はじめに
こんにちは。株式会社ベーシックの AI・データ分析チームに所属している shitara です。2021 年ももうすぐ終わります。皆さんにとって、どんな1年だったでしょうか。
さて、年末年始シーズンになるとよく見かけるのが「干支の画像」。2022年は「寅」ですね。
年賀状を作る方にとっては必須となる干支画像ですが、今回は GAN というモデルを使って、AI に干支画像を描いてもらおうと思います。今回は寅の画像を作ることをゴールにしますが、せっかくなので、設定を変更すれば寅以外の干支画像も描くことができるように実装してみましょう!
※ あくまで GAN の紹介記事ですので、出力される画像のクオリティには目を瞑ってください。出力サンプルは以下です。出力画像は 64 × 64 のサイズなので、解像度は低めです。

前提
- AI を作ったことが無い方でも大丈夫です。コードをコピーして実行すれば、誰でも干支画像を作ることができます。(※ コードの実行には 30 分ほどかかります。)
- 紹介するコードの各種パラメータは寅画像の生成に合わせて調整しています。寅以外を指定した場合、どんな画像が生成されるかは未知数です。
- 一般公開されているデータセット(CIFAR10, CIFAR100)を使う都合上、以下の制約があります。
- データセットに対象クラスが無いため、未(ひつじ)、申(さる)、亥(いのしし)の画像は生成できません。未年、申年、亥年の方はすみません…。
- 辰(たつ)を指定した場合、代わりに「恐竜」が生成されます(公開データセットに竜のクラスが無く、最も近いのが恐竜だったため)。許してください。
GAN とは
コードの紹介に入る前に、今回使用する「GAN」という AI について簡単に説明します。
GAN とは「Generative Adversarial Network」の略で、日本語では「敵対的生成ネットワーク」と呼ばれます。この AI を使うと「本物そっくりのフェイクデータ」を作ることができます。
GAN は「敵対的」の名前の通り、 Generator(生成器)と呼ばれる AI と、Discriminator(識別器)と呼ばれる AI を競い合わせることで学習が進みます。それぞれの AI の役割は以下の通りです。
- Generator
- ランダムな数字からなる数列を入力として受け取り、その数列をもとに「本物そっくりのフェイクデータ」を出力する。
- Discriminator を騙すようなフェイクデータを生成することを目的に成長していく。
- Discriminator
- 画像を入力として受け取り、その画像が「本物(リアル)」なのか「偽物(フェイク)」なのかを見分ける。
- 本物と偽物を正しく識別することを目的に成長していく。
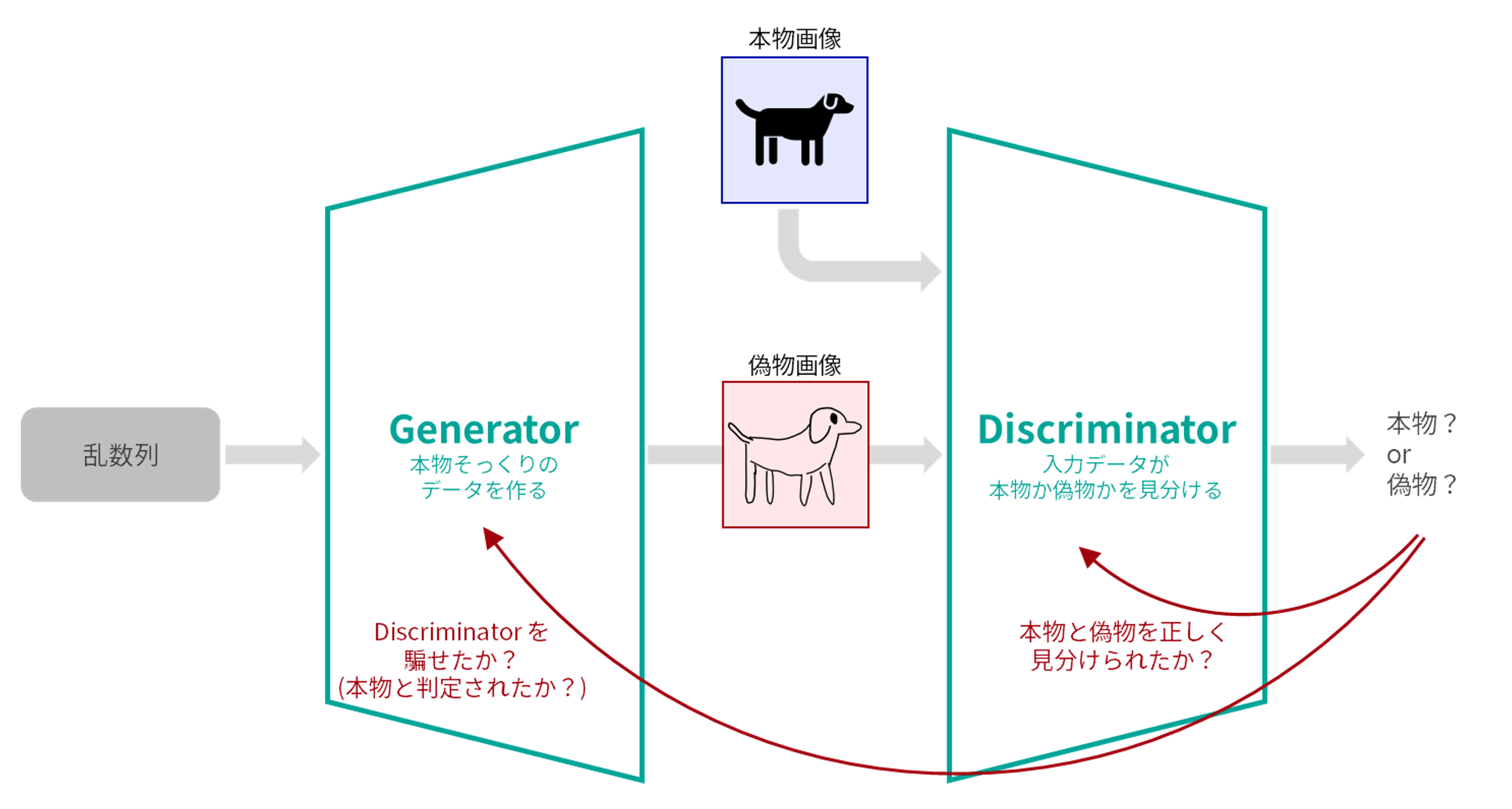
これらの AI を競わせることで、最終的に「本物そっくりのデータを生成する能力を持った Generator」が誕生します。この記事では、一般公開されているデータセットで GAN を機械学習し、成長した Generator さんに 2022 年の干支である寅画像を描いてもらうことがゴールとなります。
Google Colaboratory の準備
コーディングを始める前に、AI の開発環境を整えます。今回は Google Colaboratory を使います。
Google Colaboratory はブラウザからアクセスできる Jupyter Notebook 実行環境で、GPU 付きのランタイムを無料で使用できます(ただし、実行時間等に制限があります)
こちら から Google Colab にアクセスし、「ファイル」>「ノートブックを新規作成」を選択します。Google アカウントにログインしていない場合はログインが求められます。
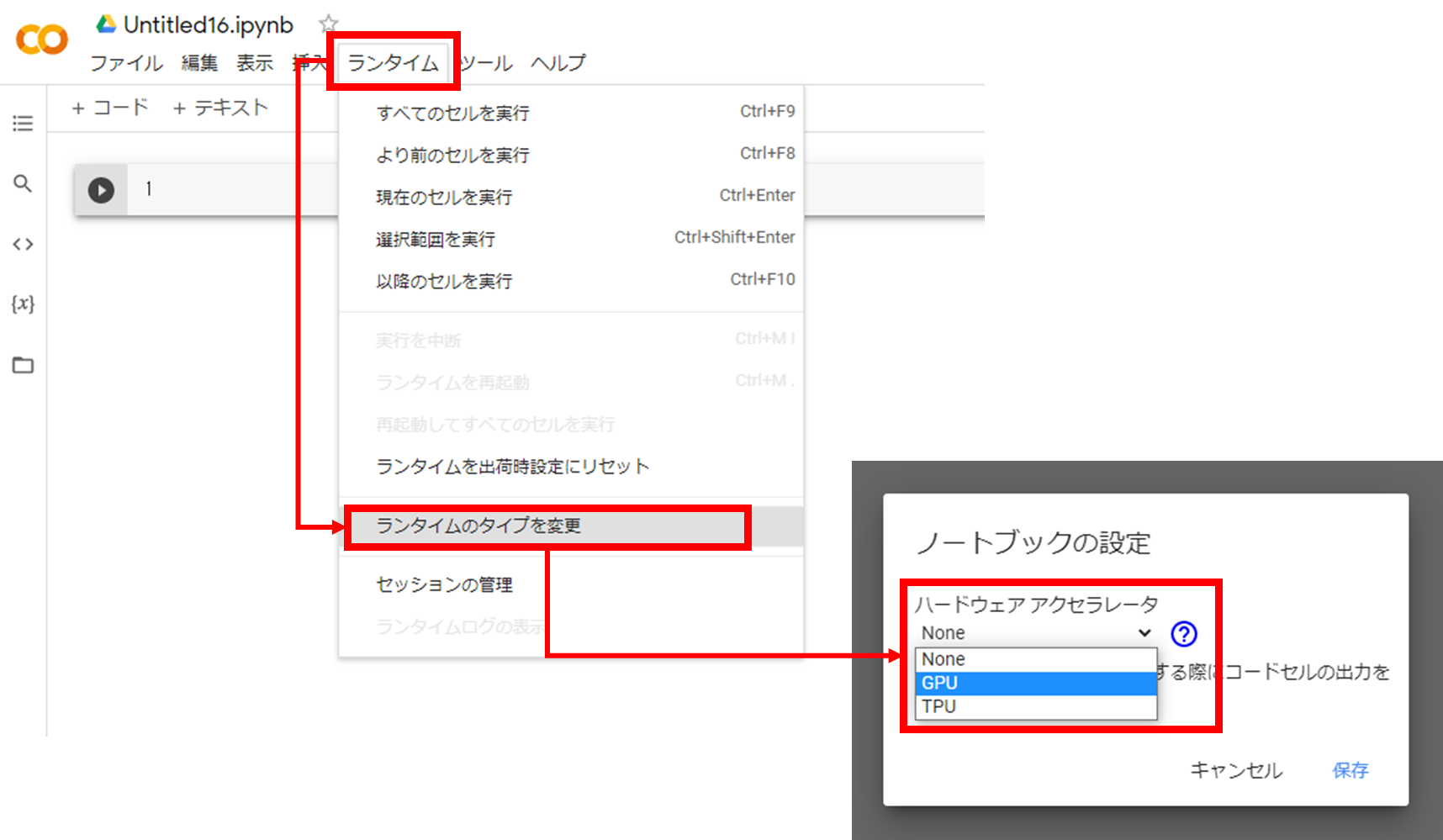
次に、GPU を ON にします。「ランタイム」>「ランタイムのタイプを変更」をクリックし、ハードウェアアクセラレータを「None」から「GPU」に変更して保存します。
これで準備は完了です!
Google Colaboratory は「セル」と呼ばれるブロックの組み合わせでコードを書きます。セルにはPython のコードを書いて実行できる「コードセル」と、マークダウン形式で文章を記載できる「テキストセル」があります。ヘッダー部分の「+コード」や「+テキスト」からセルを追加できます。
GAN の Python コードを書こう
それでは、実際に GAN のコードを書いていきましょう。今回は PyTorch のチュートリアルを参考に、一部パラメータ等を変更して干支画像を生成していきます。
ライブラリのインポート・グローバル変数の宣言
はじめに必要なライブラリをインポートし、同時に各種グローバル変数を宣言します。新しいコードセルを追加し、以下のコードを記載して実行します。セルを実行するには、セルをマウスオーバーした際に表示される実行ボタンをクリックするか、Ctrl + Enter を押します。
%matplotlib inline
import os
import random
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from PIL import Image
from IPython.display import HTML
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as T
import torch.optim as optim
import torchvision.utils as vutils
from torch.utils.data import Subset, DataLoader
from torchvision.datasets import CIFAR10, CIFAR100
OUTPUT_DIR = "output-images"
if not os.path.exists(OUTPUT_DIR):
os.mkdir(OUTPUT_DIR)
MODEL_DIR = "models"
if not os.path.exists(MODEL_DIR):
os.mkdir(MODEL_DIR)
# 乱数シード
RANDOM_SEED = 42
random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
# エポック数
NUM_EPOCHS = 500
# バッチサイズ
BATCH_SIZE = 16
# 入力画像のカラーチャネル数
NC = 3
# 潜在ベクトルの長さ
NZ = 100
# Generator の特徴マップサイズ
NGF = 64
# Discriminator の特徴マップサイズ
NDF = 64
# 学習率
LR = 0.0001
# Adam オプティマイザーのハイパーパラメータ
BETA1 = 0.5
# 正解・不正解のラベル
REAL_LABEL = 1.
FAKE_LABEL = 0.
上記コードの NUM_EPOCHS で機械学習のループ回数を指定しています。筆者が事前に試した限りでは、500 回以内にはそれなりの寅画像を生成できるようになるみたいですが、必要に応じてループ回数を増減してください。設定値を変えた場合は、再度セルを実行する必要があります。
出力する干支の指定
次に、出力対象の干支を指定します。コードセルを追加し、以下のコードを記載して実行します。
ZODIAC = {
"rat": {"dataset": "CIFAR100", "index": 50},
"ox": {"dataset": "CIFAR100", "index": 19},
"tiger": {"dataset": "CIFAR100", "index": 88},
"rabbit": {"dataset": "CIFAR100", "index": 65},
"dragon": {"dataset": "CIFAR100", "index": 29},
"snake": {"dataset": "CIFAR100", "index": 78},
"horse": {"dataset": "CIFAR10", "index": 7},
"sheep": {},
"monkey": {},
"rooster": {"dataset": "CIFAR10", "index": 2},
"dog": {"dataset": "CIFAR10", "index": 5},
"boar": {},
}
TARGET = "tiger"
target_zodiac = ZODIAC.get(TARGET)
if not target_zodiac:
raise Exception("'{}' は非対応です".format(TARGET))
ZODIAC では、参照するデータセットと、データセット中における各干支のクラス番号を定義しています。一方、出力する干支は TARGET に指定します。今回は寅画像を出力するので、 "tiger" を指定します。
Transform の定義
GAN の機械学習に使用する寅の画像は、CIFAR100 という一般公開データセットの tiger クラスに属するものを使用します。この画像の枚数は 500 枚です。
ここでは、これらの寅画像に対する「加工方法」を定義します。機械学習に使用するデータが少ないと、なかなか高性能なモデルが生まれません。そのため今回は、データを上手く加工することで、少ないデータから様々なバリエーションを発生させて利用します(これを Data Augmentation と呼びます)。
以下のコードセルを追加して実行します。
transform = T.Compose([
T.Resize(64),
T.CenterCrop(64),
T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1),
T.RandomHorizontalFlip(p=0.5),
T.ToTensor(),
])
ここでは、以下の処理を記載しています。
-
Resize:画像のサイズを変更する処理 -
CenterCrop:画像の中央をくり抜き、正方形にする処理 -
ColorJitter:画像に対してランダムに明るさ・コントラスト・彩度を変更する処理 -
RandomHorizontalFlip:画像をランダムに左右反転する処理 -
ToTensor:画像を Tensor に変換する処理
Generator, Discriminator を構成するニューラルネットワークは、入力できるデータのサイズが決まっています。 Resize と CenterCrop を使い、画像をニューラルネットワークに合ったサイズに変換します。
ColorJitter と RandomHorizontalFlip は画像に対してランダムに適用される処理です。これらの処理により、500 枚の寅画像はループの度に「微妙に異なる画像」としてモデルに読み込まれることになり、結果としてデータのバリエーションを増やすことができます。
最後の ToTensor では、画像を Tensor と呼ばれる特殊な型に変換します。
DataLoader の作成
次に、下記コードを実行します。ここでは、先程定義した transform を指定しつつ、一般公開されているデータセット(寅画像の場合は CIFAR100 )のデータを取得し、対象クラスのみを抽出して DataLoader を作成します。DataLoader は、機械学習のループ時に使用するデータを管理するための PyTorch のクラスです。
if target_zodiac["dataset"] == "CIFAR10":
dataset = CIFAR10("CIFAR10", train=True, download=True, transform=transform)
elif target_zodiac["dataset"] == "CIFAR100":
dataset = CIFAR100("CIFAR100", train=True, download=True, transform=transform)
indices = [i for i, (_, idx) in enumerate(dataset) if idx == target_zodiac["index"]]
dataset = Subset(dataset, indices)
data_loader = DataLoader(
dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=os.cpu_count())
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
ngpu = torch.cuda.device_count()
データを確認する
前のセルの実行が終わったら、いくつかサンプルを確認してみましょう。以下のコードを実行すると、機械学習に使用するデータのうち 30 枚が可視化されます。
sample_dataset = Subset(dataset, range(30))
plt.figure(figsize=(30, 10))
for i, (image_tensor, _) in enumerate(sample_dataset):
img = image_tensor.to("cpu").detach().numpy().transpose((1, 2, 0))
plt.subplot(3, 10, i + 1)
plt.imshow((img * 255).astype(np.uint8))

モデルの実装:初期化メソッドの定義
データの準備が整ったので、次は AI モデルを作っていきます。
はじめに、Generator, Discriminator の初期化に使用するメソッドの定義です。チュートリアルによると、各モデルの重みが平均 0.0, 標準偏差 0.02 の正規分布に従う乱数で初期化される必要があるようです。以下のコードを実行して、メソッドを定義しましょう。
def weights_init(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
モデルの実装:Generator
次に、Generator クラスを定義します。Generator は、ランダムな数列を入力として受け取って、フェイクデータを生成するモデルです。以下のコードを実行します。
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.ConvTranspose2d(NZ, NGF * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(NGF * 8),
nn.ReLU(True),
nn.ConvTranspose2d(NGF * 8, NGF * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(NGF * 4),
nn.ReLU(True),
nn.ConvTranspose2d(NGF * 4, NGF * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(NGF * 2),
nn.ReLU(True),
nn.ConvTranspose2d(NGF * 2, NGF, 4, 2, 1, bias=False),
nn.BatchNorm2d(NGF),
nn.ReLU(True),
nn.ConvTranspose2d(NGF, NC, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
Generator の構造に関する詳しい説明は省略しますが、簡単に要約すると、
- 長さ
NZの数列を受け取り、 - 変換処理を繰り返し、最終的に h × w × c =
64×64×NCの画像を生成する
という処理を行います。今回の場合は、長さ 100 の数列から、 64 × 64 × 3 の画像を生成してくれます。「c 」というのは、画像のチャネル(RGB など)のことで、「c = 3 」はカラー画像であることを示しています。
モデルの実装:Discriminator
次は Discriminator です。Discriminator は、入力されたデータが本物か、偽物かを識別するモデルです。以下のコードを実行します。
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.Conv2d(NC, NDF, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(NDF, NDF * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(NDF * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(NDF * 2, NDF * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(NDF * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(NDF * 4, NDF * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(NDF * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(NDF * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
Discriminator は、Generator とは反対に 64 × 64 × 3 の画像を入力として受け取り、最後に1つの値(0.0~1.0 の範囲)を出力します。今回は、入力画像が本物だと判断すれば1に近く、偽物だと判断すれば0に近い値を出力するように成長していきます。
モデルの実装:インスタンス化
ここまでで定義したモデルをインスタンス化します。以下のコードを実行しましょう。インスタンス化と同時に、初期化メソッドも適用しています。
net_g = Generator(ngpu).to(device)
net_d = Discriminator(ngpu).to(device)
if (device.type == "cuda") and (ngpu > 1):
net_g = nn.DataParallel(net_g, list(range(ngpu)))
net_d = nn.DataParallel(net_d, list(range(ngpu)))
net_g.apply(weights_init)
net_d.apply(weights_init)
損失関数とオプティマイザーの定義
最後に、損失関数( criterion )とオプティマイザーを定義します。
損失関数は、モデルによる予測と正解のズレを評価する関数で、損失関数の値を小さくするようにモデルが成長していきます。オプティマイザー(最適化アルゴリズム)は、機械学習の進み方を最適化するモジュールです。
criterion = nn.BCELoss()
optimizer_g = optim.Adam(net_g.parameters(), lr=LR, betas=(BETA1, 0.999))
optimizer_d = optim.Adam(net_d.parameters(), lr=LR, betas=(BETA1, 0.999))
ここまでで機械学習の準備が整いました。本格的に GAN の機械学習を始めていきましょう!
機械学習でモデルを育てる
それでは、機械学習を実行して Generator と Discriminator を育てていきます。以下のコードを実行しましょう。
NUM_EPOCHS の設定値にもよりますが、機械学習が終わるまで数分~数時間かかります。 NUM_EPOCHS を 500 に設定したときは、だいたい 20 ~ 30 分ほどかかるようです。ループが進むごとにログが出力されるので、すべてのループが終わるまで待ちましょう!
※ Google Colaboratory を長時間操作しないと、セッションが切れてしまい、最初のセルからやり直しになってしまいます。小まめに画面を操作するなどして、セッションが切れないように注意してください。
def save_generator(net_g, path):
state = {
"model": net_g.state_dict()
}
torch.save(state, path)
g_losses = []
d_losses = []
fixed_noise = torch.randn(64, NZ, 1, 1, device=device)
img_list = []
label_list = []
for epoch in range(NUM_EPOCHS):
for i, (image, _) in enumerate(data_loader):
### Phase-1: Discriminator をアップデート
net_d.zero_grad()
# Step-1: Real データで機械学習
real_cpu = image.to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), REAL_LABEL, dtype=torch.float, device=device)
output = net_d(real_cpu).view(-1)
loss_d_real = criterion(output, label)
loss_d_real.backward()
d_x = output.mean().item()
# Step-2: Fake データで機械学習
noise = torch.randn(b_size, NZ, 1, 1, device=device)
fake = net_g(noise)
label.fill_(FAKE_LABEL)
output = net_d(fake.detach()).view(-1)
loss_d_fake = criterion(output, label)
loss_d_fake.backward()
loss_d = loss_d_real + loss_d_fake
d_g_z1 = output.mean().item()
optimizer_d.step()
### Phase-2: Generator をアップデート
net_g.zero_grad()
label.fill_(REAL_LABEL)
output = net_d(fake).view(-1)
loss_g = criterion(output, label)
loss_g.backward()
d_g_z2 = output.mean().item()
optimizer_g.step()
d_losses.append(loss_d.item())
g_losses.append(loss_g.item())
print("EPOCH [{epoch}] {loss_d}\t{loss_g}\t{d_x}\t{d_g_z}".format(
epoch="{:>3}/{:>3}".format(epoch + 1, NUM_EPOCHS),
loss_d="Loss_D: {:.4f}".format(loss_d.item()),
loss_g="Loss_G: {:.4f}".format(loss_g.item()),
d_x="D(x): {:.4f}".format(d_x),
d_g_z="D(G(z)): {:.4f} / {:.4f}".format(d_g_z1, d_g_z2)
))
if (epoch + 1) % 25 == 0:
with torch.no_grad():
fake = net_g(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=False))
label_list.append(epoch)
model_path = os.path.join(MODEL_DIR, "{}.pth".format(epoch + 1))
save_generator(net_g, model_path)
ロス推移を可視化
機械学習が終わったら、結果を確認していきます。まずは、Generator と Discriminator のロスの推移を確認します。以下のコードを実行し、グラフを出力しましょう。
plt.figure(figsize=(10, 5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(g_losses, label="G")
plt.plot(d_losses, label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
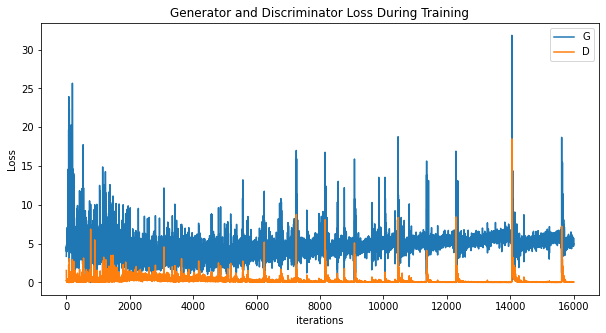
このグラフの横軸(iterations)はモデルを更新した回数で、縦軸はロス(損失関数の値)です。青線は Generator, オレンジ線は Discriminator の結果を示しています。詳細な解説は割愛しますが、機械学習中のロス推移を確認することで、モデルの学習が正しく進行しているかを判断できます。
今回のグラフを見てみると、後半は Discriminator のロスが低く、Generator のロスは高めです。後半はGenerator が作るフェイク画像が Discriminator に見破られがちになっているようですね。
生成画像の変化を可視化
次は、Generator が描く画像の変化を見ていきます。以下のコードを実行すると、機械学習ループ 25 回ごとに記録した Generator の出力画像がアニメーションで表示され、同時に gif 画像も出力されます。
fig, ax = plt.subplots(figsize=(8, 8))
plt.axis("off")
frames = []
for i, l in zip(img_list, label_list):
grid = plt.imshow(np.transpose(i, (1, 2, 0)), animated=True)
title = ax.text(
0.5,
1.01,
"epoch={}".format(l + 1),
ha="center",
va="bottom",
transform=ax.transAxes,
fontsize="large")
frames.append([grid] + [title])
ani = animation.ArtistAnimation(fig, frames, interval=1000, repeat_delay=1000, blit=True)
ani.save("animation.gif", writer="pillow")
HTML(ani.to_jshtml())

最初のうちはモヤモヤした画像が生成されていますが、中盤以降は寅の特徴を掴んだ画像になってきています。解像度が 64 × 64 なので若干ぼやけていますが、遠目で見れば寅っぽい画像もいくつかありますね!
ベストな1枚を描いてもらう
最後に、Generator さんにベストな寅画像を作ってもらいます。上手な寅画像を描いてもらうにはいくつかコツがありますので、順を追って説明していきます。
採用するモデルを決める
機械学習ループの最後の Generator が最高性能を発揮するとは限りません。Discriminator との競争度合いや、過学習(学習データに過剰に適応した状態)の発生によって、最終モデルが本気を出せていない可能性もあります。
そこで、先程のアニメーションを使って、上手に寅画像を描くことができている Generator を特定します。アニメーションを見つつ、上手な寅画像を描けていると思う「epoch」を確認してください。「epoch」はグリッドの上部に表示されます。
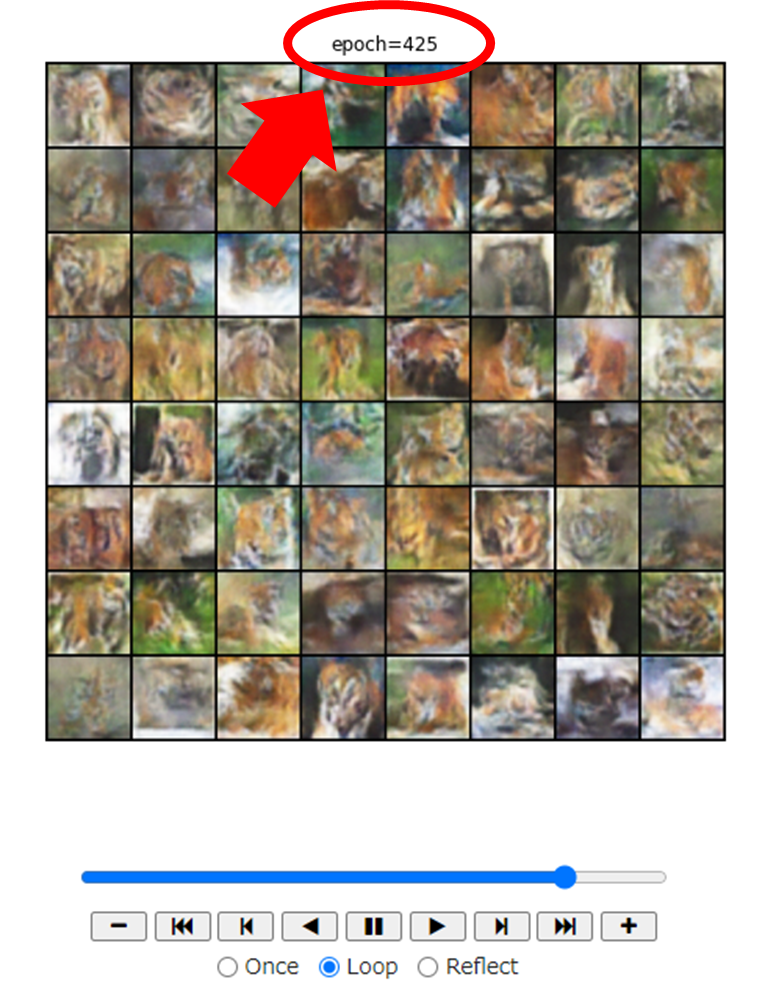
ベースとなる画像を決める
採用するモデルが決まったら、次は描いてもらう画像のベースを決めます。
アニメーションで表示される 64 枚の画像のうち、「これだ!」と思う画像を1つピックアップしましょう。基本的には、最も寅っぽい画像を選ぶのがおすすめです。
画像が 8 × 8 で並んでいるので分かりづらいですが、以下の図も参考に、選んだ画像のインデックスを特定してください。

ベース画像に似た画像を描き、ベストな1枚を選ぶ
Generator が描く画像には、「入力される数列が似ていれば、出力される画像も似たものになる」という性質があります。これを利用して、先程決めたベース画像に似た画像をいくつか生成し、ベストな1枚を選びます。
下記コードをコピーし、以下の変数を変更します。
- ピックアップしたモデルの epoch を
pickup_epochに、ベース画像のインデックスをpickup_img_idxに指定します。 -
stdはベース画像の数列に加える乱数ノイズの標準偏差で、小さいほどベース画像に似た画像が生成され、大きいほどバリエーション豊かな画像が生成されます。0.2~0.8程度がおすすめです。
変数を設定したら、コードを実行しましょう。
pickup_epoch = 425
pickup_img_idx = 59
std = 0.7
def load_generator(net_g, path):
checkpoint = torch.load(path)
net_g.load_state_dict(checkpoint["model"])
def generate_images(random_noise, device, net_g, output_png=True):
with torch.no_grad():
fake = net_g(random_noise).detach().cpu()
plt.figure(figsize=(20, 10))
for i, fake_img in enumerate(fake):
img = fake_img.to("cpu").detach().numpy().transpose((1, 2, 0))
img = (img * 255).astype(np.uint8)
if output_png:
path = os.path.join(OUTPUT_DIR, "{}.png".format(i))
pil_img = Image.fromarray(img)
pil_img.save(path)
plt.subplot(5, 10, i + 1)
plt.imshow(img)
base_noise = fixed_noise[pickup_img_idx]
random_noise = torch.normal(0.0, std, size=(50, NZ, 1, 1), device=device)
pickup_generator = Generator(ngpu).to(device)
state_path = os.path.join(MODEL_DIR, "{}.pth".format(pickup_epoch))
load_generator(pickup_generator, state_path)
generate_images(base_noise + random_noise, device, pickup_generator)
ベース画像に近い画像が 50 枚生成されるので、最も上手く描けているものを選びます。

画像本体( png ファイル)は output-images フォルダに出力されるので、ダウンロードすることも可能です。画面左側のフォルダアイコンをクリックし、 output-images ディレクトリ配下にある画像のファイル名を右クリックしてダウンロードします。ダブルクリックすると、プレビューを確認できます。画像は「インデックス.png」のファイル名になっています。
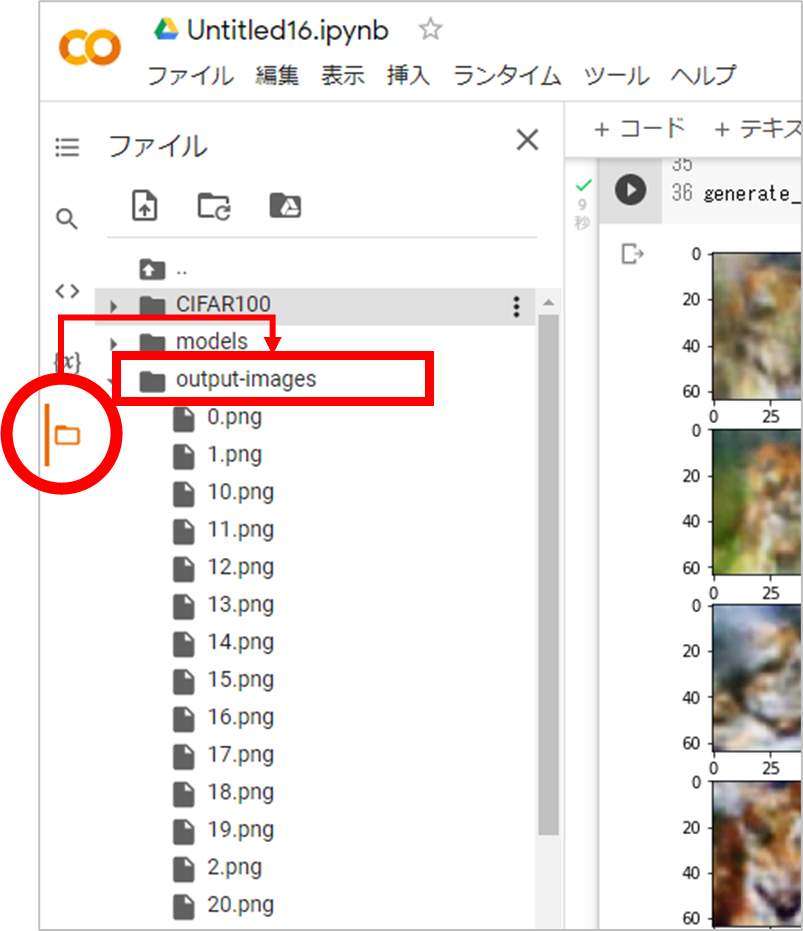
上記コードは実行する度に結果が変わるので、納得の行く画像がなければ、何度か繰り返し画像を描いてもらいましょう。
おわりに
今回は 2022 年の干支である「寅」を題材に、GAN で画像を作る方法をご紹介しました。Google Colaboratory での実行を想定しているので、AI の開発経験が無い方でも気軽にチャレンジできたはずです。
実は筆者のアイコンも、AI の学習を始めてから最初に GAN に描いてもらった「ネコ」のイラストです。GAN が生成する画像のクオリティや雰囲気は、扱うデータやパラメータの設定に大きく影響します。興味がある方は、この記事のコードも参考に、ご自身でいろいろと試行錯誤してみてください!