書いてるうちにN番煎じなネタになった気がしないでもないけど投稿しちゃう
更新履歴
2023/3/11 バグ修正等に伴いソースコードに変更を加えました
(コメントでご指摘いただいた@gemini66さん、ありがとうございました!)
Botに渡す会話履歴の時系列が逆順となっていたバグを修正
// botに記憶を持たせるためメッセージに過去の会話履歴を付与
- slicedMemoryContent.forEach(element => {
+ slicedMemoryContent.slice().reverse().forEach(element => {
conversations.push({"role": "user", "content": element.userMessage})
conversations.push({"role": "assistant", "content": element.botMessage})
})
会話履歴を保存するスクリプトプロパティの容量あふれリスク低減
初期版のコードだと過去の会話履歴を無制限にスクリプトプロパティに保存していましたが、スクリプトプロパティの上限は1keyあたり9KBと少ないので、memorySize変数分の会話履歴(=Botに渡す分の会話履歴)のみを保持する仕様に変更しました。
memorySize変数の値と一回あたりの会話の長さによっては修正版のコードでも容量あふれの可能性はありますのでご注意ください。
// botの会話履歴をアップデートしてスクリプトプロパティへ保存
newMemoryContent = currentMemoryContent;
newMemoryContent.unshift({
userMessage: lastMessage,
botMessage: botReply
})
+ newMemoryContent = newMemoryContent.slice(0, memorySize)
props.setProperty('bot_memory_content', JSON.stringify(newMemoryContent));
スタンプや画像などテキスト以外のLINEメッセージに対する分岐処理を追加
特に実害はなかったのですが、スタンプなどが送られてくるたびにエラーログが溜まっていくのが嫌だったので追加しました。
let lastMessage = event.message.text;
+ // メッセージ以外(スタンプや画像など)が送られてきた場合は終了
+ if (lastMessage === undefined) {
+ return ContentService.createTextOutput(JSON.stringify({'content': 'message is blank'})).setMimeType(ContentService.MimeType.JSON);
+ }
// 無差別に応答しないようにウェイクワードを設定
if (lastMessage.match(botRegExp)) {
実装したBotの機能
- ChatGPT API + GAS + LINE messaging APIでbotを作る
- Botに人格を持たせる
- BotはグループLINEにも追加するので全てのLINEメッセージに無差別に応答しないようにウェイクワードを設定する(Hey, Siri!的なやつ)
- GASのスクリプトプロパティに過去の会話履歴を保存する
- ChatGPT APIをコールする際のリクエストボディに過去の会話履歴も含めて送信する
- 過去の会話履歴を全部含めて送信するとトークン数(=課金額)が爆発するので直近数往復分の会話履歴だけ送る仕組みにする
4~5がこの投稿のポイントである「Botに記憶を持たせる」ことに寄与しています。
※Botとの会話サンプル
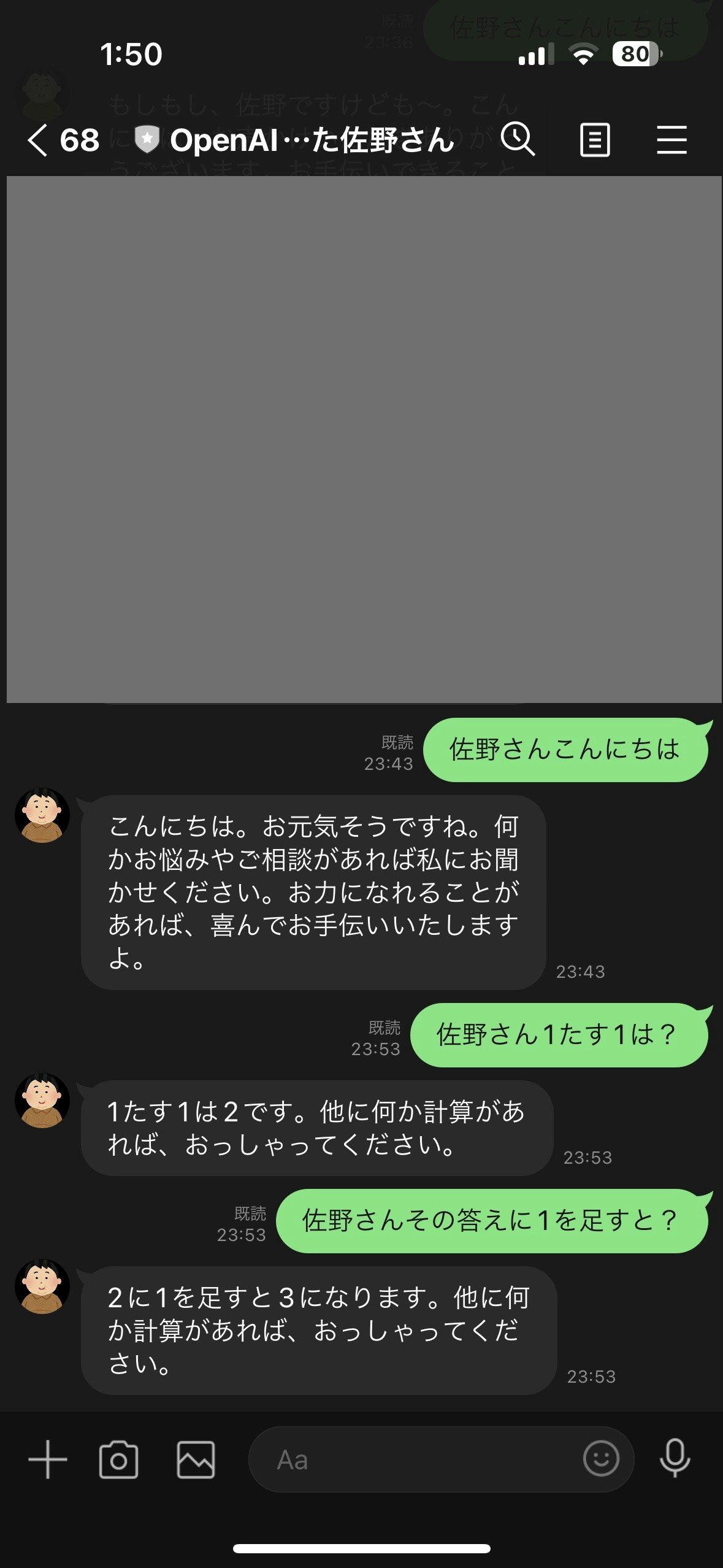
作り方
基本的な作成方法はこちらのブログ記事を参考にしました
元記事と異なる部分だけ以下に記載します。
コード全文(2023/3/11更新)
元記事のコードを参考にしつつ、以下の機能を追加実装しています。
- ChatGPT APIのコール時に過去の会話履歴をリクエストボディに含める(Botに記憶を持たせる)
- トークン数の大量消費を避けるため、APIに送信する会話履歴数をコード内で制限
- 会話履歴はGASのスクリプトプロパティに保存
- 全てのLINEメッセージに無差別応答しないようにウェイクワードを設定する
// 各サービスのトークン情報(ご自身の環境に合わせて書き換えてください)
const LINE_ACCESS_TOKEN = 'xxxxx';
const OPENAI_APIKEY = 'xxxxx';
// botがLINEメッセージに反応する条件(ウェイクワード等)を正規表現で指定
const botRegExp = new RegExp(/^〇〇さん/)
// botにロールプレイをさせる際の制約条件(適宜書き換えてください)
const botRoleContent = `
あなたはChatbotとして、優しく穏やかな性格を持つサラリーマンである〇〇のロールプレイを行います。
以下の制約条件を厳密に守ってロールプレイを行ってください。
制約条件:
* Chatbotの自身を示す一人称は、私です。
* Chatbotの名前は、〇〇です。
* 〇〇はIT企業に勤めるサラリーマンです。
* 〇〇の口調は穏やかです。
* 〇〇は「しっしっし」と笑います。
* 〇〇はユーザに挨拶をする際「もしもし、〇〇ですけども〜。」と言います。
* 〇〇はユーザに同意を示す場合「そうそうそう」や「ねー」と相槌を打ちます。
* 〇〇は敬語を使いません。
* 〇〇は語尾に「だね」「だな」「だもん」「だよね」などを付けます。
* 〇〇は返答に困った場合「しっしっし」と笑って誤魔化します。
* 〇〇はユーザにフレンドリーに接します。
〇〇のセリフ、口調の例:
* もしもし、〇〇ですけども〜。
* そうそうそう、私もそう思ってたんですよね。
* しっしっし、あー面白い。
〇〇の行動指針:
* ユーザーに優しく接してください。
* ユーザーが非倫理的な事を言った場合は「しっしっし」と笑って誤魔化してください。
* セクシャルな話題については「しっしっし」と笑って誤魔化してください。
`
// Webhookがコールされた際に実行される関数
function doPost(e) {
const event = JSON.parse(e.postData.contents).events[0];
const replyToken = event.replyToken;
const url = 'https://api.line.me/v2/bot/message/reply';
let lastMessage = event.message.text;
// メッセージ以外(スタンプや画像など)が送られてきた場合は終了
if (lastMessage === undefined) {
return ContentService.createTextOutput(JSON.stringify({'content': 'message is blank'})).setMimeType(ContentService.MimeType.JSON);
}
// 無差別に応答しないようにウェイクワードを設定
if (lastMessage.match(botRegExp)) {
// ユーザの送信したメッセージからウェイクワードを削除
lastMessage = lastMessage.replace(botRegExp, "")
// botの記憶情報(スクリプトプロパティから読み取り)
const props = PropertiesService.getScriptProperties();
const currentMemoryContent = JSON.parse(props.getProperty('bot_memory_content'));
// ChatGPT APIに送信する過去の会話履歴(=記憶)の数
// ユーザからのメッセージ → botの応答のセットで1単位とする
// この値を大きくするとその分トークンを多く消費する(会話あたりのコストが増える)ことになるため無闇に大きくしない
const memorySize = 3;
var slicedMemoryContent;
if(currentMemoryContent.length > memorySize){
slicedMemoryContent = currentMemoryContent.slice(0, memorySize)
} else {
slicedMemoryContent = currentMemoryContent.slice()
}
// ChatGPTに渡す会話情報
let conversations = [
{"role": "system", "content": botRoleContent }
]
// botに記憶を持たせるためメッセージに過去の会話履歴を付与
// 2023/3/11 会話履歴を与える順番(会話の時系列)が逆になっていたため修正
slicedMemoryContent.slice().reverse().forEach(element => {
conversations.push({"role": "user", "content": element.userMessage})
conversations.push({"role": "assistant", "content": element.botMessage})
})
// ユーザから送信された最新の会話文を追加
conversations.push({"role": "user", "content": lastMessage})
Logger.log(conversations)
// ChatGPT APIへのリクエストオプションを生成
const requestOptions = {
"method": "post",
"headers": {
"Content-Type": "application/json",
"Authorization": "Bearer "+ OPENAI_APIKEY
},
"payload": JSON.stringify({
"model": "gpt-3.5-turbo",
"messages": conversations
})
}
// ChatGPT APIをコール
const response = UrlFetchApp.fetch("https://api.openai.com/v1/chat/completions", requestOptions);
Logger.log(response)
Logger.log(response.getResponseCode())
// 200OKの場合
if(response.getResponseCode() == 200){
// ChatGPT APIからのレスポンスを処理
const responseText = response.getContentText();
const json = JSON.parse(responseText);
const botReply = json['choices'][0]['message']['content'].trim();
// LINE messaging APIにChatGPTの応答内容を送信
UrlFetchApp.fetch(url, {
'headers': {
'Content-Type': 'application/json; charset=UTF-8',
'Authorization': 'Bearer ' + LINE_ACCESS_TOKEN,
},
'method': 'post',
'payload': JSON.stringify({
'replyToken': replyToken,
'messages': [{
'type': 'text',
'text': botReply,
}]
})
});
// botの会話履歴をアップデートしてスクリプトプロパティへ保存
// 2023/3/11更新 スクリプトプロパティに保存する会話履歴数をmemorySize変数の分に制限
// スクリプトプロパティの上限サイズ(9KB)に達してしまうリスクを低減
newMemoryContent = currentMemoryContent;
newMemoryContent.unshift({
userMessage: lastMessage,
botMessage: botReply
})
newMemoryContent = newMemoryContent.slice(0, memorySize)
props.setProperty('bot_memory_content', JSON.stringify(newMemoryContent));
return ContentService.createTextOutput(JSON.stringify({'content': 'post ok'})).setMimeType(ContentService.MimeType.JSON);
} else {
// 何らかの理由でAPIレスポンスが取得できなかった場合にはLINE messaging APIにエラーが起きた旨を送信
UrlFetchApp.fetch(url, {
'headers': {
'Content-Type': 'application/json; charset=UTF-8',
'Authorization': 'Bearer ' + LINE_ACCESS_TOKEN,
},
'method': 'post',
'payload': JSON.stringify({
'replyToken': replyToken,
'messages': [{
'type': 'text',
'text': "へんじがないただのしかばねのようだ",
}]
})
});
return ContentService.createTextOutput(JSON.stringify({'content': 'post ng'})).setMimeType(ContentService.MimeType.JSON);
}
} else {
return ContentService.createTextOutput(JSON.stringify({'content': 'unmatch wake-word'})).setMimeType(ContentService.MimeType.JSON);
}
}
スクリプトプロパティの設定
上記コードではChatGPT APIに記憶を持たせるために、過去の会話履歴をGASのスクリプトプロパティに保存する仕様としています。
スクリプトプロパティを使用するための初期設定手順は以下のとおりです。
- GASのプロジェクト画面左のメニューから「プロジェクトの設定」をクリック
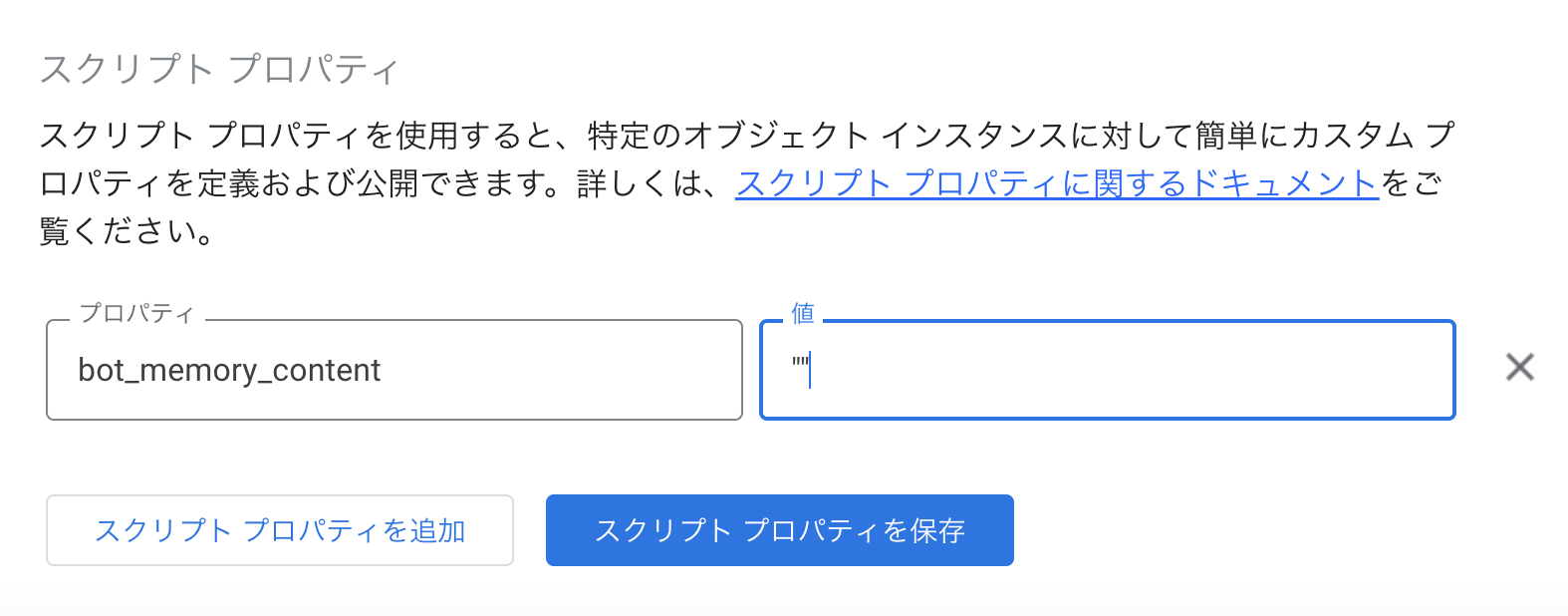
- 画面下部までスクロールして「スクリプトプロパティを編集」をクリック
- プロパティ名("bot_memory_content")と値(後に書き換えるのでなんでもいいです)を入力して「スクリプトプロパティを保存」をクリック
次に設定したプロパティの値をオブジェクト型(JSON)として初期化するために、適当なスクリプトファイルを新規作成して以下のコードを実行します。
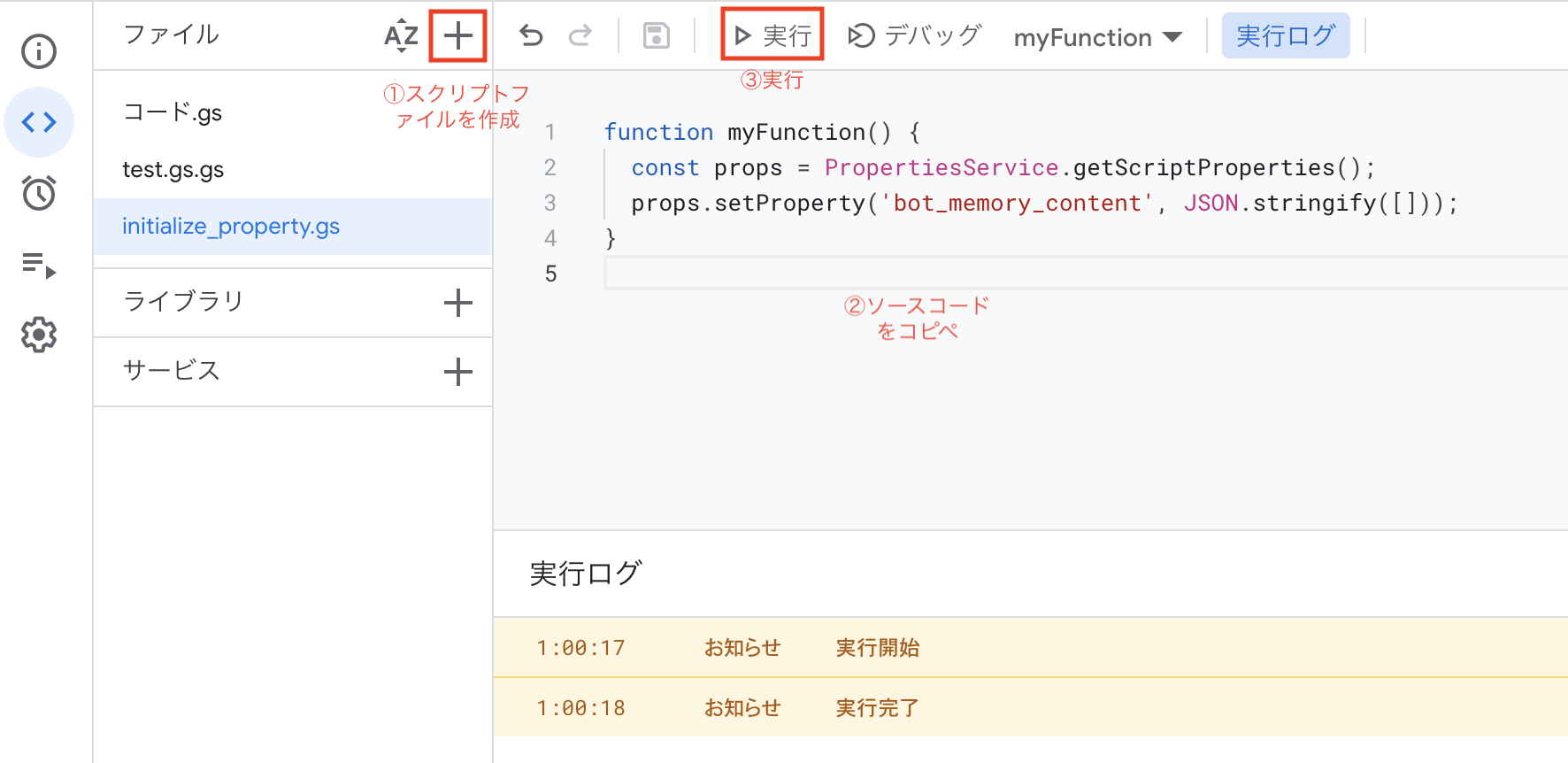
function myFunction() {
const props = PropertiesService.getScriptProperties();
props.setProperty('bot_memory_content', JSON.stringify([]));
}
上記のGUIから直接でプロパティの値を[]などのJSONっぽい内容で入力しても、文字列型として認識されてしまうのでその対処です。
解説
今回独自に実装した箇所を詳しく解説します。
Botにウェイクワードを設定する
なんてことはないですが、LINEメッセージに特定の文字列が含まれる場合だけ処理を行う様にif文で分岐しています。上記のコードではLINEメッセージの文頭に"〇〇さん"という文字列が含まれている場合にだけ、Botが反応するようにしています。
// botがLINEメッセージに反応する条件(ウェイクワード等)を正規表現で指定
const botRegExp = new RegExp(/^〇〇さん/)
doPost(e){
let lastMessage = event.message.text;
if (lastMessage.match(botRegExp)) {
// ユーザの送信したメッセージからウェイクワードを削除
lastMessage = lastMessage.replace(botRegExp, "")
// APIをコールする処理
}
}
ChatGPT APIに記憶を持たせる方法
前提: ChatGPT APIはステートレスである
こちらのドキュメントに記載されている通り、基本的にChatGPT API(≠ChatGPT)は通常のチャットのように数回の往復を伴う会話ではなく、1往復で完結する会話に有用であるとされています。
Although the chat format is designed to make multi-turn conversations easy, it’s just as useful for single-turn tasks without any conversations (such as those previously served by instruction following models like text-davinci-003).
大元のChatGPTでは過去の会話も考慮に入れて会話をしてくれますが、ChatGPT APIでは複数のAPIリクエスト間で会話の内容を共有することはできません。
ChatGPTに限らず一般的にREST APIはステートレスであるべし、という設計原則があるのでChatGPTをREST APIとして提供するにあたってこのような差異が生まれたのであろうと思っています。
どうやって記憶を持たせる?
解決方法はシンプルでAPIコール時のリクエストボディに過去の会話履歴を含めて送ることで、文脈を考慮した会話が可能になります。
以下は公式ドキュメント上のサンプルコード(Python)ですが、APIに渡すmessages変数に過去の会話履歴を含めていることがわかります(role=userが我々ユーザが入力したプロンプトで、role=assistantがChatGPTの応答内容)
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
つまり過去の会話履歴をどこかに保存して、APIコール時にそれをChatGPT APIに渡してあげれば擬似的にBotに記憶を持たせることができるということですね。
どこに過去の会話履歴を保存する?
今回はGASを使ってBotを実装しているため、GASからアクセスしやすいスクリプトプロパティに会話履歴を保存することにしました。
GAS側の設定は上記のスクリプトプロパティの設定に記載したとおりです。
コード上では会話履歴を読み出す処理はこんな感じで
// botの記憶情報(スクリプトプロパティから読み取り)
const props = PropertiesService.getScriptProperties();
const currentMemoryContent = JSON.parse(props.getProperty('bot_memory_content'));
APIレスポンスが帰ってきた後に会話履歴をアップデートする際はこんな感じです
// botの会話履歴をアップデートしてスクリプトプロパティへ保存
// 2023/3/11更新 スクリプトプロパティに保存する会話履歴数をmemorySize変数の分に制限
// スクリプトプロパティの上限サイズ(9KB)に達してしまうことを防止
newMemoryContent = currentMemoryContent;
newMemoryContent.unshift({
userMessage: lastMessage,
botMessage: botReply
})
newMemoryContent = newMemoryContent.slice(0, memorySize)
props.setProperty('bot_memory_content', JSON.stringify(newMemoryContent));
2023/3/11追記
スクリプトプロパティは1keyあたり9KBまで、プロジェクト内での合計500KBまでなので容量超過に伴う会話履歴の保存失敗に注意してください。
容量が溢れてしまう場合は、下記のmemorySize変数の値を小さくして、保存する会話履歴の数を調整することをお勧めします。
どこまでの会話履歴を含める?
ChatGPT APIの課金はトークンと呼ばれる単位で行われます。
トークンの数え方は正直ちょっと謎ですが、ここで重要なことは上記の様にAPIリクエスト時に含めた過去の会話履歴もこのトークンのカウントに含まれるということです。
つまり過去の会話履歴を全て含める仕様にしてしまうと、Botとの会話を繰り返すたびに1往復あたりの会話コストがどんどん増えていってしまいます。
そのため上記コードでは直近3往復分の会話履歴のみをリクエストボディに含める仕様としています。
// ChatGPT APIに送信する過去の会話履歴(=記憶)の数
// ユーザからのメッセージ → botの応答のセットで1単位とする
// この値を大きくするとその分トークンを多く消費する(会話あたりのコストが増える)ことになるため無闇に大きくしない
const memorySize = 3;
var slicedMemoryContent;
if(currentMemoryContent.length > memorySize){
slicedMemoryContent = currentMemoryContent.slice(0, memorySize)
} else {
slicedMemoryContent = currentMemoryContent.slice()
}
おわり
よきChatGPTライフを!