はじめに
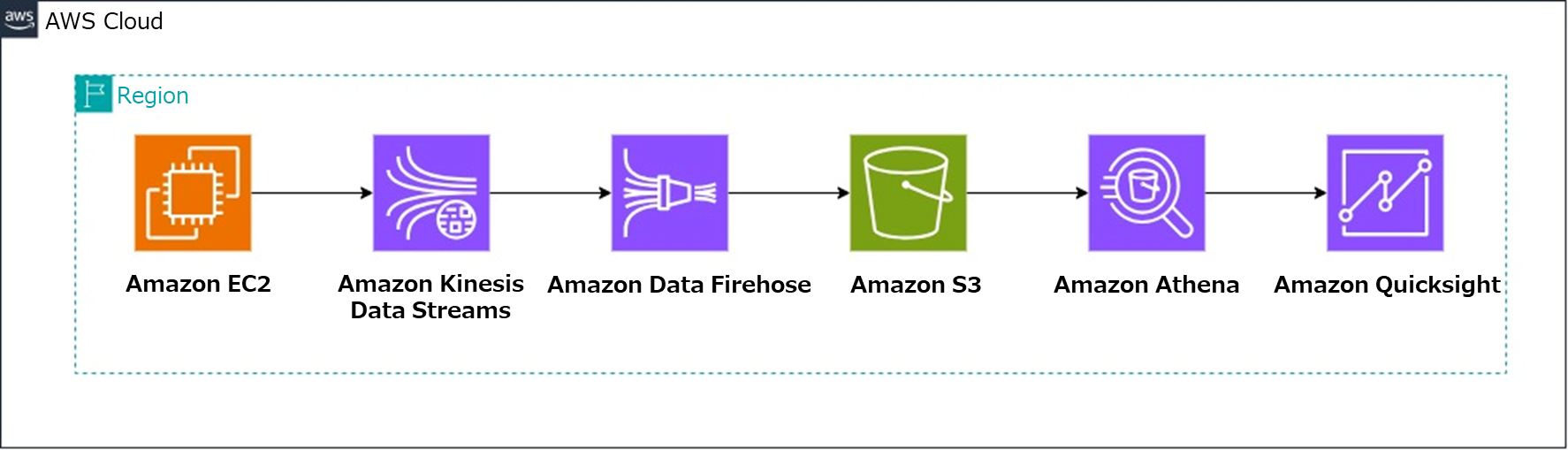
AWS認定試験の勉強をしていると、何回も何十回も出てくるこの構成...笑
しかし、「実際どう動いてるねん!?」というものを理解するために、構築しました。
ECサイト利用時の疑似ログを活用したハンズオンになります。ぜひ、頭の中のイメージだけでなく、手を動かして理解を深めてみてください。
環境構築
STEP 1: データソースの準備 (Amazon EC2)
まず、ログデータを生成するためのEC2インスタンスをセットアップします。
-
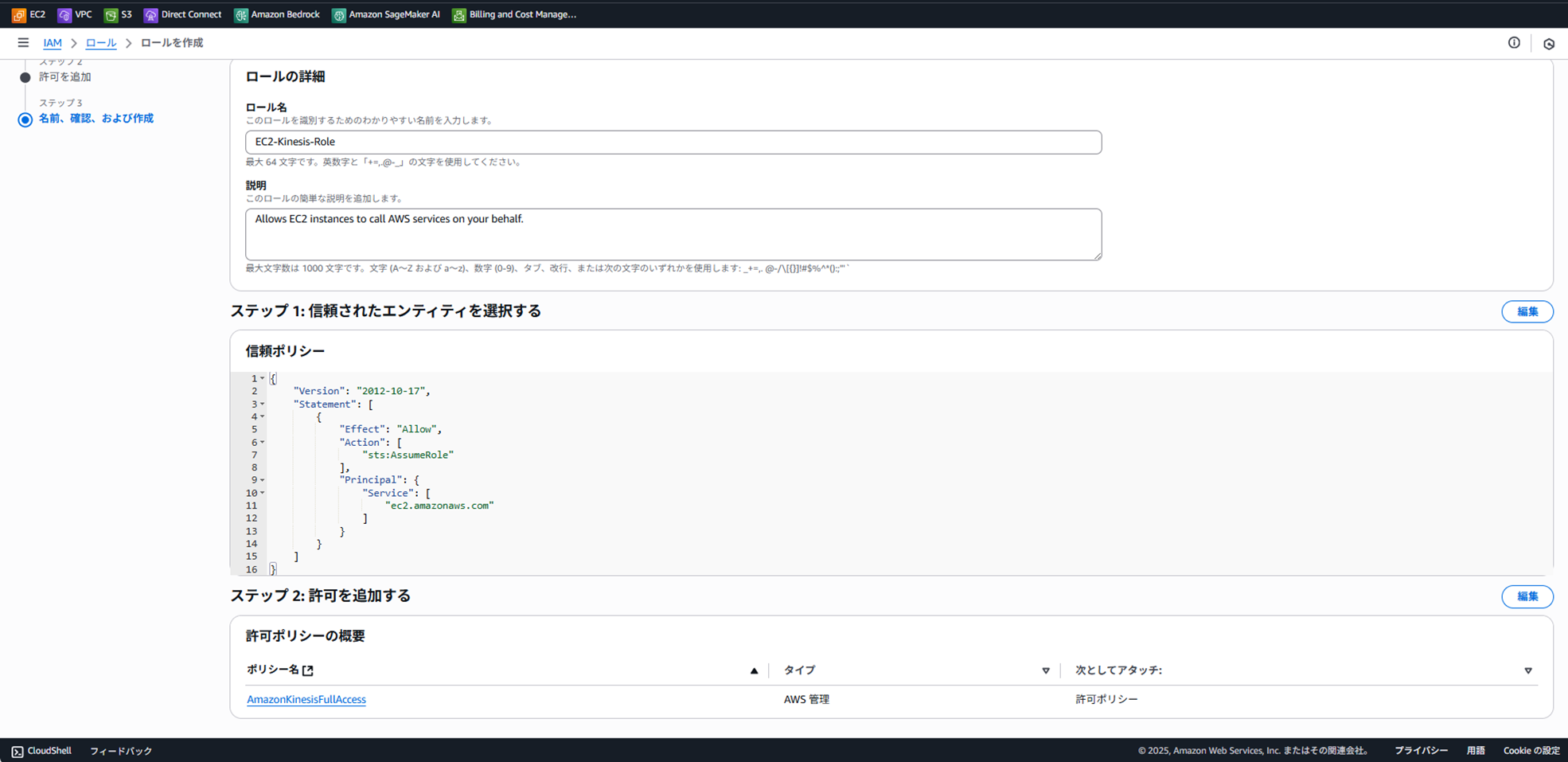
IAMロールの作成: EC2インスタンスがKinesisにデータを送信できるよう、IAMロールを作成します。
IAMコンソール > ロール > ロールを作成 を選択。
信頼されたエンティティタイプ: AWSのサービス
ユースケース: EC2 を選択し、「次へ」。
許可ポリシー: AmazonKinesisFullAccess を検索してチェックし、「次へ」。
ロール名: EC2-Kinesis-Role などと入力し、ロールを作成します。
-
EC2インスタンスの起動:
EC2コンソール > インスタンスを起動 を選択。
名前: handson-EC2 などと入力。
Amazonマシンイメージ: Amazon Linux 2023 AMI (無料利用枠対象) を選択。
インスタンスタイプ: t3.micro (無料利用枠対象) を選択。
キーペア: 既存のものを使用するか、新しく作成します。
ネットワーク設定: 編集 をクリックし、SSHトラフィックを許可 のソースを マイIP に設定します。
高度な詳細 > IAMインスタンスプロファイル: 先ほど作成した EC2-Kinesis-Role を選択します。
インスタンスを起動 をクリックします。
- データ生成スクリプトの実行:
SSHクライアントでEC2インスタンスに接続します。
(よくわからない場合は、以下参照)
boto3 (AWS SDK for Python) をインストールします。
sudo yum update -y
sudo yum install python3 python3-pip -y
pip3 install boto3
データ生成スクリプト として、producer.py を作成します。
これは、ハンズオン学習用にECサイトのユーザー行動ログを以下の4種類からランダムに疑似的に生成します。
・login: ユーザーのログイン
・view_item: 商品ページの閲覧
・add_to_cart: カートへの商品追加
・purchase: 商品の購入
nano producer.py
以下のコードを貼り付けて保存します。(your-stream-name と your-region は後ほど作成するKinesisストリームの情報に合わせて変更します)
import boto3
import json
import random
import datetime
import time
# ▼▼▼ **STEP2で必要になります** ▼▼▼
STREAM_NAME = "handson-data-stream" # Kinesis Data Streamのストリーム名
REGION_NAME = "ap-northeast-1" # リージョン名
# ▲▲▲ *********************** ▲▲▲
kinesis_client = boto3.client('kinesis', region_name=REGION_NAME)
def generate_data():
event_types = ['login', 'view_item', 'add_to_cart', 'purchase']
return {
'user_id': random.randint(1000, 2000),
'event_type': random.choice(event_types),
'product_id': random.randint(1, 100) if 'view' in event_types[-1] else None,
'timestamp': datetime.datetime.utcnow().isoformat()
}
print(f"Sending data to Kinesis Stream: {STREAM_NAME}")
while True:
data = generate_data()
partition_key = str(data['user_id'])
try:
kinesis_client.put_record(
StreamName=STREAM_NAME,
Data=json.dumps(data),
PartitionKey=partition_key
)
print(f"Successfully sent: {json.dumps(data)}")
except Exception as e:
print(f"Error: {e}")
time.sleep(random.uniform(0.5, 2.0)) # 0.5秒から2秒のランダムな間隔で送信
nanoやvimエディタの使い方がわからない場合は、以下記事をご覧ください。
このスクリプトはまだ実行しないでください。 次のステップでKinesisストリームを作成した後に実行します。
STEP 2: ストリーミングデータ収集 (Kinesis)
- Kinesis Data Streamの作成:
Kinesisコンソール > データストリーム > データストリームを作成 を選択。
データストリーム名: handson-data-stream (EC2スクリプトで指定したもの) を入力。
キャパシティーモード: オンデマンド を選択し、データストリームを作成 をクリックします。

- EC2でスクリプトを実行:
Data Streamが アクティブ になったら、EC2にSSH接続しているターミナルで producer.py を実行します。
python3 producer.py
データが正常に送信されていることを確認します。

-
Kinesis Data Firehoseの作成:(これがないとS3に配信できない)
Kinesisコンソール > 配信ストリーム > 配信ストリームを作成 を選択。
ソース: Amazon Kinesis Data Streams を選択。
送信先: Amazon S3 を選択。
ソース設定 > Kinesis data stream: 先ほど作成した handson-data-stream を選択。
配信ストリーム名: handson-firehose-s3 などと入力。 -
送信先の設定:
S3バケット: 参照 をクリックし、バケットを作成 を選択。ユニークなバケット名(例: handson-datalake-yyyymmdd-yourname)を入力し、作成します。作成したバケットを選択します。
S3バケットプレフィックス: data/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/
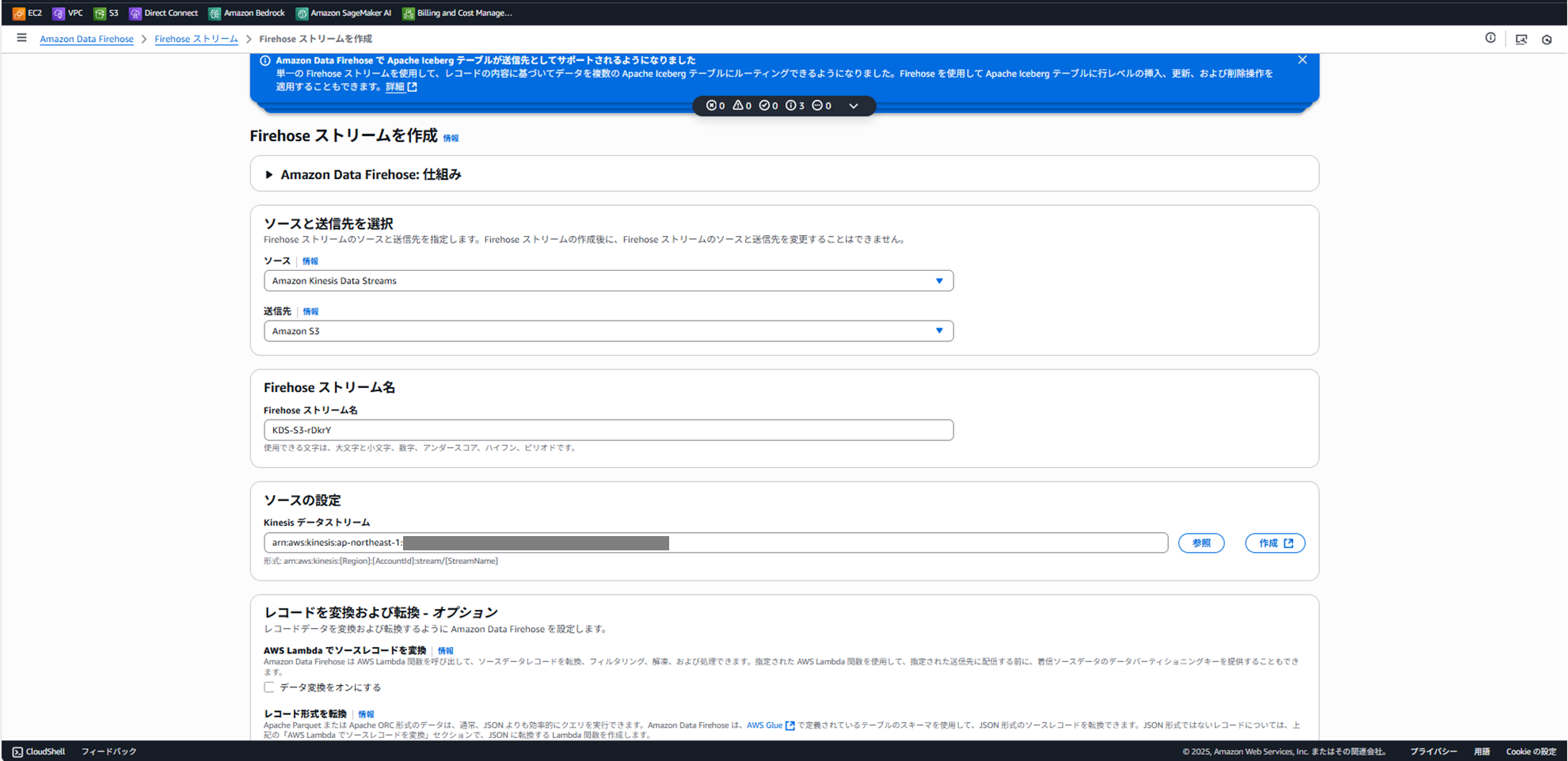
重要: このプレフィックスにより、データが日付/時間ベースでパーティション分割され、後のAthenaでのクエリ効率が大幅に向上します。
S3バケットエラー出力プレフィックス: error/
バッファヒント: バッファ間隔 を 60 秒に設定します(最小値)。これにより、約60秒ごとにS3にファイルが書き出されます。
その他の設定はデフォルトのまま 配信ストリームを作成 をクリックします。
STEP 3: データレイクの確認 (Amazon S3)
数分待ってから、作成したS3バケットを確認します。
data/year=2025/month=07/... のようなフォルダ構造が作成され、中にGZIP圧縮されたデータファイルが格納されていることを確認します。
STEP 4: データカタログの作成 (AWS Glue)
-
Glueデータベースの作成:
Glueコンソール > データベース > データベースの追加 を選択。
データベース名: handson_db と入力し、作成します。
Glueクローラの作成:
Glueコンソール > クローラ > クローラの作成 を選択。
クローラ名: handson-s3-crawler などと入力。
データソース: S3 を選択し、先ほど作成したS3バケットの data フォルダ (s3://handson-datalake-xxxx/data/) を指定します。
IAMロール: 新しいIAMロールを作成 を選択し、ロール名を入力して作成します。
ターゲットデータベース: 作成した handson_db を選択します。
スケジュール: オンデマンドで実行 を選択します。
クローラを作成 をクリックし、作成後に クローラを実行 をクリックします。

-
テーブルの確認:
クローラの実行が完了(数分かかります)したら、Glueコンソールの テーブル を確認します。

data というテーブルが作成され、スキーマ(列情報)とパーティション情報(year, month, day, hour)が自動で認識されていることを確認します。
STEP 5: データのクエリ (Amazon Athena)
Athenaクエリエディタのセットアップ:
初めてAthenaを使用する場合、クエリ結果を保存するS3の場所を設定する必要があります。
Athenaコンソール > 設定 > 管理 から、クエリ結果用のS3ロケーション(例: s3://your-athena-query-results-bucket/)を指定します。
クエリの実行:
Athenaクエリエディタを開きます。
データソース: AwsDataCatalog
データベース: handson_db
テーブルに data が表示されているはずです。
以下のクエリを実行して、データが正しく読み取れるか確認します。FirehoseからのデータはBase64でエンコードされているため、デコードが必要です。
SELECT
user_id,
event_type,
product_id,
"timestamp"
FROM "data"
LIMIT 10;
次に、JSON形式のデータをパースして、各要素を列として抽出します。
SELECT
user_id,
event_type,
product_id,
"timestamp" AS event_time -- カラム名を分かりやすくするために別名(AS)をつけています
FROM "data"
-- パーティションを指定してスキャン範囲を限定すると高速かつ安価になります
WHERE year = '2025' AND month = '07'
LIMIT 100;
クエリ実行後、下記画像のように検索結果が表示されていればOKです。

STEP 6: データの可視化 (Amazon QuickSight)
QuickSightのセットアップ:
初めて利用する場合は、QuickSightのアカウント登録が必要です。
QuickSightがAthenaとS3にアクセスできるよう、アクセス許可を設定します。QuickSightの管理(画面右上 人型アイコン内) > セキュリティとアクセス権限 > QuickSightのAWSサービスへのアクセス から Amazon Athena と Amazon S3 にチェックを入れ、S3バケットを選択します。

データセットの作成:
QuickSightのメイン画面 > 新しい分析(右上) > 新しいデータセット を選択。
Athena を選択します。
データソース名: handson-athena などと入力し、データソースを作成 をクリック。
テーブルの選択: handson_db の data テーブルを選択し、編集/プレビュー をクリック。
完了 をクリックし、SPICEにインポート(インメモリデータベースで高速)を選択して Visualize をクリックします。
分析とダッシュボードの作成:
分析画面で、ビジュアルを作成します。
例1: イベントタイプ別件数(円グラフ)
ビジュアルタイプ: 円グラフ
グループ/色: event_type
例2: 時間帯別ユーザーのアクション数(棒グラフ)
ビジュアルタイプ: 折れ線グラフ
X軸: hour(時間軸)
値: event_type(カウントとして集計)
色: event_type(アクション別に色分け)
画面右上の 共有 > ダッシュボードを公開 をクリックして、これでダッシュボードの完成です!お疲れ様でした!

STEP 7:片付け
ハンズオン終了後は、不要な課金を避けるために作成したリソースを削除してください。
EC2インスタンスの終了
Kinesis Data Firehoseの削除
Kinesis Data Streamの削除
S3バケットの空にして削除
Glueクローラ、データベース、テーブルの削除
QuickSightのデータセットと分析の削除
IAMロールの削除
最後に
元データが自作Pythonスクリプトによるものなのでダッシュボードによる可視化があまりおもしろくありませんが、応用編としてfruentdを使ってみても良いかと思います。