深層学習を用いたブレ除去(Deblur)について概観したいと思います。非常に幅広い研究分野ですが、本記事では一枚のブレ画像からシャープ画像を推定するSingle image deblurringに絞って考えていきます。
ブレ(blur)とは何か?
カメラで画像を撮影する際、「シャッタースピード」という概念が登場します。シャッターをどのくらいの時間開いて光を蓄積するかの設定値で、環境の明るさに左右されて自動決定されるものです。晴天の屋外だと、1/1000秒など非常に短い時間になりますが、暗い室内や夜だと1/10秒や、長い場合だと3秒などの長時間になることもあります。より長い時間撮像センサに光を蓄積してあげないと、検出できるほどの信号強度にならないためです。
シャッタースピードが長い場合、その間にカメラや被写体が動いてしまう可能性も増えます。そうなると、動いた跡が残り、ブレとなります。
数式でこれを表現すると、「畳込み」と呼ばれるものになります。
仮にシャッタースピードを十分に早くすることができた場合のシャープ画像を$I_\text{Sharp}$、 実際に取得されたブレのある画像を$I_\text{Blur}$とすると、
$I_\text{Blur} (x,y) = \int \int I_{Sharp} (x-u, y-v)k(u,v) du dv $
となります。ここで、$k(u,v)$は「カーネル」と呼ばれるもので、ブレの形を表します。例えば、シャッターを開いている間に「く」の字型にカメラをブレさせてしまった場合のブレ画像は、下の画像のようなカーネルを使ってシャープ画像を畳み込むことで再現できます。

この畳込み操作の式は高頻度で登場するため、簡易的に以下のように記述されることもあります。
$I_\text{Blur} = I_{Sharp} * k$
改めて、目的は、$I_\text{Blur}$が与えられたときに、この$I_{Sharp}$を求めることです。畳み込みの逆演算を行うことに相当しますので、逆畳み込み問題を解く、などと表現されることもあります。
この逆畳み込み問題に取り組む際、大切になってくるのは撮影時に画像に乗るノイズの取り扱いです。普段は気づかないかもしれませんが、撮像センサは熱雑音などの影響を受けており、拡大してよく見ると細かいノイズが乗っています。特に空間周波数の高い構造(細かい構造)を逆畳み込み演算する際に、このようなノイズは支配的になってくるため、ノイズの取り扱いも大きな論点です。その点も踏まえて、ノイズを表現する項$N$を加えて、上式は一般的に次のように書かれます。
$I_\text{Blur} = I_{Sharp} * k + N$
Deblurringの問題では、この式を大前提として、なるべく良い$I_{Sharp}$を推定していきます。
ブレ除去アルゴリズムを大別する要素
ブレを除去するアルゴリズムを作る上では、いくつか前提とする条件があります。以下では、それらについて述べていきます。
カーネルを事前に要求するか?
上式の中で、カーネル$k$が事前に分かっているのであれば、問題はだいぶ簡単になり、逆畳み込みの操作を実行するだけとなります。純粋に数学的な操作で$I_\text{Sharp}$を求めることができるため、深層学習などに頼る必要もありません。
ただし、カーネルが事前に分かるようなケースは現実的には限られています。
画像全体で共通のカーネルを想定しているか?
上の式では、画像全体で一つのカーネルを利用していました。実際、$k(u,v)$の形になっており、ピクセル座標$(x,y)$の変数とはなっていません。
カメラが一方向に移動したようなブレであれば、カーネルが全ピクセルに対して一定という仮定は成立します。
一方、固定カメラで人や車を捉えたようなケースでは、背景はブレていないものの、人や車だけがブレているというケースも発生します。このときには、カネールはピクセルごとに異なるため、問題の難易度が上がります。
どのような学習データを要求するか?
特に深層学習を利用したブレ除去の場合、事前にネットワークの学習が必要となることがあります。その際に必要な学習データがどのようなものかによって、準備難易度が大きく変わります。
同じシーンのブレ画像とシャープ画像が対で必要 [難易度:最大]
全く同じシーンについて、ブレ画像とシャープ画像が対で必要な場合、学習データの準備の難易度が上がります。準備をするためには、以下の2つの方法があります。
- シャッタースピードの短い画像 (シャープ画像)を時系列で記録しておく。その時系列の連続する数フレームを重ね合わせることで人工的なブレ画像を作る
- カメラに工夫をし、シャッタースピードの長い画像 (ブレ画像) と、短い画像 (シャープ画像) を同時に撮れるようにする
前者は一件簡単に見えますが、例えば一秒間に120px動くような点光源を30FPSで撮影した映像に適用すると、120px/30FPS=4pxおきに点が描画されているような映像になり、きれいなブレ画像を作ることができません。そのため、この手法を用いている
GoPro datasetでは、240FPSでの撮影をすることにより、滑らかなブレ画像を作っています。
後者についても、厳密に同じ画角の画像の対が必要になりますので、ESTRNNで導入されているような、レンズ中の光を2つに分けるビームスプリッターを内蔵した特殊カメラを準備する必要があります。
いずれの作り方にせよ、そもそも何らかの形でシャープな画像を撮影できることが前提となりますので、シャッタースピードが低くなりがちな夜などの環境で学習データを作ることはそもそも至難の技になります。
ブレ画像とシャープ画像が必要だが別のシーンで良い / シャープ画像のみで良い [難易度:中]
この場合は、例えば暗い夜にブレ画像を撮影し、明るい昼にシャープ画像を撮影するだけで必要な学習データを揃えることができます。
もしくは、同じ夜の時間帯に撮影するものの、ブレ画像は通常のカメラで撮影し、シャープ画像はもっと性能のよい明るいレンズ (光を集めやすい大きな口径のレンズ) のカメラを近くに設置して撮影することで集めることができます。
学習データを必要としない [難易度:低]
いくつかの手法は、そもそも学習データを必要としません。この場合は、学習データ収集という大きな障壁を回避することが可能です。
推論をOnePassで行うか?
通常の深層学習では、画像を入力してForward Propagationを行い出力を出す、いわゆるOnePassの推論が多く用いられます。この推論は、GPUを用いれば通常数十msで終わりますので、リアルタイムのブレ除去を行うことが可能です。
一方、ブレ除去においてはそうでない手法も数多く存在し、何千回もの繰り返し計算を要求するものもあります。この場合、画像1枚あたりのブレ除去に数分を要しますのので、リアルタイムの処理は難しくなります。
単一フレームのみ考慮するか?複数フレームを考慮するか?
ブレ除去の場合、動き情報を正しく取り込むため、複数フレームを考慮した方がより精度が上がります。これはVideo deblurringなどと呼ばれます。
本記事では、まず単一フレームのみ考慮するSingle image deblurringについてのみ取り扱うことにしたいと思います。
過去の研究
以上の観点を踏まえながら、Single image deblurringについて、代表的な研究を見ていきたいと思います。まずは深層学習ではない手法からスタートして、中盤以降は深層学習を使った手法を紹介します。
Wiener Deconvolution
カーネルが予め分かっている場合、逆畳み込み演算はフーリエ変換を通して簡単に計算することができます。詳細はWikipediaなどに詳しく書いてあるためここでは踏み込みませんが、フーリエ変換されたカーネルの逆数に対して畳み込み演算を行うことで一意に計算することができます。
ただし、特に画像の高周波成分がノイズの影響を受けがちなため、Signal-to-Noise Ratio (SNR) の大きさを見ながら影響を軽減する補正を加えたのが、Wiener Deconvolutionになります。
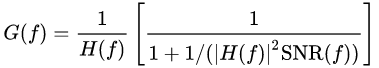
また、「リンギング」などと呼ばれる繰り返し模様が発生したりします。このような、アルゴリズムが生み出した画像の不良を一般にアーティファクトと呼びます。
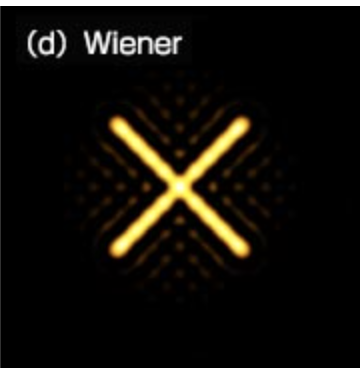
(超解像顕微鏡に全力投球より引用)
Richardson-Lucy deconvolution
こちらもカーネルがきちんと分かっているときに有効な手法で、条件付き確率の考え方を用いた逆畳み込みの方法になります。数式の整理や導出が複雑なので、詳細は弊社インターンの方の記事に譲ります。
ある処理を何度も画像に適用していくと、徐々にシャープ画像が推定されていく処理方法です。
Deep Image Prior / Self-Deblur
ここから、深層学習を用いた手法になります。
Deep Image Priorはとても気に入っている研究なのでぜひ一度論文に目を通してもらうと良いと思います。ここで主張しているのは、
- 深層学習モデルは、Convolution Layerが組み合わされて作られているが、その構造がすでに自然界の"自然な"画像の様子をうまく取り込んだものとなっている。
- U-Net型のネットワークを作って、AutoEncoderのような学習をさせる。その時、入力画像が自然であればすんなり学習してLossは下がるが、不自然な画像を入力しているとLossがなかなか下がらない (Impedanceを持つ)
ということです。実際に、自然な画像と、人工的なノイズ画像をそれぞれ入れてLossの下がり具合を見たのが以下のグラフです。
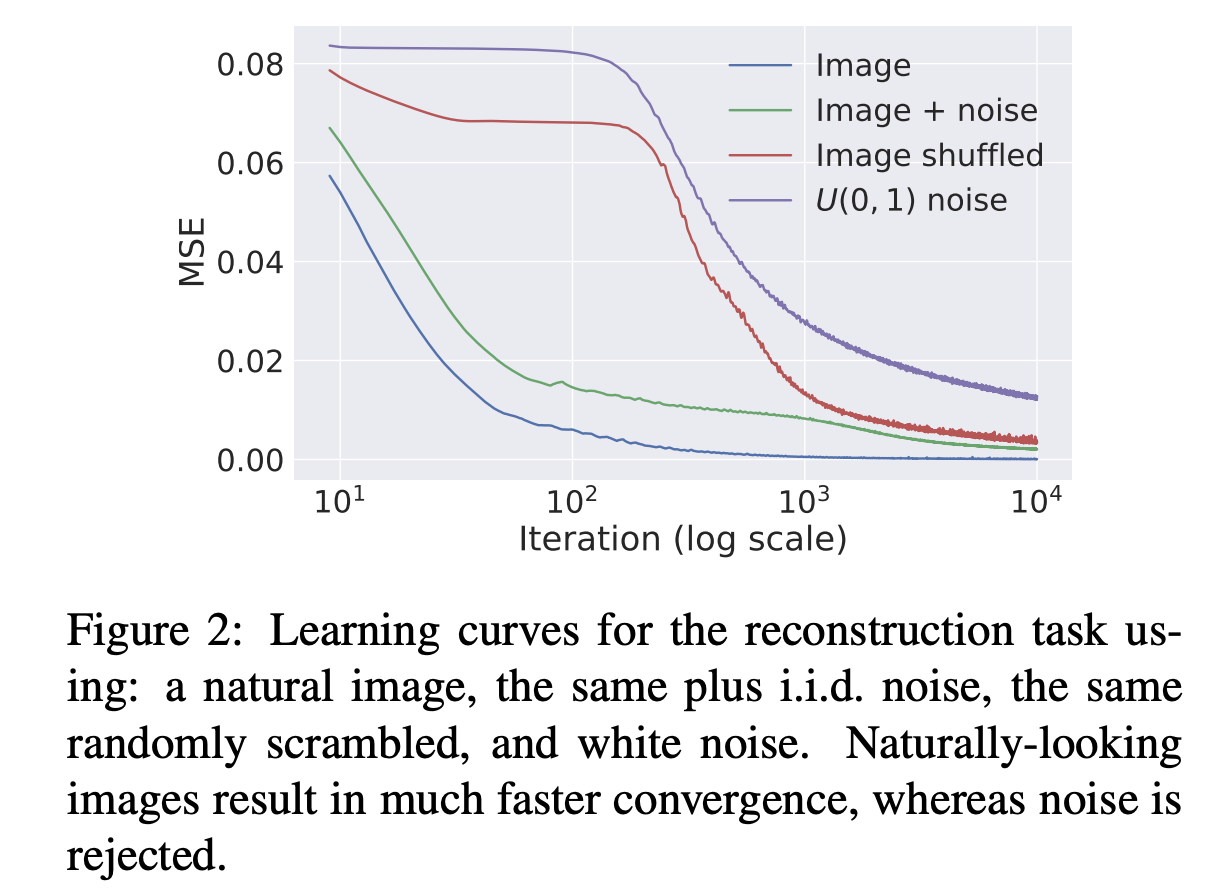
例えばこのようなノイズ画像を入れたときにも、徐々にきれいな画像になっていきます。

それどころか、一部画像にマスクを掛けたとしても、それを埋めて自然な画像を復元してしまいます。

このように、深層学習のネットワーク構造は、すでに「何が自然な画像か?」を判断するための性質が備わっているということが分かったので、その性質を用いてブレの除去を行う試みがSelf-Deblurです。
逆畳み込み問題では、ブレ画像$y$が与えられたときにシャープ画像$x$を推定するような問題を解くわけですが、前述のようにノイズの影響を強く受けてしまったり、おかしな構造のアーティファクトを生み出してしまうという問題を抱えています。それを防ぐために、自然な画像かどうかを判断する指標である$\mathcal{R}(x)$を導入し、目的関数に制約を掛けることで、ノイズやアーティファクトの少ない自然なシャープ画像を推定させようという方針です。
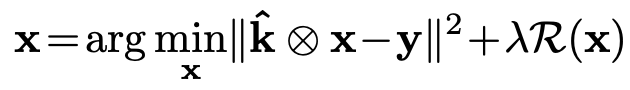
これを実際に実装する上で、直接、$\mathcal{R}(x)$を計算するのではなく、convolutionから構成される「自然な画像」を好むネットワーク$\mathcal{G_x}$を作り、そのパラメータを最適化する方法を取っています。
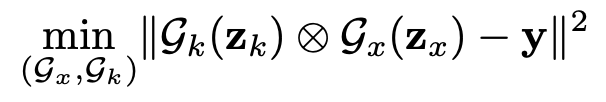
実際にブレ除去された画像は以下になります。他の手法はアーティファクトを作ってしまっていますが、Self-deblurにはそのような現象は見られません。

この手法は、学習データが不要という面で優れています。一方で、$\mathcal{R}(x)$の最適化のために数千回の繰り返し計算が必要であり、計算に時間がかかります。また、放っておくと過学習されてしまい、ブレ画像と同じ画像が出力されるようになってしまいます。止め時は肉眼で判断するしか無いため、それが実用上の大きな課題となります。
Image restoration using Autoencoding Priors
この手法でも同様に、「何が自然な画像か?」という情報を使ってブレの除去を行います。ただし、画像の自然さを判断するために、予めシャープ画像で学習させたDenoising AutoEncoderを利用することが新しい試みです。
この研究の中では、ブレ画像$B$と所与のカーネル$K$、および、予めImageNetで学習させたDenoising AutoEncoder $A_{\sigma_\eta}$を用いて、シャープ画像$I$の推定を以下のように行います。$D$も登場しますが、これは超解像への応用のときに使えるよう一般化して書いているだけですので、ここでは無いものとして読んでいただいて構いません。
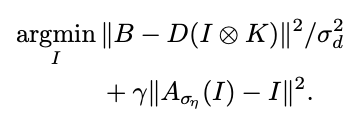
1つ目のタームは、所与のカーネルを使いながら逆畳み込み問題を解く形の最適化です。ただ、それだけだと、ノイズやアーティファクトの影響を受けた不自然な画像が推定されてしまいます。それを解決するために2つ目のタームで、Denoising AutoEncoderによって「自然な画像かどうか?」を判断させ、自然さを増すように最適化の目的関数に制約を掛けます。
結果として、逆畳み込みを単純に解くような手法(ここではLucy Richardson)と比べると、ノイズやアーティファクトの少ない綺麗な画像が作られていることが分かると思います。

DeblurGAN (v1, v2)
Pix2Pixの目覚ましい成果を見ていると、これをブレ除去に使えないかという発想が生まれます。つまり、ブレ画像を入力してシャープ画像を出力するようなU-Net状のGeneratorを作ります。Discriminatorは、シャープ画像かどうかを判定させるようにしておけば、Generatorがシャープ画像を出力するよう学習できるはずです。
これを実際にやったのがDeblurGAN(v1)(v2)になります。
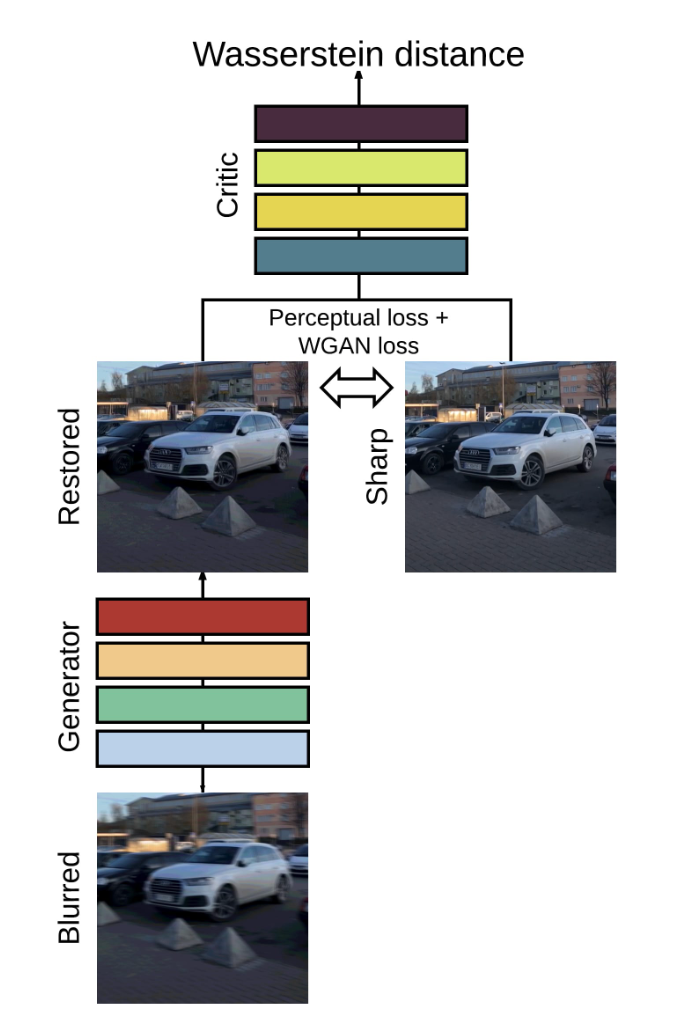
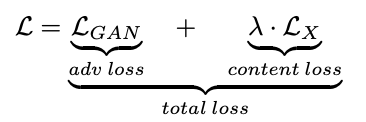
学習の設計は上図のようにシンプルですが、Lossの設計には工夫があります。通常のGAN学習に関するadv lossに加え、content lossという項を加えています。これは、Generatorによって「復元されたシャープ画像」$G_{\theta_G} (I^B)$と、「学習データのシャープ画像」$I^S$が同じ内容であることを要求するものです。これがない場合、Generatorは入力画像と関係のない画像を出力するようになってしまう"Mode collapse"を起こす可能性があるため、学習の安定化には重要な項です。この研究の中では、content lossは、$G_{\theta_G} (I^B)$と$I^S$をVGG16に通したときの中間層の特徴量の一致具合から計算されています(同様のlossのことを、論文によってはperceptual lossと呼ぶこともあります)
また、このcontent lossの存在により、学習時にはブレ画像・シャープ画像の対が必要となるという弱点が生まれてしまっています。
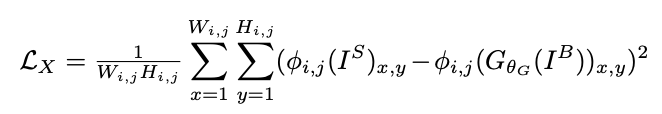
結果については下の通りで、アーティファクトもないきれいにブレ除去ができています。

また、カーネルが場所ごとに違うようなシーンでも、ブレの改善を実現しています。

SL-CycleGAN
DeblurGANはPix2Pixと似たような発想から出てくるものと述べましたが、逆にGANの中でも、対になっている画像をなるべく用いないことを謳うものが存在します。CycleGANはその典型です。その学習の仕組みをブレ除去に利用しようとしたのがSL-CycleGANになります・・・と期待を高めましたが、おそらく研究の途中で何らかの問題に行き当たったののでしょう、結局、DeblurGANと同様、同一画像に対するブレ画像・シャープ画像対のperceptual lossを取るようになってしまっているため、学習時にブレ・シャープ画像対が必要だという条件の緩和には至っていません。
一方で、DeblurGAN-v2と比較して、ブレ除去がより精緻に行えると主張しています。

似た発想のアプローチに、Deblurring by Realistic Blurringもあります。ただしこれも、perceptual lossを使っていますので、上に挙げた問題点は解決されていません。
番外編: Enlighten-GAN
これだけ、ブレ除去の問題設定ではなく、暗く撮影されてしまった画像の明るさを最適化し、きれいな(HDRチックな)画像を作り出すものです。問題設定は異なるものの、ある劣化した画像を入力として受け、鮮明な画像を出力するという点で、広い視点では類似しています。
なにより、この研究にける提案手法は、ブレ画像・シャープ画像対に対応する対の画像を使わない状況でも学習を可能にできるよう工夫をしています。
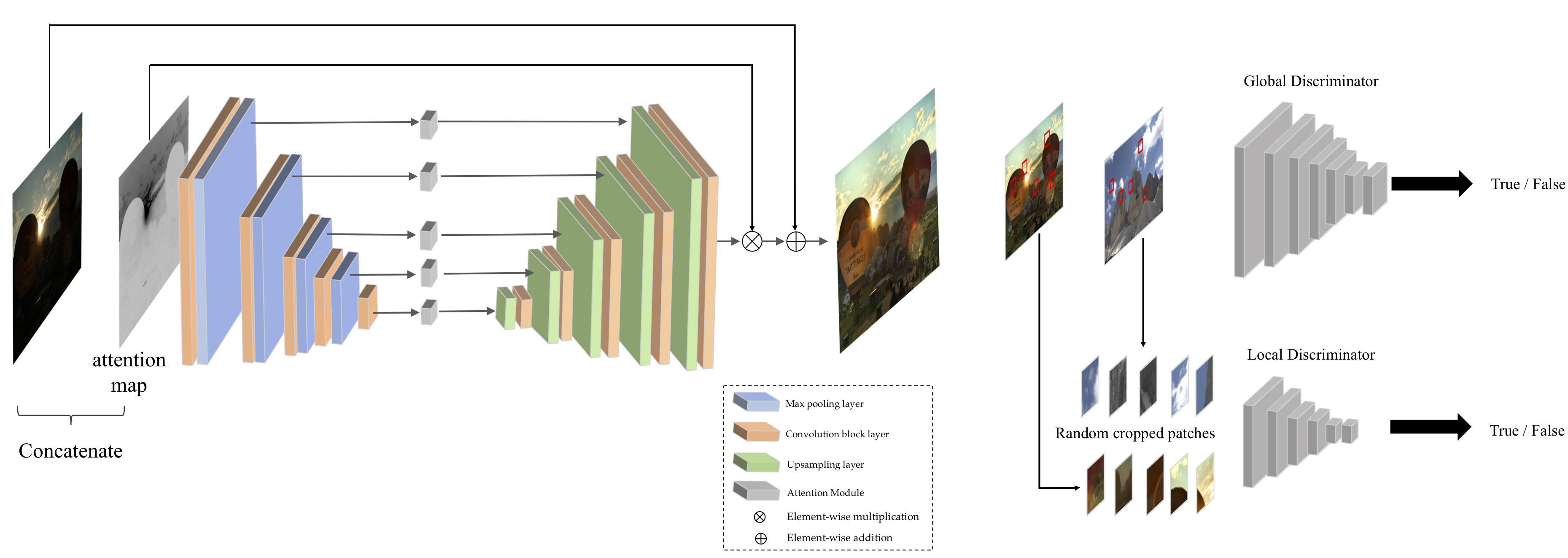
この手法では、同一シーンについての対の画像は必要なく、劣化した画像群ときれいな画像群がそれぞれ別に用意されていれば学習が可能です。Mode Collapseさせず、Generatorが入力画像に対応する画像をきちんと作るような制約は、Generatorの入力画像・出力画像の間のperceptual lossを取ることによって実現されています。
まとめ: それぞれの研究の長所と短所
以上、深層学習を用いたSingle image deblurringについて、いくつかの研究を見てきました。この分野の研究は、どれだけきれいなシャープ画像を推定するかという定量指標で報告されていますが、実応用の観点では冒頭でまとめたような、「前提条件」としてそれぞれ何を要求するか、というのがより重要になってくるかと思います。その点について、表の形式で整理したのが以下です:
| 研究 | カーネルを事前に要求するか? | 画像全体で共通のカーネルを想定しているか? | どのような学習データを要求するか? | 推論をOnePassで行うか? |
|---|---|---|---|---|
| Wiener Deconvolution | △ カーネルを与える必要あり | △ カーネルは画像全体で一定 | ◎ 学習画像不要 | ◎ OnePass (リアルタイム可能) |
| Richardson-Lucy deconvolution | △ カーネルを与える必要あり | △ カーネルは画像全体で一定 | ◎ 学習画像不要 | ○ OnePassでない (ただし、計算はある程度早い) |
| Self-deblur | ◎ カーネルを与える必要は無い | △ カーネルは画像全体で一定 | ◎ 学習画像不要 | △ OnePassでない (数分程度必要) |
| Image restoration using Autoencoding Priors | △ カーネルを与える必要あり | △ カーネルは画像全体で一定 | ○ 学習画像はシャープ画像のみで良い | △ OnePassでない(数分程度必要) |
| DeblurGAN | ◎ カーネルを与える必要は無い | ◎ 局所ブレ対応可能 | × ブレ画像とシャープ画像の対が必要 | ◎ OnePass(リアルタイム可能) |
| SL-CycleGAN | ◎ カーネルを与える必要は無い | ◎ 局所ブレ対応可能 | × ブレ画像とシャープ画像の対が必要 | ◎ OnePass(リアルタイム可能) |
| Enlighten-GAN (※ブレ除去ではない) | ◎ カーネルを与える必要は無い | ◎ 局所ブレ対応可能 | ○ ブレ画像群とシャープ画像群がそれぞれあればよい | ◎ OnePass(リアルタイム可能) |
最後に、会社の紹介をさせてください。ニューラルポケットでは、人々が便利で幸せな生活を送れるスマートシティの実現に向け、深層学習モデルの開発を進めています。上記で述べたような、DeblurGANの改良などにも取り組み、アカデミアの研究成果を実応用の世界に適用するための開発活動を日々行っています。社員としての採用も、インターンの募集もしていますので、少しでも興味を持っていただけた方は、ぜひ以下のページからご連絡をいただけますと幸いです。
[AIエンジニア] https://hrmos.co/pages/neuralpocket/jobs/1725841606893461511
[インターン] https://hrmos.co/pages/neuralpocket/jobs/1725841606893461512