DataFrameの覚書
{.py}
# インポート
from pandas import DataFrame
# tsvの読み込み
dframe = pd.read_csv('data.tsv', delimiter='\t', header=None)
# カラム名変更
dframe.columns = ['hoge', 'fuga']
# カラムを落として別のDataFrame作成
dframe2 = dframe[[0, 1]]
# カラム名が文字列で付いてたら、dframe[['hoge', 'fuga']]で。
# 重複行削除
dframe3 = dframe2.drop_duplicates()
# 行数調査
len(dframe3)
# DataFrameの数値の先頭X文字を切り取って新しいカラムとして使う
# sliceカラムを追加し、そこに、hoge(float型)の先頭4文字を挿入
dframe4['slice'] = dframe4['hoge'].astype(str).str.slice(0, X)
# groupbyして件数カウント
print dframe4.groupby(['slice']).size()
# 特定の文字列を含む行を抽出してDataFrame作成
df_tmp = dframe[dframe['column'].str.contains('hoge') == True]
DataFrameの一部のカラムを使って関数を実行して、新カラム作成
{.py}
# kaggleのタイタニックのデータを読み込み(https://www.kaggle.com/c/titanic/data?train.csvから取得したtrain.csv)
titanic_df = pd.read_csv('train.csv')
# 16歳未満を子供とみなす関数作成
def male_female_child(passenger):
age,sex = passenger
if age < 16:
return 'child'
else:
return sex
# titanic_dfにpersonという新しい列を追加。
# 追加方法は、male_female_child関数で作成。applyで1行ずつ関数を適応する。
titanic_df['person'] = titanic_df[['Age','Sex']].apply(male_female_child,axis=1)
このperson別の行数[人数]をカウントするのは、value_counts()でできる。
{.py}
titanic_df['person'].value_counts()
> male 537
> female 271
> child 83
> dtype: int64
matplotlibを併用して、ヒストグラムをみる
タイタニック号の乗客のage別人数
{.py}
titanic_df['Age'].hist(bins=70)
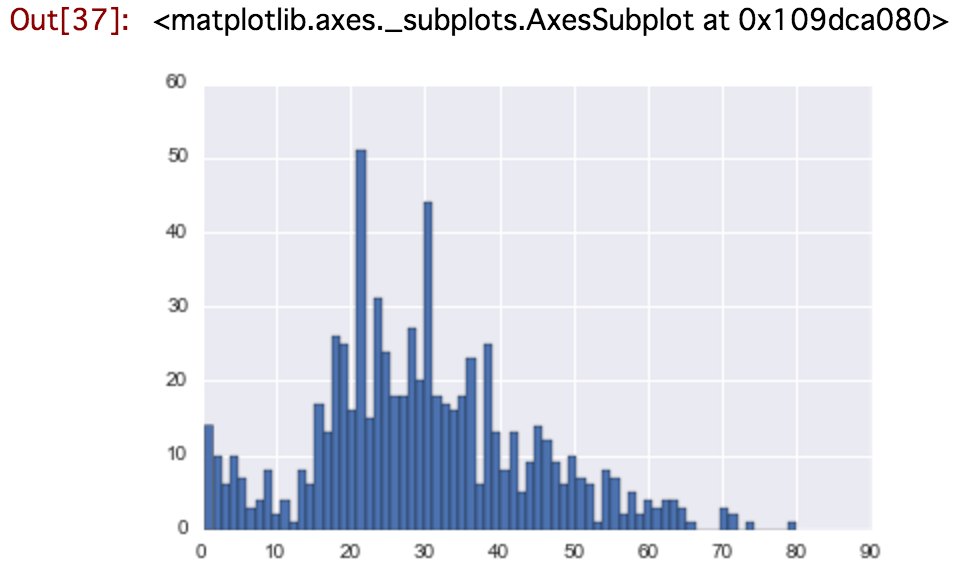
ちなみに、年齢の平均は以下でサクッと見れる。
{.py}
titanic_df['Age'].mean()
> 29.69911764705882
ヒストグラムを見て、外れ値(ゴミ)を取り除く
{.py}
sns.countplot('Cabin', data=cabin_df, palette='winter_d', order = sorted(set(levels)))
# palette:文字列を指定することで、色合いを指定できる。 _dをつけると、ちょっと暗めになる。
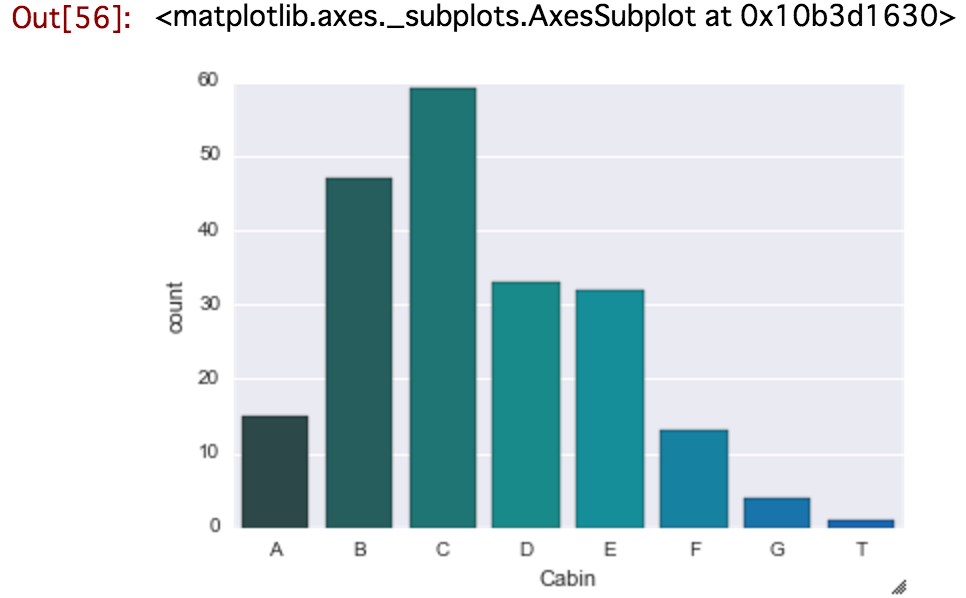
タイタニックのtrain.csvのCabinの一文字目ごとにヒストグラムを書いたけど、A〜Gの後が"T"になっていて、飛んでいる。多分誤った情報なので、これを排除したい!
{.py}
cabin_df = cabin_df[cabin_df.Cabin != 'T']
sns.countplot('Cabin', data=cabin_df, palette='summer', order = sorted(set(cabin_df.Cabin)))
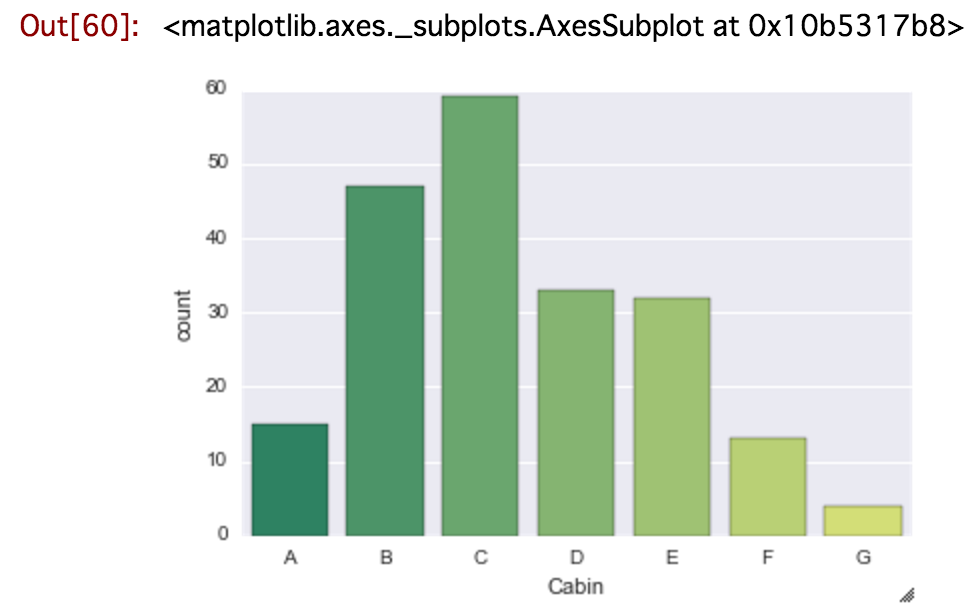
外れ値を取り除いたデータセットが作成できた。
ちなみに、orderのオプションがないと、A〜Gがばらばらになる。
DataFrameのカラムを条件に沿う形で変形
{.py}
# Aloneのカラムを、Aloneが0より大きければ、With Family、0ならAloneへ
titanic_df['Alone'].loc[titanic_df['Alone']>0] = 'With Family'
titanic_df['Alone'].loc[titanic_df['Alone']==0] = 'Alone'