はじめに
こんにちは。株式会社ベーシックの AI・データ分析チームに所属している shitara です。
最近では AI に関する文献や WEB サイトも増え、(時間と覚悟さえあれば)誰でも気軽に AI づくりに挑戦できます。実際のビジネス課題に即したテーマで自身の AI スキルを試すために、「AI コンペ」に挑戦している方も多いのではないでしょうか。
この記事では、AI コンペに チームで参加する ことに焦点を当てて、私のチームで実践している Google Cloud Platform(GCP)を使った Jupyter Notebook ベースの開発環境づくりや、ちょっとしたTipsをご紹介できればと思います。チームでの挑戦を検討している方々や、過去にチーム参加で失敗した経験をお持ちの皆さんに、少しでも参考になれば幸いです!
AI コンペとは?
AI コンペでは、特定の課題に対して期限内にモデルを開発し、スコアを競います。SIGNATE や Kaggle が有名で、実際のビジネス課題に触れつつ自身のスキルを試すことができます。
チーム参加が許可されているコンペでは、複数人で協力してモデルを作成し、予測結果を提出することができます。人数が多い分、チーム参加の方が有利に思えるかもしれませんが、メンバー間の連携がうまくできないと、十分な力を発揮できずに終わってしまうことも多いです。
チーム参加のメリット・デメリットは、次のようなものが挙げられます。
メリット
- メンバー間で知見やスキルを共有でき、仲間と協力して課題に挑戦することができます。
- 複数人で並行して作業ができるため、時間を有効に使うことができます。
- 他のメンバーの頑張りが刺激となり、スキルアップのモチベーションに繋がります。ベテランと新人でタッグを組むことで、スキルの継承にも役立ちます。
デメリット
- 人数分の高性能マシンや、チームの共有ストレージなど、開発に必要なリソースが個人参加に比べて多くなります。
- チーム開発を行うための環境づくりに時間をかけすぎると、本来の目的であるモデルづくりに費やす時間が少なくなってしまいます。
- 複数人が次々とモデルを作っていくことになるため、最高スコアやパラメータ設定といった情報の共有・管理が大変です。
これらのメリット・デメリットを踏まえて、短時間で構築でき、かつモデルやスコアの管理を簡略化するための環境づくりについてご紹介していきます。
前提
この記事は、以下の読者の方々を想定しています。
- Git でコード管理をしたことがある
- Google Cloud Platform (GCP)でプロジェクトを作った経験がある
- PyTorch で機械学習を実施した経験がある(記事中に登場するコードは、PyTorch を前提としています)
- Jupyter Notebook で機械学習コードを作成した経験がある
GCP のセットアップ方法などについては、この記事では解説していません。また、具体的な機械学習コードの紹介ではなく、お手元の Notebook ファイルを実行するための環境づくりに焦点を当てています。GCP がメインの内容ですが、システム開発やクラウド基盤構築の経験が無くても大丈夫です!
GCP でチーム開発の環境を整える
ディープラーニングなど、高度な AI モデルを開発するには、GPU を搭載した高性能マシンが必要です。チーム参加の場合、これらの高性能マシンを人数分用意する必要があり、物理的に設備を整えるには膨大な費用がかかってしまいます。
そこで今回は、GCP の仮想マシン(VM)を使って、メンバーの作業マシンを確保します。VM は従量課金制で、スペックや GPU の有無を自由に設定できるので、少ない費用で必要十分なスペックの開発マシンを用意できます。今回は、GCP のサービスの一つである「 Vertex AI 」の Notebook 機能を利用して、機械学習に適した VM を短時間で準備していきます。
また、メンバーが作成したデータを管理するためのストレージとして、Google Cloud Storage (GCS)も活用します。これにより、モデルの管理だけでなく、機械学習に必須となる学習データも合わせて管理できます。
今回ご紹介する開発環境の全体像は次の図の通りです。

それでは、いくつか要点をピックアップして説明していきます。
コードは git で管理する
チームでコンペに参加するときは、Notebook のコードを git で管理するようにしましょう。例として、以下のようなルールを決めておくと、チームにとって本当に必要なコードのみを共有できるようになります。
-
個人の作業は「個人作業用ブランチ」を切って行う。
-
「すべてのセル出力をクリアし、先頭から全セルをエラーなく実行できる状態」になっている場合のみ、.ipynb ファイルをコミットする。
-
作業が終わったら、不要なコード(個人で試行錯誤した部分など)以外の、チームにとって必要な部分のみを親ブランチにマージする。
VM の JupyterLab にブラウザからアクセスして開発を進める際、大量のデータが git の追跡対象に加わってしまうと、 JupyterLab の画面が重くなることがあります。これを回避するために、 .ipynb ファイルと合わせて .gitignore ファイルも作成し、不要なファイルが追跡対象に加わらないように制御しておきましょう。
Vertex AI で仮想マシンを用意する
GCP のサービスの一つである Vertex AI の Notebook 機能を利用すると、ディープラーニングに適した VM をすぐに利用することができます。この VM は、JupyterLab (Jupyter Notebook の開発環境)があらかじめセットアップされており、さらに追加設定で PyTorch などのライブラリもプリインストールしておくことができます。もちろん VM を複数立てることもできるので、チームのメンバー分の開発マシンをすぐに準備可能です。
VM を立てる手順は以下の通りです。

VM のスペックや GPU の設定は、「マシンの構成」と「GPU」の項目で行います。「新しいインスタンス」のドロップダウンで「PyTorch 1.9」を選んだ場合は、「詳細オプション」をクリックすることで、詳細設定画面に遷移します。GPU を搭載するときは、「NVIDIA GPU ドライバを自動的にインストールする」に必ずチェックを入れましょう。

VM を立てる際のポイントをいくつかご紹介します。
-
インスタンスを誰が管理しているのかを明確にするため、作業しているメンバーが分かるようなインスタンス名にした方が良いです。
-
使用できる GPU の種類(スペック)は、VM インスタンスを立てる際のゾーン設定によって異なります。詳しくは こちらの公式ページ に記載されています。特にこだわりがなければ、GCS のバケットと同じリージョンに設定することをおすすめします。
-
CPU・RAM の設定、および GPU の種類・数の設定は、VM を立てたあとでも変更できます。少しでも費用を抑えたい場合は、低スペックの VM を立てておき、必要に応じてスペックを上げていくと良いです。

VM を作成すると、時間経過によって料金が発生します。ここでの料金は、VM の計算リソース(CPUやGPU)に対する「Compute Engine の料金」と、VM 自体のブートディスクやストレージに対する「データ保存料金」の和であり、VM の稼働状態に応じて以下のように発生します。
| 稼働状態 | Compute Engine の料金 | データ保存料金 | VMに保存したデータ |
|---|---|---|---|
| 稼働中 | 料金が発生 | 料金が発生 | 残る |
| 停止中 | 料金は発生しない | 料金が発生 | 残る |
| 削除 | 料金は発生しない | 料金は発生しない | 消える |
必要なデータを GCS に出力し、さらに開発したコードを Git で管理することを徹底すれば、VM にデータを残し続ける必要はなくなります。機械学習で長時間稼働させる場合を除いては、小まめに VM を削除した方が良いでしょう。
GCS でデータの共有場所を用意する
VM でメンバーの開発マシンが用意できたら、次はデータの保管場所を準備します。Google Cloud Storage (GCS)は、99.999999999%(イレブンナイン) の年間耐久性を誇る GCP のストレージサービスで、形式や容量に囚われず様々なデータを保管することができます。
この GCS を利用することで、機械学習に使用する特徴量エンジニアリング済みの加工データや、生成されたモデルといったデータを、一箇所でまとめて管理できます。
以下のポイントも参考に、GCS にバケットを準備します。
-
バケットはコンペ単位ではなく、全コンペで共通のものを一つ立てることをおすすめします。この場合、コンペに使用するデータは、バケット内にそれぞれのコンペ単位でフォルダを切って管理します。これにより、後述の「ライフサイクルルール」を一括で設定できます。
-
バケット名はグローバルに一意である必要があります。個人情報や機密情報が含まれないように注意しましょう。
-
ロケーションを VM と同じにすることで、通信にかかる料金や時間を削減できます。
-
バケットに「ライフサイクルルール」を設定することで、長時間使用しないデータの保存料金を自動的に抑えることができます。ライフサイクルルールはバケット内の全データに適用されるので、大量のデータを個別に管理する手間を省くことができます。
Notebook で GCS のデータにアクセスするときは、以下のメソッドを定義しておくと便利です。
from google.cloud import storage
GCP_PROJECT_NAME = "your_project_name"
GCS_BACKET_NAME = "your_backet_name"
storage_client = storage.Client(project=GCP_PROJECT_NAME)
gcs_bucket = storage_client.bucket(GCS_BACKET_NAME)
def download_from_gcs(gcs_obj_name, file_name):
blob = gcs_bucket.blob(gcs_obj_name)
blob.download_to_filename(file_name)
def upload_to_gcs(file_name, gcs_obj_name):
blob = gcs_bucket.blob(gcs_obj_name)
blob.upload_from_filename(file_name)
Notebook で開発をはじめる
VM インスタンスの準備が整ったら、JupyterLab で開発をスタートしましょう。Vertex AI の Notebook 画面で、VM の「JUPYTERLAB を開く」をクリックします。まだボタンがアクティブになっていない場合はしばらく待ちましょう。

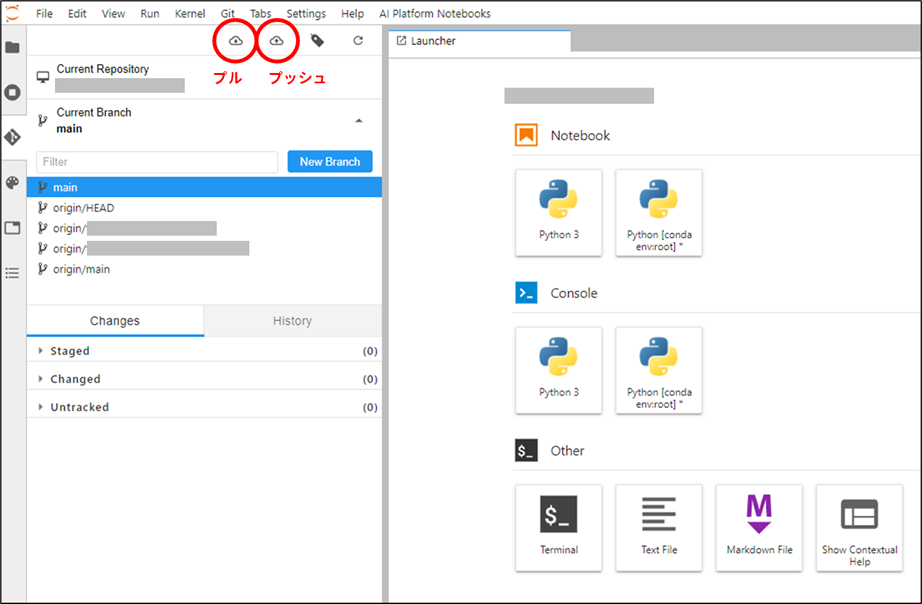
VM 作成後に初めてアクセスした場合は、git のクローンから始めましょう。

クローンが完了したら、次はブランチを切り替えます。リポジトリのディレクトリに移動した状態で、「Git」メニューをクリックし、「Current Branch」を変更します。

作業用ブランチに切り替えたら、いよいよ開発を始めます。JupyterLab でのコーディングや各種設定については、ここでは割愛します。カラーテーマの変更や行番号表示など、それぞれの好みに合わせた設定で開発を進めましょう!
機械学習を行う際は、生成したモデルを GCS に出力していきます。後述の Identification 情報も一緒に出力することで、モデル本体とパラメータ等の設定をペアで保管します。
コーディングが一通り終わったら、コードをコミットします。
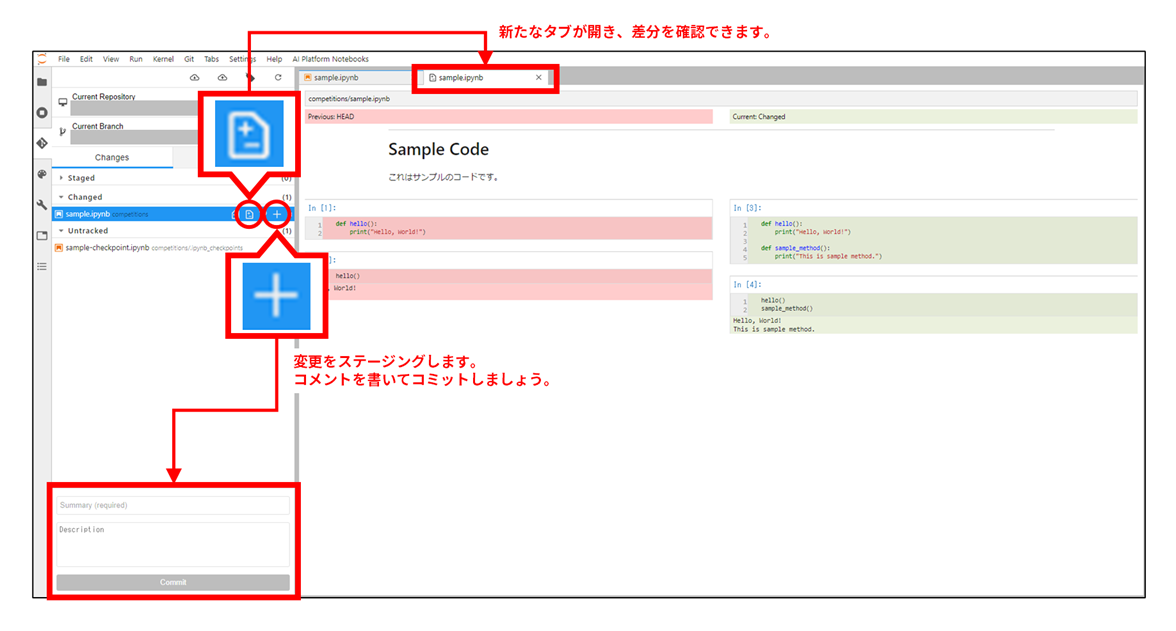
一通り作業が終わったら、ブランチをプッシュします。
以上がモデル開発の流れです。各メンバーが作成したモデルは GCS に集約されていくので、最も高性能なモデルの予測結果をコンペに提出しましょう。同時に、各メンバーのコードも Git リポジトリに集約されていきます。メンバー間で知見や実装アイデアを共有することで、チーム全体のスキルアップに繋がります。
バックグラウンドで実行する
開発が一段落したら、機械学習のループを回して本格的にモデル作成フェーズに入ります。モデルのネットワークサイズにもよりますが、長時間 Notebook を実行したまま放置することもあるでしょう。
この間、ネットワークの切断などで VM とのセッションが切れ、再接続に失敗すると、セルの実行結果を確認できなくなります。セッションが切れても JupyterLab の kernel が稼働していれば、裏では処理が進行していきますが、セルの出力や学習時のロス推移を把握することはできません。
そこで、コーディングが一段落し、セル全体を実行する段階になったら、バックグラウンドで Notebook を実行してみましょう。以下の手順で VM インスタンスに SSH 接続することで、コンソールを開くことができます。
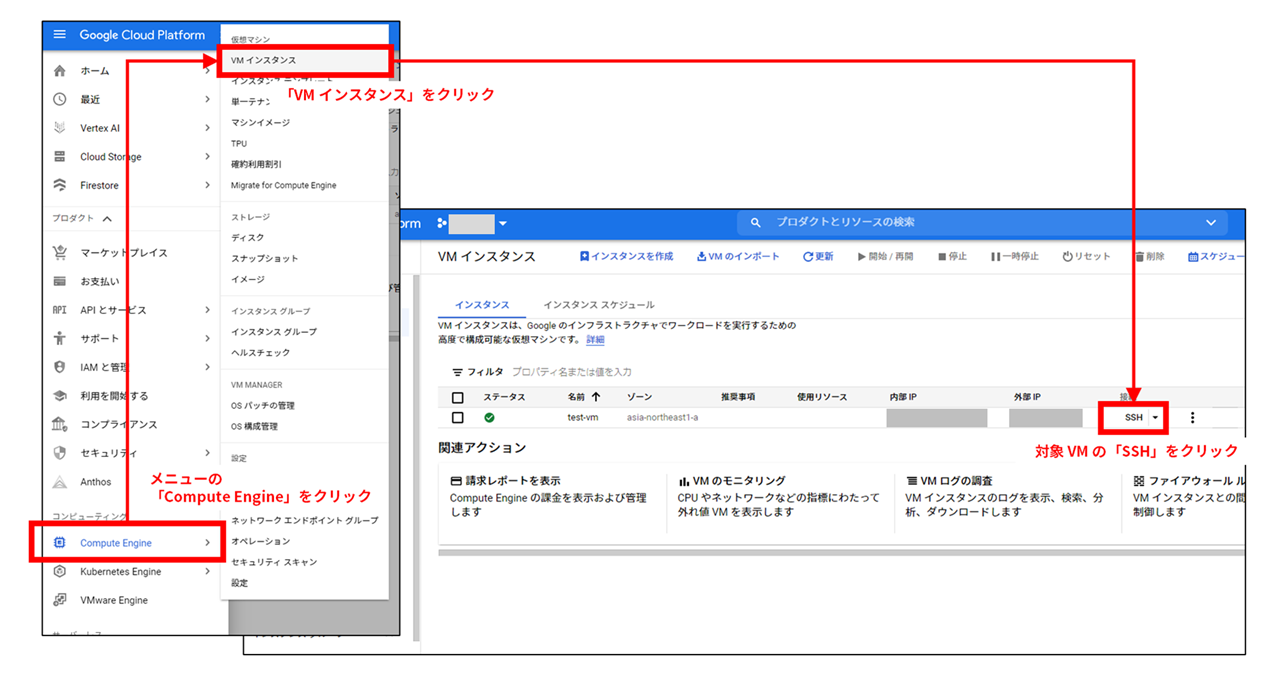
VM を作成した直後は、SSH 接続に失敗することがあるようです。筆者の場合、1時間ほど待ってみるとうまく SSH 接続ができるようになりました。コンソールが開いたら、実行対象の .ipynb ファイルをコマンドから実行します。実行方法や停止方法については、 こちらの記事 で詳しく解説されています。
実行後は、less +F コマンド等で学習時のログを追跡しましょう。
チーム開発の Tips
これまでに紹介した環境を作ることで、各メンバーが作成したモデルとコードを、チーム全体で共有することができるようになりました。さらにちょっとした工夫を加えることで、モデルの管理や学習の連携が簡単になります。ここでは、私のチームで実践している Tips をご紹介します。
モデルに身分証明書をつける
モデルを作る際、モデル作成者やパラメータ設定、投入した学習データの種類、ロスの推移など、様々な情報を管理する必要があります。私のチームでは、モデルファイルと同じフォルダに「身分証明書(Identification)」ファイルを置いておくことで、そのモデルが何者なのかを判断しやすくしています。
以下が Identification の例です。Identification に記録しておく情報は、コンペの内容や課題によって異なる可能性があるため、適宜変更します。
import json
from google.cloud import storage
class Identification():
def __init__(
self,
trainer,
model_id,
gcp_project_id,
gcs_backet,
gcs_path,
gcs_dataset_path,
batch_size,
random_seed,
model_name,
model_setting,
optimizer_name,
optimizer_setting,
scheduler_name,
scheduler_setting,
):
self.trainer = trainer
self.model_id = model_id
self.gcp_project_id = gcp_project_id
self.gcs_backet = gcs_backet
self.gcs_path = gcs_path
self.gcs_dataset_path = dataset_path
self.batch_size = batch_size
self.random_seed = random_seed
self.model_name = model_name
self.model_setting = model_setting
self.optimizer_name = optimizer_name
self.optimizer_setting = optimizer_setting
self.scheduler_name = scheduler_name
self.scheduler_setting = scheduler_setting
self.loss_history = []
@property
def model_generation(self):
return len(self.loss_history)
def append_loss(self, loss):
loss["trainer"] = self.trainer
self.loss_history.append(loss)
def export_to_gcs(self):
settings = self.__dict__
file_name = "{}_identification.json".format(self.model_id)
with open(file_name, "w") as f:
json.dump(settings, f, indent=4)
print("save identification: {}".format(file_name))
output_path = "{}/{}".format(self.gcs_path, file_name)
storage_client = storage.Client(project=self.gcp_project_id)
bucket = storage_client.bucket(self.gcs_backet)
blob = bucket.blob(output_path)
blob.upload_from_filename(file_name)
print("upload identification: {}".format(file_name))
def __str__(self):
return json.dumps(self.__dict__, indent=4)
インスタンス化する際は、機械学習の設定を引数として与えます。インスタンスを print() すると、その時点での設定情報やロス履歴が確認できます。
setting = {
"gcp_project_id": "YOUR_PROJECT_ID",
"gcs_backet": "YOUR_BACKET_NAME",
"gcs_path": "path/to/competition/dir",
"gcs_dataset_path": "path/to/dataset",
"batch_size": 16,
"random_seed": 42,
"model_name": "Faster_RCNN",
"model_setting": {
"backbone": "resnet50"
},
"optimizer_name": "SGD",
"optimizer_setting": {
"lr": 0.001,
"momentum": 0.9,
"weight_decay": 0.0005
},
"scheduler_name": "CosineAnnealingLR",
"scheduler_setting": {
"T_max": 5,
"eta_min": 0.0001
},
}
idf = Identification(
trainer="YOUR_NAME", # モデルの作成者を記録しておく
model_id="YOUR_MODEL_ID", # モデルを一意に識別する ID をつける
**setting
)
print(idf) # idf インスタンスが持つ情報やロス履歴が表示される
機械学習時の使用イメージです。train() と valid() は機械学習と検証を実行するメソッドで、それぞれのロスを戻り値として返す想定です。また、 export_model_to_gcs() はモデルを GCS に出力する処理を行います。実際に下記コードを実行するには、作成する AI に合わせてこれらのメソッドを定義する必要があります。以下の例では、1エポックごとにモデルと Identification ファイル(.json)が GCS に出力されます。
# 学習が始まる直前でインスタンス化
setting = {
# 省略
}
idf = Identification(
trainer="YOUR_NAME",
model_id="YOUR_MODEL_ID",
**setting
)
NUM_EPOCH = 10
for epoch in range(NUM_EPOCH):
new_generation = idf.model_generation + 1
loss = {}
loss["generation"] = new_generation
loss["train"] = train() # 学習(別途実装)
loss["valid"] = valid() # 検証(別途実装)
# ロス履歴に情報を追加
idf.append_loss(loss)
# モデルと identification の出力
export_model_to_gcs() # モデルをGCSに出力(別途実装)
idf.export_to_gcs() # identification を同じフォルダに出力
私たちのチームでは、GCS に出力された Identification の json ファイルを読み込み、モデルごとにグラフを描画するコードを作成し、複数のモデル間で精度を比較するようにしています。学習時のパラメータも json ファイルに記載されているので、どのような設定が効果的だったのかも合わせて把握できます。
学習の「パス回し」ができるようにする
チームでモデルを開発していると、一つのモデルを一人が作り切る必要はありません。例えば 10 エポックまでは A さんが作成し、ロスの推移等を確認しつつ、継続して学習が必要であれば、11 エポック以降は B さんが機械学習を行っても良いわけです。このような「パス回し」を実現するには、機械学習を途中から再開できるような仕組みが必要です。
「パス回し」の実現には、以下の課題があります。
- パス前後で同じ学習データを参照できるようにする
- 直前のモデルに加え、optimizer や scheduler などの設定を引き継げるようにする
上記の課題 1. に対しては、前述の Identification を使えば対応できます。json ファイルに記載されている学習データと同じものを使って、継続学習を行えば良いです。
課題 2. に対しては、モデル本体に加えて optimizer と scheduler の状態も保存しておく必要があります。PyTorch でこれを実現するには、以下のコードを実装しましょう。
import torch
def save_model(file_name, model, optimizer, scheduler):
state = {
"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"scheduler": sheduler.state_dict()
}
torch.save(state, file_name)
print("save model: {}".format(file_name))
def load_model(file_name, model, optimizer, scheduler):
checkpoint = torch.load(file_name)
model.load_state_dict(checkpoint["model"])
optimizer.load_state_dict(checkpoint["optimizer"])
scheduler.load_state_dict(checkpoint["scheduler"])
for state in optimizer.state.values():
for k, v in state.items():
if isinstance(v, torch.Tensor):
state[k] = v.to("cuda")
print("load model: {}".format(file_name))
save_model() メソッドを使用すると、model, optimizer, scheduler を一纏めにしたファイルをローカルに保存します。実際の機械学習では、このローカル保存したファイルをさらに GCS にアップロードすることで、他のメンバーが各自の作業用 VM にダウンロードして利用できるようになります。
一方、load_model() メソッドは、ローカルのファイルを読み込み、model, optimizer, scheduler の内部状態を復元します。Identification に記録された情報をもとに model, optimizer, scheduler のインスタンスを作ってから、それらを引数にして load_model() を呼び出すことで、記録された状態・重みがセットされ、続きから学習を再開できます。
おわりに
いかがでしたでしょうか。
環境整備の煩わしさや情報共有の大変さから、チームでのコンペ参加に抵抗を持っている方も多いと思います。ですが、実際にチームでコンペに挑戦してみると、メンバー間で協力できるだけでなく、他のメンバーの頑張りが刺激となってチーム全体の活性化にも繋がっていきます。
この記事が少しでも参考になれば幸いです!