4.1 Back to the Basics
Assignment
代入はプログラムにおいて最も重要な概念の一つである。
しかし、これには驚くべき点がいくつかある!!
>>> foo = 'Monty'
>>> bar = foo # (1)
>>> foo = 'Python' # (2)
>>> bar
'Monty'
上記のコードで、bar=fooと書くと (1) のfooの値(文字列'Monty')がbarに割り当てられる。つまり、barはfooのコピーなので、(2)行目でfooを新しい文字列'Python'で上書きしても、barの値は影響を受けない。
代入は式の値をコピーするが、値は常に期待されるものとは限らない!!!
特に、リストなどの構造化オブジェクトの値は、実際にはオブジェクトの単なる参照に過ぎない!
次の例で(1)はfooの参照を変数barに割り当てている。次の行でfoo内を変更するとbarの値も変更されている
>>> foo = ['Monty', 'Python']
>>> bar = foo # (1)
>>> foo[1] = 'Bodkin' # (2)
>>> bar
['Monty', 'Bodkin']
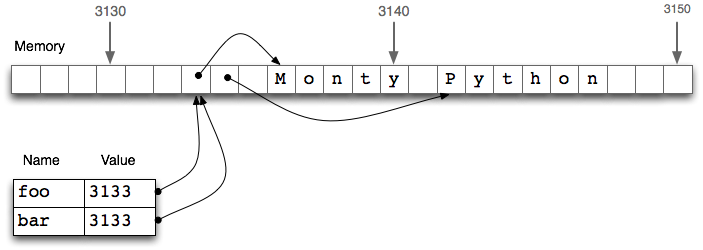
bar=fooは変数の内容をコピーしているのではなく、そのオブジェクト参照のみをコピーしている!!
これは、fooの位置3133に格納されたオブジェクトへの参照である。
bar = fooを割り当てると、コピーされるのはオブジェクト参照3133だけのため、fooを更新するとbarも変更されるということ!
空のリストを保持する変数emptyを作成し、次の行でそれを3回使用して、さらに実験してみよう。
>>> empty = []
>>> nested = [empty, empty, empty]
>>> nested
[[], [], []]
>>> nested[1].append('Python')
>>> nested
[['Python'], ['Python'], ['Python']]
リスト内の項目の1つを変更すると、それらすべてが変更された!!??
これは、3つの要素のそれぞれが実際にはメモリ内の1つの同じリストへの単なる参照であるのがわかるね!!
ここで、リストの要素の1つに新しい値を割り当てた場合、他の要素には反映されないことに注意して!
>>> nested = [[]] * 3
>>> nested[1].append('Python')
>>> nested[1] = ['Monty']
>>> nested
[['Python'], ['Monty'], ['Python']]
3行目ではリスト内の3つのオブジェクト参照の1つを変更した。しかし、'Python'オブジェクトは変更されていない。これはオブジェクト参照を介してオブジェクトを変更しているためであり、オブジェクト参照を上書きしているわけではないからね!
Equality
Pythonは、アイテムのペアが同じであることを確認する2つの方法がある。
isオブジェクト識別のための演算子をテストする。これを使用して、オブジェクトに関する以前の観察結果を検証できる。
>>> size = 5
>>> python = ['Python']
>>> snake_nest = [python] * size
>>> snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4]
True
>>> snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4]
True
同じオブジェクトの複数のコピーを含むリストを作成し、それらが==に従って同一であるだけでなく、1つの同じオブジェクトであることも示す。
>>> import random
>>> position = random.choice(range(size))
>>> snake_nest[position] = ['Python']
>>> snake_nest
[['Python'], ['Python'], ['Python'], ['Python'], ['Python']]
>>> snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4]
True
>>> snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4]
False
id()関数を使用すると検出が容易になる!
>>> [id(snake) for snake in snake_nest]
[513528, 533168, 513528, 513528, 513528]
これにより、リストの2番目の項目に個別の識別子が含まれていることがわかる!
Conditionals
ifステートメントの条件部分では、空でない文字列またはリストはtrueと評価され、空の文字列またはリストはfalseと評価される。
>>> mixed = ['cat', '', ['dog'], []]
>>> for element in mixed:
... if element:
... print element
...
cat
['dog']
つまり条件で if len(element)> 0: をする必要がない。
>>> animals = ['cat', 'dog']
>>> if 'cat' in animals:
... print 1
... elif 'dog' in animals:
... print 2
...
1
elifをifに置き換えた場合、1と2の両方を出力する。よって、elif句はif句よりより多くの情報をい持っている可能性がある。
4.2 Sequences
このシーケンスはtupleとよばれ、コンマ演算子で形成され、括弧で囲まれる。
また、文字列と同じようにインデックスを付けることによって指定の箇所を見ることができる。
>>> t = 'walk', 'fem', 3
>>> t
('walk', 'fem', 3)
>>> t[0]
'walk'
>>> t[1:]
('fem', 3)
>>> len(t)
3
文字列、リスト、タプルを直接比較し、各タイプでインデックス作成、スライス、長さの操作をしてみた!
>>> raw = 'I turned off the spectroroute'
>>> text = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> pair = (6, 'turned')
>>> raw[2], text[3], pair[1]
('t', 'the', 'turned')
>>> raw[-3:], text[-3:], pair[-3:]
('ute', ['off', 'the', 'spectroroute'], (6, 'turned'))
>>> len(raw), len(text), len(pair)
(29, 5, 2)
Operating on Sequence Types
シーケンスを反復処理するさまざまな方法

sの一意の要素を逆順にソートするには、reverse(sorted(set(s)))を使用する。random.shuffle(s)を使用して、反復する前にリストsの内容をランダム化できる。
FreqDistは、シーケンスに変換することができる!
>>> raw = 'Red lorry, yellow lorry, red lorry, yellow lorry.'
>>> text = word_tokenize(raw)
>>> fdist = nltk.FreqDist(text)
>>> sorted(fdist)
[',', '.', 'Red', 'lorry', 'red', 'yellow']
>>> for key in fdist:
... print(key + ':', fdist[key], end='; ')
...
lorry: 4; red: 1; .: 1; ,: 3; Red: 1; yellow: 2
タプルを使用してリストのコンテンツを再配置!!
>>> words = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> words[2], words[3], words[4] = words[3], words[4], words[2]
>>> words
['I', 'turned', 'the', 'spectroroute', 'off']
zip()は2つ以上のシーケンスのアイテムを取得し、それらをまとめて1つのタプルのリストに「圧縮」する!
シーケンスsが与えられると、enumerate(s)は、インデックスとそのインデックスにあるアイテムで構成されるペアを返す。
>>> words = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> tags = ['noun', 'verb', 'prep', 'det', 'noun']
>>> zip(words, tags)
<zip object at ...>
>>> list(zip(words, tags))
[('I', 'noun'), ('turned', 'verb'), ('off', 'prep'),
('the', 'det'), ('spectroroute', 'noun')]
>>> list(enumerate(words))
[(0, 'I'), (1, 'turned'), (2, 'off'), (3, 'the'), (4, 'spectroroute')]
Combining Different Sequence Types
>>> words = 'I turned off the spectroroute'.split() # (1)
>>> wordlens = [(len(word), word) for word in words] # (2)
>>> wordlens.sort() # (3)
>>> ' '.join(w for (_, w) in wordlens) # (4)
'I off the turned spectroroute'
文字列は、実際にはsplit()などのメソッドが定義されたオブジェクトである。(2)でリスト内包表記を使用してタプルのリストを作成。各タプルは数字(単語の長さ)と単語で構成されます(例:(3、'the'))。sort()メソッドを使用して(3)リストをその場でソート!
最後に、(4)で長さ情報を破棄し、単語を結合して1つの文字列に戻す。
Pythonでは、リストは可変であり、タプルは不変。つまり、リストは変更できますが、タプルは変更できない!!!
Generator Expressions
>>> text = '''"When I use a word," Humpty Dumpty said in rather a scornful tone,
... "it means just what I choose it to mean - neither more nor less."'''
>>> [w.lower() for w in word_tokenize(text)]
['``', 'when', 'i', 'use', 'a', 'word', ',', "''", 'humpty', 'dumpty', 'said', ...]
これらの単語をさらに処理したい。
>>> max([w.lower() for w in word_tokenize(text)]) # (1)
'word'
>>> max(w.lower() for w in word_tokenize(text)) # (2)
'word'