はじめに
本記事はReDrafterの紹介記事です。以下のコンテンツを含みます。
- Appleのプレスリリース
- NVIDIAのディベロッパーブログ
NVIDIA GPUでのReDrafterを用いたLLM推論の高速化
LLM推論の高速化は、機械学習における重要な研究課題です。なぜなら、自己回帰型トークン生成は計算コストが高く、比較的遅いため、推論効率を改善することでユーザーの待機時間を短縮できるからです。Appleシリコンでの推論高速化に向けた取り組みを続ける中、業界全体で幅広く使用されているNVIDIA GPU向けのLLM推論の高速化においても大きな進展がありました。
今年初め、私たちはRecurrent Drafter(ReDrafter)を発表し、オープンソース化しました。ReDrafterは革新的な推測デコード手法であり、最先端の性能を実現しています。この手法はRNNドラフトモデルを使用し、ビームサーチと動的ツリーアテンションを組み合わせることで、オープンソースモデルでのトークン生成速度を1ステップあたり最大3.5トークンまで向上させ、従来の推測デコード手法を超える性能を達成しました。
トークン生成速度の向上
以下の棒グラフは、NVIDIA TensorRT-LLMを用いたReDrafterと通常の自己回帰推論を比較したトークン生成速度の向上を示しています。
• ReDrafter: 2.7倍速
• 自己回帰: 1倍速
図1: NVIDIA TensorRT-LLMにおけるReDrafterと自己回帰のトークン生成速度の比較
ReDrafterをNVIDIA TensorRT-LLMでの高速化に適用
この研究は強力な結果を示しましたが、その最大の影響は、NVIDIA GPUでのLLM推論を高速化するために実際の運用環境で適用されたことです。ReDrafterをNVIDIA GPU向けに運用可能な形にするため、NVIDIAと協力し、NVIDIA TensorRT-LLM推論高速化フレームワークに統合しました。
TensorRT-LLMは、数多くのオープンソースLLMやMedusa推測デコード手法をサポートしていますが、ReDrafterのビームサーチとツリーアテンションアルゴリズムでは、従来のアプリケーションで使用されていなかったオペレーターを必要とします。この統合を実現するために、NVIDIAは新たなオペレーターの追加や既存オペレーターの公開を行い、TensorRT-LLMが高度なモデルとデコード手法に対応できる能力を大幅に向上させました。
これにより、NVIDIA GPUを使用する機械学習開発者は、TensorRT-LLMを通じてReDrafterの高速化されたトークン生成を簡単に活用し、自身のLLMアプリケーションを運用環境で実現できるようになりました。
NVIDIA GPU上で数十億パラメータのモデルを使用してベンチマークを行った結果、NVIDIA TensorRT-LLM推論高速化フレームワークとReDrafterを用いた場合、貪欲デコードで生成トークン数が1秒あたり2.7倍に高速化されました(図1参照)。この結果は、ユーザーの待機時間を大幅に短縮できる可能性があるだけでなく、使用するGPUの台数を減らし、消費電力を削減できることを示しています。
詳細については、NVIDIAデベロッパーブログの記事をご覧ください。
まとめ
LLMは生産アプリケーションを支える技術としてますます使用されています。推論効率を改善することで、計算コストに影響を与えるとともに、ユーザーの待機時間を短縮できます。ReDrafterの革新的な推測デコード手法がNVIDIA TensorRT-LLMフレームワークに統合されたことで、開発者はNVIDIA GPU上でより高速なトークン生成の恩恵を受け、運用アプリケーションの性能を向上させることができます。
NVIDIAのデベロッパーブログ
ReDrafter: NVIDIA TensorRT-LLMによる革新的な推測デコード技術
Recurrent drafting(ReDrafter)は、Appleが開発しオープンソース化した、LLM推論を加速させるための新しい推測デコード手法です。この技術は現在、NVIDIAのLLM推論最適化ライブラリであるTensorRT-LLMで利用可能となり、NVIDIA GPUでのLLMのパフォーマンス向上を大きく支援します。
NVIDIA TensorRT-LLMとは
TensorRT-LLMは、LLM推論の最適化を目的としたライブラリで、使いやすいPython APIを提供しています。このライブラリにより、LLMを定義し、NVIDIA TensorRTエンジンを構築することで、最先端の最適化を利用した効率的な推論が可能になります。主な最適化には以下が含まれます:
• カスタムアテンションカーネル
• 実行中のバッチング(inflight batching)
• ページングされたKVキャッシング
• 量子化(FP8、INT4 AWQ、INT8 SmoothQuant)
• その他多数
推測デコード(Speculative Decoding)とは
推測デコードは、LLM推論を加速させる技術で、複数のトークンを並列で生成します。この手法では、小型の「ドラフト」モジュールを使用して将来のトークンを予測し、それをメインモデルで検証します。この方法により、出力品質を維持しながら応答時間を大幅に短縮できます。特に低トラフィック時には、低レイテンシの推論を実現するためにリソースを効率的に活用できます。
ReDrafterの特徴とTensorRT-LLMへの統合
ReDrafterは、再帰型ニューラルネットワーク(RNN)ベースのサンプリングを使用してトークンを生成する「ドラフティング」を採用しています。また、Medusaなどの技術で使用されていたツリー型のアテンションを組み合わせることで、複数の可能な経路からドラフトトークンを予測し、検証する精度を向上させます。この方法により、デコーダーの各反復で複数のトークンを受け入れる可能性が広がります。
NVIDIAはAppleと協力し、この技術をTensorRT-LLMに統合しました。これにより、ReDrafterはより広い開発者コミュニティに提供され、以前のMedusaと比較して新たな最適化の可能性が解放されました。
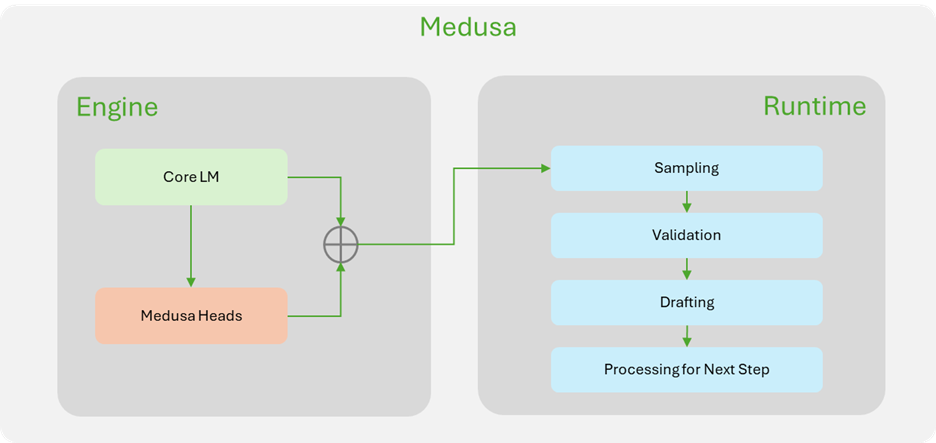
MedusaとReDrafterの違い
Medusaでは、経路の受け入れやトークンサンプリングがTensorRT-LLMランタイム内で行われますが、この方法では将来の経路をすべて処理する必要があり、そのほとんどが最終的に破棄されるため、オーバーヘッドが発生します。一方で、ReDrafterは、次の反復でトークンを生成する前に、最適な経路のトークン検証と受け入れを行う必要があります。これにより、オーバーヘッドが削減されます。
TensorRT-LLMの更新
TensorRT-LLMは、ドラフティングと検証ロジックを1つのエンジン内に統合するよう更新されました。このアプローチにより、ランタイムや別個のエンジンに依存することなくオーバーヘッドを最小化できます。さらに、TensorRT-LLMのカーネル選択やスケジューリングの自由度が向上し、ネットワーク性能を最大化する最適化が可能になりました。
ReDrafterの改善点
ReDrafterの改善をより明確にするため、図1ではTensorRT-LLMにおけるその実装とMedusaの違いを示しています。ReDrafterに関連する推測デコードのほとんどの処理がエンジン内で行われており、これによりランタイムで必要な変更が大幅に簡素化されています。
この技術統合により、NVIDIA GPUを活用する開発者は、より効率的で高速な推論を実現できるようになりました。
参考