背景
平成の次の元号は何になるの?
エンジニアに限らず、多くの人が気になる話題である。
エライ学者先生ががんばって調べたり選んだりして決めるんでしょ。
しかし、時はAIが囲碁や将棋で名人を負かす時代。
そうだ!AIに新元号を決めてもらえばいいじゃん!!
まさに悪魔的発想・・・!
「OK、Google、新しい元号は何になるの?」
⇒ 教えてくれるワケがない。(元号関連記事くらいは教えてくれる)
じゃあ自分で作ってみよう!
人の判断を一切入れずに、AIだけで新元号作ることが出来るのか?が今回のテーマ
余談: ちなみに大喜利人工知能の、大喜利βさんに聞いたところ
「アメリカ」との答えが返ってきた。
このタイミングで、アメリカ合衆国51番目の州は「本州」です、とせよとの啓示なのか!?
新元号のルールは?
以下のように決められているらしい。
1. 国民の理想としてふさわしいようなよい意味を持つものであること。
2. 漢字2字であること。
3. 書きやすいこと。
4. 読みやすいこと。
5. これまでに元号又はおくり名として用いられたものでないこと。
6. 俗用されているものでないこと。
このルールから、「AI」だけで決めることが出来るのだろうか?
また、追加ルールとして、M(明治)、T(大正)、S(昭和)、H(平成)と、
頭文字のアルファベットが重複しないようにする、というフィルタが存在する。
(※なお、本投稿では、「おくり名として用いられた」の部分は、
リストを作るのが面倒&後で除外すればよいだけなので、無視して話を進める)
AIにとっての最大の難関は「良い意味の判断」
- 新元号は「苦節」「熟成」「余命」です。
- 苦節3年、苦労がにじみ出る味があっていいね♪
- 熟成10年、おいしくなってきます♪
- 余命4年、だんだん伸びていく♪
- 漢字2字だし小学校で習う字だよねー
- これくらいならば、「6」の俗用されていないという点で、AIでもダメだと分かるかも?
- 新元号は「石上」「光宙」「炎殺」です。
- 石の上にも3年
- 光宙⇒ピカチュウ!
- 邪王炎殺黒龍波!
- これはギャグにしかならないということをどうやって機械が判断する?
- 中二病の技名みたいな名前が出ないようにしないと日本国の恥になるよ。
つまり、ルール「1」の、
「国民の理想としてふさわしい良い意味を持つ」
ということを、どうやって機械が判断するのか?
が圧倒的最大の難関になりそうである。
本投稿の内容
- ガチで、AIだけに漢字のセレクトを任せ、新元号に相応しい言葉を計算します。
- 使えるINPUT情報は、以下3点とします。
- Wikipediaのテキストデータ
- (※元号関連の記事を検索するような用途ではなく、ただの大量テキストとして扱う)
- 既に使われた元号の一覧(250個)(=これをお手本として学習)
- 教育用漢字一覧(小学校で覚える漢字一覧=1006字)(=候補一覧)
- 読みやすい=小学校レベルの漢字、と仮定。
- (※常用漢字の場合は1945字。データを入れ替えればこちらでも可)
- Wikipediaのテキストデータ
-
製作者が調整出来ることは「数値の設定だけ」で、主観で判断はいけない、とします。
- 例えば、「苦」の字は意味が悪いから使われないよね、といって除外するのは禁止
- 何かの基準で、上位N個に絞るとか、何かの得点値が10以上、などと数値を切るのはOK
- つまり、候補の約1000字に対して、「全ての文字を平等に扱う」ことになる。
- 数値やテキストの変更だけに依存し、誰がやっても同じ結果が出ること、と言い換えても良い。
外見で人を判断してはいけない、というのに似ている。筆記テストの点だけで漢字を判断
- おおまかな内容
- お手本データ=元号の一覧、と似たような組み合わせを、
- 大量の日本語コーパス(wikipedia)の学習結果をもとに、
- 1006字×1006字の組み合わせの中から見つけ出す、ということ
- コードの実行環境は全て、Windows10 + Python3 +JupyterNotebook を前提。
悪魔的発想の計画
そうだ!Char2Vecを使おう!
Char2Vecとは、Word2Vecの「1文字版」である。
(投稿時に気づいたが、Qiitaにchar2vecのタグが無かった)
Word2Vecを使った私の別の記事は以下:
参照:「赤の他人」の対義語は「白い恋人」 これを自動生成したい物語
Word2Vecの場合、単語のベクトル化を行うことで、
「王様」ー「男」+「女」=「女王」
などの演算を可能にしたが、
全く同じことを、今度は単語区切りではなく、1文字区切りで行うことで
文字(漢字)に対して、ベクトルを割り当てるというもの。
発想として、良い意味の漢字=既に元号で使われたことのある漢字、として、
それに似たベクトルを持つ漢字が、元号の候補となる漢字なのではないか?
まず、この方針で良い意味を持つ&元号に使われてもよさそうな漢字、のリストを作る。
次に、その組み合わせの中で、2字の組み合わせが良いものを探すという方針。
Char2Vecの実行例とその課題
Char2Vecは、モデルの作成時のパラメータによるのかもしれないが、
Word2Vecよりも、人が見た時の納得感が無い、と思われる。
以下は、「水」に近い文字を表示させたときの実行例。
from gensim.models.word2vec import Word2Vec
import gensim
JPmodel_path = 'モデルのパスを記載'
JPmodel = Word2Vec.load(JPmodel_path)
JPmodel.most_similar(positive = u'水', topn=10)
[('砂', 0.689274251461029),
('堰', 0.6883330345153809),
('湖', 0.6873093843460083),
('堤', 0.6631444692611694),
('塩', 0.6606267690658569),
('氷', 0.6517341136932373),
('湿', 0.6269866228103638),
('浸', 0.6251579523086548),
('流', 0.6123377680778503),
('湧', 0.6074004173278809)]
一位はなんと「砂」。サラサラという意味で近い仲間と思ったのだろうか?
ゲームの属性では天敵になりそうなほど相性が悪そうだが。
他に、例えば「右」を入れると、似ている一位は「左」なのは良いが、
2~4位は、肩、腕、腰、であった。
Word2Vecの場合は、例えば「コアラ」は「パンダ」などと入れ替えても
文章として成立するため、似た言葉を集めることが出来るが、
「漢字一字」の場合、Wordと違い、置き換えても成立するような字は多くないため、
過度の期待は出来ない。
最初は、漢字の演算(足し算や引き算)も駆使して、
新元号を作ろうかと考えたが、そこまで期待せずに、
意味的に似ているかどうか?を抽出する目的に限って使う。
余談: 英語圏では、A~Zをベクトル化しても全く面白くないこともあり、
char2vecは注目されていない気がするが、
日本語、中国語など、漢字を扱う文化においては、
もっと面白いことが出来るかもしれない。
本投稿も、日本語と中国語の漢字の意味の違いをchar2vecで比較していた時に、
年号の話題を聞いたために思いついた内容。
日本語中国語の比較についても、まとまったらどこかで発表するかもしれない。
Char2Vecのモデルの作成
前回の 「赤の他人」の対義語は「白い恋人」 これを自動生成したい物語 では、
学習済みのWord2Vecモデルを使ったが、今回は、
Char2Vecの学習済みのモデルは良さそうなものが無いために、自分で作ることにする。
むしろ本投稿の最も役立つ部分はこの章かもしれない。
そもそも本投稿によって、AIが新元号を作ったとして、何か世の中に役立つのか?
という誰もが最初に思う疑問は既に削除されている
Char2Vecのモデルをwikipediaから生成する
①Wikipediaダンプデータの入手
Wikipediaのダンプ置き場から、
「jawiki-20180501-pages-articles-multistream.xml.bz2」をダウンロードする
②パースして整理
WikiExtractorという、Wikipediaのパーサーをダウンロードする。
以下のコマンドで、加工する。
タイトル+記事のタグ形式にしてくれる。(分量があるので時間はかかるよ)
python WikiExtractor.py -o extracted jawiki-20180501-pages-articles-multistream.xml.bz2
③1行=1記事になるように加工
Hironsan様の、ja.text8のリポジトリから、
「process.py」を使って、タグや改行の除去や、1行1記事化を実施する。
②の手順で出来た「extractedフォルダ」の上で実行するだけ。
Hironssan様ありがとうございます。
なお、上記のprocess.pyはpython2向けのコードであるが、
ファイル操作の場所などをちょっと変えるだけで動作する。(例えば以下)
with open(filename) as f:
import codecs
with codecs.open(filename,"r","utf-8") as f:
④1文字単位に区切る
Word2Vecの場合は、ここでmecabが出てきて、
単語単位になるように形態素解析を行うのだが、
Char2Vecの場合、全て1文字で区切るだけ。
%%time
#↑は、jupyternotebook上で経過時間を見るため
#大ファイルを扱うので、メモリ溢れ対策に、1行ずつ読んで結果ファイルに追記していく。
with codecs.open('ItiGyouGotoKiji.txt',"r", "utf-8") as f:
for line in f.readlines():
chars = [c for c in line if c != u' ']
with codecs.open('allWiki_1kugiri.txt',"a", "utf-8") as newf:
newf.write(u' '.join(chars))
⑤機械学習でChar2Vecモデルを作る
パラメータは何回か試行錯誤したほうが良い。
以下に関連パラメータの意味もコメントに記載。
一回作るのに数時間かかる。
%%time
import logging
from gensim.models import word2vec
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus('allWiki_1kugiri.txt')
model = word2vec.Word2Vec(sentences, size=60, window=60, min_count=50, hs=0, negative=15, iter=6)
#size:空間サイズ=ベクトルの次元数(デフォルトは100だが、今回は1字なので減らす)
#hs:学習に階層化ソフトマックスを使用するかどうか =1か0
# 階層化ソフトマックスとは、単語の出現の代わりに意味クラスの出現を使うことで
# 語彙の大きさを減らす、単語を階層的に表現して単語の数を減らす手法。
#negative ランダムに、出現していない単語、側も学習するその単語数 =0
#sample: ランダムに頻出単語を消去する。(デフォルトは1e-3)非常に低い
#iter:トレーニング反復回数 ちなみにデフォルトは5。
#min-count: n回未満登場する語句は破棄する。少し多めに50に設定。レアな字は消える。
#window:前後にある単語を、何個まで文脈として判断させるか。デフォルトは5。
# 単語の場合は10以下でも良いが、今回は1字ごとなので多めに設定。
model.save("mychar2vec_fromWikiALL.model")
⑥さあ、ためしてみよう
from gensim.models.word2vec import Word2Vec
import gensim
JPChmodel_path = 'mychar2vec_fromWikiALL.model'
JPmodel = Word2Vec.load(JPChmodel_path)
JPmodel.most_similar(positive = [u'書'], topn=10)
[('冊', 0.7298516035079956),
('文', 0.7217180728912354),
('訳', 0.6349352598190308),
('訂', 0.6302940845489502),
('筆', 0.6280542612075806),
('図', 0.6250900626182556),
('稿', 0.619011402130127),
('紙', 0.6081395149230957),
('宛', 0.6069372296333313),
('著', 0.5928876996040344)]
まあ、疑問に思う点はあるけれども、
「近いジャンル」の文字は似ている文字として返している気はする。
つまり、元号の見本=良い意味の文字、を入れれば、
良い意味の漢字を返してくれるのではないだろうか!?
AIに「使いたい漢字」を決めさせる
まず、2文字の組み合わせを考える前に、
どの漢字を使ったら良いのか、元号に相応しい漢字を抽出することにする。
方針としては、過去に使われた文字と、意味の方向が似た文字を探すことにする。
過去の元号のリストを加工する
「お手本」とする漢字データの内容について言及しよう。
「大化」から「平成」まで、約250個の元号があり、
極少数の例外を除いて、ほとんどは「2文字」で構成されている。
元号のリストは簡単に見つかるので自分でぐぐってね
しかし、元号に使われている漢字の種類は意外と少ない。
なんと、72文字。
多い順からならべると、
永元天治応正長文和安延暦寛徳保承仁嘉平康宝・・・
上記の文字はどれも10回以上使われている、エース文字。日本の理想。
一番多い「永」はじつに29回
一回しか出てこない文字は、何かの間違いで入ったかもしれないので除外すると、
42文字になった。
これらの文字それぞれに対して、似ている上位20位を表示してみよう。
#元号に使われている漢字を、多い順から並べているよ。1回しか出てこない字は消しているよ。
str = "永元天治応正長文和安延暦寛徳保承仁嘉平康宝久慶建享弘貞明禄大亀寿万化観喜神政中養雲護"
nnn=20
for idx in range(0, len(str)):
out = JPmodel.most_similar(positive = str[idx], topn=nnn)
resulttext=""
resulttext+=str[idx]+": "
for var in range(0, nnn):
resulttext+=out[var][0]
print(resulttext)
永: 貞禄寛忠慶徳弘久嘉仁享元吉隆孝泰清藩亀賢
元: 永貞姓寛仁禄忠嘉久賢弘藩孝慶胤泰徳諱享氏
天: 仁皇暦光后雲宮陽崇恒貞殿永祀祠嘉紫徳太邀
治: 府策晰由黎瞭独己憲寛党ན済民ญ院چ身ปნ
応: 媒換反対互x抗逆+触排酸縮q信す蓄促変象
正: 慶則永貞忠明徳臣弘寛宗憲延改勅禄皇暦寺条
長: 副兼務任佐就員職僚官弘輔俊房委勤崎寿司雄
文: 書典著図詩説漢彙纂訳字暦訂刷儒冊譜筆唐抄
和: 騏坦弛凡成璧懋均咋髦贇雎弊厠彊宙軛櫟磐鵄
安: 仁嘉清永康昌貞徳泰守不省久尚忠孝臣享寿弘
延: 遅直至正僅慶貞永線亀余5間3≈長4禄6房
暦: 閏天永皇寛仁勅貞遷享文宝禄元没朝唐抄正叙
寛: 禄永享貞忠慶藩徳嘉弘江奉嗣元亀老久之隆戸
徳: 永忠貞嘉慶寛孝弘仁久清禄賢嗣吉泰江隆之昌
保: 依危既在康庇碍恆維看害認璠冒実祉財弁安堵
承: 孫甥嗣於婿伯帝卿爵皇統醢侯弉続祀廃胤俑遺
仁: 孝嘉貞泰清尚天弘永昌徳亀賢恭澄隆亮慶斉輔
嘉: 仁清孝泰尚徳弘貞昌永慶之賢寛呉禄亮忠斉輔
平: 昭飽功緩蹊構完睦浦熟績辯衡仁嶺珥佼-陽筬
康: 徳永忠保隆安孝弘吉清養貞嗣寛健嘉久慶俊杉
宝: 蔵塚璃舞銭五伽殿藍六獅宮寛八丹嘉竹帖納暦
久: 吉永弘祐田井藤忠伊茂徳俊松幸津隆之佐貞豊
慶: 永禄弘忠貞寛徳隆嘉孝清泰藩仁昌吉久斉正亀
建: 敷創施立置計跡殿壁棟鋳醸艤備舎瓦塔捏堂煉
享: 寛永禄貞没忠徳藩嘉慶嗣嫡老奉死久逝仁亀篤
弘: 隆孝俊吉泰慶貞嘉永賢祐久彦之輔井郎藤仁忠
貞: 永忠徳仁弘寛慶孝嘉泰禄隆賢胤享嗣元尚清久
明: 正愼賢政永貞元徳肅暦摠弘慶裁仁嘉憮寛噲菅
禄: 寛永慶忠貞藩享嘉徳賜弘江嗣亀奉元氏隆泰城
大: 中長校早稲高課杯士府学京門科蛆院三古≒後
亀: 弘吉菅井竹仁坂隆垣松奥澄久祐八嘉永丹津貞
寿: 嘉仁房橘隆呂郎清弘貞孝桃輔涼淳泰恵永夫太
万: 億円額$約0,倍%坪費百累金£俸銭税払人
化: 質酸的核媒素蛋融剤塩酵体凝脂量β炭促鉛微
観: 光測客眺洞鏡景館展灯温媚恒天僥慧蒜風涌壢
喜: 幸輔坂郎竹雅賢孝之吉淳祐弘松晴智悦井澄彦
神: 祀霊魂祈宮祠祓崇祇聖橿殿祷巫幡狐祭坐禊奈
政: 統民首摠掌革派明維僚支領閥閣威鴈弼国誥掾
中: 内北外広南近大磐桃棋四高西韓都痂扼街箕後
養: 育父乳幼康老母歳酪親牧師蚕熟摂弟子仔叔享
雲: 鳳烏龍陽淵蘇沙朔蒼遙紫竺丹霧洞天凰嶺呂陵
護: 健険防守援障救瀕衛祉者戒被頼庁境安範包有
これは、ちょっとやったことを後悔するレベル
想像以上のカオスが生まれてしまった
印刷すれば地獄先生ぬ~べ~の経文としてコスプレに使えるかもしれない
カオスの中から光を抜き出す
まず、似ているTOP20を全て表示、というのはやりすぎだった。
どーみても関係の無いというか、漢字ですらないレベルの文字まで出ている。
そこで、コサイン類似度が一定値以上という閾値を設定することで、
十分似ている文字だけを抽出することにした。
また、超難解な漢字まで抽出されているため、
ここで、常用漢字のリストと、教育漢字のリストのフィルタを適用してみよう。
str = "永元天治応正長文和安延暦寛徳保承仁嘉平康宝久慶建享弘貞明禄大亀寿万化観喜神政中養雲護"
nnn=30
ruijido=0.6
jyouyoulist = "亜哀愛悪握圧扱・・・・以下省略"
kyouikulist = "愛悪圧安暗案以・・・・以下省略"
allresult=""
for idx in range(0, len(str)):
out = JPmodel.most_similar(positive = str[idx], topn=nnn)
resulttext=""
resulttext+=str[idx]+": "
#元の元号に使われた漢字が、教育リストに含まれているならば、候補に入れる。
if kyouikulist.count(str[idx]):
allresult+=str[idx]
for var in range(0, nnn):
#コサイン近似度がruijido以上のものを対象とする。
if(out[var][1]>ruijido):
if str.count(out[var][0]):
resulttext+="("+out[var][0]+")"
else:
if kyouikulist.count(out[var][0]):
resulttext+="【"+out[var][0]+"】"
allresult+=out[var][0]
else:
if jyouyoulist.count(out[var][0]):
resulttext+="{"+out[var][0]+"}"
print(resulttext)
lst = list(set(allresult))
print(','.join(lst))
print(len(lst))
本投稿のハイライトの一つが以下の表
永: (貞)(禄)(寛)【忠】(慶)(徳)(弘)(久)(嘉)(仁)(享)(元){吉}{隆}【孝】{泰}【清】{藩}(亀){賢}【氏】{斉}(康)(暦)(正)
元: (永)(貞){姓}(寛)(仁)(禄)【忠】
天: (仁)【皇】(暦)【光】【后】(雲)【宮】
治: 【府】
応:
正: (慶)【則】(永)
長: 【副】{兼}【務】【任】{佐}
文: 【書】【典】【著】
和:
安: (仁)
延:
暦: (天)(永)【皇】
寛: (禄)(永)(享)(貞)【忠】(慶){藩}(徳)(嘉)(弘){江}{奉}{嗣}(元)(亀)【老】(久){隆}【戸】
徳: (永)【忠】(貞)(嘉)(慶)(寛)【孝】(弘)(仁)(久)【清】(禄){賢}{嗣}{吉}{泰}{江}{隆}{斉}{藩}(康)(享){斎}{尚}{津}
保: {依}【危】
承:
仁: 【孝】(嘉)(貞){泰}【清】{尚}(天)(弘)(永)(徳)(亀){賢}{恭}{澄}{隆}(慶){斉}【后】{丹}【宮】【忠】(安){唐}(元)
嘉: (仁)【清】【孝】{泰}{尚}(徳)(弘)(貞)(永)(慶){賢}(寛){呉}(禄)【忠】{斉}{唐}{隆}(亀){吉}(久){恭}【五】(寿){丹}{澄}
平: 【昭】
康: (徳)(永)
宝: 【蔵】
久: {吉}(永)(弘)【田】{井}【忠】{茂}(徳){俊}【松】【幸】{津}{隆}{佐}(貞)【豊】【坂】(亀)【賀】(嘉)【孝】(慶){藩}
慶: (永)(禄)(弘)【忠】(貞)(寛)(徳){隆}(嘉)【孝】【清】{泰}{藩}(仁){吉}(久){斉}(正)(亀){賢}{尚}{江}{嗣}
建: {敷}【創】{施}【立】
享: (寛)(永)(禄)(貞){没}【忠】(徳){藩}(嘉)
弘: {隆}【孝】{俊}{吉}{泰}(慶)(貞)(嘉)(永){賢}(久){井}{郎}(仁)【忠】【田】(徳)(亀)【清】【竹】(寛){雅}【松】
貞: (永)【忠】(徳)(仁)(弘)(寛)(慶)【孝】(嘉){泰}(禄){隆}{賢}(享){嗣}(元){尚}【清】(久){斉}【氏】{嫡}{吉}(亀){澄}
明:
禄: (寛)(永)(慶)【忠】(貞){藩}(享)(嘉)(徳){賜}(弘){江}{嗣}(亀){奉}(元)【氏】{隆}{泰}
大:
亀: (弘){吉}{井}【竹】(仁)【坂】{隆}{垣}【松】{奥}{澄}(久)【八】(嘉)(永){丹}{津}(貞){泰}【田】(慶)【孝】{堀}{尾}
寿: (嘉)(仁)
万: 【億】【円】【額】【約】
化: 【質】
観: 【光】
喜: 【幸】【坂】{郎}
神: {霊}{魂}{祈}【宮】{崇}
政: 【統】
中:
養:
雲: 【陽】{紫}{丹}{霧}{洞}(天)
護:
上記の表の凡例は以下の通り。
* 一番左の列は、元号に使われている漢字を多い順に並べたもの
* 右側に、各漢字に対してコサイン類似度が0.6以上の文字を、類似度順に記載
* 常用漢字に無い漢字は削除
* 【】は、元号の漢字リストに存在している漢字
* {} は、常用漢字(1945字)に含まれている漢字
* () は、教育用漢字 (1006字)に含まれている漢字
この結果を見ると、なんとなく縁起の良さそうな漢字が多く、
その中で多少難しい字は{}で囲われている、という雰囲気になる。
この手法は、名前を付ける際などの案出しなどとしても、多少使えそうだ。
例えば、上から見ていくと、「応」や「和」が似た漢字が無いところであるが、
これは、似た意味の言葉が見つからない、独自性が高い漢字であることを意味している。
このリストの中で、「教育用漢字」に含まれている漢字だけに限定して出力すると、
以下の71文字になる。
(※上述のプログラムを実行するとこちらの結果も同時に出力する)
喜,忠,老,孝,建,護,康,創,億,清,幸,額,府,中,治,坂,天,文,宝,蔵,田,光,承,観,皇,書,平,明,政,仁,元,任,副,万,正,立,昭,五,応,著,久,和,氏,大,約,戸,保,則,典,安,徳,統,養,神,円,延,化,八,豊,雲,永,后,陽,質,賀,長,務,危,宮,松,竹
71
どれが一位なの?順番をつけよう
使われる候補となる文字を71文字まで抽出したが、
結局どれが使われるんだよ?ってことでランキングをつける。
これまでの考え方に合わせて、「お手本の漢字」との
距離の近さが近いものを上位とする。
ただし、例えば「永」「喜」など、自分自身がお手本に入っている漢字については、
自分自身との距離は1.0(最大)になってしまいズルイので、
自身との比較を除いて、平均値で比較することにする。
なお、このランキングによって、
なぜかまだ71字に入っている「危」などは、ほぼビリの順位になって除外される。
さあ、以下のプログラムでいよいよTOP20の発表だ!
str = "永元天治応正長文和安延暦寛徳保承仁嘉平康宝久慶建享弘貞明禄大亀寿万化観喜神政中養雲護"
resultlist=[]
for lstidx in range(0, len(lst)):
distance=0
cnt=0
for stridx in range(0, len(str)):
#別な文字である場合のみ実施
if lst[lstidx] != str[stridx]:
distance += JPmodel.similarity(lst[lstidx], str[stridx])
cnt+=1
resultlist.append([lst[lstidx],distance/cnt])
ranking = sorted(resultlist, key=lambda x:x[1], reverse=True)
finalkouho=ranking[:20]
import pprint
pprint.pprint(finalkouho)
[['永', 0.4432615391959312],
['徳', 0.42958927220753584],
['仁', 0.42234036442990081],
['忠', 0.39814997500397165],
['清', 0.39167382076459972],
['孝', 0.38281166761176649],
['久', 0.35123899427760841],
['天', 0.33663049257426525],
['元', 0.33296518845281042],
['正', 0.32448461789657612],
['安', 0.31749253943023814],
['宮', 0.29887811652228685],
['蔵', 0.29585180662184218],
['老', 0.29422004885350239],
['五', 0.29177360054646811],
['康', 0.29155911853392569],
['氏', 0.28970518143898977],
['豊', 0.28275205021451155],
['明', 0.27604375636628525],
['松', 0.26546272673926241]]
今回の結果でいうと、
「永」「徳」などはもともとお手本にも入っている漢字であるが、
「忠」「孝」「清」「宮」「蔵」「老」「五」「氏」「豊」「松」
の字は、お手本にはなくAIが導き出した漢字である。
「蔵」「老」「五」「氏」あたりは使われる可能性はほぼ無さそうなものの、
他の字はそんなに悪いセンスでは無い気がする。
(と思っていたら、「老」は実は既に過去に一回使われていた。
上のお手本は、一回だけの文字は除外しているため、含んでいなかった。)
それにしても、今回の結果からも、不動のエース「永」の支持率の高さはすごい。
上位陣の顔ぶれは、お手本の上位陣とかなり近い状況であり、
元号で良く使われる漢字は、AIから見てもそれなりの理由があったということだ。
改めて今回の決勝戦メンバーを発表!!
ここまでで、AIが使いたい漢字のリストを、順位付きで作成することが出来た。
上記では、ご参考までにTOP20まで表示しているが、
組み合わせだとおよそ400パターン近くになってしまい、まだ多いため、
以降では上記の中のTOP10の漢字を使う、とする。
つまり、勝ち上がったメンバーは、AIランキング順に以下の10名。
「永」:過去採用01位=29回の不動のエース。AIランキングでも堂々1位
「徳」:過去採用13位=15回。AI的にはこれも本命
「仁」:過去採用17位=13回。八犬伝や、論語などにも登場。これも本命
「忠」:AIが出した新顔。 八犬伝や、論語などにも登場。ちと古い概念か?
「清」:AIが出した新顔。 良い意味だが、中国の国名だったのがまずい?
「孝」:AIが出した新顔。 八犬伝、論語などにも登場。新顔の中のエース格。
「久」:過去採用22位=09回。書きやすいしいいよね。
「天」:過去採用02位=27回。やはり二位も強い。
「元」:過去採用02位=27回。「天」と同様に強い。
「正」:過去採用06位=19回。これも書きやすい。
ご参考:南総里見八犬伝 の8つの字
仁・義・礼・智・忠・信・孝・悌
途中考察
一見、過去に使われた漢字を多数出しており、AIが働いていないようでもあるが、
そもそも、元号に使われている漢字は、どれも良い意味であり、
相互に意味の類似度が高いため、過去採用の漢字が多くなるのは妥当である。
「元号に使われた漢字と同じような方向性の字」のランキングであるため、
同じような方向を持ちながら今まで使われていなかった「忠」「清」「孝」を
探し出すことができた、と言うべきであろう。
昭和の「昭」、平成の「成」はそれぞれ初めて使われた字であり、
今回も1字分は新しい漢字を使う可能性もあるが、逆に言えば、
もう一方は過去に使われた字のどれかが使われる可能性が高いし、
2文字とも過去に使われた字が使われるかもしれない。
新漢字=3文字、旧漢字=7文字がTOP10であったというバランスは面白い。
AIに「元号として適切な組み合わせ」を作らせる
さて、使う漢字の整理は出来たが、
どう組み合わせれば「元号らしい」のか?
また、過去の元号で使用済みのパターンは除外する必要がある。
また、「永久」とか、「天元」とか、既に別の意味がある単語も除外する必要がある。
他に、例えば「久永」という言葉は無かったとしても、
「久」も「永」も非常に近すぎる意味であるため、カッコよく無い。
仮説として、これまでの元号も、そうした文字のバランスを考慮しているのではないか?
全部の組み合わせパターンを試してみる、だと、AIが出している感が減ってしまうため、
AIに、過去の元号の文字の「距離感」を与えることにした。
元号としての組み合わせのバランスを「計算」する
まず、仮説が正しいのか確認するため、
過去の約250個の元号の、1文字目と2文字目の「距離」(コサイン類似度)を見る。
(※4文字で出来ている一部の元号は除外)
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
gengoulist = ["大化","白雉","朱鳥",・・・省略・・・"慶応","明治","大正","昭和","平成"]
distancelist=[]
for idx in range(0, len(gengoulist)):
distance = JPmodel.similarity(gengoulist[idx][0], gengoulist[idx][1])
distancelist.append(distance)
#折れ線グラフを出力
left = np.array(range(0, len(distancelist)))
height = np.array(distancelist)
plt.plot(left, height)
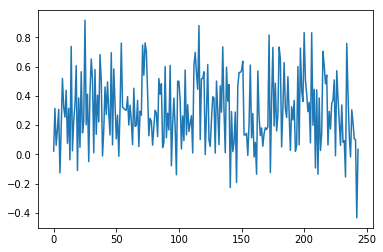
図の左端が「大化」、右端が「平成」で、それぞれ二文字の漢字の類似度をグラフ化したもの。
グラフを見ると、(最後の方の「昭和」が-0.43で極めて異例ではあるが)
ある程度一定の距離を保っている気がする。
つまり、仮説として、過去元号の距離感に近づく組み合わせにする、というのは、
良い案なのではないだろうか?
では実際に距離をいくつくらいにするべきなのか計算してみる。
from statistics import mean, median,variance,stdev
m = mean(distancelist)
median = median(distancelist)
variance = variance(distancelist)
stdev = stdev(distancelist)
print('平均: {0:.2f}'.format(m))
print('中央値: {0:.2f}'.format(median))
print('分散: {0:.2f}'.format(variance))
print('標準偏差: {0:.2f}'.format(stdev))
平均: 0.30
中央値: 0.28
分散: 0.06
標準偏差: 0.24
上記の結果より「0.3」を中心として、プラスマイナス「0.24」に入る範囲の、
漢字の組み合わせ方を探すことにする。
適切な距離感の漢字の組み合わせを探す
勝ち上がった漢字10文字×10文字の全100パターンを試して、
その漢字の距離感が上記の標準偏差の範囲内に入るような組み合わせを探す。
また、この機会に、既に過去の元号リストに全く同じものがある場合は除外する。
(また、「永永」などのように、同じ字を重ねた場合、距離=1.0になるため、自動的に除外)
そして、その結果を、最も適切な距離(平均値)である「0.3」に近い順に並べる。
finalkouho="永徳忠仁孝清久元正天"
#※前回実施のデータでTOP20⇒10にしていれば再定義する必要は無し。
hodoyoikyorilist=[]
for idxone in range(0, len(finalkouho)):
for idxtwo in range(0, len(finalkouho)):
distance = JPmodel.similarity(finalkouho[idxone][0], finalkouho[idxtwo][0])
if(0.30-0.24<distance and distance <0.30+0.24):
#0.3からの距離の絶対値を計算しておく。
absval = abs(distance-0.30)
kumiawase=finalkouho[idxone][0]+finalkouho[idxtwo][0]
#既存のgengoulistの中に含まれるパターンは、この時点で除外する。
if not(kumiawase in gengoulist):
hodoyoikyorilist.append([kumiawase, distance, absval])
#「0.3」という理想的な距離感(平均値)からの乖離が少ない順に並べる。
finalkouho_ranking = sorted(hodoyoikyorilist, key=lambda x:x[2], reverse=False)
import pprint
pprint.pprint(finalkouho_ranking)
[['忠天', 0.34512571556537058, 0.045125715565370594],
['天忠', 0.34512571556537058, 0.045125715565370594],
['清正', 0.3541912868235782, 0.054191286823578211],
['正清', 0.3541912868235782, 0.054191286823578211],
['久天', 0.35828565796442502, 0.058285657964425031],
['天久', 0.35828565796442502, 0.058285657964425031],
['元正', 0.38558117860512242, 0.085581178605122432],
['久正', 0.39211709853284332, 0.092117098532843333],
['正久', 0.39211709853284332, 0.092117098532843333],
['孝正', 0.39522379769497534, 0.095223797694975354],
['正孝', 0.39522379769497534, 0.095223797694975354],
['正天', 0.41378394594834822, 0.11378394594834823],
['清元', 0.47026353686028266, 0.17026353686028267],
['元清', 0.47026353686028266, 0.17026353686028267],
['清天', 0.47101191032529927, 0.17101191032529928],
['天清', 0.47101191032529927, 0.17101191032529928],
['孝天', 0.47803022604673118, 0.17803022604673119],
['天孝', 0.47803022604673118, 0.17803022604673119],
['仁正', 0.48142248276590699, 0.181422482765907],
['正仁', 0.48142248276590699, 0.181422482765907],
['元天', 0.50123434913804443, 0.20123434913804444],
['徳天', 0.51178692951545024, 0.21178692951545025]]
標準偏差の範囲内を合格としたため、結構幅を広くとったつもりだが、
およそ90パターンのうちで、上記22パターンしか生き残らなかった。
最後の仕上げ。ルールに沿った除外
ここまでで、以下2点のメイン部分が終了した。
* 良い意味の漢字を抽出する
* その漢字を組み合わせて、過去の元号と似た距離感の組み合わせを作る
最後に、コレまで機械にやらせるのはちょっと面倒ではあるが
以下2点の実装を行い、決定まで持っていこうと思う。
- 既に他の意味で使われている単語を除外
- M(明治)、T(大正)、S(昭和)、H(平成)と重複しない
既に他の意味で使われているか?Mecabで分解
Mecabによる形態素解析によって、
分かれる = 他の意味は無い。
分かれずに一語と認識 = 他の意味で認識された。
これを利用して、既存で別の意味があるかの判断基準とする。
ついでに、読み仮名も振っておくことで、あとでMTSH除外に使えるようにする。
単語を品詞分解する関数については、
前回の 「赤の他人」の対義語は「白い恋人」 これを自動生成したい物語 で、
「多摩動物公園」を分解するのに作った関数をちょっとだけ変えて再利用する。
import MeCab
def check_hinsi(taisyou_word):
mecab = MeCab.Tagger("-Ochasen")
#mecab = MeCab.Tagger(r"-Ochasen -d .\mecab-ipadic-neologd")
WordHinsi = []
#前処理:トリムなど。例「\t」はトリムしておく。全角スペース化
trline = taisyou_word.replace(u'\t', u' ')
#####メイン処理:
#Mecabでの解析を実施
parsed_line = mecab.parse(trline)
#分析結果を、1行(単語)ごとに分割する。改行コードで分割する。
wordsinfo_list = parsed_line.split('\n')
#状況を見る
#print(taisyou_word+"は"+str(len(wordsinfo_list))+"単語に分かれました")
#単語ごとに、解析処理に入れていく。
for wordsinfo in wordsinfo_list:
#print("wordsinfo= " + wordsinfo)
# 各単語の情報をタブで分割する。
# たき火,タキビ,たき火,名詞-一般 などのような1行が、list形式になる。
info_list = wordsinfo.split('\t')
#print(info_list)
#空白などの場合、三番目の要素が無い場合もあるため、
#最初にそのリストの長さをチェック
#以下のように無意味に3分割されるため、品詞情報が存在しないものは無視する。
#['コアラ', 'コアラ', 'コアラ', '名詞-一般', '', '']
#['EOS']
#['']
if(len(info_list)>2):
#info_list[1]が読み仮名が入る
WordHinsi.append((info_list[0], info_list[1], info_list[3]))
return WordHinsi
#check_hinsi("多摩動物公園")
#元号の候補にそれぞれ上記関数を適用してみる。
ffor idx in range(0, len(finalkouho_ranking)):
print(check_hinsi(finalkouho_ranking[idx][0]))
[('忠', 'チュウ', '名詞-一般'), ('天', 'テン', '名詞-一般')]
[('天', 'テン', '名詞-一般'), ('忠', 'タダシ', '名詞-固有名詞-人名-名')]
[('清正', 'キヨマサ', '名詞-固有名詞-人名-名')]
[('正清', 'ショウセイ', '名詞-固有名詞-地域-一般')]
[('久', 'ヒサ', '名詞-一般'), ('天', 'テン', '名詞-一般')]
[('天久', 'アメク', '名詞-固有名詞-人名-姓')]
[('元正', 'ガンショウ', '名詞-一般')]
[('久', 'ヒサ', '名詞-一般'), ('正', 'タダシ', '名詞-固有名詞-人名-名')]
[('正久', 'マサヒサ', '名詞-固有名詞-人名-名')]
[('孝正', 'タカマサ', '名詞-固有名詞-人名-名')]
[('正', 'セイ', '接頭詞-名詞接続'), ('孝', 'コウ', '名詞-一般')]
[('正', 'セイ', '接頭詞-名詞接続'), ('天', 'テン', '名詞-一般')]
[('清元', 'キヨモト', '名詞-一般')]
[('元', 'ゲン', '名詞-固有名詞-人名-姓'), ('清', 'キヨシ', '名詞-固有名詞-人名-名')]
[('清', 'セイ', '名詞-固有名詞-人名-姓'), ('天', 'タカシ', '名詞-固有名詞-人名-名')]
[('天', 'テン', '名詞-一般'), ('清', 'キヨシ', '名詞-固有名詞-人名-名')]
[('孝', 'コウ', '名詞-一般'), ('天', 'テン', '名詞-一般')]
[('天', 'テン', '名詞-一般'), ('孝', 'コウ', '名詞-一般')]
[('仁', 'ヒトシ', '名詞-固有名詞-人名-名'), ('正', 'タダシ', '名詞-固有名詞-人名-名')]
[('正', 'セイ', '接頭詞-名詞接続'), ('仁', 'ヒトシ', '名詞-固有名詞-人名-名')]
[('元', 'モト', '接頭詞-名詞接続'), ('天', 'テン', '名詞-一般')]
[('徳', 'トク', '名詞-一般'), ('天', 'テン', '名詞-一般')]
例えば、「清正」は既に人名として広まっているのでアウト!
「天久」とか、「孝正」なんかは一見まだセーフな気もするが、
人名などでも良く使われるようなパターンとして、Mecabに認識されているということで、
そういった語句は落とされるという考え方で良いと思う。
M(明治)、T(大正)、S(昭和)、H(平成)の除外
上記で機械が与えた読み方をチェックして、MTSHで始まっていないもの、を抽出する。
(ついでに、分解結果が1語のもの=既存意味のあるもの、は除外)
for idx in range(0, len(finalkouho_ranking)):
bunkaigo=check_hinsi(finalkouho_ranking[idx][0])
if not(bunkaigo[0][1][0] in "マミムメモタチツテトサシスセソハヒフヘホ"):
if len(bunkaigo)>1:
print(bunkaigo)
[('元', 'ゲン', '名詞-固有名詞-人名-姓'), ('清', 'キヨシ', '名詞-固有名詞-人名-名')]
[('孝', 'コウ', '名詞-一般'), ('天', 'テン', '名詞-一般')]
「元清」と「孝天」が出た。
※もし、この時点で全部候補が消えてしまったら、もう少し絞り条件を緩めて
再実施すればよい。また、もっと候補をたくさん出したい場合も同様。
最後のこの2点の優先度をどうするかであるが、
1点だけ後付けルールで申し訳ないが、「姓」や「名」で一字でも使われている字は、
実在の人物になってしまう可能性があるため、
「名詞一般」の組み合わせの方がよりポイントが高いということにする。
(まあ候補が二つでした、でも良いが、
機械が出したデータだけに依存した一位を決めたいため、
品詞判定結果=ポイント、とする)
そこで、「孝天」 > 「元清」 となった。
結果: AIに新元号を作らせるとこうなる
結果
超長い戦いだったが、とうとう最後の決定までたどり着いた。
AIが導きだした結果は、以下である。
結果:「孝天」
(次点:「元清」)
また、再度最終候補に挙がった漢字10文字を再度列挙しておく。
「永」:過去採用01位=29回
「徳」:過去採用13位=15回
「仁」:過去採用17位=13回
「忠」:AIが出した新顔
「清」:AIが出した新顔
「孝」:AIが出した新顔
「久」:過去採用22位=09回
「天」:過去採用02位=27回
「元」:過去採用02位=27回
「正」:過去採用06位=19回
あとで、「予想が当たったぜ~」って言うためには、
もっと多めに出しておいたほうが良いのだが。
(11位の「安」も可能性があるか?)
誰かが既に予想している元号にはしない、という説もあるため、
なんてひねくれた決め方だろうか
こういった記事を投稿する時点で絶対外れになる一方で、
元号考えるエライ人はqiitaは見ないんじゃね?
見てもこの超長い駄文&プログラムは分からないんじゃね?という気もする。
実際に新元号が発表されたら、
ぜひその漢字が本記事の方法で何位だったのか、後で確かめてみたい。
また、その2つの文字の距離も、0.3に近かったのか、計算してみたい。
結果が出たら、その結果も記事にするので見逃さないでね
使った数値的要素まとめ(チューニングポイント)
- 「2回以上過去元号に使用されたことのある漢字」をお手本とした。
- 当然2回というところは変更可能であるし、元号というのは、
- 採用までいかずに候補になったもの、もあるそうで、
- それらをターゲットに含めるかどうかでも調整が変わる
- 選んでくる対象を「教育漢字」にした点
- 「常用漢字」まで広げる方法もあるが、優先度としては「教育」>「常用」であり、
- 今回は多数の候補を出そうとしていなかったため、早めに「教育」に絞った
- 類似度の足切りの点数 = 0.6
- 0.7くらいの高めにしてもっと絞っても良さそうではあった。
- お手本に近い度合でトップ何位までを利用対象とするか? = 10
- 予想と称して沢山の候補をあげすぎるのが面倒/面白くないため、
- かなり絞った値だと思われる。
- 二つの漢字の距離感の適切値=0.3
- 今回は「平均値」を採用したが、「 中央値」を採用する方法もあるし、
- そもそも、「大化」の時代から全てのデータをみるようなことはせずに、
- 直近の何年かのデータだけでみるなどの方法もある。
- 品詞判定結果の辞書及び、その結果どのような品詞を優先/除外するか?
- 名詞一般 > 姓名、とした点や、二つに分かれたら除外なのかどうか。
- Mecabの分解辞書が変われば結果も変わる
- 除外の方法/基準
- 今回は「おくり名」は調査していない
- 現代であれば、Google検索してみて語句の普及度を見る方法もある
- Char2Vecのモデルの生成
- 今回はWikipediaをベースにしたが、元号の性質を考えると、
- 論語などの「四書や「五経」を学習させた結果も良いと思う。
あとがき
漢字そのもの、組み合わせそのもの、について、
全く人の良識/常識による判断を入れなくても、
パラメータ設定と機械学習だけで、
ある程度それっぽい新元号の案が作れたと思う。
新元号は誰が決めるのか良くわからないが、
平成が決まった時代よりはるかにインターネットが普及している現在では、
どんな元号にしようとも、Google検索で余計な意味付けが無いか、
入念な調査を要するだろう。
そしてどう発表しようとも、いろいろな人がSNSなどでその評価を好き勝手叫ぶ。
かつては全く考えられなかった、過去最大に難しい元号決定なのではないか?
各学者先生やエライ人のいろいろな調整や思惑が入るよりは、
予め定められた「基準」(今回でいうパラメータや、INPUTテキスト)をみなで同意して、
同意後に初めて一発勝負でプログラムを走らせて、TOP10くらいの候補を出させて、
その候補の中で投票するような仕組みのほうが、公明正大、
決め方に透明性があってみんなが納得するような気もする。
Word2VecやChar2Vecは、その演算だけでも面白がられるツールである。
ただ、ちょっと言葉の演算をして終わり、ではなく、
ぜひどういった「遊び」が考えられるのか、
人間の知恵を絞ると新たな世界が広がりそうである。
人間としては、AIに負けない「悪魔的発想」「圧倒的閃き」を目指したいものだ。
人類の進化は「遊び」からはじまる。
こんな「遊び」が出来るならば、というアイデアに触発される人がでて、
生活にも役に立つような「発明」が生まれるのだ。
~ Char Fuitter (1847~1912 オランダ) ~
2018/06/03 初版作成。(将来の答え合わせのため、日付を明記)
この物語はフィクションです。
登場する人物・団体・名称等は架空であり、
実在のものとは関係ありません。
Char Fuitter (チャー・フイター)は架空の人物です。