Rubyで日本語ツイートの感情分析をしてみました。
RubyとかPythonを使った感情分析の記事はたくさんあるので、ツイートの感情分析結果についてのみ触れたいと思います。
構成は以下の通りです。
- 感情レベル算出までのフロー
- ツイート取得
- 形態素解析
- 語レベル解析
- 感情値算出
- ツイートの感情分析結果
ツイートの感情分析結果についてのみ触れると言いつつ、ソースコードも少し載せています。
Rubyコードすっ飛ばして結果だけ見てもよいです。
感情レベル算出までのフロー
- ツイート取得
- 形態素解析
- 語レベル解析(単語感情極性対応表と比較)
- 感情値算出
ツイート取得
ツイート取得には、gemのtweetstreamを用いました。
ツイート取得時の抽出条件は以下の3点です。
- 日本語設定のツイートのみ
- リツイートは除外
- リプライは除外
require 'tweetstream'
# Twitter APIのキー設定
TweetStream.configure do |config|
config.consumer_key = '***'
config.consumer_secret = '***'
config.oauth_token = '***'
config.oauth_token_secret = '***'
config.auth_method = :oauth
end
# ツイート格納用配列
list_tweets = Array.new
# ツイート取得
TweetStream::Client.new.sample do |status, client|
# 言語設定が「日本語」かつ、リツイート以外のツイートかつ、リプライでないツイートを抽出
if status.user.lang == "ja" && !status.text.index("RT") && status.in_reply_to_user_id.nil? then
h = Hash.new
# 日付
h['date'.to_sym] = status.created_at
# スクリーンネーム
h['screen_name'.to_sym] = "@" + status.user.screen_name
# ツイート
h['tweet'.to_sym] = status.text
# 配列にツイート格納
list_tweets << h
# 取得ツイート数が100以上でストップ
client.stop if list_tweets.size >= 100
end
end
形態素解析
形態素解析エンジンにはMecabを用いました。
下記ソースコードのnattoは、Mecabをrubyで使えるようにするgemです。
また、形態素解析前に文字の正規化処理をしました。
参照先:https://github.com/neologd/mecab-ipadic-neologd/wiki/Regexp.ja
require 'natto'
list_morph = Array.new
# ツイートを格納した配列の展開
list_tweets.each{ |e|
tmp = Array.new
# 解析前に行う文字の正規化処理(上記リファレンスのソースコードを使用させていただきました)
text = normalize_neologd "#{e[:tweet]}"
nm = Natto::MeCab.new(dicdir: "/opt/local/lib/mecab/dic/mecab-ipadic-neologd")
nm.parse(text.encode("UTF-8")) do |n|
next if n.is_eos?
h = Hash.new
# 表層形
h['word'.to_sym] = n.surface
# 読み
h['reading'.to_sym] = n.feature.split(',')[-2].tr('ァ-ン', 'ぁ-ん')
# 品詞
h['pos'.to_sym] = n.feature.split(',')[0]
tmp << h
end
list_morph.push tmp
}
語レベル解析
ツイートに対して形態素解析し、単語感情極性対応表と比較しました(本記事ではソースコード省略)
。
単語感情極性対応データベースには、http://www.lr.pi.titech.ac.jp/~takamura/pndic_en.htmlを採用しました。
まずは、単語感情極性対応データベースを配列に格納
# 単語感情極性対応データベース格納用配列
list_db = Array.new
# 'db.txt'は上記データベースをテキストファイルに保存したテキストファイル
File.open('db.txt', 'r') do |file|
file.each{ |line|
h = Hash.new
# 単語
h['word'.to_sym] = line.chomp.split(':')[0]
# 読み
h['reading'.to_sym] = line.chomp.split(':')[1]
# 品詞
h['pos'.to_sym] = line.chomp.split(':')[2]
# 感情値
h['semantic_orientations'.to_sym] = line.chomp.split(':')[3]
list_db << h
}
end
感情値算出
次は、ツイートと比較
# 感情値格納用配列
list_semantic = Array.new
# 形態素解析結果を格納した配列から各ツイートの形態素解析結果に展開
list_morph.each{ |e|
tmp = Array.new
e.each{ |h|
list_db.each{ |line|
# 単語、読み、品詞が一致の場合、感情値をカウント
if h[:word] == line[:word] and h[:reading] == line[:reading] and h[:pos] == line[:pos] then
tmp.push line[:semantic_orientations]
end
}
}
# カウントした感情値の平均値
semantic_ave = tmp.inject(0){ |sum, i| sum += i.to_f} / tmp.size unless tmp.size == 0
list_semantic.push semantic_ave
}
結果
20ツイート連続取得して感情値をプロットしたグラフが下図です。
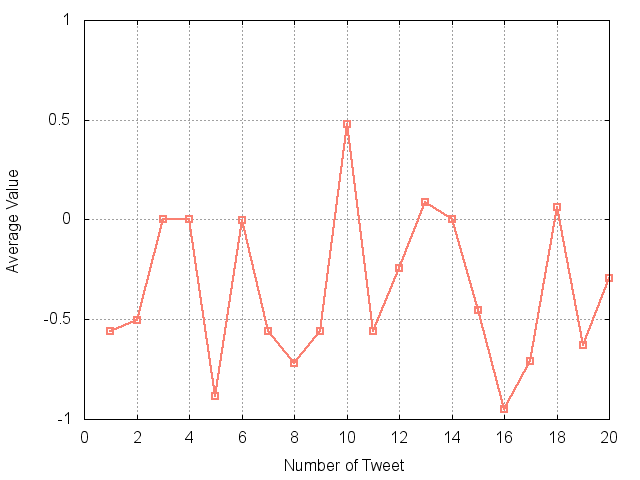
1がポジティブ、-1がネガティブと考えたらよいと思います。
ネガティブツイートが多め?
この記事書いてる時間が深夜なのでそれも関係している???
ツイートの詳細を見てみましょう。
一番ポジティブ指数を示した10番目のツイート、一番ネガティブ指数を示した16番目のツイート、あと適当に2番目あたりのツイートをピックアップして見てみます。
スクリーンネームはさすがに表示できないので、ツイート内容だけ載せます。
| 感情値 | ツイート | |
|---|---|---|
| 2番目 | -0.51 | 土方さん大好き!ムニャムニャ。。。(寝言です) |
| 10番目 | 0.48 | 久しぶりにSchwardix MarvallyのFlowers Of Dearlyが聴きたくなって聴いたん。やっぱいいな〜、メロスピ風味の古き良き王道展開のV系。 |
| 16番目 | -0.95 | 紫原「あ、おやつの時間だ」青峰「寝ろ」 |
まず、土方さん大好き!ムニャムニャ。。。(寝言です)のツイートについて
形態素解析結果はこんな感じです。
{:word=>"土方", :reading=>"ひじかた", :pos=>"名詞"},
{:word=>"さん", :reading=>"さん", :pos=>"名詞"},
{:word=>"大好き!", :reading=>"だいすき", :pos=>"名詞"},
{:word=>"ムニャムニャ", :reading=>"むにゃむにゃ", :pos=>"副詞"},
{:word=>"。", :reading=>"。", :pos=>"記号"},
{:word=>"。", :reading=>"。", :pos=>"記号"},
{:word=>"。", :reading=>"。", :pos=>"記号"},
{:word=>"(", :reading=>"*", :pos=>"記号"},
{:word=>"寝言", :reading=>"ねごと", :pos=>"名詞"},
{:word=>"です", :reading=>"です", :pos=>"助動詞"},
{:word=>")", :reading=>"*", :pos=>"記号"}
この結果に対して、単語感情極性対応表と比較した結果がこちらです。
"さん"=>"-0.598002"
"寝言"=>"-0.414056"
ほお、寝言は-0.41なんですね。
久しぶりにSchwardix MarvallyのFlowers Of Dearlyが聴きたくなって聴いたん。やっぱいいな〜、メロスピ風味の古き良き王道展開のV系。は、ポジティブな感情なような気もします。
ちなみにこんな結果です。
"風味"=>"0.967643"
"王道"=>"0.979772"
"展開"=>"-0.509787"
次に、2016年になってから今日までのツイートを日別にプロットしたのが下図です。
gemのclockworkを使って、15分間隔で1/1~2/6までツイート取得を行いました。
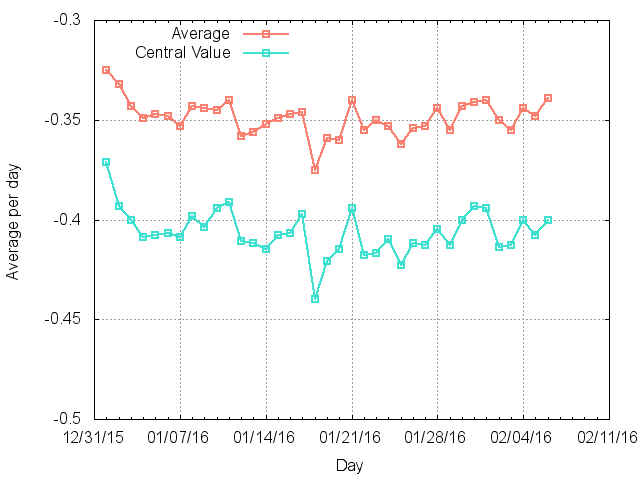
ピンクがその日に取得した全ツイートの感情値の平均値、水色がその日に取得した全ツイートの感情値の中央値です。
ネガティブ指数高いですね。
結論
- 当たり前のことだと思いますが、感情値は感情辞書依存が強いので、異なる感情辞書でもやってみようと思います。
- 今回初めてQiitaに投稿してみました。自分のやったことをこうして記録していくことは大事なのかもしれない、、、