はじめに
本記事は、OpenAIの論文「Deliberative Alignment: Reasoning Enables Safer Language Models」の概要と専門用語の解説です
概要
大規模言語モデル(LLMs)が安全性が求められる領域でますます活用される中、明確に定義された原則に確実に従わせることが重要な課題となっています。本論文では、モデルに安全性の仕様を直接教え、回答前にそれらを明示的に思い出し、正確に推論するよう訓練する新たな手法「Deliberative Alignment」を提案します。
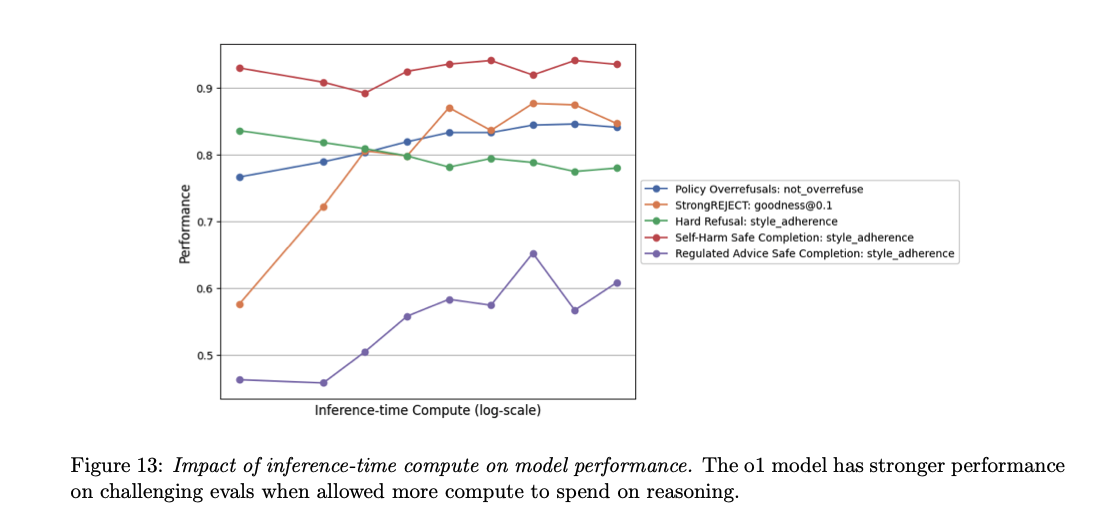
この手法をOpenAIのoシリーズモデルに適用し、人間が作成した思考過程や回答を必要とせずに、OpenAIの安全ポリシーに高精度で従うことを実現しました。Deliberative Alignmentは、脱獄攻撃(jailbreak)に対する耐性を高めつつ、正当な要求を過度に拒否する率を低減し、未知の状況への一般化能力も向上させます。明示的に指定されたポリシーに基づいて推論することで、よりスケーラブルで信頼性が高く、解釈可能なモデルの整合性を実現します。
用語の解説
- 大規模言語モデル(LLMs): 大量のテキストデータを学習し、人間の言語を理解・生成する能力を持つAIモデル。自然言語処理の多様なタスクに応用されます。
- Supervised Fine Tuning(SFT): 教師あり学習により、特定のタスクや目的にモデルを適応させるプロセス。事前学習済みモデルに対して、追加のデータセットで微調整を行います。
- Reinforcement Learning from Human Feedback(RLHF): 人間のフィードバックを活用して、モデルの出力を強化学習により最適化する手法。モデルの応答が人間の期待や価値観に沿うよう調整します。
- 脱獄攻撃(Jailbreak): AIモデルの制約や安全対策を回避し、意図しない出力や有害な情報を引き出す試み。モデルの安全性を評価する上での課題となります。
- Chain-of-Thought(CoT)推論: 複雑な問題に対して、段階的に思考過程を展開し、最終的な回答に至る推論手法。モデルの解釈性や信頼性を向上させる目的で使用されます。
主要な図と表