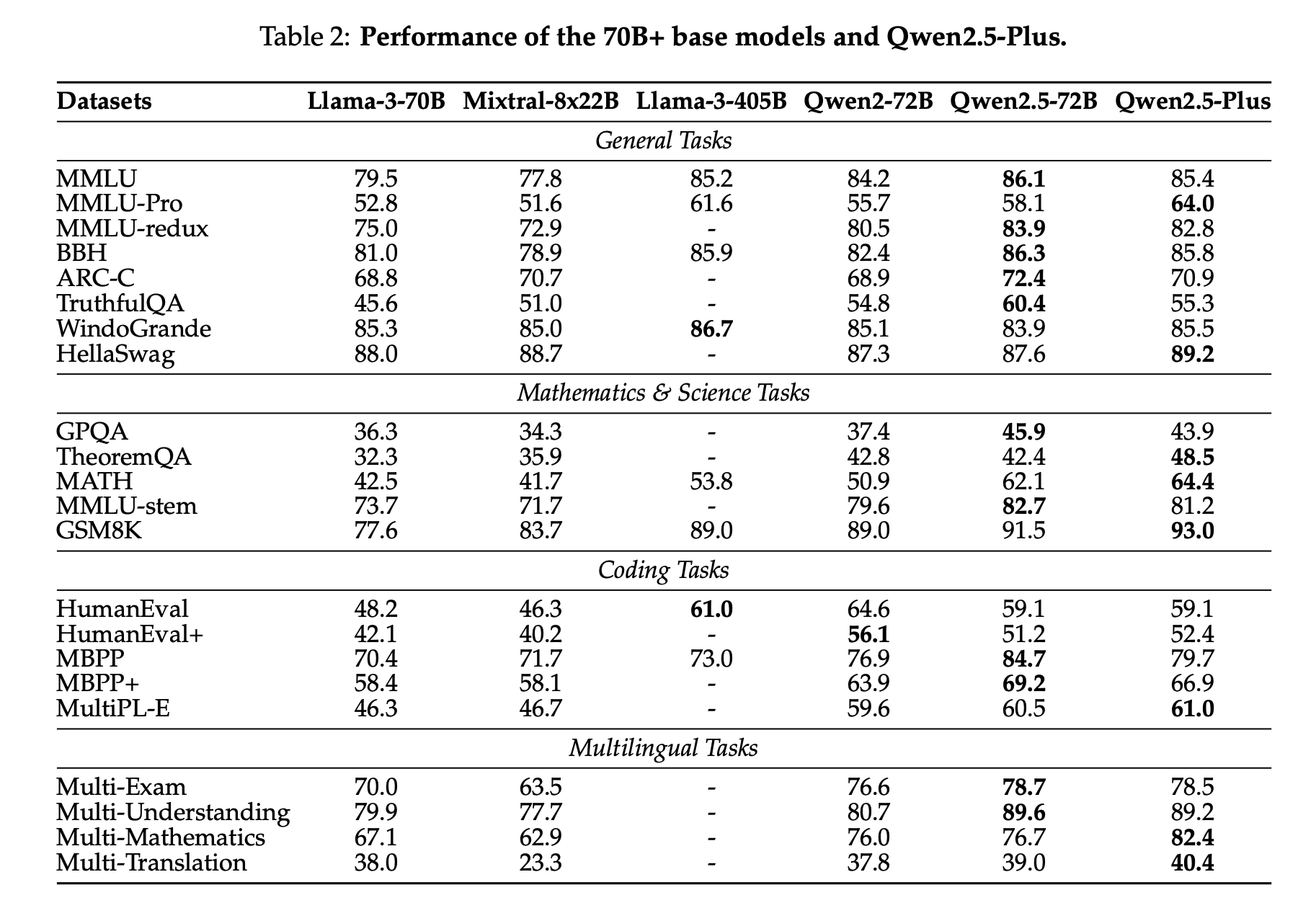
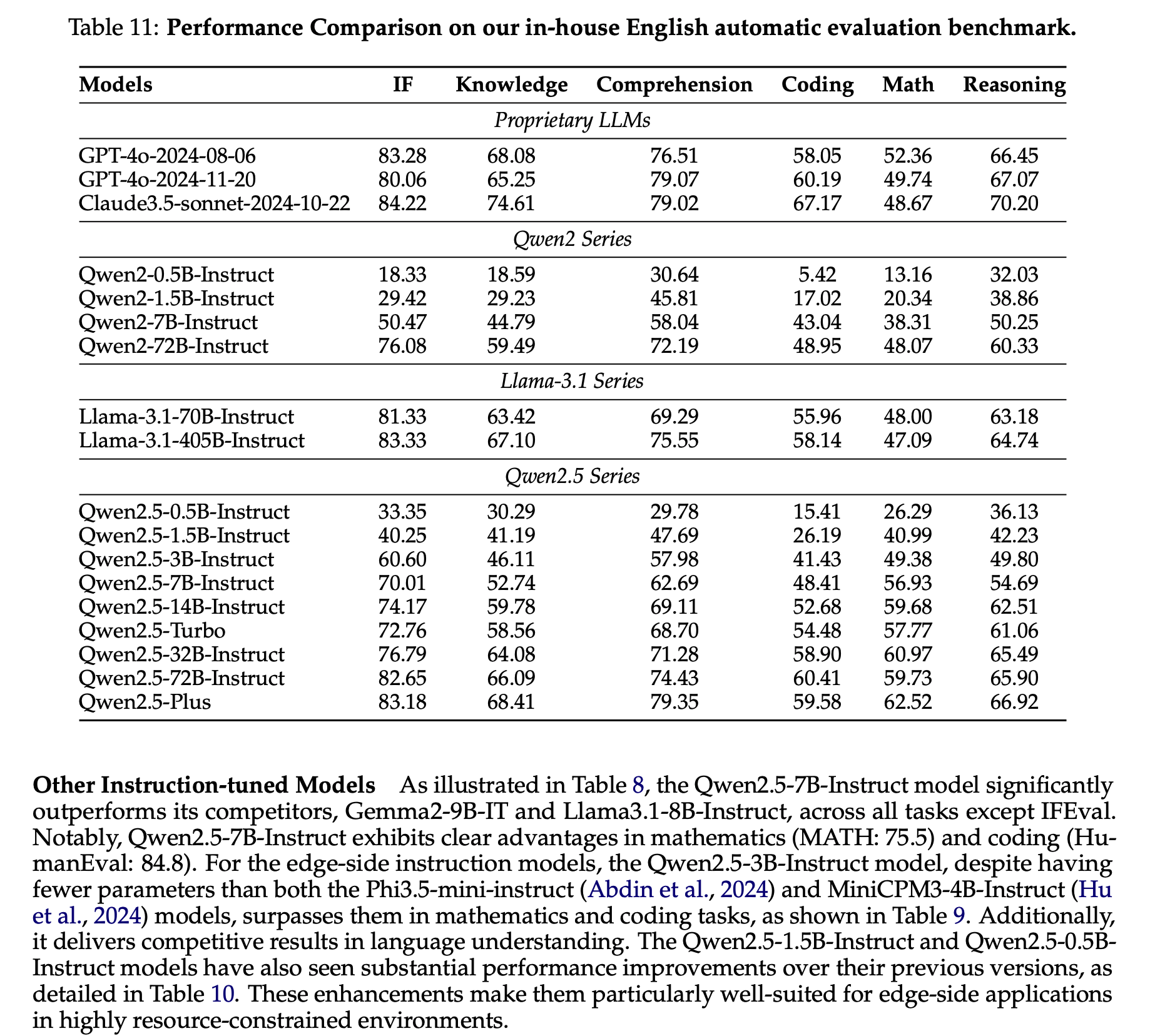
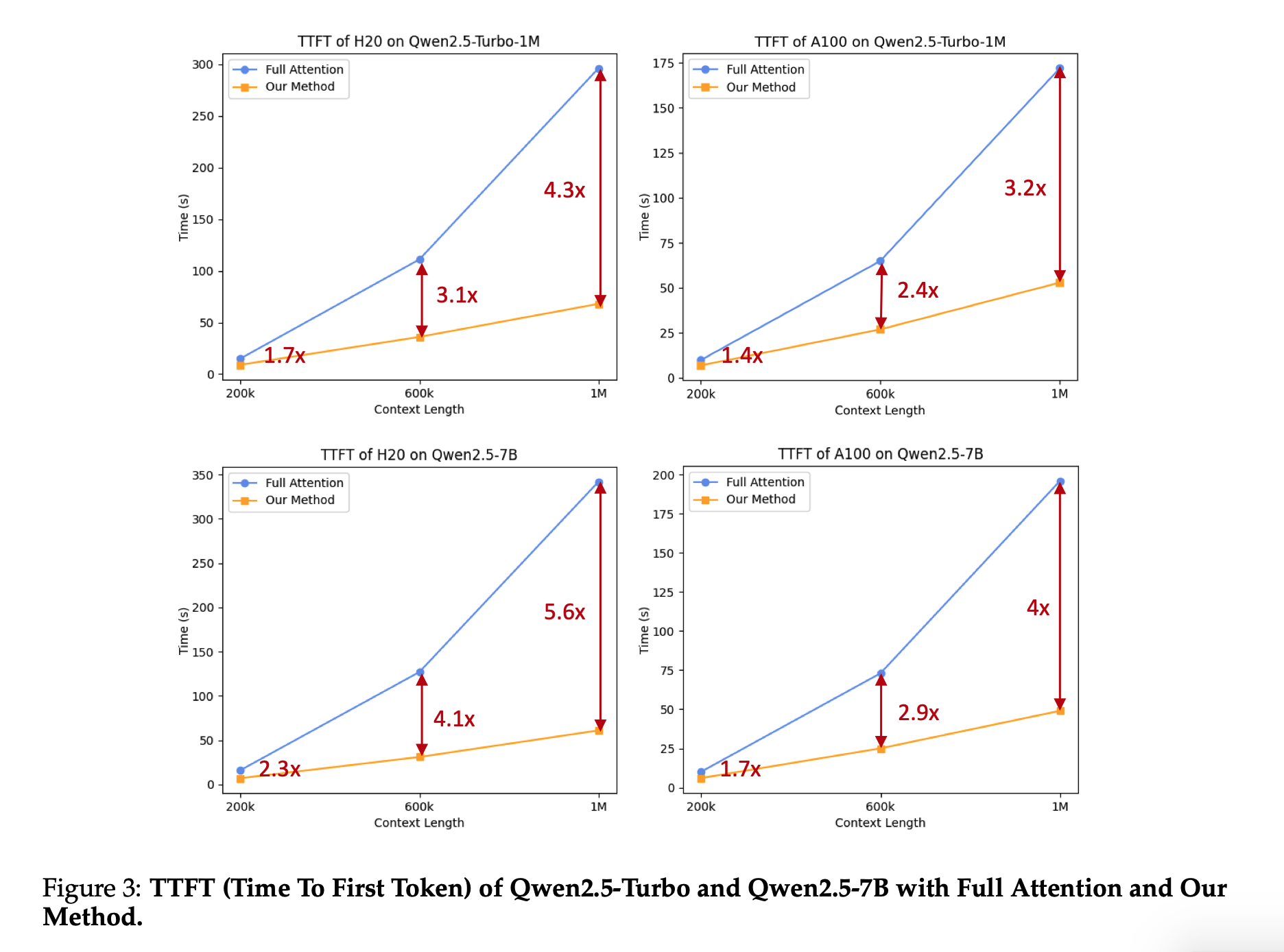
Qwen2.5は、言語理解、推論、数学、コーディング、人間の嗜好適合性など、多岐にわたるベンチマークで最高水準の性能を示しています。特に、オープンウェイトのフラッグシップモデルであるQwen2.5-72B-Instructは、多くのオープンおよびプロプライエタリモデルを上回り、約5倍のサイズであるLlama-3-405B-Instructと競合する性能を発揮しています。また、Qwen2.5-TurboとQwen2.5-Plusは、GPT-4o-miniやGPT-4oと比較して、コスト効率と性能の両面で優れたバランスを提供しています。さらに、Qwen2.5は、Qwen2.5-Math、Qwen2.5-Coder、QwQ、マルチモーダルモデルなどの専門モデルの基盤としても活用されています。
用語の解説
- 大規模言語モデル(LLM): 人間の言語を理解し生成するために設計された人工知能モデルで、大量のテキストデータを学習して言語処理能力を獲得します。
- 事前学習: モデルが大量の未ラベルデータから一般的なパターンや知識を学習するプロセスで、モデルの基礎的な能力を構築します。
- 教師あり微調整: 事前学習済みモデルに対して、特定のタスクに関連するラベル付きデータを用いてさらに学習させ、特定のタスクでの性能を向上させるプロセスです。
- 強化学習: モデルが試行錯誤を通じて最適な行動を学習する手法で、報酬を最大化するように行動を調整します。
- Mixture-of-Experts(MoE): モデル内に複数の専門家(サブモデル)を持ち、入力に応じて最適な専門家を選択して処理を行うアーキテクチャで、効率的な計算と高性能を両立します。
図表の引用