JavaScript で半角幅としての文字列長を調べた件です。日本語のみ考慮してます。
課題
input type="text" の size や textarea の cols に文字数にて横表示幅を指定すると、これらは半角が前提なので、全角文字が入ると困った挙動になります。
<meta charset="utf-8">
<input type="text" value="ABC" size="3">
<input type="text" value="赤青黄色" size="4">
<textarea cols="4">赤青黄色</textarea>
<textarea style="white-space: nowrap" cols="4">赤青黄色</textarea>
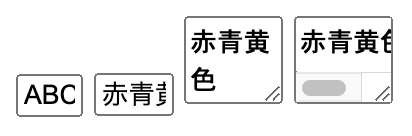
text は見切れますし、textarea は自動改行されます。自動改行阻止すると当然のように textarea も見切れます。
(プロポーショナルフォントなので実は ABC も微妙に足りませんが、大体は見えてるのでスルーで)
対応
全角1文字は半角の2文字としてカウントする処理があれば良さそうです。
具体的には、以下のようにカウント分けします。
| 種類 | 文字例 | length as harf width |
|---|---|---|
| 記号 | +-~ | 1 (x 3 文字 = 3) |
| アルファベット | ABCXYZ | 1 (x 6文字 = 6) |
| 半角カナ | アイウエオ | 1 (x 5文字 = 5) |
| 全角カタカナ | アイウエオ | 2 (x 5文字 = 10) |
| 全角ひがらな | いろは | 2 (x 3文字 = 6) |
| 漢字 | 赤青黄 | 2 (x 3文字 = 6) |
| 異体字 | 葛󠄀城市 | 2 (x 3文字 = 6) |
| 絵文字 | 😄 | 2 |
| 合成絵文字 | 👨👩👧👦 | 2 |
コードベース
大さっぱに以下の方針で行きます。
- 半角、もしくは全角では無いと判断できる文字はカウント +1
- それ以外は多分全角だろうからカウント +2
- 更に必要に応じて特殊なコード対応。
function lengthAsHalfWidth(text) {
let len = 0;
for (const t of text) {
const cp = t.codePointAt(0);
if (半角、もしくは全角ではないと判断できる文字) {
len += 1; // 半角
} if else (特殊なコード) {
// コードに応じた何かの処理
} else {
len += 2; // きっと全角
}
}
return len;
}
ちなみに以下のようにするとうまく行きません。絵文字の章で説明します。
for (let i = 0; i < text.length; i++) {
const cp = text[i].codePointAt(0);
あと、charCodeAt を使うとコードが 2 byte に収まらない場合(例えば異体字セレクタ 0xE0100)、2つに分かれた値を見て判断する必要があり面倒です。このエントリでは、codePointAt を使います。
> for (c of Array.from("葛󠄀")) { console.log(c.charCodeAt(0), c.charCodeAt(1)) }
33883 NaN
56128 56576
> for (c of Array.from("葛󠄀")) { console.log(c.codePointAt(0)) }
33883
917760
917760 は16進数だと 0xE0100 で、異体字セレクタです。
ASCII 記号/数字/アルファベット
if ((0x00 <= cp) && (cp < 0x7f)) {
len += 1; // ASCII 記号/数字/アルファベット
} else {
...
0x20(スペース)〜 0x7E"~" の範囲に絞っても良いですが、それをしても範囲外(だいたい制御文字)が全角としてカウントされるだけなので。いっそのこと ASCII の前半を全てカバーで。
ASCII コードを 8bit のまま 0xA1 〜 0xDF を使って日本語のカタカナや記号を表す JIS X 0201 規格がありますが、Unicode に対応する領域があると聞かないので、スルーします。
半角カナ
SJIS で多用していた半角カナは Unicode にもあります。
if ((0xff61 <= cp) && (cp < 0xffa0)) {
len += 1; // 半角カナ
} else {
...
半角カナは、昔の 2ch AAや、あとガラケー時代の文字を再現するのに必須ですね。。(๑>◡<๑)
SJIS半角予約領域
Unicode には私的利用領域があり、いわゆる外字を割り当てるのですが、SJIS に半角文字として将来(大昔にとっての将来)使うかもしれない予約領域があり、それとのマッピングを意識する場合、以下のようになります。
if ((0xf8f0 <= cp) && (cp < 0xf8f4)) {
len += 1; // 半角文字の予約エリア
} else {
...
概念的には対応した方がすっきりするかもしれません。自分は一旦無視します。(テスト出来ないので)
実際にこの文字を見た事がある。という方がいれば、教えてください。
異体字
> Array.from("葛󠄀城市")
(4) ['葛', '󠄀', '城', '市']
この2つ目は異体字セレクタ(0xE0100)で、文字幅に影響しない為、無視します。
if (((0xfe00 <= cp) && (cp <= 0xfe0f)) ||
((0xe0100 <= cp) && (cp <= 0xe01fe))) {
; // 異体字セレクタは幅0扱い
} else {
...
絵文字
冒頭で i でループする方法が駄目と触れましたが、
実際に文字列を配列として参照すると、絵文字は2文字に分割されます。サロゲートペアが原因です。
> t = "赤青黄"; for (let i=0; i < t.length; i++) { console.log(t[i]) }
赤
青
黄
> "😄👀🌹".length
6
> t = "😄👀🌹"; for (let i=0; i < t.length; i++) { console.log(t[i]) }
�
�
�
�
�
�
Iterator がサロゲートペアに対応しているので、for of を使うか、Array.from(text) を通せば配列アクセスで問題なくなります。
> for (const c of "😄👀🌹") { console.log(c) }
😄
👀
🌹
> t = Array.from("😄👀🌹"); for (let i=0; i < t.length; i++) { console.log(t[i]) }
😄
👀
🌹
以下のサイトの解説が詳しいので参考にどうぞ
- JavaScript における文字コードと「文字数」の数え方
絵文字修飾
異体字セレクタの絵文字版みたいなものです。
具体的にはこれ "👍🏻👍🏼👍🏽👍🏾👍🏿"
if ((0x1f3fb <= cp) && (cp <= 0x1f3ff)) {
; // Emoji Modifier
合成文字
例えば、👨👩👧👦 のような合成絵文字は Array.from でも対応できません。
> "👨👩👧👦".length
11
> text = Array.from("👨👩👧👦"); for (const c of text) { console.log(c) }
👨
👩
👧
👦
空行が入っているのが気になります。
> "👨👩👧👦".length
11
> Array.from("👨👩👧👦")
(7) ['👨', '', '👩', '', '👧', '', '👦']
この絵文字のノリしろになっている '' は、Zero Width Joiner (ZWJ,0x200D) です。
なので、前の絵文字の分スペースを戻せば、辻褄は合いそうです。
} else if (cp === 0x200d) { // ZWJ
len -= 2; // 合成絵文字のノリしろ
} else {
なお、正しく処理したい場合は、専用ライブラリを使うと良いでしょう。例えばこれとか。
まとめ
function lengthAsHalfWidth(text) {
let len = 0;
for (const c of text) {
const cp = c.codePointAt(0);
if ((0x00 <= cp) && (cp < 0x7f)) {
len += 1; // ASCII 記号/数字/アルファベット
} else if ((0xff61 <= cp) && (cp < 0xffa0)) {
len += 1; // 半角カナ
} else if (cp === 0x200d) { // ZWJ
len -= 2; // 合成絵文字のノリしろ
} else if (((0xfe00 <= cp) && (cp <= 0xfe0f)) ||
((0xe0100 <= cp) && (cp <= 0xe01fe))) {
; // 異体字セレクタは幅0扱い
} else if ((0x1f3fb <= cp) && (cp <= 0x1f3ff)) {
; // 絵文字修飾も幅0扱い
} else {
len += 2; // きっと全角
}
}
return len;
}
もし、ZWJ で巻き戻るのが全角だけでなく半角の可能性があるのなら、少し複雑ですが、こんな実装が思いつきます。
function lengthAsHalfWidth(text) {
let len = 0;
let width = 0
for (const c of text) {
const cp = c.codePointAt(0);
if ((0x00 <= cp) && (cp < 0x7f)) {
width = 1; // ASCII 記号/数字/アルファベット
} else if ((0xff61 <= cp) && (cp < 0xffa0)) {
width = 1; // 半角カナ
} else if (cp === 0x200d) { // ZWJ
width = -width; // 合成絵文字のノリしろ
} else if (((0xfe00 <= cp) && (cp <= 0xfe0f)) ||
((0xe0100 <= cp) && (cp <= 0xe01fe))) {
; // 異体字セレクタは幅0扱い
} else if ((0x1f3fb <= cp) && (cp <= 0x1f3ff)) {
; // 絵文字修飾も幅0扱い
} else {
width = 2; // きっと全角
}
len += width;
}
return len;
}
テスト
> lengthAsHalfWidth("XYZ");
3
> lengthAsHalfWidth("漢字ですデス");
12
> lengthAsHalfWidth("😄😇");
4
> lengthAsHalfWidth("アイウエオ");
5
> lengthAsHalfWidth("👨👩👧👦");
2
追記
絵文字の異体字に対応していませんでした。課題で。
"👍🏻👍🏼👍🏽👍🏾👍🏿"
参考
- 半角を判別する
- JavaScriptでの絵文字の扱われ方を知っていますか?
- JavaScript における文字コードと「文字数」の数え方
- 半角を判別する
- Full-width half-width conversion
- JavaScriptで絵文字とサロゲートペアと結合文字とgrapheme clusterを正しく扱うのに少し苦労した話
- JavaScript: 異体字セレクターを考慮して文字数を求める
- https://ja.wikipedia.org/wiki/異体字セレクタ
- 字形選択子(異体字セレクタ) Variation Selectorsの文字一覧 - 1 Unicode U+FE00~U+FE0F(65025文字目~65040文字目)
- https://www.weblio.jp/wkpja/content/その他の記号及び絵記号_その他の記号及び絵記号の概要