この記事の要約
- ONTAP 9.12からの新機能であるData Duality(単一のストレージボリュームに、S3とNFSの2つのプロトコルで同時アクセスできる機能)をAmazon SageMakerと組み合わせて活用してみました
- 機械学習ワークロードでData Dualityの活用する際は、各プロトコルをこんな感じで使い分けると良いと思います
- S3: データ収集のフェーズで、多数のデバイスから学習用データを収集する際に使用
- NFS: モデルのトレーニングのフェーズで、学習ノードから集めた学習用データに高速アクセス
- S3バケットから学習ノードにデータセットをダウンロードしてくる時間と手間を省けるので、重たいデータセットを使って学習したい時なんかに特に便利です
データの観点から見た機械学習のボトルネック
ちょっとした前置きを挟みますので、技術的な部分だけ見たい方はこちらへ。
機械学習ワークロードはおおまかに以下の3つのフェーズに大別することができます。
- データ収集
- 学習(モデルのトレーニング)
- 推論(トレーニングしたモデルの運用)
時に膨大なデータを処理する機械学習ワークロードにおいて、そのデータの流れに着目した場合、このなかで特にボトルネックを生みやすいのが1→2の間のデータの受け渡しです。
データ収集のフェーズでは、データの収集先(データレイク)としてAWS S3などのオブジェクトストレージがよく用いられます。オブジェクトストレージは以下のような理由からデータ収集のワークロードに適しています。
- スケーラブル(拡張性が高い)
- メディアファイルなども含む様々な形式のデータを格納できる
- HTTP/HTTPS経由でデータにアクセスできる(多様なクライアントに対応)
一方で学習フェーズでは、モデルの学習時間をできるだけ短縮したいといった理由から特定の数台のサーバ(学習ノード)から高速にデータアクセスできる、ということがストレージへの主な要件になります。こういったユースケースではNFSやiSCSIといったプロトコルによるデータアクセスが有力な選択肢になりますが、AWS S3をはじめとするオブジェクトストレージは直接これらのプロトコルを介してデータボリュームをマウントすることができません。1
従ってモデルの学習を行う際に、予め学習に使用するデータセットを、学習ノードのローカルファイルシステムやファイルサーバなどに一旦ダウンロードするという処理が必要になるというケースが多々あります。この際、データセットが巨大であればあるほど、ダウンロードに時間がかかり、実際にモデルの学習が始まるまでになが〜い待ち時間が発生します。
いくら性能がよい(そして単価の高い)GPUサーバもデータサイエンティストも、この時間はただ待つことしかできません。
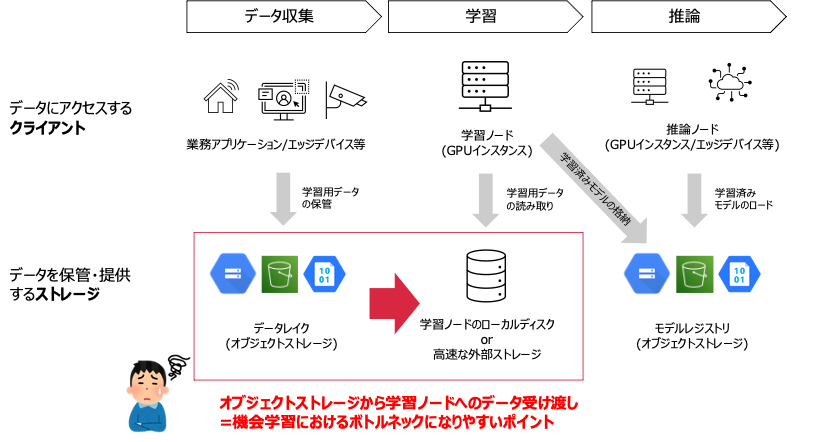
コンピュートの計算能力(GPU性能)、データセットのサイズ、ネットワーク帯域, etcにも依存するので一概には言えませんが、このオブジェクトストレージから学習用ノードへデータを受け渡す際の待ち時間は、学習フェーズにおけるボトルネックになりやすいポイントと言えるでしょう。
そこでこのデータの受け渡しをONTAPのData Dualityによって解決しよう!というのが、以下の趣旨になります。
Data Dualityを活用してみよう
ということで今回の本題です。
弊社ネットアップのONTAPというストレージOSでは、単一のボリュームに対してNFSとS3で同時アクセスできる機能(Data Duality)がサポートされています。
これを機械学習に応用すると、S3プロトコル経由で集めたデータをそのまま、学習用のコンピュートなどからNFSでマウントすることができます。つまり機械学習のボトルネックになりがちなオブジェクトストレージから学習ノードへのデータダウンロードを待つことなく、すぐさまモデルの学習を開始できるということです。
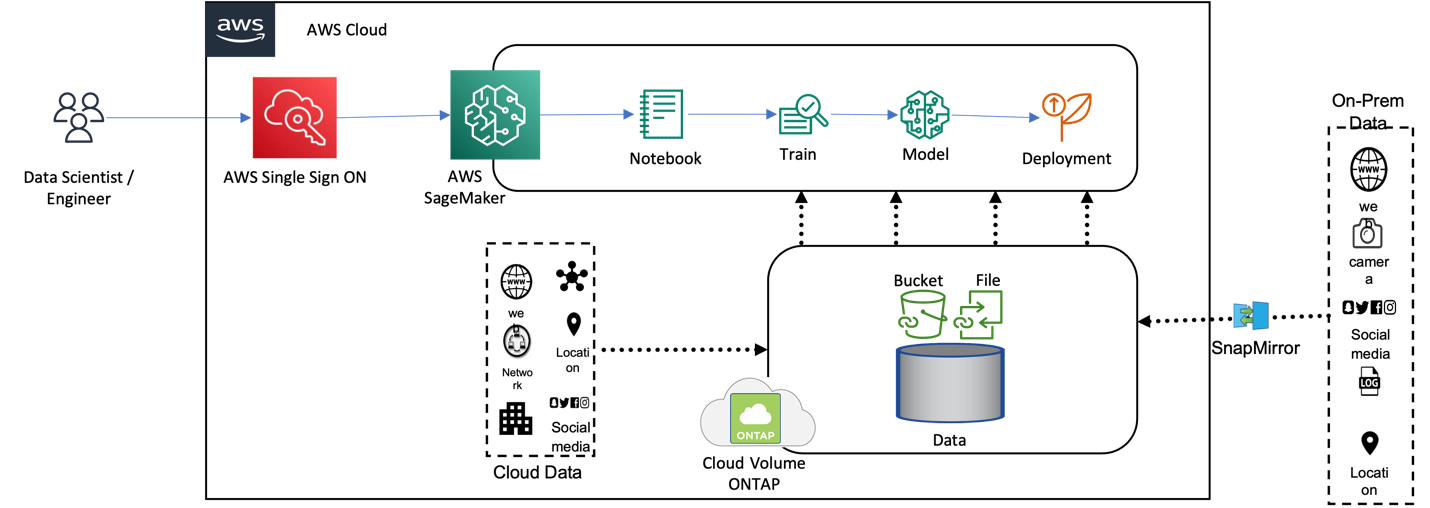
上記はネットアップがData Dualityの具体的な活用例として示しているリファレンスアーキテクチャで、AWS SageMakerによるモデル学習のワークロードにクラウド版ONTAPであるCloud Volumes ONTAPを組み合わせたものとなっています。
なおData DualityはAWSだけでなくONTAP 9.12以降であればオンプレでも他のクラウドサービスプロバイダーでも利用できます。
上記アーキテクチャ以外にも、Vertex AI + CVO(GCP)やセルフマネージドなKubeflow + オンプレONTAPといった具合に、お使いの機械学習プラットフォームに合わせて応用できそうです。
環境構築手順
それでは上記アーキテクチャを実際に構築してみます。構築手順は以下の通り、大まかに3ステップです。
- Cloud Volumes ONTAPのセットアップ
- Amazon SageMaker(ノートブックインスタンス)のデプロイ
- ノートブックインスタンスからのData Dualityによるストレージアクセス
1. Cloud Volumes ONTAPのセットアップ
CVOはネットアップのサービスポータルであるBlueXPを介して、各クラウドプロバイダー上に払い出すことができます。
前提としてBlueXPへのサインアップとBlueXPコネクターと呼ばれるコンポーネントのデプロイが必要になりますが、今回は既に実施済みのものとして割愛します(詳細はこちら)
CVOのデプロイ
CVOインスタンスのデプロイ自体は本アーキテクチャ固有のものではありませんので、詳細は以下折りたたみ内をご確認ください。
BlueXPによるCVOデプロイ手順
BlueXPのトップ画面から** + Add Working Environment**をクリック
Amazon Web Serviceを選択し、さらにCloud Volumes ONTAP(またはCloud Volumes ONTAP HA)のAdd newボタンをクリック
CVOのインスタンス名(=ONTAPクラスタ名)と、管理用の認証情報を入力
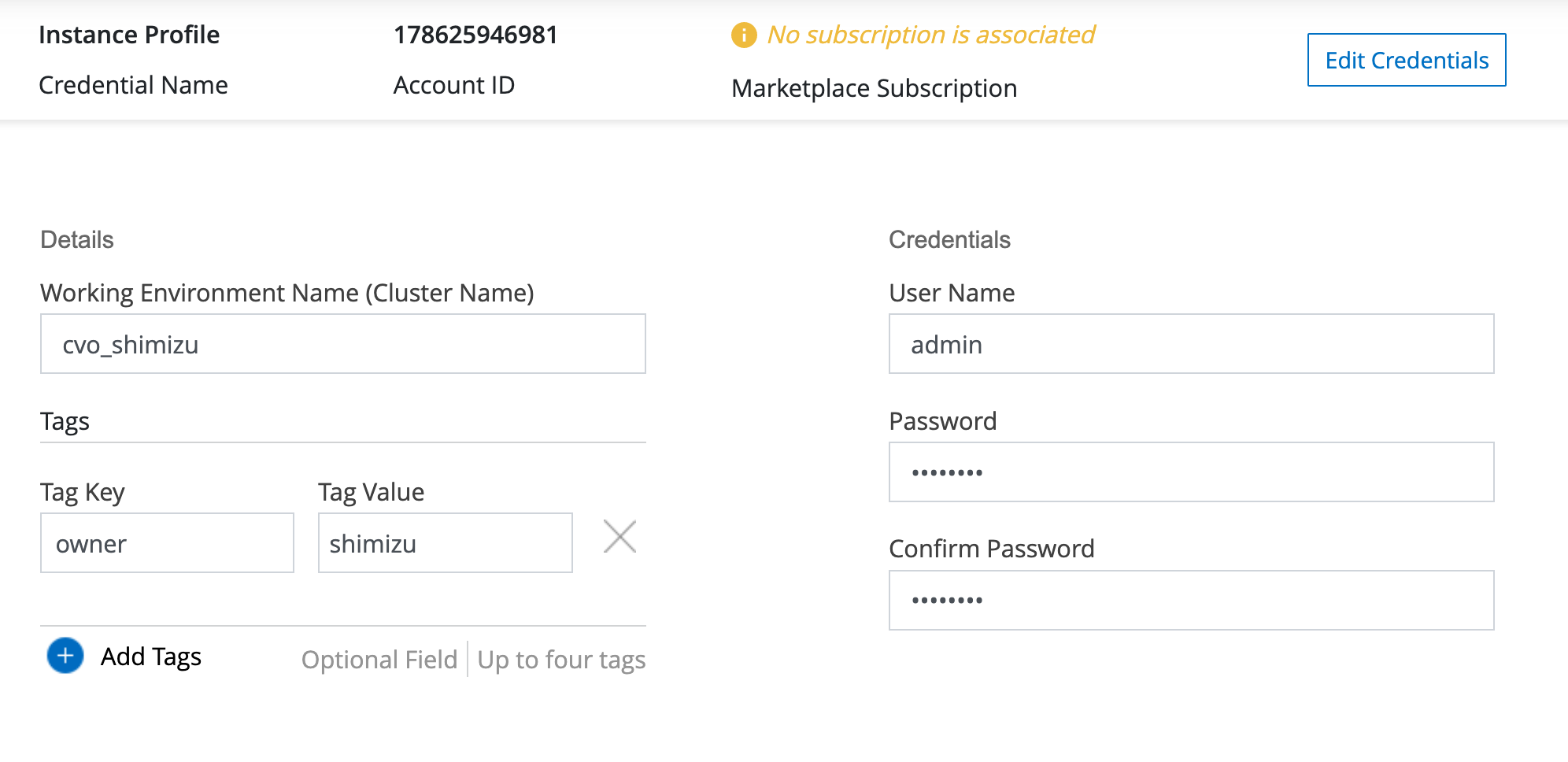
必要に応じてオプションサービスを選択(今回は全部無効)
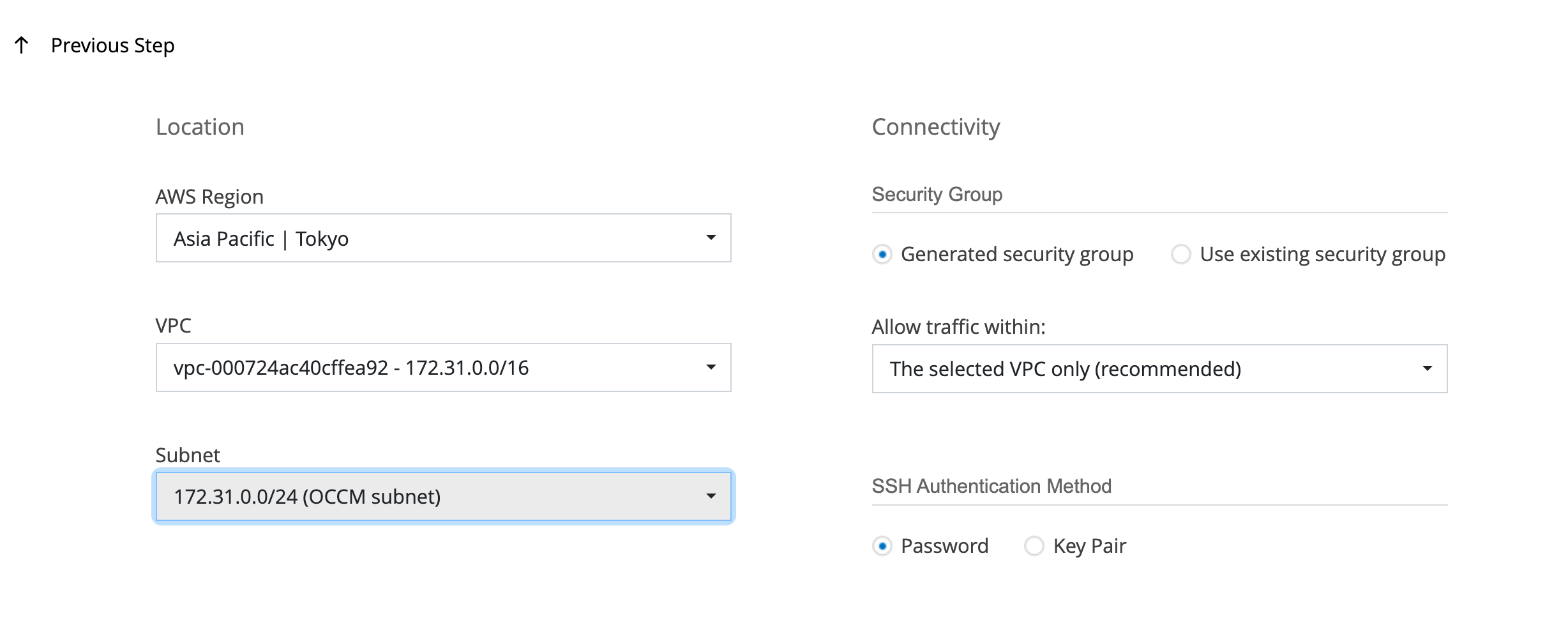
CVOインスタンスをデプロイするネットワーク情報を入力
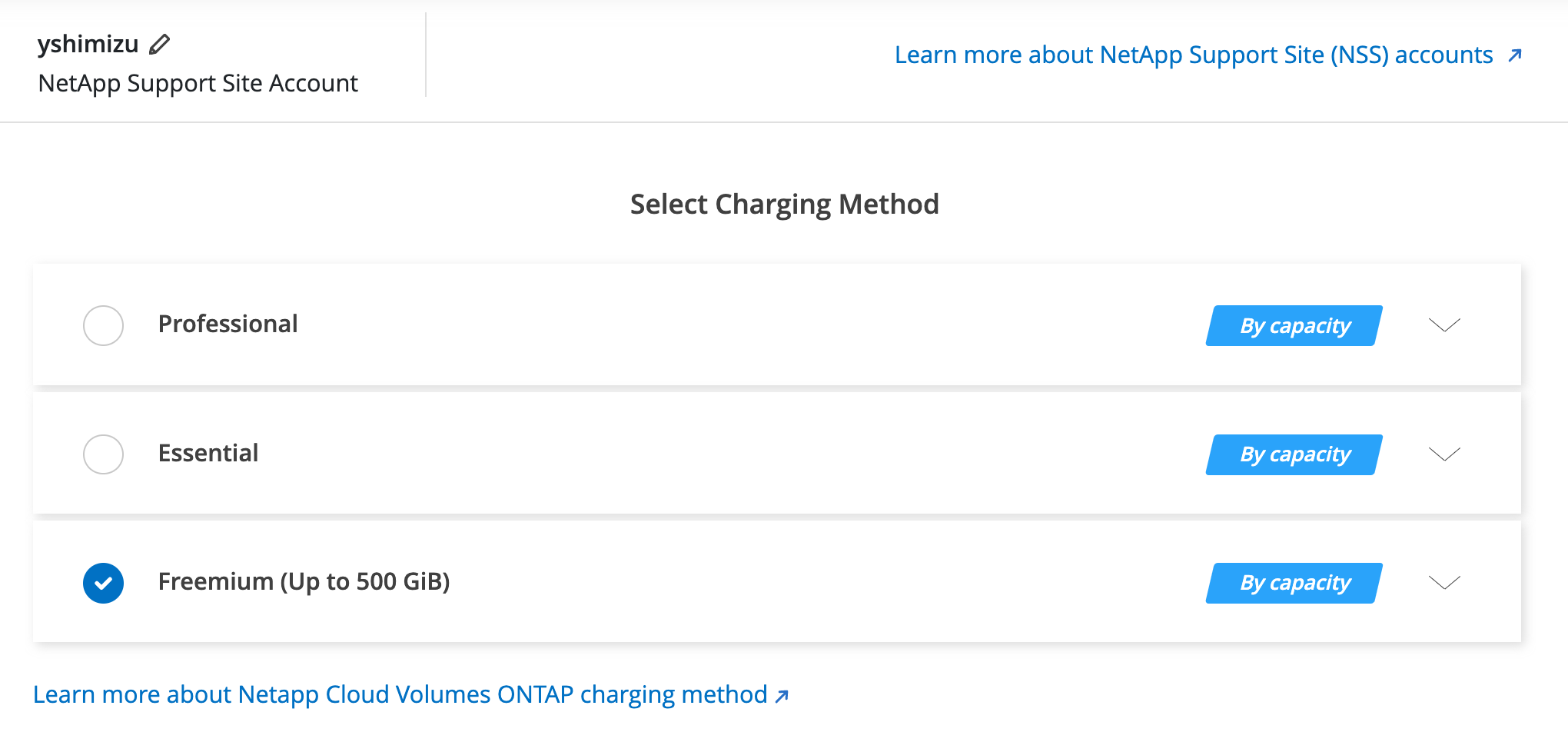
サブスクリプションプランを選択(今回は検証用なのでFreemium)
ONTAP上に作成するワークロード(ボリューム等)を設定
今回は100GBのNFSボリュームを作成(後の手順でこちらを使ってData Dualityを設定)
また同一VPC内からのアクセスのみを許可するexport policyも設定。
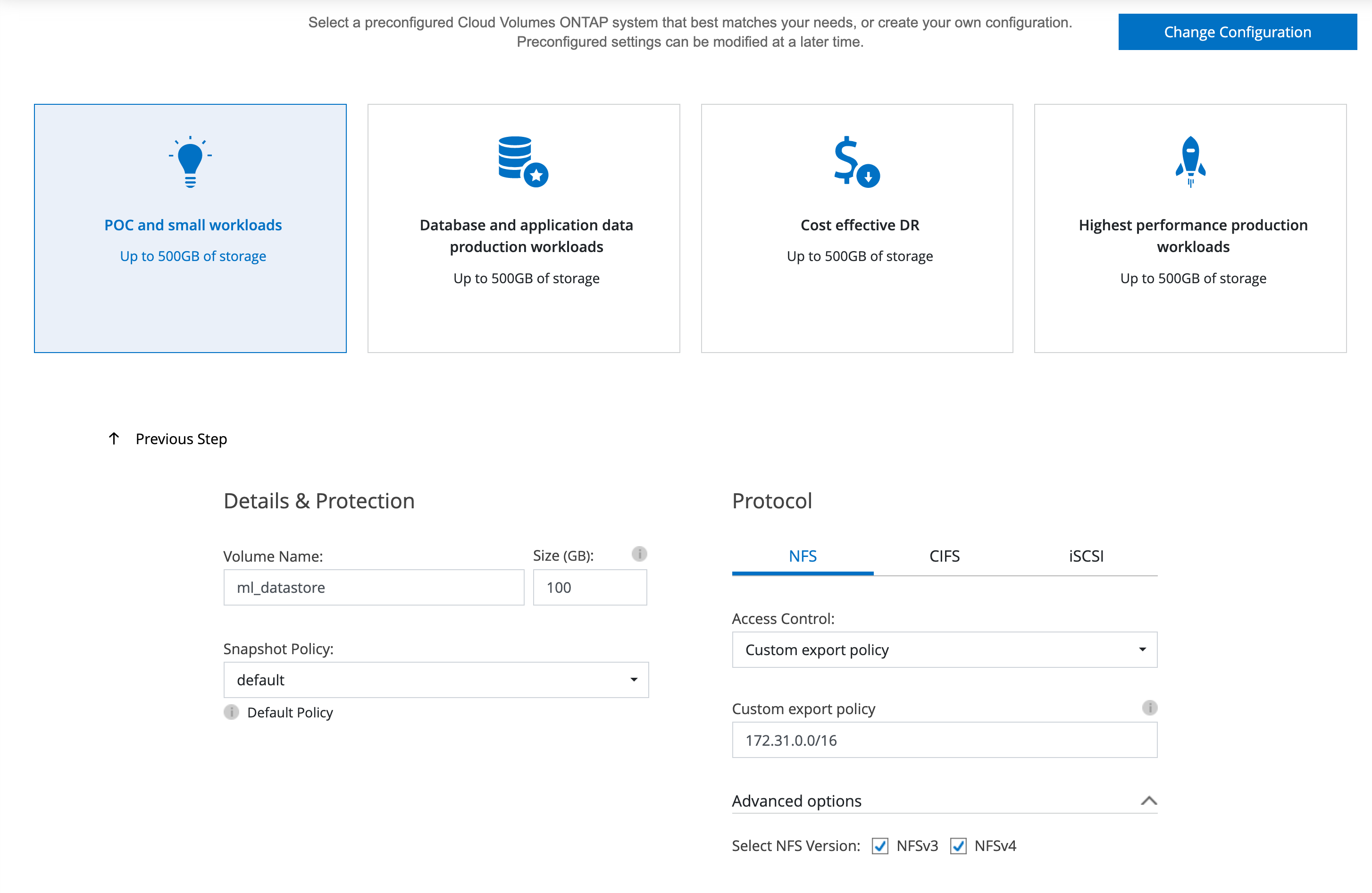
重複排除やストレージ階層化の設定。今回の検証には影響ありませんが、オンにするとストレージのコスト効率が向上します。

内容確認して、CVOのデプロイ開始。結構時間かかりますので気長に待ちます。
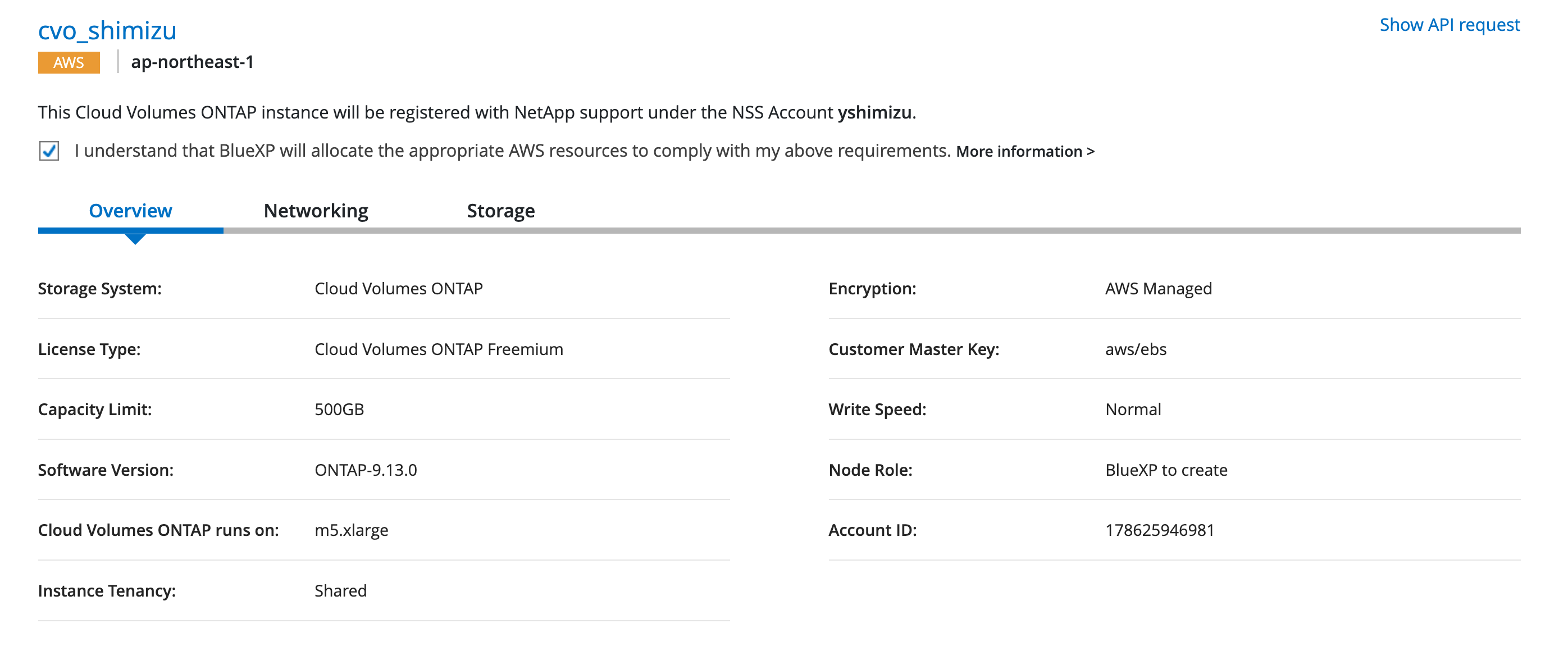
デプロイが完了すると、BlueXPのキャンバス上にCVOインスタンスが追加されます。
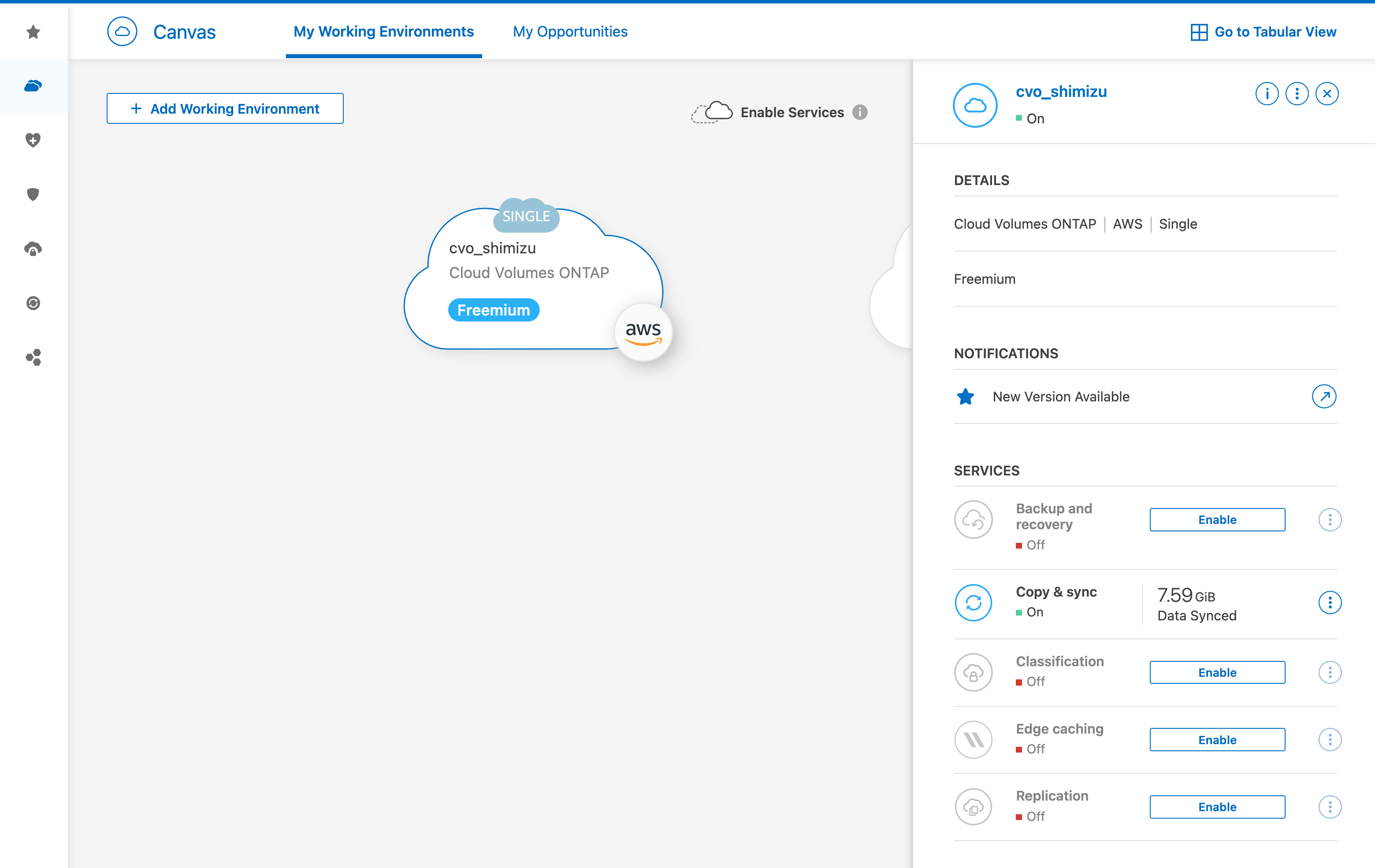
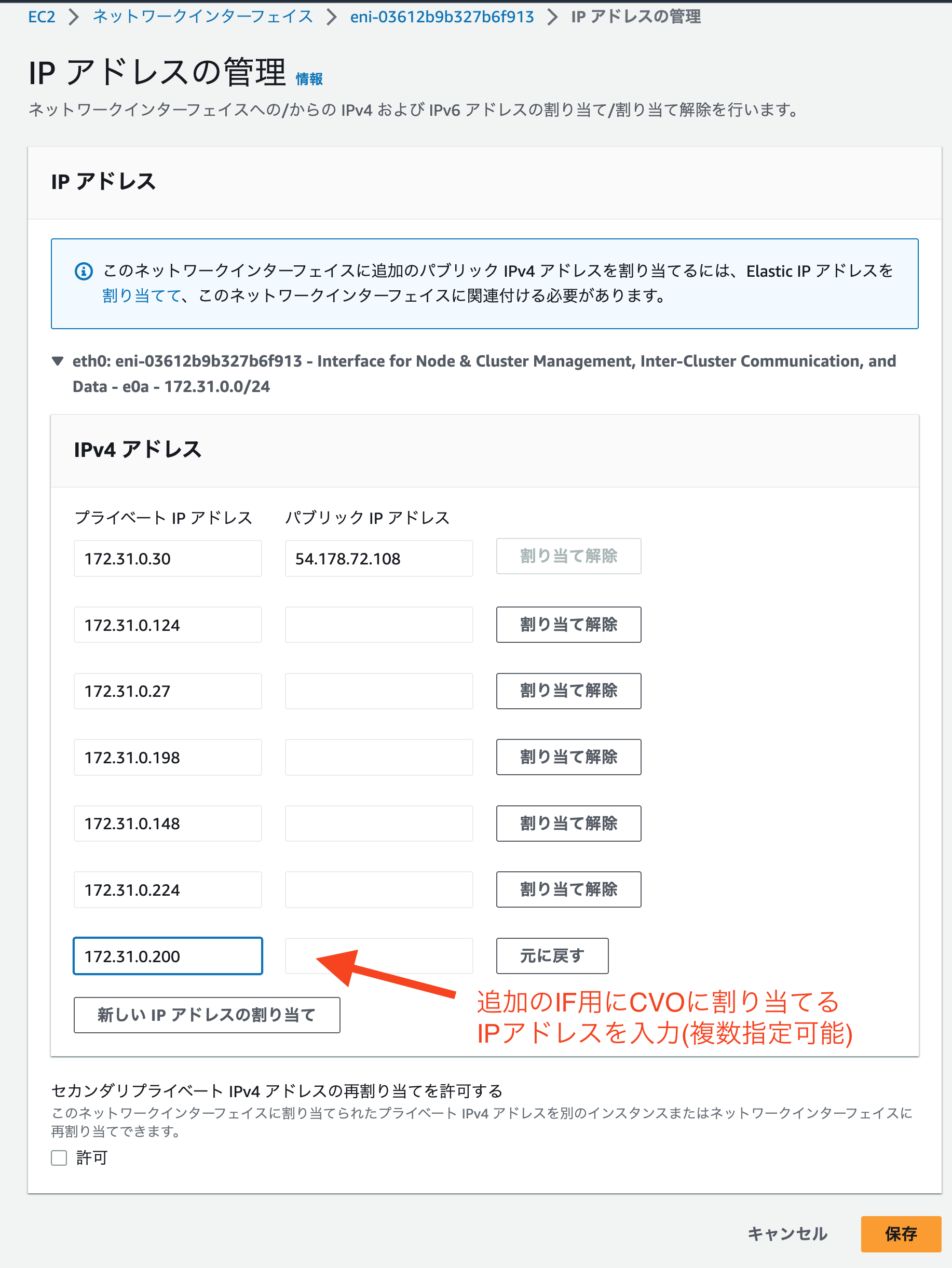
ここまでで一旦CVOのデプロイは完了になりますが、以降の手順ではCVO上に自動作成されたIF(LIF)ではなく、Data Duality用に新規にIFを作成して使用する方法を取っている関係上、CVOインスタンスに対して追加のIPアドレスを割り当てられるように設定を行います。
AWSコンソールからCVOインスタンスに割り当てられたENIを選択
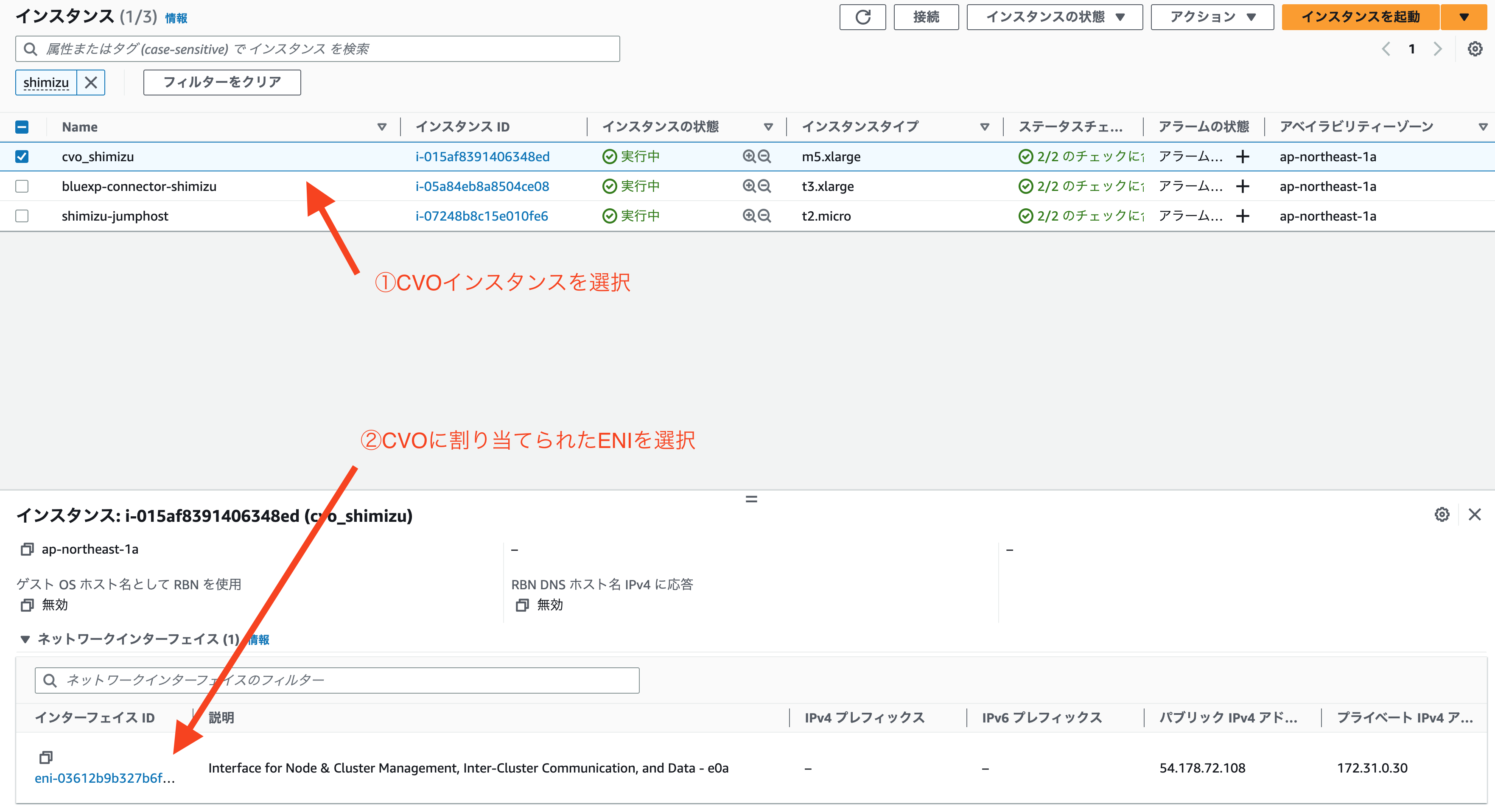
ENIの一覧画面からIPアドレスの管理を選択

以降の手順でData Duality用に作成するIFに割り当てるIPアドレスを入力
Data Dualityのセットアップ
CVOインスタンスのデプロイが完了したら、ONTAPのCLIを使用してData Dualityのセットアップを行なっていきます。
まずは踏み台端末等からCVOインスタンスのIPアドレス(=ONTAPの管理IPアドレス)宛にsshログイン。
[ec2-user@ip-172-31-0-139 ~]$ ssh admin@172.31.0.30
(admin@172.31.0.30) Password:
This is your first recorded login.
Unsuccessful login attempts since last login: 1
# ONTAPのプロンプトに切り替わる
cvo_shimizu::>
ログインできたらCVOのデプロイに伴って自動作成されたStorage Virtual Machine(SVM)ならびにNFSボリュームを確認します。
SVMはONTAP内に作成される仮想マシンであり、ボリュームやデータアクセス用のIF(LIF)などがホストされます。上記の通りにCVOをデプロイした場合、svm_<CVOインスタンス名>という名称でSVMが自動作成されているはずです。
# SVMの確認
cvo_shimizu::> vserver show
Admin Operational Root
Vserver Type Subtype State State Volume Aggregate
----------- ------- ---------- ---------- ----------- ---------- ----------
cvo_shimizu admin - - - - -
cvo_shimizu-01
node - - - - -
svm_cvo_shimizu # 自動作成されたSVM
data default running running svm_cvo_ aggr1
shimizu_
root
# NFSボリュームの確認
cvo_shimizu::*> vol show -vserver svm_cvo_shimizu
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
svm_cvo_shimizu ml_datastore aggr1 online RW 100GB 95.00GB 0% # 自動作成されたNFSボリューム
svm_cvo_shimizu svm_cvo_shimizu_root aggr1 online RW 1GB 972.4MB 0%
2 entries were displayed.
次にサービスポリシーというオブジェクトを作成します。
サービスポリシーはONTAPにおけるファイアウォール的な機能を司るもので、ここでは任意のIPからNFSとS3の両プロトコルでアクセスできるようなポリシーを作成しておきます。
# advanced権限に昇格
cvo_shimizu::> set advanced
Warning: These advanced commands are potentially dangerous; use them only when directed to do so by NetApp personnel.
Do you want to continue? {y|n}: y
# サービスポリシー作成
cvo_shimizu::*> net int service-policy create -vserver svm_cvo_shimizu -policy sagemaker_s3_nfs_policy -services data-core,data-s3-server,data-nfs,data-flexcache
(network interface service-policy create)
# 作成したサービスポリシーの確認
cvo_shimizu::*> net int service-policy show -vserver svm_cvo_shimizu -policy sagemaker_s3_nfs_policy
(network interface service-policy show)
Vserver: svm_cvo_shimizu
Policy Name: sagemaker_s3_nfs_policy
Included Services: data-core, data-nfs, data-flexcache, data-s3-server
Service: Allowed Addresses: data-core: 0.0.0.0/0
data-nfs: 0.0.0.0/0
data-flexcache: 0.0.0.0/0
data-s3-server: 0.0.0.0/0
上記で作成したサービスポリシーを使って、SVM上に仮想インターフェース(LIF)を作成します。LIF作成時に指定したIPアドレスは、後ほどSageMakerのノートブックインスタンスからNFSマウントを行う際に指定するIPアドレスとなりますので、適宜控えておきましょう。
# LIFの作成
cvo_shimizu::*> net int create -vserver svm_cvo_shimizu -lif sagemaker_s3_nfs_dual_access -service-policy sagemaker_s3_nfs_policy -home-node cvo_shimizu-01 -home-port e0a 172.31.0.200 -netmask 255.255.255.0
(network interface create)
Warning: The configured failover-group has no valid failover targets for the LIF\'s failover-policy. To view the failover targets for a LIF, use the
"network interface show -failover" command.
# 作成したLIFの確認
cvo_shimizu::*> net int show -lif sagemaker_s3_nfs_dual_access
(network interface show)
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- ------- ----
svm_cvo_shimizu
sagemaker_s3_nfs_dual_access up/up 172.31.0.200/24 cvo_shimizu-01 e0a true
次にSVMにおけるS3サーバ機能を有効化します。今回は検証用とということでhttpのみ(≠https)でのアクセスを想定しています。
# S3サーバの作成
cvo_shimizu::*> vserver object-store-server create -vserver svm_cvo_shimizu -is-http-enabled true -object-store-server svm_cvo_shimizu_s3 -is-https-enabled false
# 作成したS3サーバの確認
cvo_shimizu::*> vserver object-store-server show
Vserver: svm_cvo_shimizu
Object Store Server Name: svm_cvo_shimizu_s3
Administrative State: up
HTTP Enabled: true
Listener Port For HTTP: 80
HTTPS Enabled: false
Secure Listener Port For HTTPS: 443
Certificate for HTTPS Connections: -
Default UNIX User: pcuser
Default Windows User: -
Comment:
作成したS3サーバ上にユーザならびにグループを作成します。
作成したユーザのAccess KeyとSecret Keyは、各S3クライアントからの認証に使用しますので、こちらも適宜控えておきましょう、
# S3ユーザの作成
cvo_shimizu::*> vserver object-store-server user create -vserver svm_cvo_shimizu -user s3user
# 作成したS3ユーザの確認
cvo_shimizu::*> vserver object-store-server user show
Vserver User ID Access Key Secret Key
----------- --------------- --------- ------------------- -------------------
svm_cvo_shimizu root 0 - -
Comment: Root User
svm_cvo_shimizu s3user 1 6BK0Z21WDR5NWAC78R6O CthD_0CtXrcm6nhu_YtlPp_93WXca2e41SYg0g_p # 表示されたAccess Key/Secret Keyを控えておく
2 entries were displayed.
# グループを作成し、上記で作成したユーザにFullAccess権限を割り当て
cvo_shimizu::*> vserver object-store-server group create -name s3group -users s3user -comment ""
cvo_shimizu::*> vserver object-store-server group delete -gid 1 -vserver svm_cvo_shimizu
cvo_shimizu::*> vserver object-store-server group create -name s3group -users s3user -comment "" -policies FullAccess
# 作成したグループの確認
cvo_shimizu::*> vserver object-store-server group show -vserver svm_cvo_shimizu
Vserver Group ID Group Name Users Policies
----------- --------- -------------- ---------------- -------------------
svm_cvo_shimizu 2 s3group s3user FullAccess
そして最後に、既存のNFSボリューム上にS3バケットを作成します。
# S3バケットの作成
cvo_shimizu::*> vserver object-store-server bucket create -bucket ontapbucket1 -type nas -comment "" -vserver svm_cvo_shimizu -nas-path /ml_datastore
# S3バケットの確認
cvo_shimizu::*> vserver object-store-server bucket show
Vserver Bucket Type Volume Size Encryption Role NAS Path
----------- --------------- -------- ----------------- ---------- ---------- ---------- ----------
svm_cvo_shimizu ontapbucket1 nas ml_datastore - false - /ml_datastore
これでData Dualityのセットアップは完了です。
2. Amazon SageMaker(ノートブックインスタンス)のデプロイ
AWSコンソールから機械学習用のインスタンス(Amazon SageMakerのノートブックインタンス)を払い出します。
こちらに関しても特別本アーキテクチャ固有の設定というほどのものはありませんが、インスタンス外部(CVO)のNFSボリュームをマウントする形となるため、以下の設定項目は意識する必要があります。
- ノートブックインスタンスからCVOへの通信を許可する
- ノートブックインスタンスに割り当てるセキュリティグループ側で予め設定しておく
- ノートブックへのルートアクセス権を付与する
- インスタンス払い出し後に
mountコマンドを実行するので必須 - ノートブックインスタンスの作成ウィザード内で指定できる
- インスタンス払い出し後に
ノートブックインスタンスの作成をクリック
インスタンスタイプやAMI等を適宜カスタマイズする
「ノートブックへのルートアクセス権をユーザに付与する」は有効にしておく
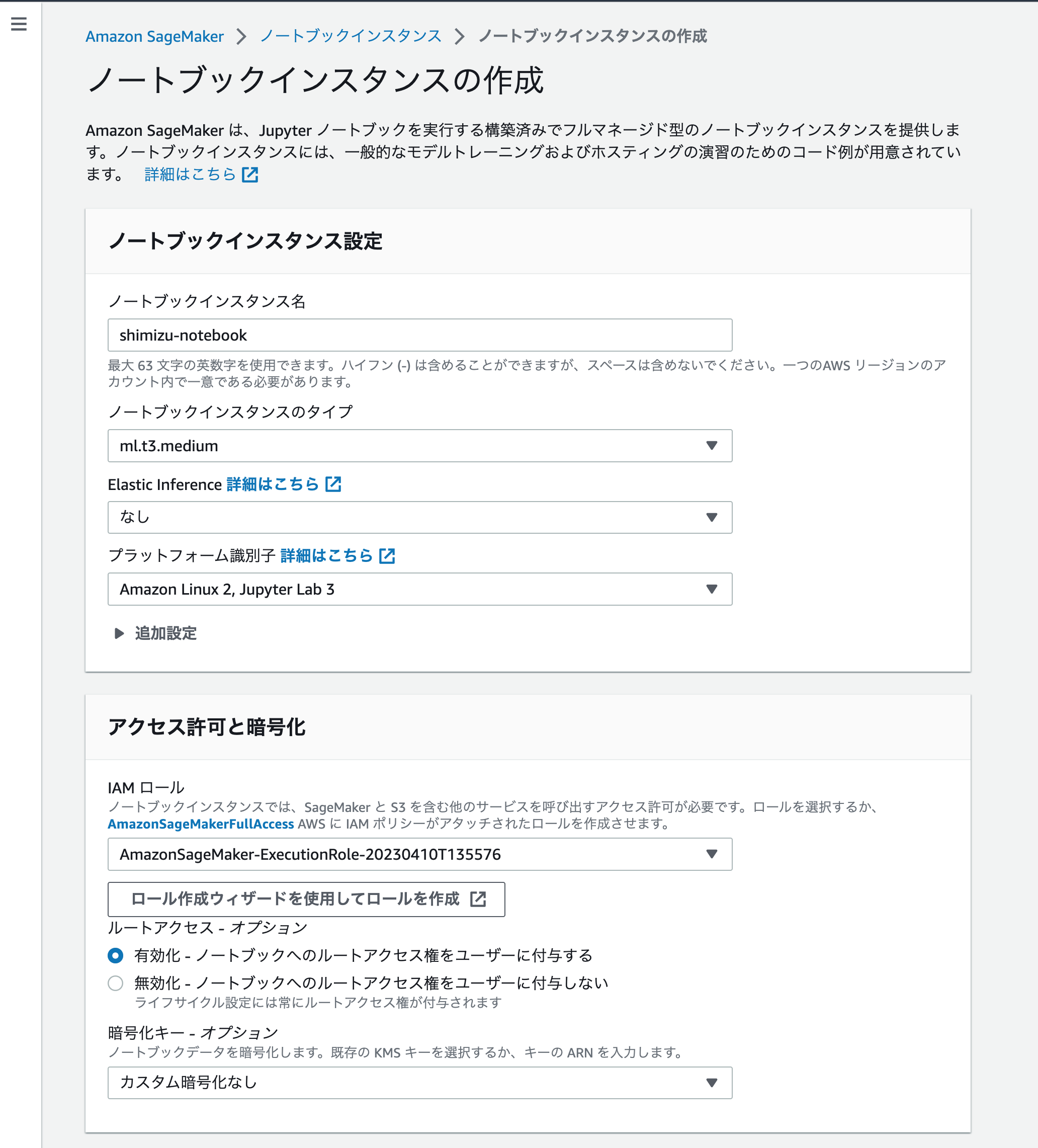
インスタンスをデプロイするネットワークを指定
ここで割り当てたセキュリティグループが、「ノートブックインスタンスからCVO上のNFSボリュームをマウントできる」設定になっているかは要チェックです。
今回はCVO作成時に自動作成されたセキュリティグループ(同一VPCからのアクセスを許可)を指定しています。
あとは適宜お好みで設定して頂いたらノートブックインスタンスの作成をクリックします。
3. ノートブックインスタンスからのData Dualityによるストレージアクセス
いよいよノートブックインスタンスからストレージ(CVO)へ、Data DualityによるS3/NFSアクセスを行います。
AWSコンソール上で対象のノートブックインスタンスの"JupyterLabを開く"をクリック
JupyterLab上のTerminalを起動します

まずはNFSプロトコルを介して、ストレージ(CVO)内のデータにアクセスできるようにします。
ターミナル上でmountコマンドを実行し、NFSボリュームをマウント。
なおマウント先のパスは、<CVO上で新規作成したLIFのIPアドレス>:/<NFSボリューム名>となります。
# NFSボリューム(CVO)マウント
sh-4.2$ sudo mkdir /datasets; sudo mount -t nfs 172.31.0.200:/ml_datastore /datasets
# マウント後の確認
sh-4.2$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 620K 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/nvme0n1p1 160G 129G 32G 81% /
/dev/nvme1n1 4.8G 28K 4.6G 1% /home/ec2-user/SageMaker
tmpfs 387M 0 387M 0% /run/user/1002
tmpfs 387M 0 387M 0% /run/user/1000
tmpfs 387M 0 387M 0% /run/user/1001
172.31.0.200:/ml_datastore 95G 2.2M 95G 1% /datasets # マウントしたNFSボリューム
次に先ほどNFSマウントしたボリュームに対してS3プロトコルでもアクセスができることも確認していきます。
実際のS3クライアントのセットアップ手順はデータ収集元のアプリケーションやデバイスに応じて異なりますが、今回は一例として「SageMakerのノートブックインスタンスからaws cli経由でS3バケットを確認・操作を行う」という体で以下のように実施しています。
# aws cliのセットアップ
sh-4.2$ aws configure --profile netapp
AWS Access Key ID [None]: AKIASTFXPUVSXCV5ULDN # CVOのデプロイ時に作成したS3ユーザのAccess Keyを入力
AWS Secret Access Key [None]: nBRK4HGYhwZWUCOJjf3SWRZc5pkZs8dR6zjt8HCE # CVOのデプロイ時に作成したS3ユーザのSecret Keyを入力
Default region name [None]: ap-northeast-1
Default output format [None]:
# S3バケットの一覧を確認
sh-4.2$ aws s3 ls --profile netapp --endpoint-url http://172.31.0.200
2023-05-25 07:02:50 ontapbucket1 # 上記でマウントしたNFSボリューム上に作成されているS3バケット
ここまでで一通りのセットアップは完了です。
最後にS3プロトコル経由でアップロードしたデータをNFS経由で取得できるか確認してみます。
# テスト用ファイル作成
sh-4.2$ echo "This file was uploaded via S3 protocol." > s3.txt
# テスト用ファイルをS3プロトコル経由でバケットにアップロード
sh-4.2$ aws s3 cp s3.txt s3://ontapbucket1/ --profile netapp --endpoint-url=http://172.31.0.200
upload: ./s3.txt to s3://ontapbucket1/s3.txt
# NFSマウント先のディレクトリにS3経由でアップロードしたファイルが存在することを確認
sh-4.2$ ls -l /datasets/s3.txt
-rw-r--r-- 1 nobody nobody 39 May 30 05:45 /datasets/s3.txt
sh-4.2$ cat /datasets/s3.txt
This file was uploaded via S3 protocol.
無事、S3経由でアップロードしたファイルがNFSでもアクセスでき、Data Dualityがセットアップできていることが確認できました。
まとめ
今回ご紹介したアーキテクチャは、データ量が多く、モデル学習前のデータ準備に時間がかかってしまうような機械学習ワークロードにおいて特に有効だと思います。
なおAWSにおいては、今回扱ったCloud Volumes ONTAPだけでなくFSx for NetApp ONTAP(ONTAPベースのAWSマネージドなファイルサービス)でも、今後のバージョンアップによってData Dualityに相当する機能が追加されるかもしれません。
活用の幅が広がりますのでぜひ期待したいですね!
-
s3fsなどS3ストレージをマウントすることは技術的には可能ですが、安定性やコストの観点から非推奨とされています(参考Link: https://aws.amazon.com/jp/blogs/news/webinar-bb-summit-2018/) ↩