記事を書く動機
CVPR 2024に現地参加することになったため、実際に行く前にどんなもんかざっくりと把握がしたい!
CVPR 2024とは
2024/6/17~2024/6/21にシアトルコンベンションセンターにて開催されるコンピュータビジョン(Computer Vision)とパターン認識(Pattern Recognition)に関するカンファレンス。
採択された論文数は2719本に及ぶ大規模なトップカンファレンスとなっており、全世界が注目しているといっても過言ではない(過言かもしれない)。
今年のトレンド

上記表からわかる通り、今年は(今年に限らず少し前からの感はあるが)
- Generation
- 3D
- Language
- Multi-modal
等の生成AI、点群技術に関連していそうなワードが含まれる分野の論文数が多い。
その他にも人に関する分析、DNNの学習に関する事柄、一般的によく耳にするワード、自動運転、医療分野への応用など普段からなじみのある分野も挙げられている。
論文タイトルから単語レベルでは
- Diffuion
- 3D
- Generation
- Language
- Video
- Detection
- Segmentation
- Reconstruction
- Human
- Transformer
- Multimodal
が見られ、CVPR trendsと世間の流行が概ね一致している感想を受ける。
以下、気になるものを雑多にピックアップする。
※簡単なコメント以外は基本的に機械翻訳ですが、雰囲気を感じることが目的なのでご容赦ください。
LEGaussians: Language Embedded 3D Gaussians for Open-Vocabulary Scene Understanding
Project Page
Th, Jun 20, 09:00 -- Poster Session 2 & Exhibit Hall
Language Embedded 3D Gaussiansというオープンボキャブラリタスク用の新しいシーン表現を提唱。
結果からはいい感じに埋め込み表現を獲得できているように見える。
Abstract

3D 空間でのオープン語彙クエリは困難ですが、オブジェクトのローカリゼーションやセグメンテーションなどのシーン理解タスクには不可欠です。言語埋め込みシーン表現は、言語機能を 3D 空間に組み込むことで進歩してきました。ただし、その有効性は、トレーニングとレンダリングにリソースを大量に消費するニューラル ネットワークに大きく依存しています。最近の 3D ガウス分布は効率的で高品質の新しいビュー合成を提供しますが、言語機能を直接埋め込むと、メモリ使用量が法外になり、パフォーマンスが低下します。この研究では、オープン語彙クエリ タスク用の新しいシーン表現である Language Embedded 3D Gaussiansを紹介します。高次元の生の意味機能を 3D ガウス分布に埋め込む代わりに、メモリ要件を大幅に軽減する専用の量子化スキームと、ポイントベース表現のマルチビュー機能の不一致と高周波の帰納的バイアスに対抗して、よりスムーズで高精度なクエリを実現する新しい埋め込み手順を提案します。私たちの包括的な実験により、私たちの表現は、単一のデスクトップ GPU 上でリアルタイムのレンダリング フレーム レートを維持しながら、現在の言語埋め込み表現の中で最高の視覚品質と言語クエリ精度を実現することが示されました。
Overview

言語埋め込み 3D ガウス分布のトレーニング プロセスは、3D ガウス分布のスプラッティングに従ってシーンを初期化し、意味的特徴をランダムに初期化して不確実性をゼロに設定することから始まります。マルチビュー CLIP と DINO からの高密度言語特徴は量子化され、離散的特徴空間と意味的インデックスが作成されます。次に、3D ガウス分布のこれらの属性は、微分可能ラスタライザーを使用して 2D マップにレンダリングされます。最適化は、意味的および適応的な空間スムージング損失によって実現されます。
Results

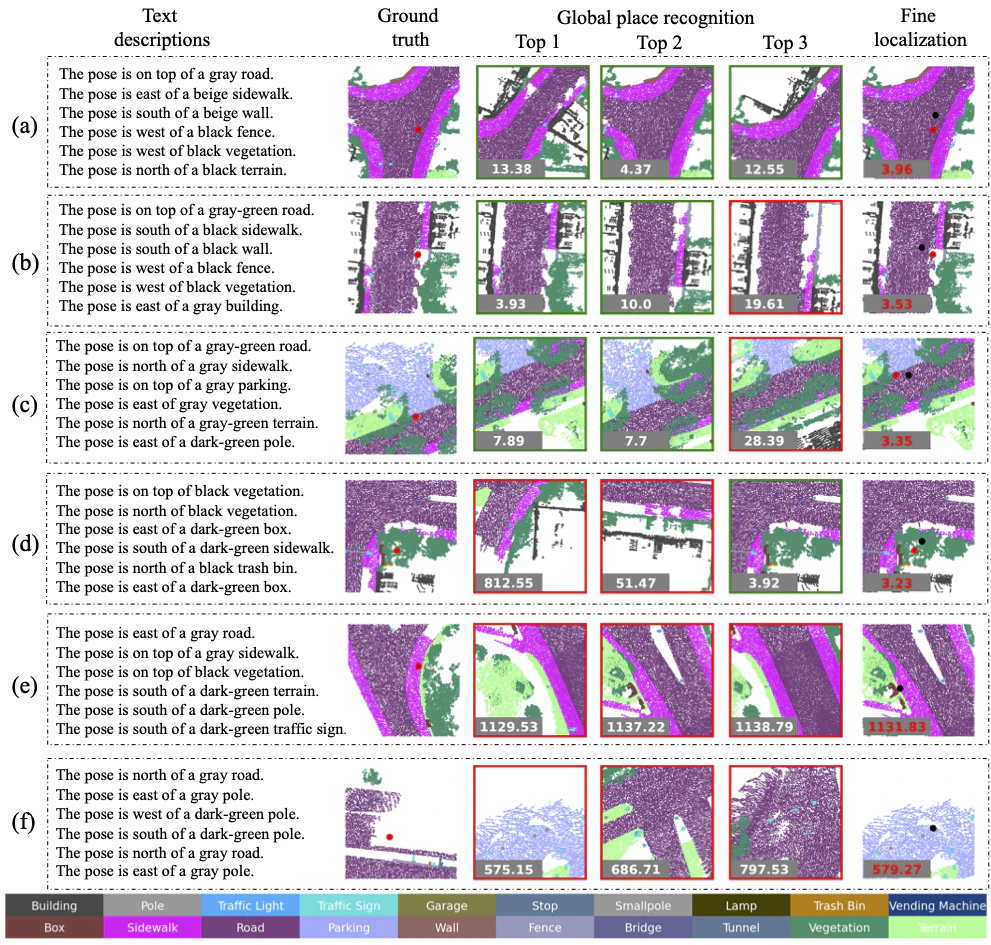
Text2Loc: 3D Point Cloud Localization from Natural Language
Project Page
Fr, Jun 21, 09:00 -- Poster Session 4 & Exhibit Hall
Text2Locという自然言語を用いて点群の位置推定を行う。
自然言語と点群についての特徴量の対応を学習している?と思われ興味深い。
ぱっと見textの書き方はルールがありそう(The pose is ...)に見える。
Abstract
私たちは、いくつかの自然言語記述に基づく 3D ポイント クラウドの位置特定という問題に取り組み、ポイントとテキストの意味関係を完全に解釈する新しいニューラル ネットワーク Text2Loc を紹介します。Text2Loc は、粗から細への位置特定パイプライン (テキスト サブマップのグローバルな場所の認識、その後の細かな位置特定) に従います。グローバルな場所の認識では、各テキスト ヒント間の関係ダイナミクスが階層型トランスフォーマーと最大プーリング (HTM) でキャプチャされ、正と負のペアのバランスはテキスト サブマップの対照学習を使用して維持されます。さらに、複雑なテキスト インスタンスのマッチングの必要性を完全に排除し、以前の方法よりも軽量、高速、正確な、マッチングを必要としない新しい細かな位置特定方法を提案し、位置予測をさらに改良します。広範な実験により、Text2Loc は KITTI360Pose データセットで最先端の方法よりも最大 2 倍の位置特定精度を向上させることが示されています。コードは公開されます。

Method
Text2Loc architecture: グローバルな場所認識と精細な位置特定という 2 つのタンデム モジュールで構成されています。
グローバルな場所認識:テキストベースの位置記述が与えられた場合、まず、大まかな候補位置のセット、つまり「サブマップ」を特定します。
サブマップには、ターゲット位置が含まれる可能性があり、クエリの大まかな位置特定として機能します。
これは、新しいテキストからセルへの検索モデルを使用して、以前に構築されたサブマップのデータベースから上位 k 個の最も近いセルを取得することで実現されます。
精細な位置特定:次に、取得したサブマップの中心座標を、設計したマッチングフリーの位置推定モジュールを使用して調整し、精度を高めます。

Qualitative Localization Results
KITTI360Pose データセットの定性的な位置特定結果。
グローバルな場所認識では、上位 3 つの検索サブマップの数字は、検索されたサブマップと実際の位置との中心距離を表します。
緑色のボックスは、ターゲット位置を含む正のサブマップを示し、赤色のボックスは負のサブマップを表します。
詳細な位置特定では、赤色と黒色のドットは実際の位置と予測されたターゲット位置を表し、赤色の数字はそれらの間の距離を示します。
RegionGPT: Towards Region Understanding Vision Language Model
Project Page
Fr, Jun 21, 02:30 -- Poster Session 3 & Exhibit Hall
画像内の領域を指定するとその領域の説明を返してくれるVLM。
画像全体のキャプション生成とかはよく見るけど、領域指定なのが面白い。
書いてあることベースだと精度もまぁ良さそう。
Abstract
視覚言語モデル (VLM) は、大規模言語モデル (LLM) と画像とテキストのペアの統合を通じて急速な進歩を遂げてきましたが、視覚エンコーダの空間認識が限られていることと、詳細な地域固有のキャプションがない粗粒度のトレーニング データを使用しているため、詳細な地域の視覚理解が困難です。
これに対処するために、複雑な地域レベルのキャプションと理解のために設計された新しいフレームワーク、RegionGPT (略して RGPT) を紹介します。
RGPT は、VLM の既存の視覚エンコーダにシンプルかつ効果的な変更を加えることで、地域表現の空間認識を強化します。
さらに、トレーニング フェーズと推論フェーズの両方でタスク ガイド付きの指示プロンプトを統合することで、特定の出力スコープを必要とするタスクのパフォーマンスを向上させながら、汎用タスクに対するモデルの汎用性を維持します。
さらに、自動化された地域キャプション データ生成パイプラインを開発し、詳細な地域レベルのキャプションでトレーニング セットを充実させます。
我々は、ユニバーサル RGPT モデルを効果的に適用でき、複雑な領域の説明、推論、オブジェクトの分類、参照表現の理解など、さまざまな領域レベルのタスクにわたってパフォーマンスを大幅に向上できることを実証します。
Overview
マルチモーダル大規模言語モデルに 複雑な領域レベルのキャプション、推論、分類、および参照表現の理解機能を可能にする RegionGPT を紹介します。
ユーザーは、命令内の任意の位置でをプレースホルダーとして使用して、任意の形状の関心領域を入力できます。
このようなプレースホルダーは、その後、言語デコーダーに送られるセマンティックな領域レベルの埋め込みに置き換えられます。

論文のProject Pageでは結果について詳しい説明もなされている。
GSVA: Generalized Segmentation via Multimodal Large Language Models
Th, Jun 20, 02:30 -- Poster Session 1 & Exhibit Hall
MLLMを使用したセグメンテーションに関する論文。
複数ターゲットや対象が存在しない場合の過検出を抑える工夫をしている。
GSVAを提案。
Poster内でFrozenっぽいイラストのVision Encoderには何を使っているのか?
Poster

Abstract
一般化参照表現セグメンテーション (GRES) は、従来の RES の範囲を拡張して、1 つの表現で複数のオブジェクトを参照したり、画像に存在しない空のターゲットを識別したりします。
GRES では、画像内のインスタンスの複雑な空間関係をモデル化し、存在しない参照先を識別するという課題があります。
マルチモーダル大規模言語モデル (MLLM) は、これらの複雑な視覚言語タスクで最近大きな進歩を見せています。
大規模言語モデル (LLM) と視覚モデルを接続する MLLM は、視覚入力によるコンテキストの理解に優れています。
その中でも代表的な LISA は、特別な [SEG] トークンを採用してセグメンテーション マスク デコーダー (SAM など) をプロンプトし、RES タスクで MLLM を有効にします。
ただし、現在のセグメンテーション MLLM では、ユーザーが単一のプロンプトで複数の対象を参照したり、画像ターゲットと一致しない説明を提供したりする場合を正しく処理できないため、GRES の既存のソリューションは不十分なままです。
本稿では、このギャップを解決するために、一般化セグメンテーション ビジョン アシスタント (GSVA) を提案します。
具体的には、GSVA は [SEG] トークンを再利用して、セグメンテーション モデルが複数のマスク参照を同時にサポートするように促し、革新的な方法で [REJ] トークンを生成してヌル ターゲットを明示的に拒否するように学習します。
実験により、GSVA が GRES 問題を解決する有効性が検証され、GRES ベンチマーク gRefCOCO データセットで顕著な機能強化と新記録を達成しました。
GSVA は、さまざまな従来の参照セグメンテーションおよび理解タスクでも有効であることが証明されています。
コードは https://github.com/LeapLabTHU/GSVA で入手できます。
※コードはこれから追加予定とのこと
Repository of GSVA: Generalized Segmentation via Multimodal Large Language Models.
Code will be released soon.
🍴 FAMix 🍴 A Simple Recipe for Language-guided Domain Generalized Segmentation
ドメイン適応(or 一般化)にLLMが使えることを示唆する論文。
論文ではCLIPによるvision-languageモダリティを使用している。
CLIPの言語モダリティをソースとして使用しセグメンテーションタスクの一般化をしている(ように見える)。
Abstract
トレーニング中に見られなかった新しいドメインへの一般化は、ニューラル ネットワークを実際のアプリケーションに展開する際の長年の目標および課題の 1 つです。
既存の一般化手法では、外部データセットから取得される可能性のある大量のデータ拡張が必要であり、さまざまなアライメント制約を課すことで不変表現を学習することを目的としています。
大規模な事前トレーニングは最近、有望な一般化機能と、異なるモダリティを橋渡しする可能性を示しています。
たとえば、CLIP などの視覚言語モデルの最近の登場により、視覚モデルがテキスト モダリティを活用する道が開かれました。
この論文では、言語をランダム化のソースとして使用して、セマンティック セグメンテーション ネットワークを一般化するシンプルなフレームワークを紹介します。
私たちのレシピは、
i) 最小限の微調整による CLIP 固有の堅牢性の維持、
ii) 言語主導のローカル スタイルの拡張、
iii) トレーニング中にソース スタイルと拡張スタイルをローカルに混合することによるランダム化
という 3 つの主要な要素で構成されています。
広範囲にわたる実験により、さまざまな一般化ベンチマークにおける最先端の結果が報告されています。コードは公開される予定です。
Approach

YouTube
動画
FAMixがいい感じなのが見られる。
Summarize the Past to Predict the Future: Natural Language Descriptions of Context Boost Multimodal Object Interaction Anticipation
Fr, Jun 21, 09:00 -- Poster Session 4 & Exhibit Hall
過去の行動(動画)から次の行動を予測するタスク。
TransFusionというアーキテクチャを提案し、画像だけでなく言語を使用することで精度向上を図った。
Poster

Abstract
私たちは、自己中心的なビデオにおけるオブジェクトインタラクション予測を研究しています。
このタスクでは、オブジェクトに対する過去のアクションによって形成された時空間コンテキスト (「アクションコンテキスト」と呼ばれる) を理解する必要があります。
私たちは、短期的なオブジェクトインタラクション予測のためのマルチモーダルトランスフォーマーベースのアーキテクチャである TransFusion を提案します。
私たちの方法は、事前トレーニング済みの視覚言語基盤モデルを利用して過去のビデオフレームからアクションコンテキストを抽出した後、アクションコンテキストをテキストで要約することで言語の表現力を活用します。
要約されたアクションコンテキストと最後に観察されたビデオフレームは、マルチモーダルフュージョンモジュールによって処理され、次のオブジェクトインタラクションを予測します。
Ego4D の次のアクティブオブジェクトインタラクションデータセットでの実験は、私たちのマルチモーダルフュージョンモデルの有効性を示し、視覚だけで十分と思われるタスクで基盤モデルと言語ベースのコンテキスト要約の力を使用することの利点を強調しています。
私たちの新しいアプローチは、Ego4D データセットの両方のバージョンですべての最先端の方法よりも優れています。
OneLLM: One Framework to Align All Modalities with Language
Sa, Jun 22, 09:00 -- Poster Session 6 & Exhibit Hall
これまではモダリティごとにEncoderを用意していたが、Vision TransformerをUniversal Encoderとして使用し、1つのEncoderで複数モダリティを扱っている。
似たようなモデルにImageBindがあった気がするけどどっちがどうなんだろうか。
Poster

Abstract
マルチモーダル大規模言語モデル (MLLM) は、その強力なマルチモーダル理解能力から大きな注目を集めています。
しかし、既存の研究はモダリティ固有のエンコーダーに大きく依存しており、これらは通常、アーキテクチャが異なり、共通のモダリティに限定されています。
本稿では、統一されたフレームワークを使用して8 つのモダリティを言語に合わせる MLLM であるOneLLMを紹介します。
これは、統一されたマルチモーダル エンコーダーと漸進的なマルチモーダル アライメント パイプラインによって実現されます。
詳細には、最初に画像投影モジュールをトレーニングして、ビジョン エンコーダーを LLM に接続します。
次に、複数の画像投影モジュールと動的ルーティングを組み合わせて、ユニバーサル投影モジュール (UPM) を構築します。
最後に、UPM を使用して、より多くのモダリティを LLM に漸進的に合わせます。指示に従う際の OneLLM の可能性を最大限に活用するために、画像、音声、ビデオ、ポイント クラウド、深度/法線マップ、IMU、fMRI 脳活動からの200 万項目を含む包括的なマルチモーダル指示データセットもキュレートしました。
OneLLM は、マルチモーダルキャプション、質問回答、推論などのタスクを網羅する25 の多様なベンチマークで評価され、優れたパフォーマンスを発揮します。
コード、データ、モデル、オンラインデモは https://github.com/csuhan/OneLLM で入手できます。
MMA: Multi-Modal Adapter for Vision-Language Models
Sa, Jun 22, 02:30 -- Poster Session 5 & Exhibit Hall
CLIPへのadapter追加によるImage Classificationタスクの精度向上研究。
モデルの微調整をLoRA等で行うのはよく見たが、shared layerを持ってlanguage-vision両モーダルで同じものを使うのは面白いなと感じた。
Poster

LISA: Reasoning Segmentation via Large Language Model
LLMによるOpen-Vocaburaryセグメンテーションのガイド的な内容。
SAM + LLM + adapter のような構成に見える。
Microsoftっぽいしいい感じだと信じたい。
Poster

Abstract
近年、知覚システムは目覚ましい進歩を遂げていますが、視覚認識タスクを実行する前に、依然として人間の明示的な指示や定義済みのカテゴリに依存して対象オブジェクトを識別しています。
このようなシステムは、ユーザーの暗黙の意図を積極的に推論して理解することはできません。
この研究では、新しいセグメンテーションタスクである推論セグメンテーションを提案します。このタスクは、複雑で暗黙的なクエリテキストが与えられた場合にセグメンテーションマスクを出力するように設計されています。
さらに、評価目的で複雑な推論と世界知識を組み込んだ、1,000を超える画像指示マスクデータサンプルを含むベンチマークを確立しました。
最後に、マルチモーダル大規模言語モデル(LLM)の言語生成機能を継承しながら、セグメンテーションマスクを生成する機能も備えたLISA:大規模言語指示セグメンテーションアシスタントを紹介します。
元の語彙を拡張し、トークンを作成し、マスクとしての埋め込みパラダイムを提案してセグメンテーション機能を解き放ちます。
驚くべきことに、LISA は複雑な推論と世界知識を含むケースを処理できます。また、推論のないデータセットのみでトレーニングした場合、堅牢なゼロショット機能を発揮します。
さらに、わずか 239 個の推論セグメンテーション データ サンプルでモデルを微調整すると、パフォーマンスがさらに向上します。
定量的および定性的な実験の両方で、この方法がマルチモーダル LLM の新しい推論セグメンテーション機能を効果的に解き放つことが示されています。
コード、モデル、およびデータは、github.com/dvlab-research/LISA で入手できます。
Inversion-Free Image Editing with Natural Language
Project Page
Th, Jun 20, 09:00 -- Poster Session 2 & Exhibit Hall
Diffusion ModelベースのアーキテクチャDenoising Diffusion Consistent Model (DDCM)を考案。
テキストをプロンプトとして入れ、inputに対するテキストと出力してほしいテキストの差分をベースに編集を行う(ように見える)。
とても良い感じに編集できているように見える。
Poster

Abstract
反転ベースの編集における最近の進歩にもかかわらず、テキスト誘導画像操作は拡散モデルにとって依然として課題となっています。
主なボトルネックには、
- 反転プロセスの時間のかかる性質、
- 一貫性と精度のバランスをとることの難しさ、
- 一貫性モデルで使用される効率的な一貫性サンプリング方法との互換性の欠如
が含まれます。
上記の問題に対処するために、まず、編集のために反転プロセスを排除できるかどうかを自問します。
初期サンプルがわかっている場合、特別な分散スケジュールにより、ノイズ除去ステップが複数ステップの一貫性サンプリングと同じ形式に削減されることを示します。
これをノイズ除去拡散一貫性モデル (DDCM) と名付け、サンプリング時に明示的な反転を行わない仮想反転戦略を意味することを指摘します。
さらに、テキスト誘導編集用のチューニング不要のフレームワークで注意制御メカニズムを統合します。
これらを組み合わせることで、反転不要の編集 (InfEdit) を提示します。
これにより、画像の整合性と明示的な反転を損なうことなく複雑な変更に対応し、リジッドおよび非リジッドの両方の意味変更に対して一貫性のある忠実な編集が可能になります。
広範囲にわたる実験を通じて、InfEdit はさまざまな編集タスクで優れたパフォーマンスを示し、シームレスなワークフロー (1 つの A40 で 3 秒未満) も維持し、リアルタイム アプリケーションの可能性を実証しました。
Sat2Scene: 3D Urban Scene Generation from Satellite Images with Diffusion
Th, Jun 20, 09:00 -- Poster Session 2 & Exhibit Hall
Diffusion modelを使って、衛星画像から3D都市シーンを予測する。
先行研究ではGANを使っていた?
本当に質の良いものができるならすごい。
Poster

Abstract
衛星画像から直接シーンを生成することは、ゲームや地図サービスなどのアプリケーションに統合できるエキサイティングな可能性を提供します。
ただし、ビューの大幅な変更とシーンのスケールから課題が生じます。
これまでの取り組みは主に画像またはビデオの生成に焦点を当てており、任意のビューに対するシーン生成の適応性については調査されていませんでした。
既存の 3D 生成作業は、オブジェクト レベルで動作するか、衛星画像から取得したジオメトリを利用するのが困難です。
これらの制限を克服するために、拡散モデルを 3D スパース表現に導入し、ニューラル レンダリング手法と組み合わせることで、直接 3D シーンを生成するための新しいアーキテクチャを提案します。
具体的には、私たちのアプローチでは、最初に 3D 拡散モデルを使用して特定のジオメトリのポイント レベルでテクスチャ カラーを生成し、次にフィードフォワード方式でシーン表現に変換します。
この表現は、単一フレームの品質とフレーム間の一貫性の両方で優れた任意のビューをレンダリングするために使用できます。
2 つの都市規模のデータセットでの実験では、私たちのモデルが衛星画像からフォトリアリスティックなストリート ビュー画像シーケンスとクロス ビューの都市シーンを生成する能力を発揮することが示されています。
DiffusionRegPose: Enhancing Multi-Person Pose Estimation using a Diffusion-Based End-to-End Regression Approach
Th, Jun 20, 02:30 -- Poster Session 1 & Exhibit Hall
複数人物の姿勢推定タスクに対しDiffusion modelベースのEnd-to-Endモデルを提案している。
Poster

Abstract
この論文では、1 段階のエンドツーエンドのキーポイント回帰モデルを拡散ベースのサンプリング プロセスに変換する、複数人のポーズ推定の新しいアプローチである DiffusionRegPose を紹介します。
既存の 1 段階の決定論的回帰法は効率的ではあるものの、ポーズの曖昧さを推論できないため、混雑したシーンや遮蔽されたシーンでは検出漏れや誤検出が発生する傾向があります。
これらの課題に対処するために、私たちは、拡散確率モデルによって特徴付けられる画像条件付きポーズ分布からサンプリングする生成的な方法で、つまり、曖昧なポーズを処理します。
具体的には、画像から抽出された初期ポーズ トークンを使用して、アテンション レイヤーを介して初期トークンと対話することで、ノイズの多いポーズ候補を徐々に絞り込みます。
COCO および CrowdPose データセットの広範な評価により、DiffusionRegPose は混雑したシナリオでのポーズ精度を明らかに向上させることがわかりました。
これは、CrowdPose データセットの$AP_H$メトリック。これは、現実世界のアプリケーションで堅牢かつ正確な人間の姿勢推定を行うためのモデルの潜在能力を示しています。
ReconFusion: 3D Reconstruction with Diffusion Priors
Project Page
Sa, Jun 22, 02:30 -- Poster Session 5 & Exhibit Hall
NeRFベースの3D再構成にDiffusionの枠組みを導入し、数枚の画像で再構成精度を上げている研究。
Poster

Abstract
Neural Radiance Fields (NeRF) などの 3D 再構成法は、複雑なシーンのフォトリアリスティックな新しいビューをレンダリングするのに優れています。
ただし、高品質の NeRF を復元するには、通常、数十から数百の入力画像が必要であり、時間のかかるキャプチャ プロセスになります。
ここでは、数枚の写真のみを使用して現実世界のシーンを再構成する ReconFusion を紹介します。
このアプローチでは、合成およびマルチビュー データセットでトレーニングされた拡散事前分布を利用して新しいビューを合成し、入力画像セットでキャプチャされたもの以外の新しいカメラ ポーズで NeRF ベースの 3D 再構成パイプラインを正規化します。
この方法では、観測された領域の外観を維持しながら、制約の少ない領域にリアルなジオメトリとテクスチャを合成します。
正面および 360 度のシーンを含むさまざまな現実世界のデータセットで広範な評価を実行し、以前の少数ビューの NeRF 再構成アプローチよりも大幅なパフォーマンスの向上を実証しました。
ECoDepth: Effective Conditioning of Diffusion Models for Monocular Depth Estimation
Project Page
Sa, Jun 22, 09:00 -- Poster Session 6 & Exhibit Hall
Abstract
視差の手がかりがない場合、学習ベースの単一画像深度推定 (SIDE) モデルは、画像内の陰影とコンテキストの手がかりに大きく依存します。
このシンプルさは魅力的ですが、キャプチャするのが難しい大規模で多様なデータセットでこのようなモデルをトレーニングする必要があります。
CLIP などの事前トレーニング済みの基礎モデルからの埋め込みを使用すると、いくつかのアプリケーションでゼロショット転送が改善されることが示されています。
これに触発されて、私たちの論文では、事前トレーニング済みの ViT モデルから生成されたグローバル画像事前分布を使用して、より詳細なコンテキスト情報を提供する方法を検討します。
大規模なデータセットで事前トレーニングされた ViT モデルからの埋め込みベクトルは、疑似画像キャプションを生成してから CLIP ベースのテキスト埋め込みを行う通常の方法よりも、SIDE にとってより関連性の高い情報を取得すると主張します。
このアイデアに基づいて、ViT 埋め込みを条件とする拡散バックボーンを使用する新しい SIDE モデルを提案します。
我々の提案する設計は、NYU Depth v2 データセットで SIDE の新しい最先端技術 (SOTA) を確立し、現在の SOTA (VPD) の 0.069 と比較して、Abs Rel 誤差 0.059 (14% の改善) を達成しました。
また、KITTI データセットでは、現在の SOTA (GEDepth) の 0.142 と比較して、SqRel 誤差 0.139 (2% の改善) を達成しました。
NYU Depth v2 でトレーニングされたモデルによるゼロ ショット転送では、(Sun-RGBD、iBims1、DIODE、HyperSim) データセットで NeWCRF に対して (20%、23%、81%、25%) の平均相対改善が報告されています。
これは、ZoEDepth による (16%、18%、45%、9%) と比較して改善されています。
Architecture

Zero-Shot Qualitative Results

DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
Th, Jun 20, 09:00 -- Poster Session 2 & Exhibit Hall
ドラッグベースで画像を編集するDiffusion model。
少し前にDragGANが話題になっていたが、やっぱりDiffusionでもやる人いるよな~という感想。
Poster

Abstract
正確で制御可能な画像編集は、最近大きな注目を集めている困難なタスクです。
特に、Pan ら (2023) によって開発された DragGAN は、ピクセルレベルの精度で印象的な編集結果を実現するインタラクティブなポイントベースの画像編集フレームワークです。ただし、生成的敵対ネットワーク (GAN) に依存しているため、その汎用性は事前トレーニング済みの GAN モデルの容量によって制限されます。
この研究では、この編集フレームワークを拡散モデルに拡張し、新しいアプローチである DragDiffusion を提案します。
大規模な事前トレーニング済みの拡散モデルを利用することで、実際の画像と拡散生成画像の両方に対するインタラクティブなポイントベースの編集の適用性が大幅に向上します。
複数の時間ステップの拡散潜在に関するガイダンスを提供する他の拡散ベースの編集方法とは異なり、私たちのアプローチは、1 つの時間ステップのみの潜在を最適化することで、効率的でありながら正確な空間制御を実現します。
この新しい設計は、特定の時間ステップでの UNet 機能がドラッグベースの編集をサポートするのに十分な意味的および幾何学的情報を提供するという私たちの観察に基づいています。
さらに、元の画像のアイデンティティをさらに保持するために、アイデンティティ保持微調整と参照潜在制御という 2 つの追加手法を導入します。
最後に、インタラクティブなポイントベースの画像編集方法のパフォーマンスを評価する最初のベンチマークである、DragBench と呼ばれる挑戦的なベンチマーク データセットを紹介します。
さまざまな困難なケース (複数のオブジェクト、多様なオブジェクト カテゴリ、さまざまなスタイルなどを含む画像) での実験により、DragDiffusion の汎用性と一般性が実証されます。
コードと DragBench データセットはリリースされます。
Drag Your Noise: Interactive Point-based Editing via Diffusion Semantic Propagation
Project Page
Th, Jun 20, 09:00 -- Poster Session 2 & Exhibit Hall
DragNoiseというDragGANとDragDiffusionの後続と思われるやつ。
DragDiffusionすら今さっき知ったのにもう古いということ??
Poster

Abstract
ポイントベースのインタラクティブ編集は、既存の生成モデルの制御性を補完する重要なツールとして機能します。
同時作業である DragDiffusion は、ユーザー入力に応じて拡散潜在マップを更新し、グローバルな潜在マップの変更を引き起こします。
これにより、元のコンテンツが不正確に保存され、勾配消失により編集が失敗します。
対照的に、潜在マップを再トレースせずに堅牢で高速な編集を提供する DragNoise を紹介します。
DragNoise の中心的な理論的根拠は、各 U-Net の予測ノイズ出力をセマンティック エディターとして利用することにあります。
このアプローチは、2 つの重要な観察に基づいています。第 1 に、U-Net のボトルネック機能は、本質的にインタラクティブ編集に最適なセマンティックが豊富な機能を備えています。
第 2 に、ノイズ除去プロセスの早い段階で確立された高レベルのセマンティクスは、後続のステージでの変化が最小限に抑えられます。
これらの洞察を活用して、DragNoise は単一のノイズ除去ステップで拡散セマンティクスを編集し、これらの変更を効率的に伝播して、拡散編集の安定性と効率性を確保します。
比較実験により、DragNoise は優れた制御と意味保持を実現し、DragDiffusion と比較して最適化時間を 50% 以上短縮することが明らかになりました。
Single Mesh Diffusion Models with Field Latents for Texture Generation
Project Page
Th, Jun 20, 09:00 -- Poster Session 2 & Exhibit Hall
Diffusion modelによる高品質のテクスチャ合成を行う。
Poster

Abstract
我々は、高品質のテクスチャを合成することを目的として、3D 形状の表面で直接動作する固有の潜在拡散モデルのフレームワークを紹介します。
我々のアプローチは、2 つの貢献によって支えられています。
フィールド潜在、つまりテクスチャをメッシュ頂点上の離散ベクトル場としてエンコードする潜在表現、およびフィールド潜在拡散モデルです。
フィールド潜在拡散モデルは、表面上の学習された潜在空間で拡散プロセスのノイズ除去を学習します。
我々は、モデルがメッシュ上に特定のテクスチャのバリエーションを生成するようにトレーニングされる、単一テクスチャメッシュパラダイムを検討します。
我々は、合成されたテクスチャが、既存の単一テクスチャメッシュ生成モデルのものと比較して優れた忠実度であることを示します。
我々のモデルは、インペインティングやラベル誘導生成などのユーザー制御の編集タスクにも適応できます。
我々のアプローチの有効性は、部分的には、等長変換の下での提案フレームワークの等変性によるもので、モデルが局所的に類似した領域全体で詳細をシームレスに再現できるようにし、生成テクスチャ転送の概念への扉を開きます。
Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
Project Page
Th, Jun 20, 02:30 -- Poster Session 1 & Exhibit Hall
教師無し学習により得られたモデルでゼロショットセグメンテーションをStable Diffusionで行う研究。
論文を全く読んでいないためそんなことができるのか何一つ信じてはいないが、できるならすごい!!
Poster

Abstract
画像の高品質なセグメンテーションマスクを生成することは、コンピュータビジョンの基本的な問題です。
最近の研究では、事実上あらゆる画像スタイルでゼロショットセグメンテーションを可能にする大規模な教師ありトレーニングと、密な注釈なしでセグメンテーションを可能にする教師なしトレーニングが検討されています。
しかし、注釈なしでゼロショット方式であらゆるものをセグメンテーションできるモデルを構築することは依然として困難です。
この論文では、安定拡散モデルの自己注意層を利用してこの目標を達成することを提案します。
これは、事前トレーニング済みの安定拡散モデルが注意層内でオブジェクトの固有の概念を学習しているためです。
具体的には、注意マップ間の KL ダイバージェンスを測定してそれらを有効なセグメンテーションマスクにマージすることに基づく、シンプルでありながら効果的な反復マージプロセスを導入します。
提案された方法は、あらゆる画像に対して高品質なセグメンテーションを抽出するために、トレーニングや言語への依存を必要としません。
DiffAssemble: A Unified Graph-Diffusion Model for 2D and 3D Reassembly
Project Page
Sa, Jun 22, 09:00 -- Poster Session 6 & Exhibit Hall
パーツがばらされた状態から元の状態にGraph-Diffusion modelを使用して戻す研究。
2D, 3Dともに同じアプローチをとっている。
Graph-Diffusion modelって何者?
Poster

Abstract
再構成タスクは多くの分野で基本的な役割を果たしており、特定の再構成問題を解決するためのアプローチは複数存在します。
この文脈において、入力データのタイプ(画像、3D など)に関係なく、一般的な統合モデルがこれらすべてに効果的に対処できると仮定します。
拡散モデルの定式化を使用して再構成タスクを解決することを学習するグラフ ニューラル ネットワーク (GNN) ベースのアーキテクチャであるDiffAssemble を紹介します。
私たちの方法は、2D パッチの断片であろうと 3D オブジェクトのフラグメントであろうと、セットの要素を空間グラフのノードとして扱います。
要素の位置と回転にノイズを導入し、反復的にノイズを除去して一貫した初期ポーズを再構築することによってトレーニングが実行されます。
DiffAssembleは、ほとんどの 2D および 3D 再構成タスクで最先端 (SOTA) の結果を達成し、回転と平行移動の両方で 2D パズルを解く最初の学習ベースのアプローチです。
さらに、実行時間が大幅に短縮され、パズルを解くための最速の最適化ベースの方法よりも 11 倍高速に実行されることも強調します。
Segment and Caption Anything
Project Page
Fr, Jun 21, 02:30 -- Poster Session 3 & Exhibit Hall
SAMを拡張してセグメンテーション+キャプショニングを行うSCAを提案。
どこかでしっかり読みたい。
Poster

Abstract
我々は、Segment Anything Model (SAM) に地域キャプションを生成する機能を効率的に装備する方法を提案します。
SAM は、セグメンテーションの強力な一般化機能を提供しますが、意味理解の略です。
軽量のクエリベースの機能ミキサーを導入することで、地域固有の機能を言語モデルの埋め込み空間に合わせ、後でキャプションを生成します。
トレーニング可能なパラメーターの数が少ない (通常は数千万のオーダー) ため、計算コスト、メモリ使用量、通信帯域幅が少なくなり、トレーニングが高速かつスケーラブルになります。
地域キャプション データの不足の問題に対処するために、まずモデルをオブジェクト検出およびセグメンテーション タスクで事前トレーニングすることを提案します。
事前トレーニング データには完全な文章の説明ではなくカテゴリ名のみが含まれているため、このステップを弱い監督の事前トレーニングと呼びます。弱い監督の事前トレーニングにより、公開されている多くのオブジェクト検出およびセグメンテーション データセットを活用できます。
我々は、方法の優位性を実証し、各設計の選択を検証するために、広範な実験を実施しています。
この研究は、地域の字幕データの拡大に向けた足がかりとなり、SAM を地域のセマンティクスで拡張する効率的な方法の探求に光を当てます。
3D Neural Edge Reconstruction
Project Page
Sa, Jun 22, 02:30 -- Poster Session 5 & Exhibit Hall
マルチビュー2Dマップから3Dエッジマップを再構築するEMAPを提案。
このタスク自体初見だったが、こういう業界では需要はあるのかもしれない。

※Project Pageより引用
Abstract
現実世界の物体や環境は、主に直線や曲線などのエッジ特徴で構成されています。
このようなエッジは、CAD モデリング、サーフェス メッシュ、レーン マッピングなどのさまざまなアプリケーションにとって重要な要素です。
しかし、既存の従来の方法では、幾何学的モデリングを簡素化するために、曲線よりも線のみが優先されます。
この目的を達成するために、直線と曲線の両方に焦点を当てた 3D エッジ表現を学習する新しい方法である EMAP を紹介します。
この方法は、マルチビュー エッジ マップから 3D エッジの距離と方向を符号なし距離関数 (UDF) に暗黙的にエンコードします。
このニューラル表現に加えて、推定されたエッジ ポイントとその方向からパラメトリック 3D エッジを堅牢に抽象化するエッジ抽出アルゴリズムを提案します。
包括的な評価により、この方法により、複数の困難なデータセットでより優れた 3D エッジ再構築が達成されることが実証されています。
さらに、学習した UDF フィールドにより、より多くの詳細をキャプチャすることで、ニューラル サーフェス再構築が強化されることも示しています。
Multiple View Geometry Transformers for 3D Human Pose Estimation
Th, Jun 20, 02:30 -- Poster Session 1 & Exhibit Hall
Abstract以外の情報はまだ出ていないが、幾何学ベースのモジュールをTransformerに導入して画像から姿勢推定精度の向上を図ったMVGFormerを提案。
興味深い。
Abstract
本研究では、マルチビュー 3D 人間のポーズ推定におけるトランスフォーマーの 3D 推論能力の向上を目指します。
最近の研究では、エンドツーエンドの学習ベースのトランスフォーマー設計に焦点が当てられてきましたが、特にオクルージョン時に、幾何学情報を正確に解決するのが困難です。
代わりに、一連の幾何学モジュールと外観モジュールが反復的に編成された新しいハイブリッド モデル MVGFormer を提案します。
幾何学モジュールは学習不要で、すべての視点依存の 3D タスクを幾何学的に処理するため、モデルの一般化能力が大幅に向上します。
外観モジュールは学習可能で、エンドツーエンドで画像信号から 2D ポーズを推定することに専念しているため、オクルージョンが発生した場合でも正確な推定値を達成でき、新しいカメラやジオメトリに対して正確かつ一般化可能なモデルになります。
ドメイン内とドメイン外の両方の設定でアプローチを評価しましたが、モデルは一貫して最先端の方法よりも優れており、特にドメイン外の設定では大幅に優れています。
コードとモデルは https://github.com/XunshanMan/MVGFormer で公開します。
まとめ
事前に調べているとモチベーション上がってきたので楽しみです。
発表者だけでなく参加者同士でも雑談できる何かがあると嬉しいけどどうなんだろうか…。
とりあえず荷造り頑張ります。