動機
研究室配属された後輩に向けて、環境構築+実装の基本をまとめておこうと思った
目標
plant-disease-recognition-datasetをCNNで分類するための環境構築&データダウンロード。
- 環境構築後の実装は、Luís Fernando Torresの記事を行うことを想定
前提
- 研究室サーバーを使う
- 研究室サーバーは研究に必要なソフトがインストールされている
- SSH接続はできている状態
- VScodeの基本設定は終わっている状態
- 基本的なLinuxコマンドやPythonコードは自身で調べながら理解できる
ディレクトリ構造の例
project/
├── kaggle/input/plant-disease-recognition-dataset/ # KaggleからDLしたデータ
│ └── Test/
│ └── Train/
│ └── Validation/
├── venv/ # 仮想環境を使う場合
├── requirements.txt
├── compose.yml # Dockerを使う場合
├── Dockerfile # Dockerを使う場合
└── script.py # など実装ファイル
実際には、好みに合わせて配置を調整すると良い。
requirements.txt
以下は参考例。GPU を使うなら TensorFlow GPU を指定したり、Anaconda なら conda install コマンドでも良い。
必要に応じて公式のインストール方法を参照しながら修正してほしい。
tensorflow==2.11.0
numpy
matplotlib
pandas
scikit-learn
kaggle
メモ:
- ローカル環境やサーバに CUDA と cuDNN がインストールされている場合は、tensorflow-gpu==2.11.0 を指定するとGPU対応版がインストールされる
- Docker を使う場合は、ベースイメージとして tensorflow/tensorflow:2.11.0-gpu を使用すれば、基本的に GPU 対応がセットアップ済みになる
環境構築
環境構築には様々な流派がある。好みの方法を使えばOK!下記に代表的な方法をざっくりまとめた。
どんなやり方があるか全体的に俯瞰したいときは、こちらの記事がおすすめ。
1. venvを用いた環境構築
Python には標準で仮想環境を作るモジュール venv が用意されている。
シンプルに仮想環境を分けたいだけなら、これが最も手軽。
1. プロジェクトディレクトリへ移動する
cd project-dir
2.python3 -m venv venv で仮想環境を作成
python3 -m venv my_venv
3.仮想環境を有効化する
# bash/zsh向け
source venv/bin/activate
4. pip install --upgrade pip などで pip を最新にしておく(任意)
5. pip install -r requirements.txt で必要なライブラリをインストール
6. 作業が終わったら deactivate で仮想環境を抜ける
pyenvを用いた環境構築
pyenvは、複数のPythonバージョンを切り替えながら仮想環境も管理できる便利なツールである。システム全体のPythonに影響を与えることなく、プロジェクトごとに異なるバージョンを使用できる。
1. pyenvのインストール
Linuxにインストールするには、pyenvのGitHubを参照。
2. Pythonのインストール
任意のPythonバージョンをインストールできる。
# インストールされているバージョンの確認
pyenv install --list
# 特定のバージョンをインストール
pyenv install 3.9.7
3. プロジェクトディレクトリへ移動する
cd project-dir
4. プロジェクトのPythonバージョン設定
プロジェクトディレクトリで特定のPythonバージョンを使用するように設定する。
cd project-dir
pyenv local 3.9.7
これにより.python-versionファイルが作成され、そのディレクトリ以下では指定したバージョンが使用される。
5. 仮想環境の作成と管理
pyenv-virtualenvプラグインを使用して仮想環境を管理できる。
# 仮想環境の作成
pyenv virtualenv 3.9.7 myenv
# 仮想環境の有効化(必要があれば、この後に5.必要なパッケージのインストールを行う)
pyenv activate myenv
# 仮想環境の無効化
pyenv deactivate
6. 必要なパッケージのインストール
パッケージをインストールするには、仮想環境を有効化してから以下を実行。
pip install -r requirements.txt
Anaconda/Minicondaを用いた環境構築
AnacondaとMinicondaは、データサイエンスやAI開発に特化したPythonディストリビューションである。
- Anaconda: データサイエンス関連の主要なパッケージが最初から同梱された完全版
- Miniconda: 最小限のインストールで、必要なパッケージを後から追加できる軽量版
1. Anaconda/Minicondaのインストール
Anaconda/Miniconda が Linux にインストールされているか、以下のコマンドで確認する:
conda --version
インストールされていない場合は公式サイトを参照する。
2. 仮想環境の作成と管理
# 基本的な環境作成
conda create -n myenv python=3.9
# 環境の有効化
conda activate myenv
# 環境の無効化
conda deactivate
以下のように、作成した環境の確認や削除ができる。
# 作成した環境の一覧表示
conda env list
# 環境の削除
conda env remove -n myenv
3. パッケージのインストール
condaとpipの両方を使用できるが、可能な限りcondaを優先することが推奨される。
# condaでのインストール(推奨)
conda install numpy pandas matplotlib scikit-learn
# conda-forgeチャンネルの追加(パッケージの選択肢が広がる)
conda install -c conda-forge パッケージ名
# 複数のパッケージを一度にインストール
conda install numpy pandas matplotlib scikit-learn jupyter
# pipでのインストール(conda にないパッケージの場合)
pip install -r requirements.txt
4. その他:環境のエクスポートと共有
プロジェクトの環境を他者と共有することができる。
# 環境の設定をファイルにエクスポート
conda env export > environment.yml
# エクスポートした環境を再現
conda env create -f environment.yml
注意点
- conda と pip を混在して使用する場合は、基本的に conda を先に使用し、その後に pip を使用することを推奨
- Anacondaは容量が大きいため、個人利用ではMinicondaで十分な場合が多い
- プロジェクトごとに新しい環境を作成することを推奨
Dockerを用いた環境構築
Dockerがなんたるかは世の中の様々な記事を見た方が早いので割愛。環境をホストに汚さず、OS レベルで分離したい場合に有力な選択肢である。
まずは、以下の2ファイルを用意する。
- Dockerfile: 単一のコンテナイメージをビルドするための設定ファイル
- compose.yml: 複数のコンテナを定義・管理するための設定ファイル
services:
test-service-hoge:
image: hogehoge
build:
context: .
dockerfile: Dockerfile
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
volumes:
- .:/app
command: /bin/bash
ipc: host
tty: true
stdin_open: true
container_name: "${USER}_hogehoge"
FROM tensorflow/tensorflow:2.11.0-gpu
# 必要な追加ツール等があればインストール
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
unzip \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
CMD ["bash"]
以下のコマンドでコンテナを立ち上げる
docker compose up -d --build
使わない間は必ず以下を実行して、コンテナを壊しておくこと
docker compose down
2回目以降で立ち上げる場合は以下
docker compose up -d
ファイルのダウンロード(コマンド)
直接データセットページからダウンロードしても良いが、コマンドでダウンロードする方法もある
APIの設定(初めてのときのみ必要)
pip install kaggle --upgrade
kaggleのアカウント設定画面からAPI > Create New API Token をクリック
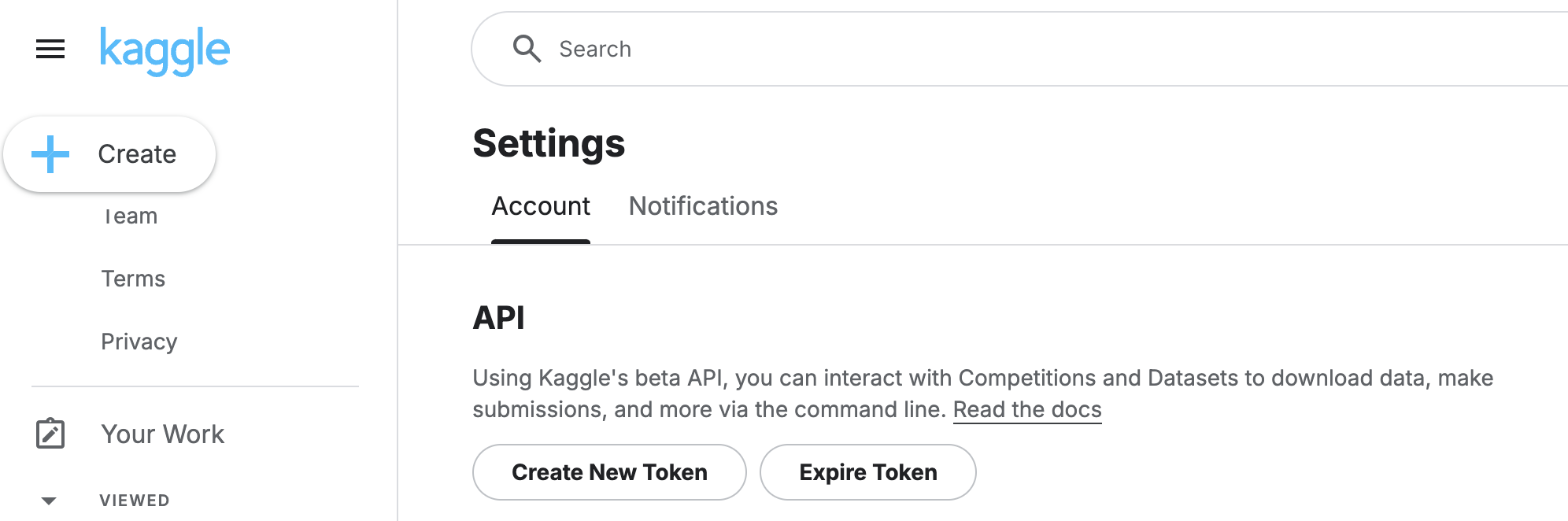
kaggle.json がダウンロードされるので、以下で~/.kaggle/kaggle.json へ配置。
cp {元のディレクトリ}/kaggle.json ~/.kaggle/kaggle.json
例)
cp /download/kaggle.json ~/.kaggle/kaggle.json
アクセス権限の変更
chmod 600 ~/.kaggle/kaggle.json
参考:kaggle 上のデータセットを cli でダウンロードする
ダウンロード
まず、データセットの利用規約があれば同意する
次に Downlooad > Kaggle CLI からダウンロード用のコマンドをコピー
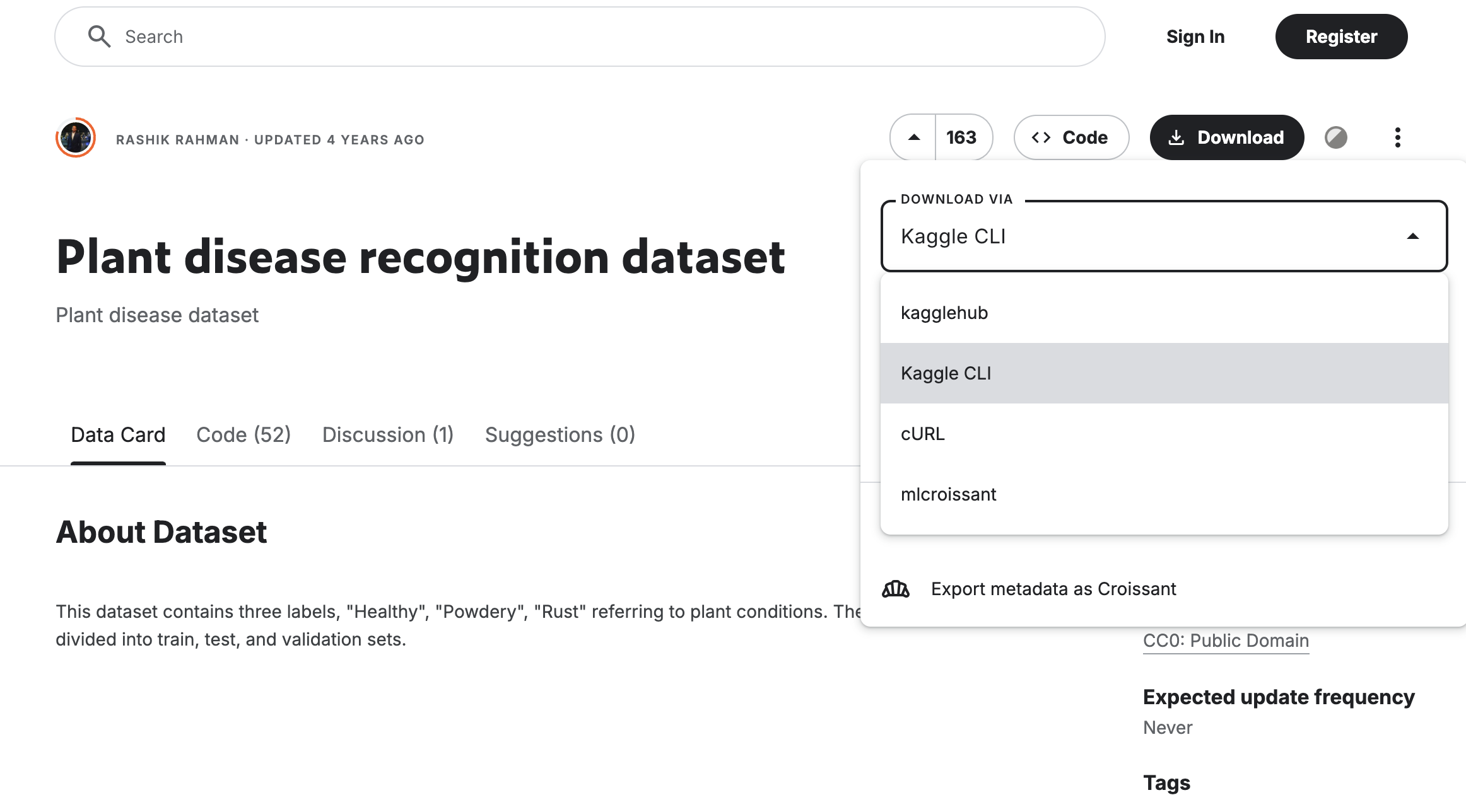
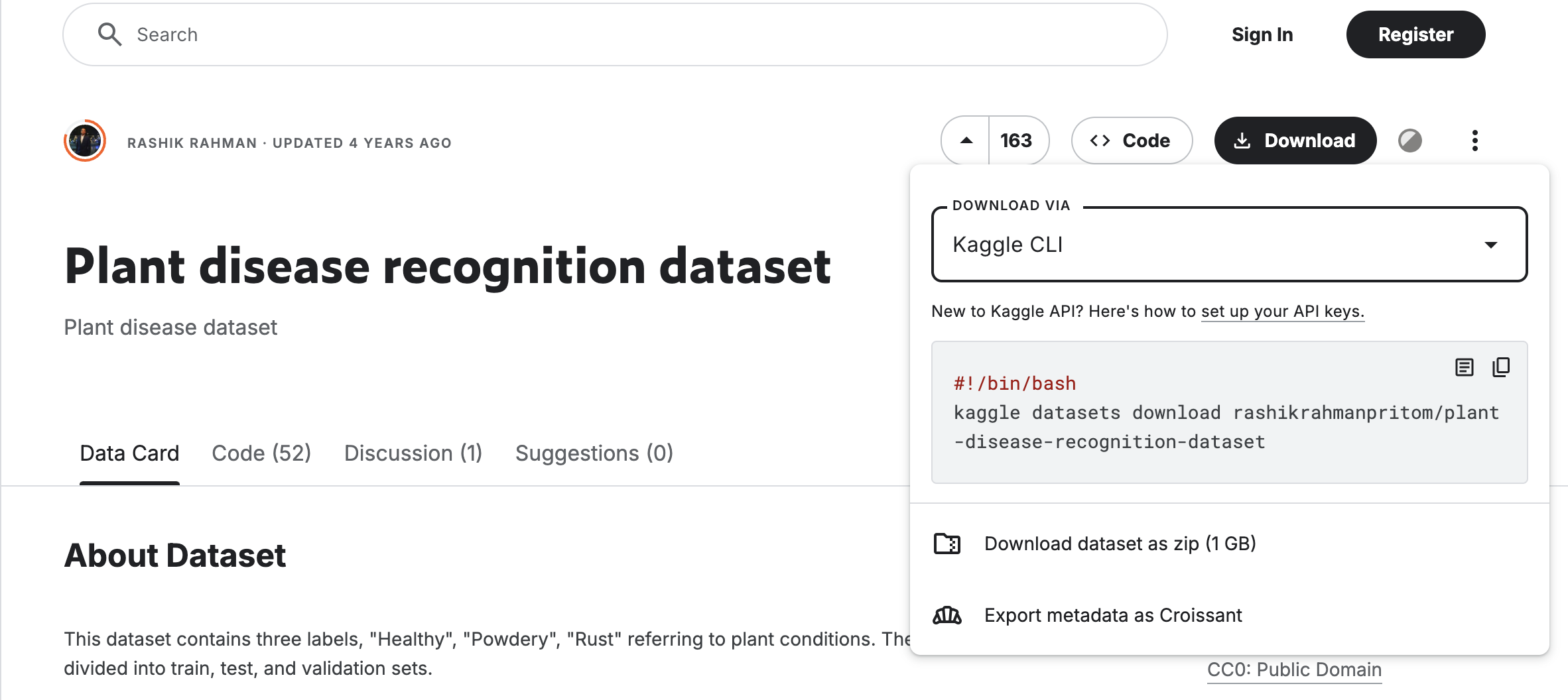
今回の場合は、以下のコマンドを入力
kaggle datasets download rashikrahmanpritom/plant-disease-recognition-dataset
終わり
初めての記事なので、簡単なとこまでで終わりにしたいと思います。これ系の記事は素晴らしいものがネット中に転がっているので、不明な点は調べていただければと思います。