前回、以下の記事を書いた際に扱った「face-api.js」の話です。
●ml5.js の FaceApi(face-api.js の一部の機能を使える API)で扱える仕組み・モデルに関するメモ - Qiita
https://qiita.com/youtoy/items/932c1868b032e3a4dfa8
その中でも、ml5.js の FaceApi では扱えない仕組みとなっていた「Face Expression Recognition(表情認識)」の情報を見ていこうと思います。
サクッと試す
もし、face-api.js の「表情認識」の動作確認をしたいというだけなら、公式のデモにアクセスするのが一番簡単です。
公式デモにアクセスする
デモを試す場合、まずは公式のリポジトリの中にある項目「Click me for Live Demos!」をクリックして、face-api.js のデモページにアクセスしてください。
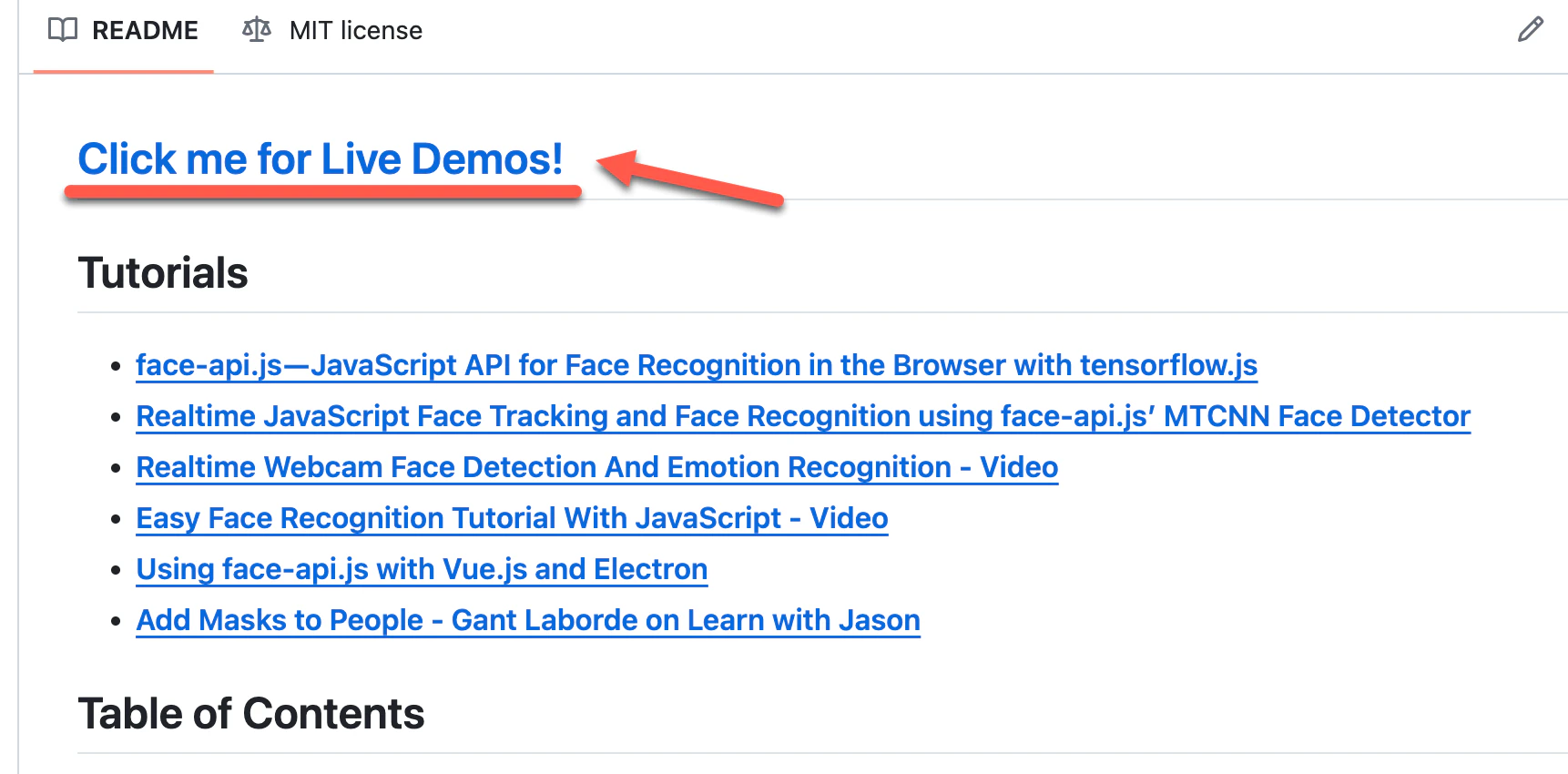
静止画に対する表情認識を試す
その後、デモページの左側のメニューにある「Face Expression Recognition」という項目を選びます。
そうすると、あらかじめ用意された複数の静止画に対して、表情認識の処理を行った結果を見ることができます。
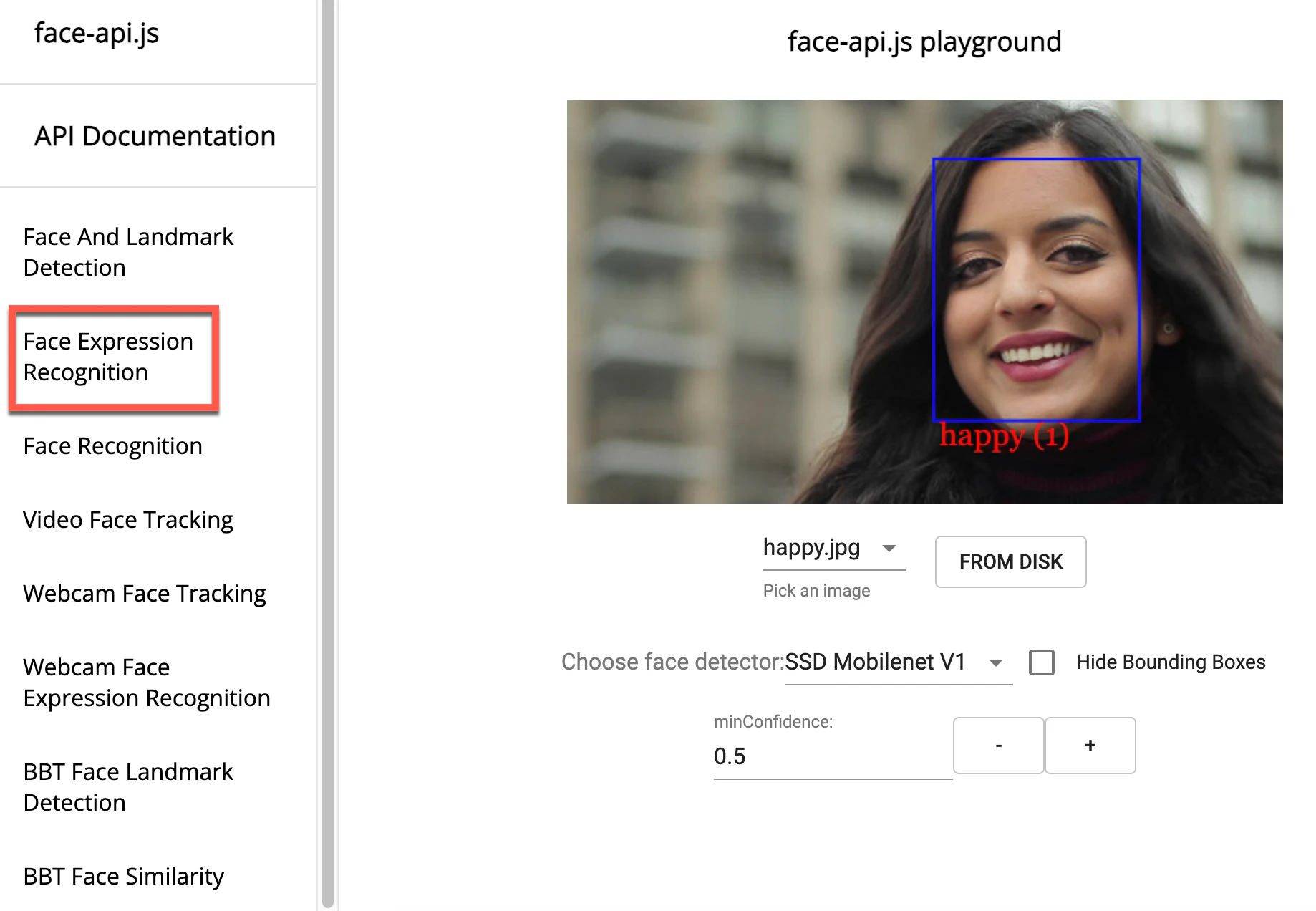
上記の例では「happy」という判定になっています。また、別の画像を選ぶと、それと違う結果を確認することもできます。
以下は「angry」と判定された例です。

選択できるモデルの種類
このページでも、画面の下のプルダウンメニューを選ぶことで、利用するモデルを変更できます。
以下が、そこで選べる選択肢です。

デフォルトは「SSD Mobilenet V1」が選択されています。それ以外で「Tiny Face Detector」「MTCNN」の 2つを選ぶことができます。
これらの違いについては、後で少し記載します。
動画に対するリアルタイム処理を試す
上で見たデモは、静止画に対して表情認識の処理を行っていました。それ以外に、デモの中には動画に対する処理を行えるものがあります。
それを試す場合は、ページの左側のメニューにある「WebCam Face Expression Recognition」という項目を選びます。

そうすると、カメラから入力された動画に対する表情認識の処理結果を確認できます。
選択できるモデルの種類
このページでは、画面の下のメニューで利用するモデルを変更できます。
以下が、そこで選べる選択肢です。
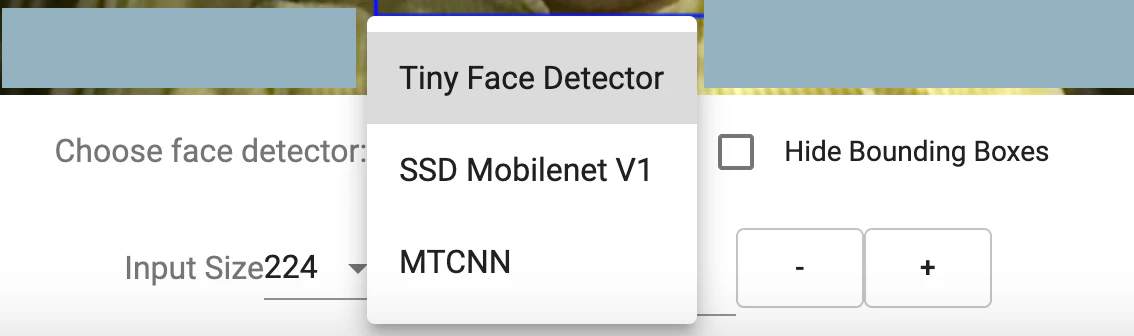
デフォルトは「Tiny Face Detector」が選択されており、それ以外で「SSD Mobilenet V1」「MTCNN」の 2つを選ぶことができます。
ここで選択肢に出てきている各モデルについて、簡単に内容を見てみることにします。
3つのモデルの情報を見てみる
公式リポジトリで、3つのモデルの情報を見てみます。
3つのうちの 2つは、「Available Models > Face Detection Models」の部分に説明が書いてあります。
具体的には、「SSD Mobilenet V1」「Tiny Face Detector」の 2つについてです。ざっくり、そこで書かれている内容を見ていきます。
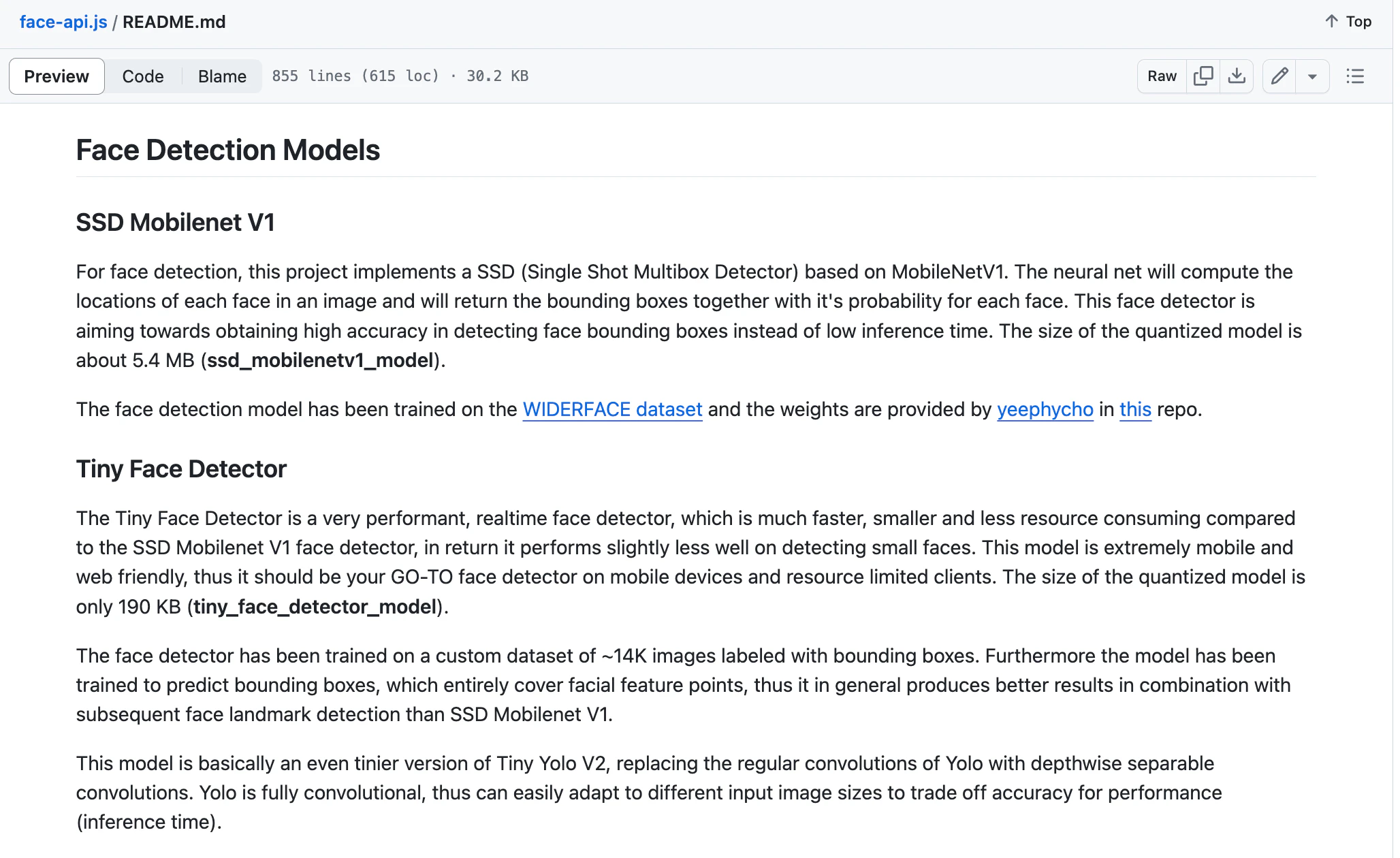
SSD Mobilenet V1 について
SSD Mobilenet V1 については、主に以下のような内容が書いてありました。
- SSD (Single Shot Multibox Detector) based on MobileNetV1
- 画像中の顔の場所を示すバウンディングボックスと、それに関する probability の値を出力する
- この仕組みは、推論時間を短かくしつつ顔のバウンディングボックスの検出精度は高くなるようにしている
- 量子化されたモデルのサイズは約5.4MB
- 検出モデルのトレーニングには、「WIDER FACEデータセット」を用いている
Tiny Face Detector について
Tiny Face Detector については、主に以下の内容が書いてあります。
- 上記の「SSD Mobilenet V1」と比べて、高速で、リソース消費も小さい
- モバイルデバイスなどの、リソースが限られているところでの利用に適する
- 量子化されたモデルのサイズはわずか 190KB
- バウンディングボックスに関して、顔の特徴点を完全にカバーするようにトレーニングしているため、一般的に SSD Mobilenet V1 よりも、この後の処理となる顔のランドマーク検出との組み合わせでより良い結果得られる
- 基本的に Tiny Yolo V2 のさらに小さなバージョン
MTCNN について
「MTCNN」についての情報も探してみます。
項目を見ていくと、「Tutorials > Realtime JavaScript Face Tracking and Face Recognition using face-api.js’ MTCNN Face Detector」という内容があります。

このリンクを選択すると、以下のページに遷移します。
●Realtime JavaScript Face Tracking and Face Recognition using face-api.js’ MTCNN Face Detector | by Vincent Mühler | ITNEXT
https://itnext.io/realtime-javascript-face-tracking-and-face-recognition-using-face-api-js-mtcnn-face-detector-d924dd8b5740
ページを少しスクロールすると、以下の記載があるようです。

これも SSD Mobilenet v1 と比べると、精度が低くなるものの、軽量な処理で顔検出ができるようです。長所として、以下の内容が書かれています。
- 推論時間が短い(検出速度が速い)
- 顔の中の 5つのランドマークを検出できる
- モデルサイズがわずか~2MB のサイズ
- 特定の要件に合わせてパフォーマンスを向上させるためのパラメータ調整ができる

処理速度について
上記を見ると、「SSD Mobilenet V1」と比べて「Tiny Face Detector」「MTCNN」は処理が軽い(その分、精度が犠牲になる)という感じの説明に思えます。
しかし一方で face-api.js のデモサイトの「WebCam Face Expression Recognition」を試すと、MTCNN が一番処理が重い感じがしました。
この 3つの違いについて、Qiita の以下の記事で比較が行われているのを見かけてました。その 3つを比較した結果でも「MTCNN」が一番処理が重い、という結果になっているようでした。
●face-api.jsの顔検出速度を比較してみた【技術メモ】【小ネタ】 - Qiita
https://qiita.com/U_sagi/items/137d70dabb046ec9bcd9
現時点では、「MTCNN」の位置付けがよく分からない状態になりました。
とりあえず、「Tiny Face Detector」が「SSD Mobilenet V1」の軽量版というのは、自分が試した感じでも上記の記事でも同じようなので、「MTCNN」はいったん除外をしてお試しを進めようかと思います。
表情認識の処理の流れ
次に処理のポイントになる部分を見てみます。
ポイントになる部分は、公式リポジトリの「Realtime Webcam Face Detection And Emotion Recognition - Video」というリンク先の「Build Real Time Face Detection With JavaScript」という動画で確認してみます。
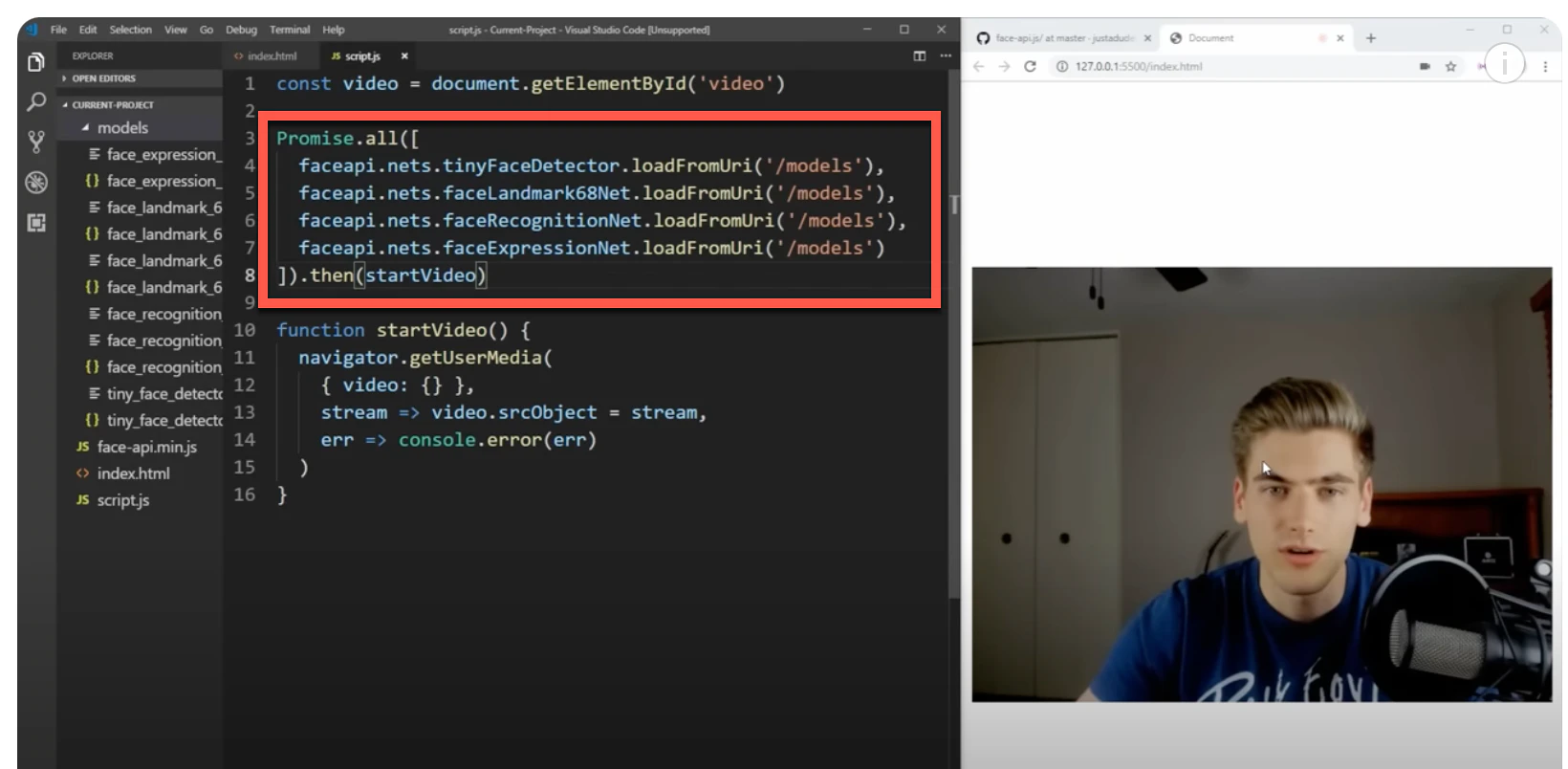
モデルの読み込み
モデルの読み込みは、以下の部分で示されていました。
ここでは 4つのモデルを読みこんでいます。モデルの名称や、この後に出てきているプログラムの内容的には、表情認識では「tinyFaceDetector」「faceLandmark68Net」「faceExpressionNet」の 3つがあれば良さそうな感じがします。
画像に対する処理
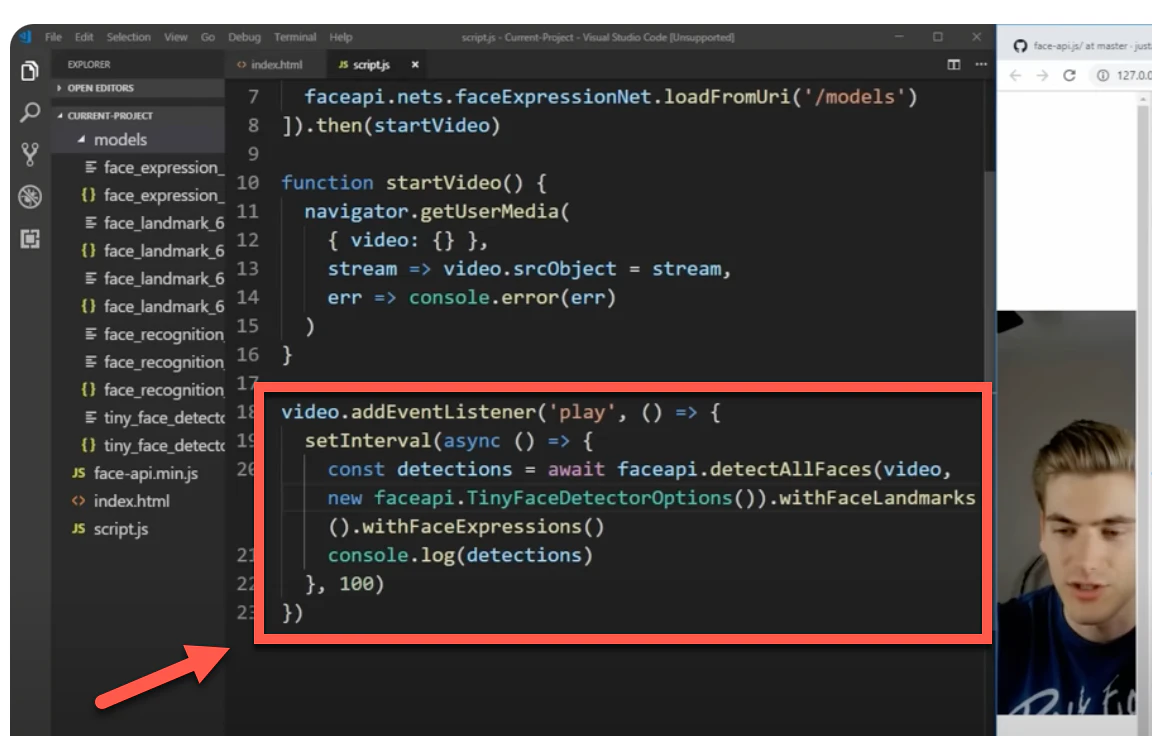
次に、画像に対する処理の流れを見てみます。
以下を見ると、「顔検出 ⇒ ランドマークを得る ⇒ 表情認識」という流れにすれば良さそうです。
表情認識にランドマークを得るのは不要?
この部分の処理について、Qiita で見かけた以下の記事での内容では、「tinyFaceDetector」「faceExpressionNet」の 2つと、「顔検出 ⇒ 表情認識」という処理の流れで良さそうかもしれません。
●顔出しをせずに表情だけを伝えることができるwebアプリを作った【Next.js+TypeScriptでface-api.jsを使って表情認識】 - Qiita
https://qiita.com/yuikoito/items/a494402993ac4be46d97
この部分は、別途、自分でプログラムを書いて検証してみようと思います。
p5.js との組み合わせでテスト実装
p5.js を使った描画との組み合わせで、テスト的に実装してみました。
試してみた結果、やはり表情認識のみ行えれば良いという場合は、モデルは以下の 2つのみで大丈夫でした(顔のランドマークを検出するモデルは不要でした)。
- モデル
- tinyFaceDetector
- faceExpressionNet