はじめに
本記事は「GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models」の紹介を紹介しています。
概要
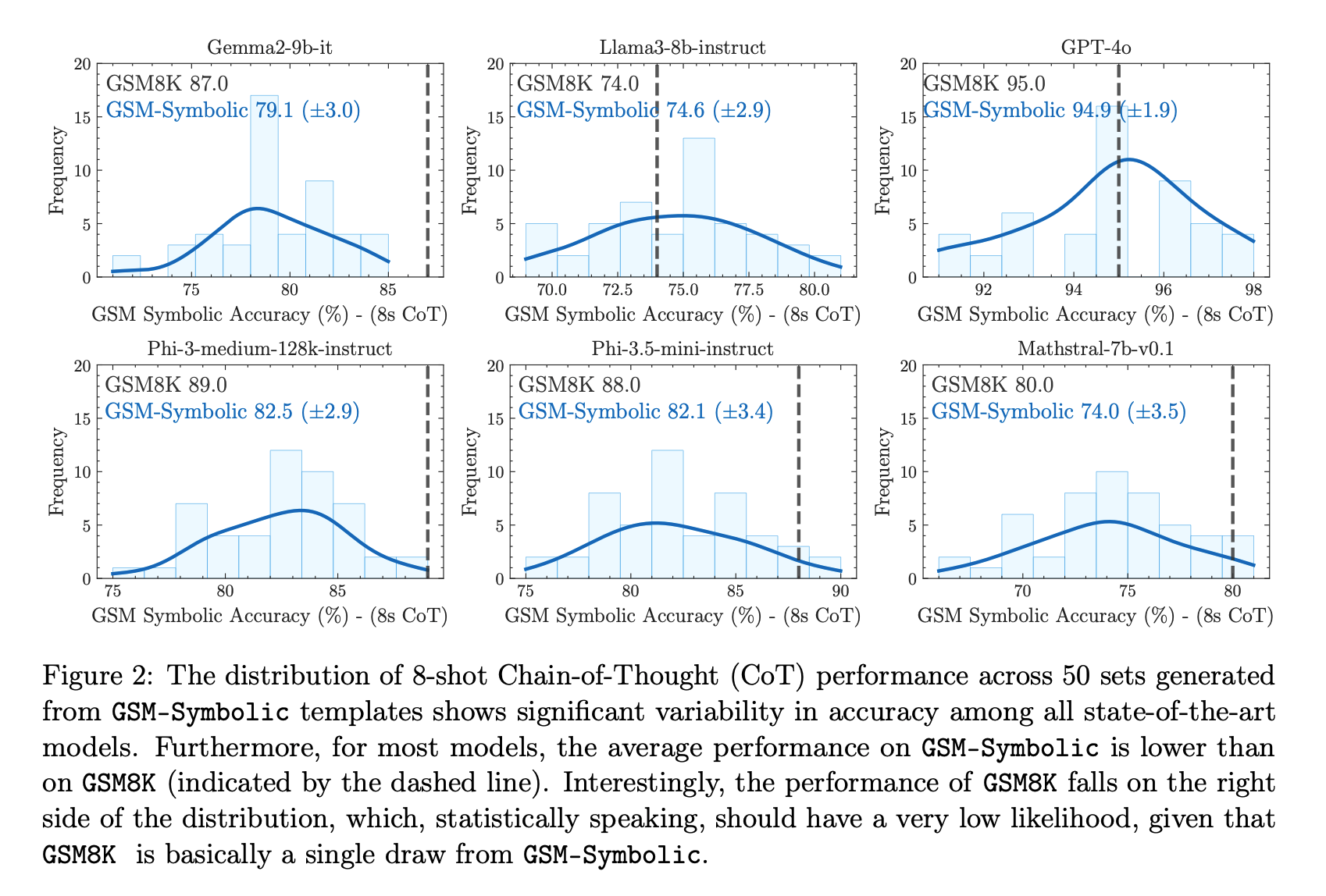
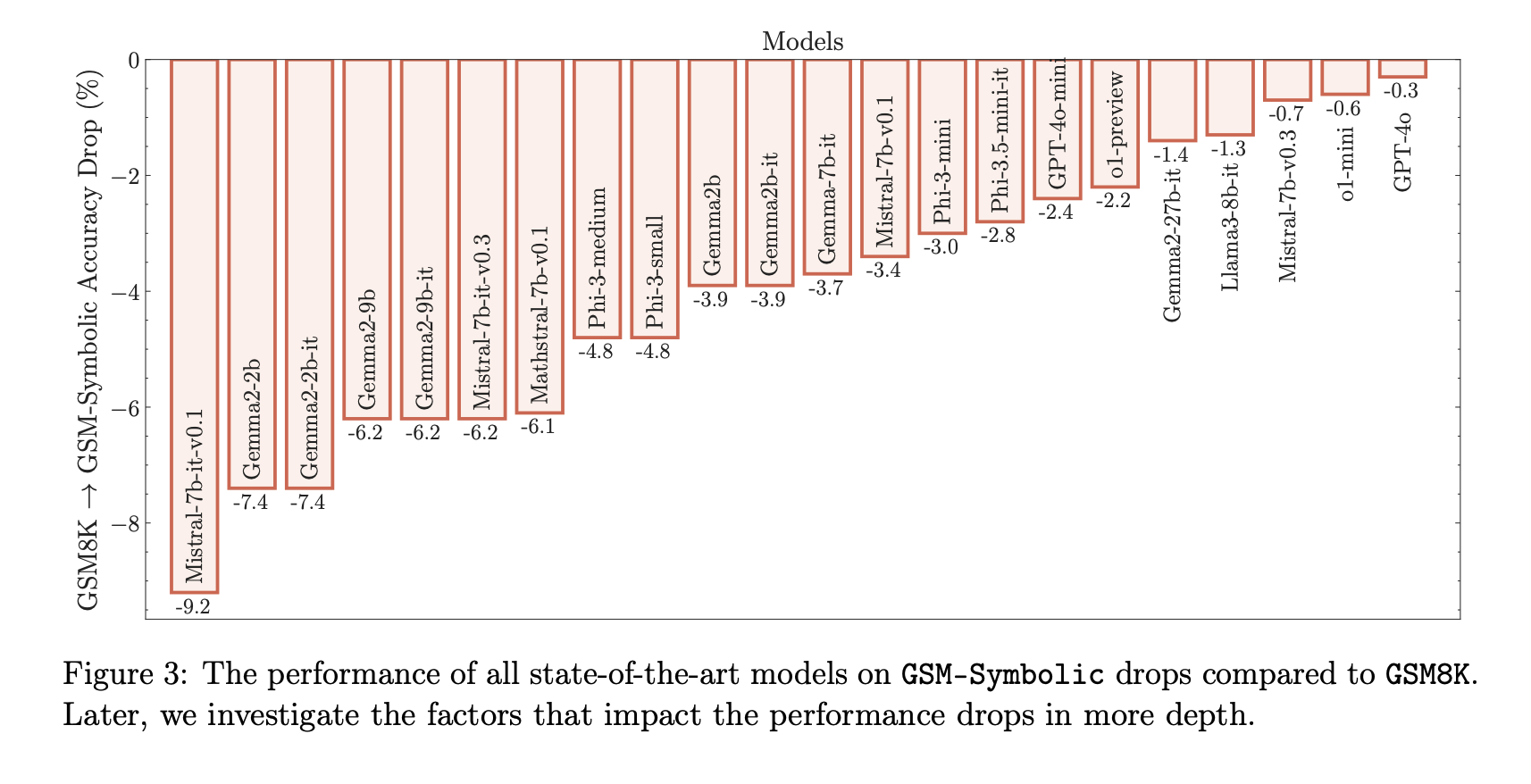
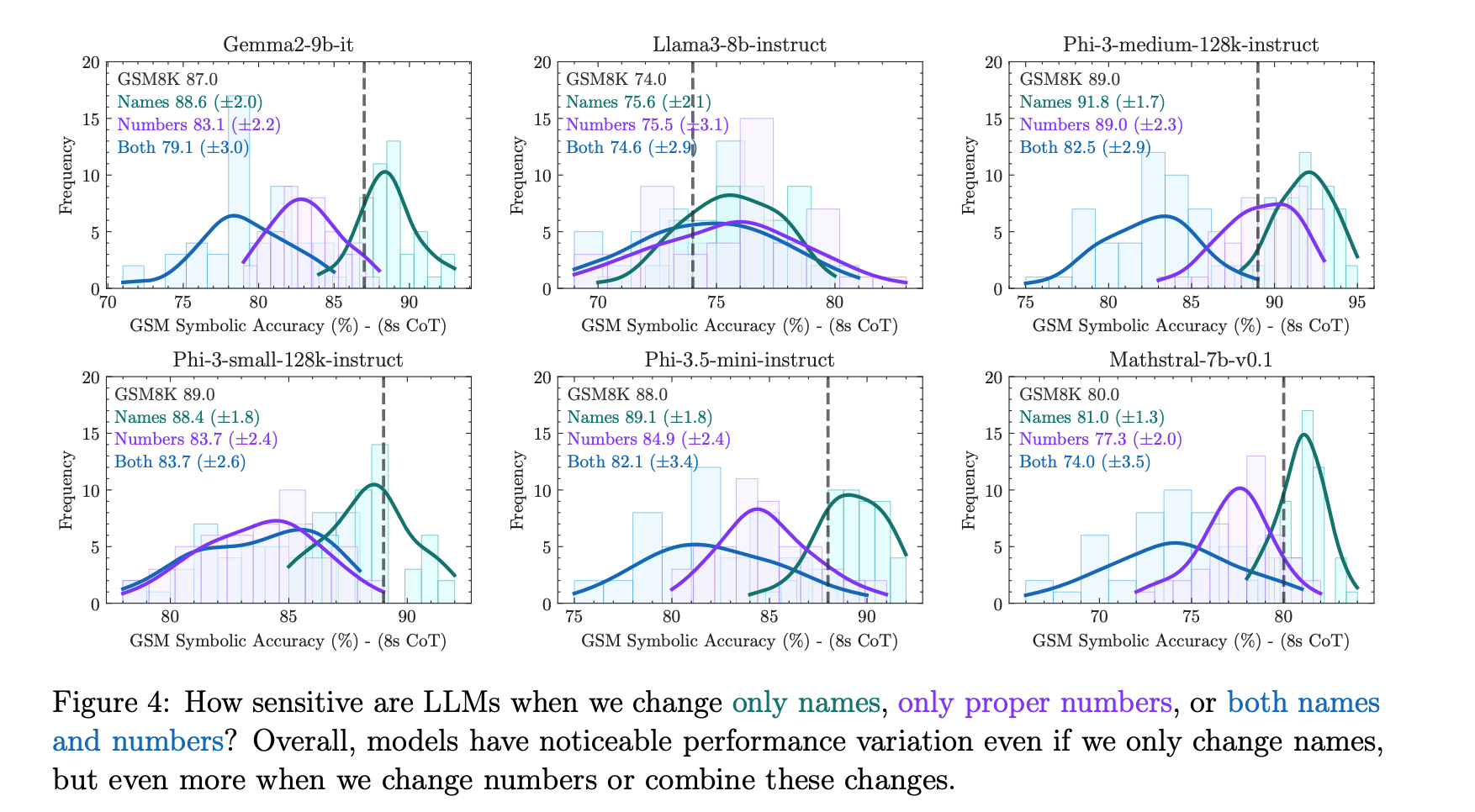
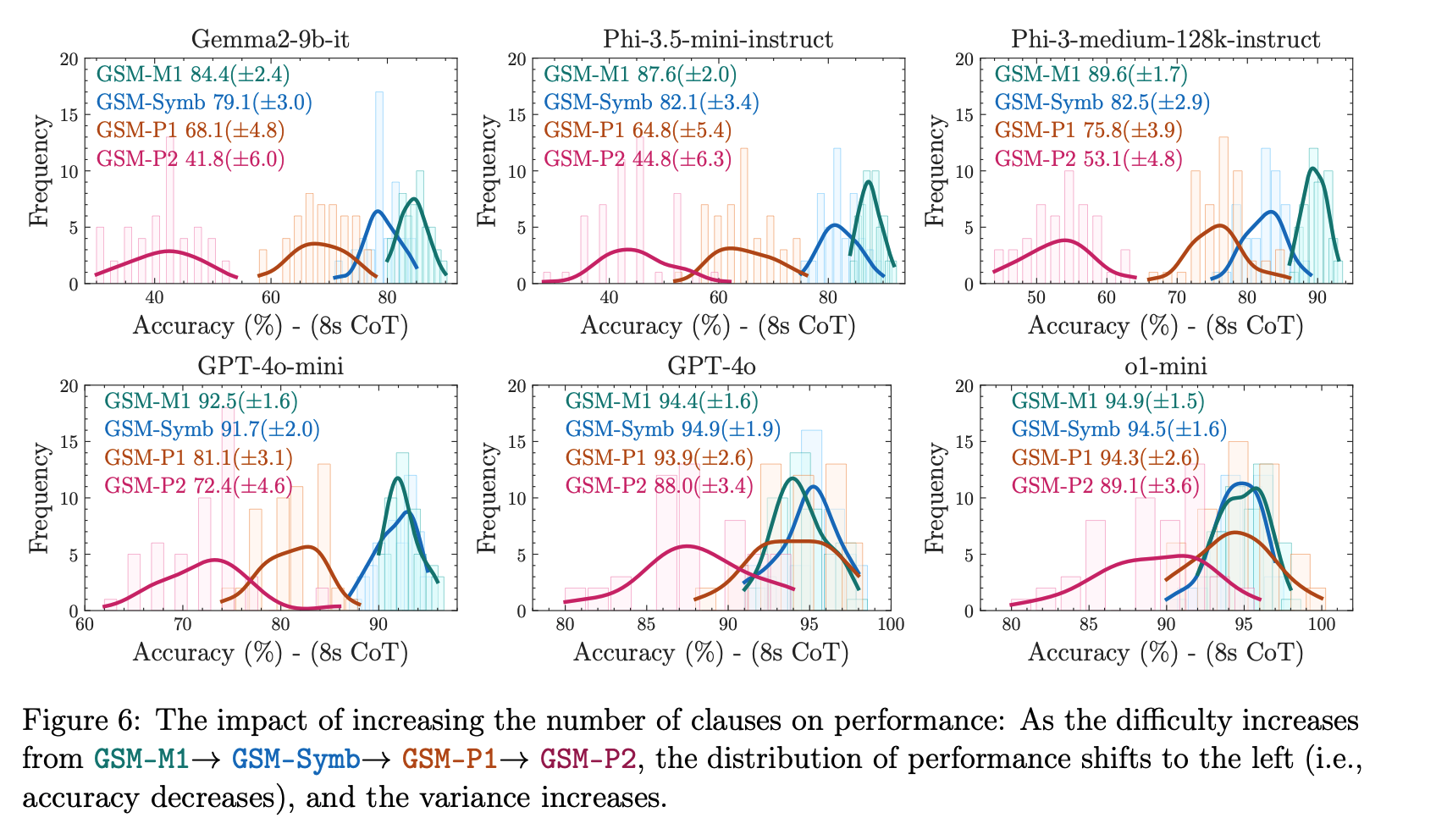
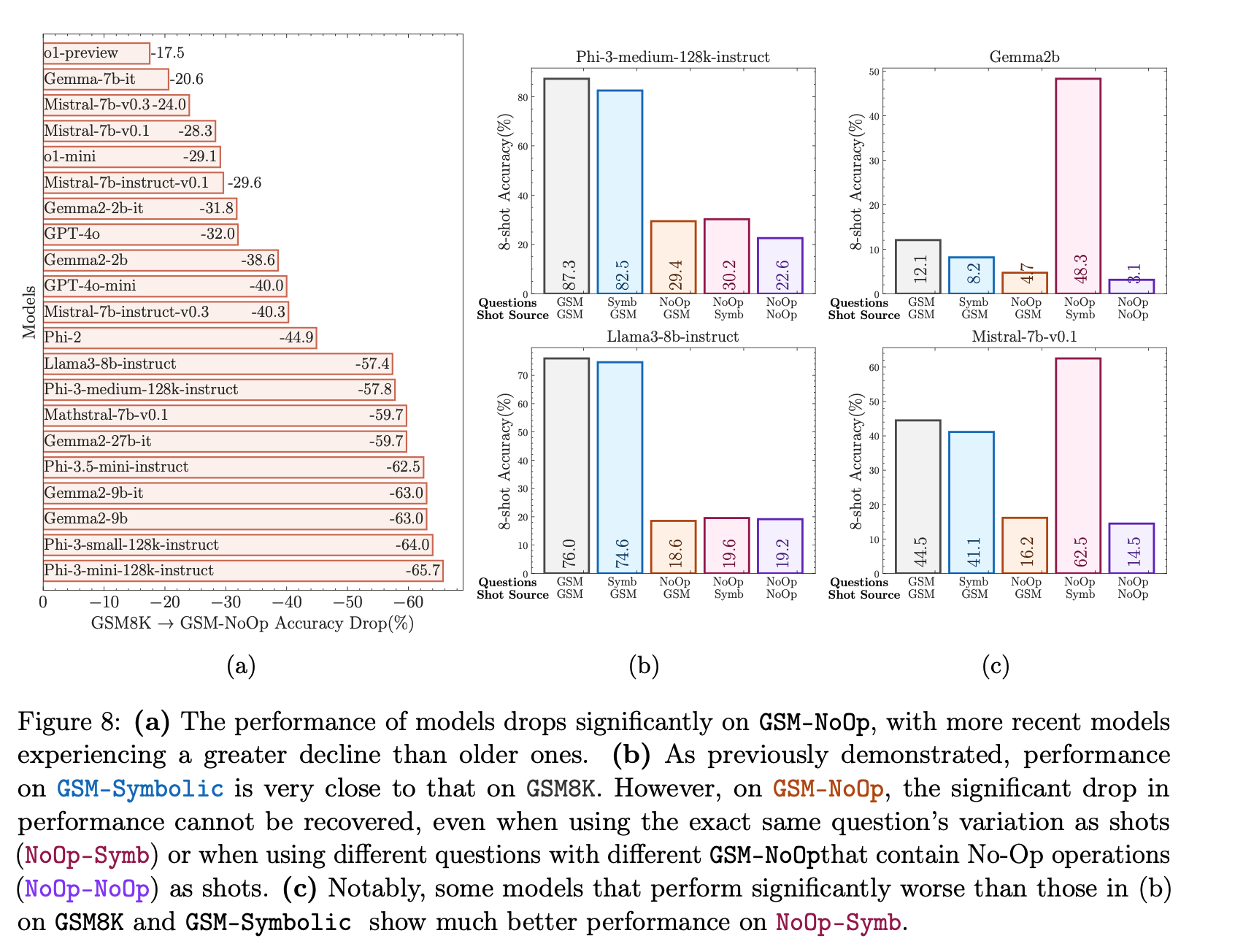
近年の大規模言語モデル(LLM)の進展により、特に数学における形式的推論能力への関心が高まっています。GSM8Kベンチマークは、小学生レベルの数学問題に対するモデルの推論能力を評価するために広く使用されています。しかし、LLMのGSM8Kにおける性能が近年大幅に向上している一方で、その数学的推論能力が本当に進歩したのかは明確ではなく、報告されている指標の信頼性に疑問が生じています。これらの懸念に対処するために、我々は複数の最先端のオープンおよびクローズドモデルに関する大規模な研究を実施しました。既存の評価の限界を克服するために、我々はGSM-Symbolicを導入しました。これは、シンボリックなテンプレートから作成された改良版ベンチマークで、多様な質問の生成を可能にします。GSM-Symbolicは、より制御可能な評価を可能にし、モデルの推論能力を測定するための重要な洞察とより信頼性の高い指標を提供します。我々の研究結果は、LLMが同じ質問の異なる具体化に対して顕著なばらつきを示すことを明らかにしています。具体的には、GSM-Symbolicベンチマークで数値だけを変更した場合、すべてのモデルの性能が低下しました。さらに、これらのモデルの数学的推論の脆弱性を調査し、質問内の節の数が増えるにつれて性能が大幅に低下することを示しました。この低下は、現在のLLMが本当の論理的推論を行うことができず、訓練データから観察された推論ステップを再現しているためであると仮定しています。質問に関連するように見える節を1つ追加するだけで、最先端のすべてのモデルで大幅な性能低下(最大65%)が観察されました。これは、その節が最終的な答えに到達するための推論チェーンに寄与していないにもかかわらずです。全体として、我々の研究は、LLMの数学的推論における能力と限界について、より微妙な理解を提供します。 
用語の解説:
- 大規模言語モデル(LLM):
大量のテキストデータを基に訓練された人工知能モデルで、人間の言語を理解し生成する能力を持っています。GPT-4やBERTなどがその例です。 - GSM8Kベンチマーク:
小学生レベルの数学問題を集めたデータセットで、言語モデルの数学的推論能力を評価するために使用されます。 - シンボリックテンプレート:
数式や記号を用いて一般的な問題の構造を表現したテンプレートで、具体的な数値や要素を代入することで多様な問題を生成できます。 - 推論チェーン:
問題の解決に至る一連の論理的なステップやプロセスのことを指します。 - 性能低下(パフォーマンスドロップ):
モデルの精度や効果が、特定の条件下で減少する現象を指します。例えば、問題の複雑さが増すとモデルの正答率が下がる場合などです。
論文中の主要な図表