はじめに
いい加減なタイトルにも関わらずこのページを開いてくださりありがとうございます!!
皆さんはネット上の散らばった画像を集めて1つのファイルにいい感じに並べたいと思ったことはありますでしょうか?
私は並べたいと思ってしまったので今この記事を書いております。
私の場合は各種天気図を1つのファイルにまとめたいと思いました。。。(専門天気図って画像が分かれていて全部開いたりするの面倒なんですよね。。。)
やりたいこと
- 散らばったネット上の画像を1つのファイルにまとめる
- レイアウトはいい感じにしたい
- 用紙サイズはA4が良い(印刷したいため)
- PDFで出力したい
作戦
使用する天気図
各種天気図は北海道放送「予想にチャレンジ!専門天気図」のホームページから拝借します。
このページは以下のように各種天気図が羅列してありアクセスしやすくなっており便利です。
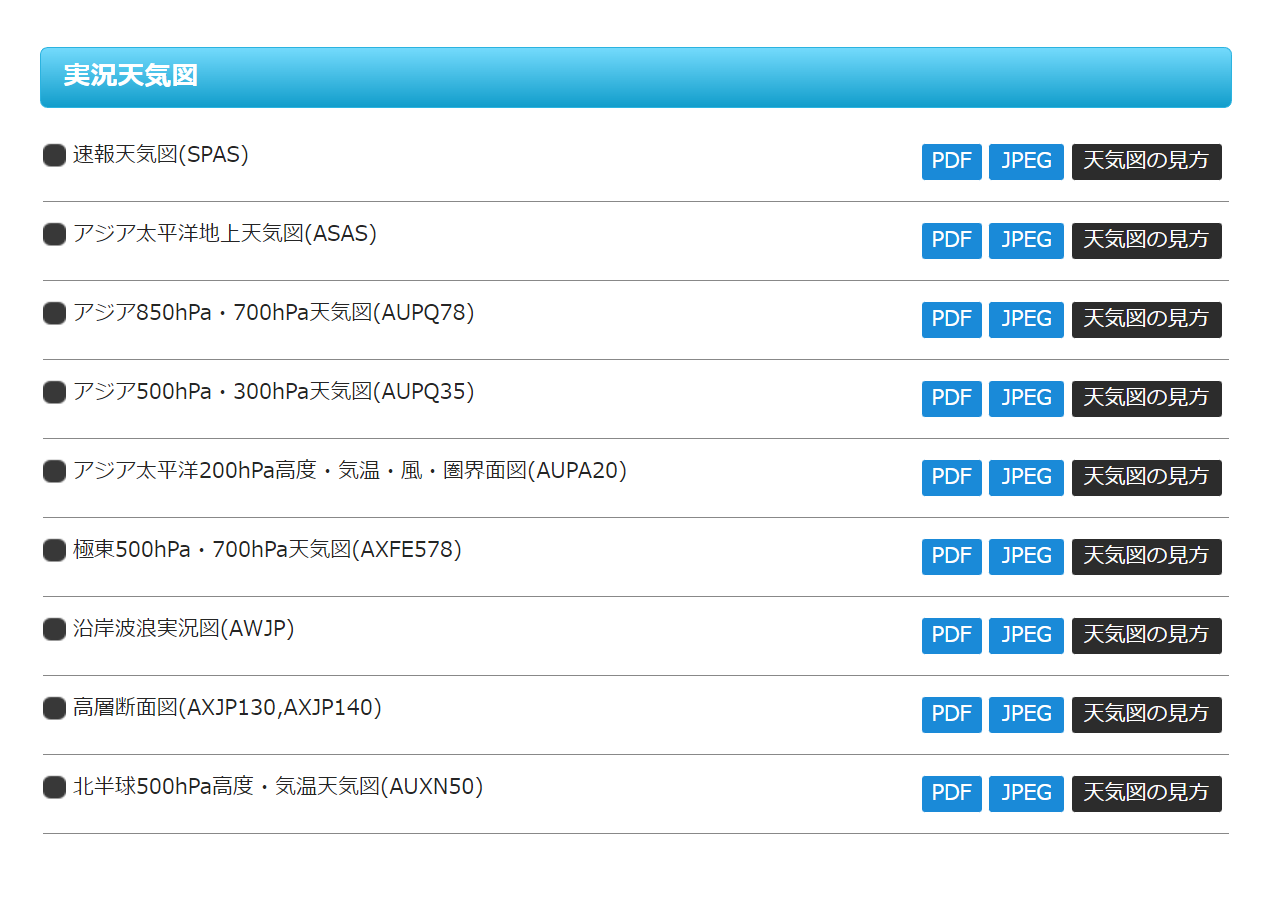
今回は以下の天気図たちをまとめます。
速報天気図(SPAS)
https://www.hbc.co.jp/tecweather/SPAS.jpg

アジア太平洋地上天気図(ASAS)
https://www.hbc.co.jp/tecweather/ASAS.jpg
日本850hPa風・相当温位12・24・36・48時間予想図(FXJP854)
https://www.hbc.co.jp/tecweather/FXJP854.jpg

アジア850hPa・700hPa天気図(AUPQ78)
https://www.hbc.co.jp/tecweather/AUPQ78.jpg
アジア500hPa・300hPa天気図(AUPQ35)
https://www.hbc.co.jp/tecweather/AUPQ35.jpg
500hPa高度・渦度+極東地上気圧・降水量・海上風
12・24時間予想図(FXFE502)
https://www.hbc.co.jp/tecweather/FXFE502.jpg

極東850hPa気温・風、700hPa上昇流+極東500hPa気温、
700hPa湿数12・24時間予想図(FXFE5782)
https://www.hbc.co.jp/tecweather/FXFE5782.jpg

使用言語
今回はPythonでやります。
使用する主なライブラリは以下の通りです。
- opencv
- python-opencv-utils
- matplotlib
実装
では順に実装していきます。
import, setting
import cv2
import cv2u # urlから画像を読み込むために使用
import datetime # いつのファイル、天気図かがわかるようにするため
import matplotlib.pyplot as plt
from matplotlib.backends.backend_pdf import PdfPages
# matplotlibでの日本語の文字化け(豆腐)を回避するための設定
plt.rcParams['font.family'] = 'MS Gothic'
date = datetime.date.today()
height, width = 8.27, 11.69 # matplotlibのfigureのサイズ、A4縦だとこのサイズらしい
使用する画像周りの設定
# 使用する画像を「タイトル:url」のdictで保持
dict_urls = {
"速報天気図(SPAS)": "https://www.hbc.co.jp/tecweather/SPAS.jpg",
"アジア太平洋地上天気図(ASAS)": "https://www.hbc.co.jp/tecweather/ASAS.jpg",
"日本850hPa風・相当温位12・24・36・48時間予想図(FXJP854)": "https://www.hbc.co.jp/tecweather/FXJP854.jpg",
"アジア850hPa・700hPa天気図(AUPQ78)": "https://www.hbc.co.jp/tecweather/AUPQ78.jpg",
"アジア500hPa・300hPa天気図(AUPQ35)": "https://www.hbc.co.jp/tecweather/AUPQ35.jpg",
"500hPa高度・渦度+極東地上気圧・降水量・海上風 \n12・24時間予想図(FXFE502)": "https://www.hbc.co.jp/tecweather/FXFE502.jpg",
"極東850hPa気温・風、700hPa上昇流+極東500hPa気温、\n700hPa湿数12・24時間予想図(FXFE5782)": "https://www.hbc.co.jp/tecweather/FXFE5782.jpg",
}
# matplotlibのsubplotでの各画像の位置
pos = [421, 422, 412, 223, 224, 211, 212]
# 改ページを行うindex(指定した場所から新しいページになる)
i_reset_page = [0, 5]
# 画像の上半分を使う場合のflg(下半分はいらない画像があったので。。。)
half = [False, False, True, False, False, False, False]
# 画像数(なくてもよい。。。)
n = len(dict_urls)
3桁のintの意味
3桁のint(仮に $ijk$ とあらわされるとする)は左から順に各桁が
figureを $i$ 行 $j$ 列のグリッドに分割したときの $k$ 番目のグリッドを指定する!という意味になります。
※具体的な位置に関しては下の方の「plt.subplotの補足」で少し触れています。
処理本体
def main():
# pdf書き出し用のobject生成、ファイル名は「日付.pdf」
pp = PdfPages(f"{date}.pdf")
# 現在のページ数(スタートは1ページ目、出力用)
i_page = 1
for i, (k, v) in enumerate(dict_urls.items()):
if i in i_reset_page:
# figureの初期化
fig = plt.figure(figsize=(height, width))
plt.suptitle(f"{date} ({i_page}/{len(i_reset_page)})")
i_page += 1
# 画像をurlから取得
img = cv2u.urlread(v)
# pos[i]に画像、タイトルの表示
plt.subplot(pos[i])
plt.title(k)
# 画像は白黒画像なのでimshow字にRGBに変換している
if half[i]: plt.imshow(cv2.cvtColor(img[:len(img)//2], cv2.COLOR_GRAY2RGB))
else: plt.imshow(cv2.cvtColor(img, cv2.COLOR_GRAY2RGB))
plt.axis("off") # 目盛りはいらない
# 各ページの最後の画像をimshowしたらファイルにページを書き出す
if i+1 in i_reset_page or i+1==n: pp.savefig(fig)
pp.close()
plt.subplotの補足
ざっくりとした補足です。
plt.subplotに渡すposですが
3桁のint(例:plt.subplot(111))かintを3つ並べたもの(例:plt.subplot(1, 1, 1))になります。
今回は前者の方法を使用しております。
例として、423で指定した場合は以下の図の③の箇所に画像を書くことになります。

また、同じfigure内で違う大きさで画像を貼りたい(例えば、上の図の③④の位置に張りたい)場合には、plt.subplot(412)と指定すればよいです。
412と場所を指定することで以下の図のようになるため、先ほどの4行2列の箇所の③④部分に画像を貼ることができます。

これを踏まえて、
# 4行2列の図の①に貼り付け
plt.subplot(421)
plt.imshow(im1)
# 4行2列の図の②に貼り付け
plt.subplot(422)
plt.imshow(im2)
# 4行1列の図の②に貼り付け
plt.subplot(412)
plt.imshow(im3)
とすることで、サイズの違う大きさで画像を複数並べることができます。
処理結果
以下のようになりました。
記事用にpngで出力していますが、2ページのpdfで両面印刷すると1枚になるため満足です。
使用した北海道放送さんのホームページは毎日同じurlでも最新の天気図に更新されるので、今回のコードを使いまわすことで最新の情報がまとまって得られるため手間が省けると感じます。(私と同じことをやりたい人はあまりいないと思いますが。。。)

まとめ
今回はネット上に散らばっている画像を1ファイルにまとめてpdf出力するということをやりました。
opencv-utilsにurlreadがあったり、matplotlibにpdf出力用のPdfPagesがあったりと知らなかったけど便利な機能を見つけることもできて良かったです。
おまけ:全体のコード
import cv2
import cv2u
import datetime
import matplotlib.pyplot as plt
from matplotlib.backends.backend_pdf import PdfPages
plt.rcParams['font.family'] = 'MS Gothic'
date = datetime.date.today()
height, width = 8.27, 11.69
dict_urls = {
"速報天気図(SPAS)": "https://www.hbc.co.jp/tecweather/SPAS.jpg",
"アジア太平洋地上天気図(ASAS)": "https://www.hbc.co.jp/tecweather/ASAS.jpg",
"日本850hPa風・相当温位12・24・36・48時間予想図(FXJP854)": "https://www.hbc.co.jp/tecweather/FXJP854.jpg",
"アジア850hPa・700hPa天気図(AUPQ78)": "https://www.hbc.co.jp/tecweather/AUPQ78.jpg",
"アジア500hPa・300hPa天気図(AUPQ35)": "https://www.hbc.co.jp/tecweather/AUPQ35.jpg",
"500hPa高度・渦度+極東地上気圧・降水量・海上風 \n12・24時間予想図(FXFE502)": "https://www.hbc.co.jp/tecweather/FXFE502.jpg",
"極東850hPa気温・風、700hPa上昇流+極東500hPa気温、\n700hPa湿数12・24時間予想図(FXFE5782)": "https://www.hbc.co.jp/tecweather/FXFE5782.jpg",
}
pos = [421, 422, 412, 223, 224, 211, 212]
i_reset_page = [0, 5]
half = [False, False, True, False, False, False, False]
n = len(dict_urls)
def main():
pp = PdfPages(f"{date}.pdf")
i_page = 1
for i, (k, v) in enumerate(dict_urls.items()):
if i in i_reset_page:
fig = plt.figure(figsize=(height, width))
plt.suptitle(f"{date} ({i_page}/{len(i_reset_page)})")
i_page += 1
img = cv2u.urlread(v)
plt.subplot(pos[i])
plt.title(k)
if half[i]: plt.imshow(cv2.cvtColor(img[:len(img)//2], cv2.COLOR_GRAY2RGB))
else: plt.imshow(cv2.cvtColor(img, cv2.COLOR_GRAY2RGB))
plt.axis("off")
if i+1 in i_reset_page or i+1==n: pp.savefig(fig)
pp.close()
if __name__ == "__main__":
main()