この記事は、Adventar の「なんでもCopilot Advent Calendar 2024」の 23日目の記事です。
はじめに
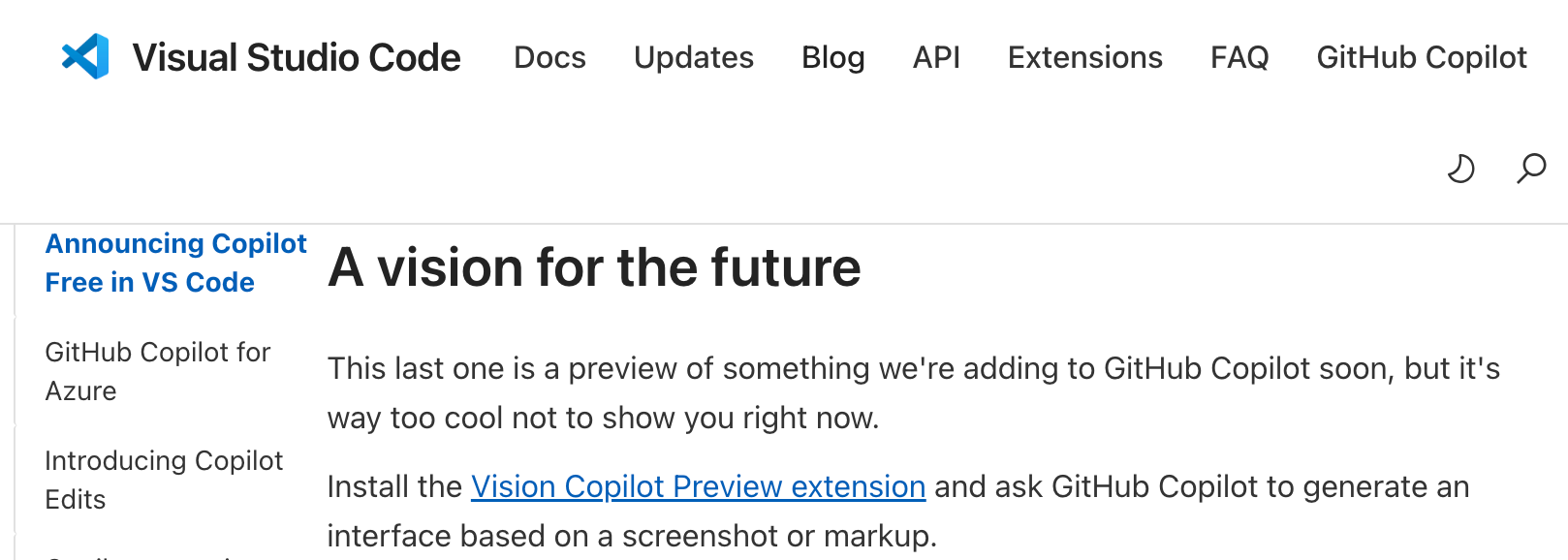
この記事は、以下の公式ブログ記事内で見かけた、Microsoft製の VSCode の拡張機能「Vision for Copilot Preview」に関するものです。
(以下の記事自体の主題は、GitHub Copilot の無償版提供に関するもの)
●Announcing a free GitHub Copilot for VS Code
https://code.visualstudio.com/blogs/2024/12/18/free-github-copilot
上記の記事内の「A vision for the future」という項目のところで、「Vision for Copilot Preview」の情報を見かけたのので、それを軽く試してみて記事も書いてみました。
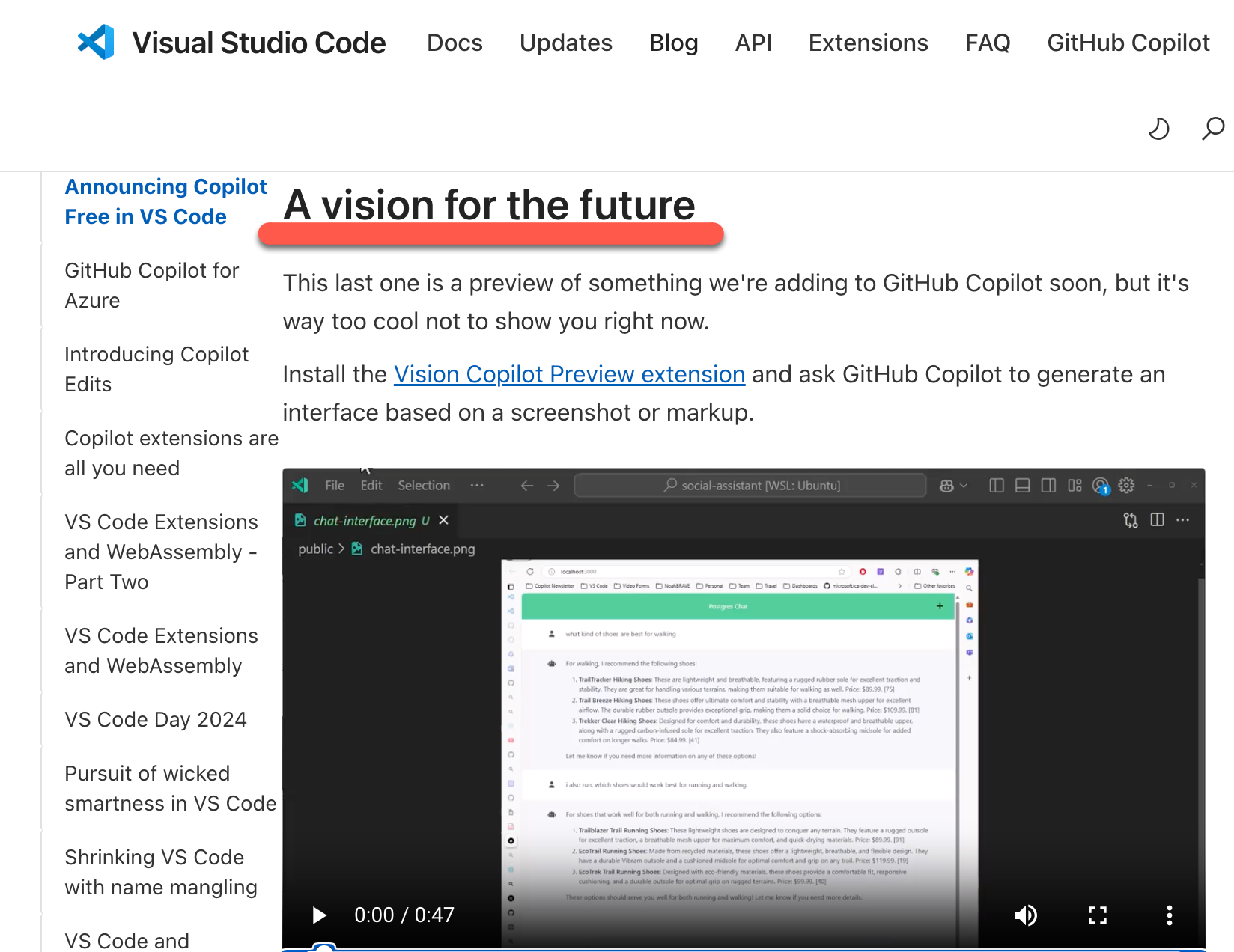
VSCode拡張機能「Vision for Copilot Preview」
マーケットプレイス上の「Vision for Copilot Preview」のページを見てみます。
●Vision for Copilot Preview - Visual Studio Marketplace
https://marketplace.visualstudio.com/items?itemName=ms-vscode.vscode-copilot-vision
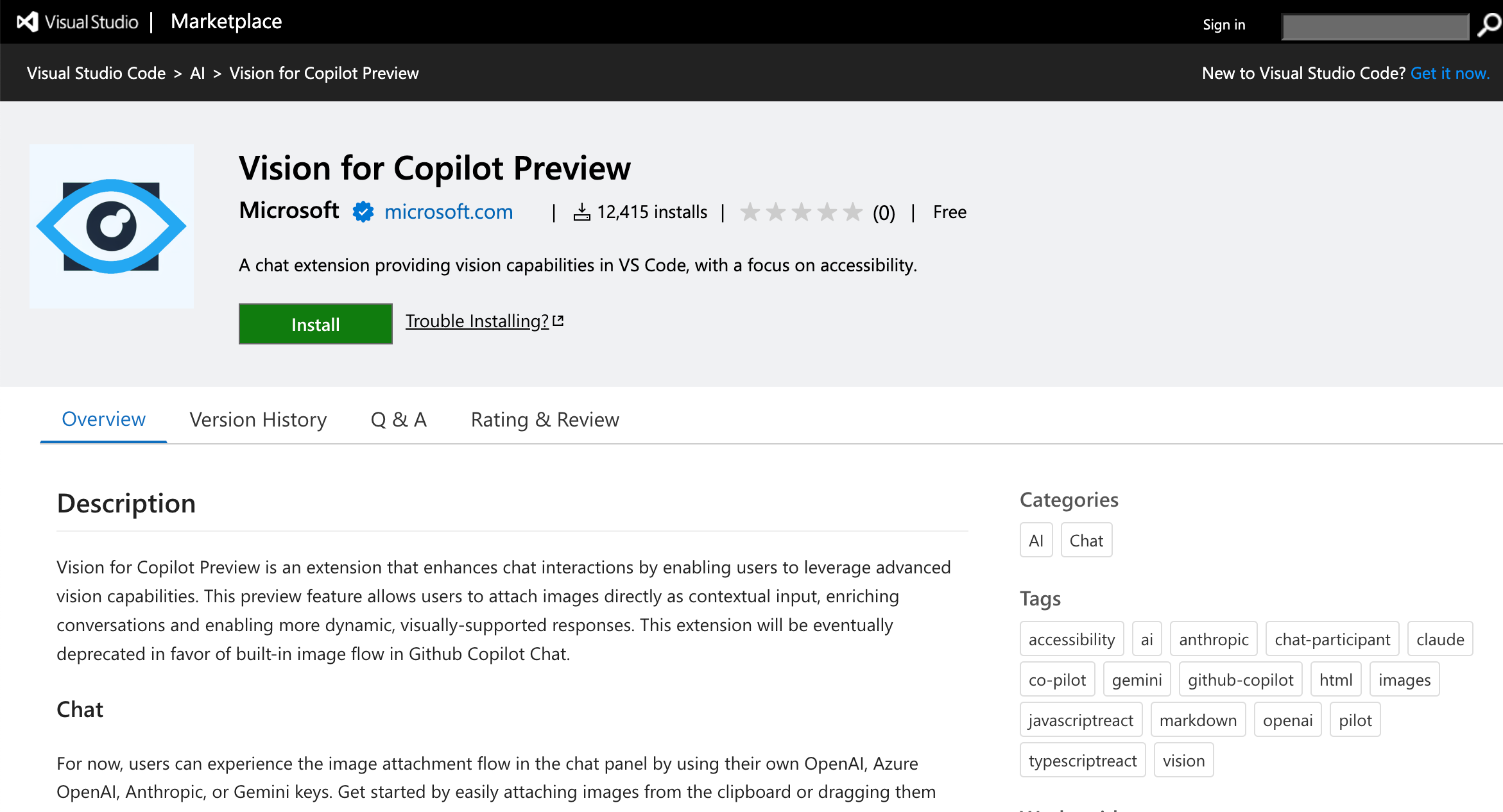
概要説明などが掲載されています。
また、GitHub のリポジトリは以下となるようです。
●microsoft/vscode-copilot-vision: Exploration into leveraging vision capabilities of an LLM
https://github.com/microsoft/vscode-copilot-vision
コマンドなど
VSCode上でも拡張機能のページを見てみました。
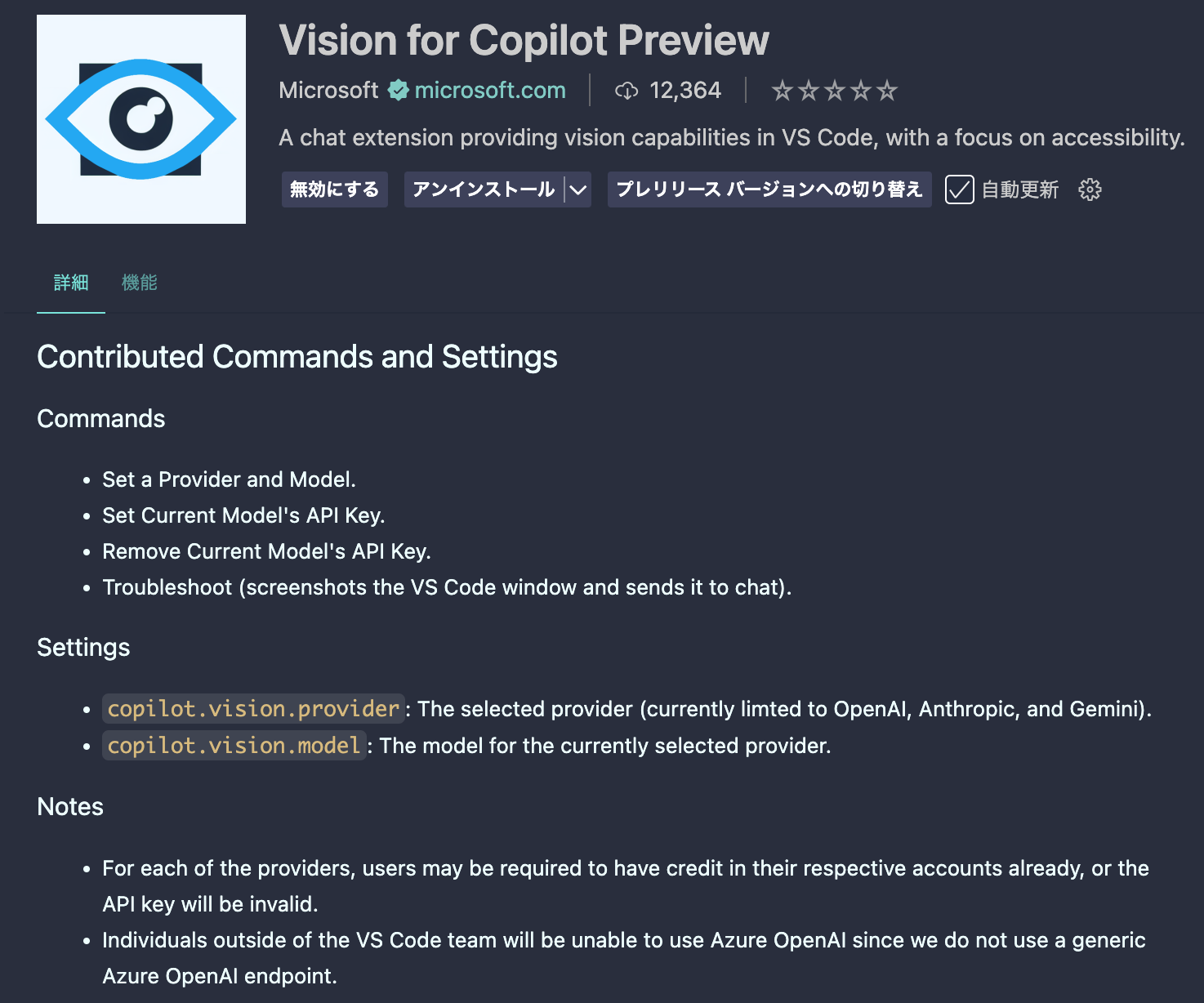
利用可能なコマンドとしては、以下の記載がありました。
- Set a Provider and Model
- Set Current Model's API Key
- Remove Current Model's API Key
- Troubleshoot (screenshots the VS Code window and sends it to chat)
これを見ると、GitHub Copilot が標準で画像入力を受け付けるのではなく、別途自分が用意した APIキーを使って API を利用する構成のようです。
また以下の設定の部分を見ると、モデルのプロバイダーとして現状で選べるのは「OpenAI、Anthropic、Gemini」になるようです。
copilot.vision.provider: The selected provider (currently limted to OpenAI, Anthropic, and Gemini).
copilot.vision.model: The model for the currently selected provider.
実際に使ってみる
実際に試してみます。
設定コマンドを実行してみる
まずは、VSCode のコマンドパレットから設定用のコマンドを実行してみます。

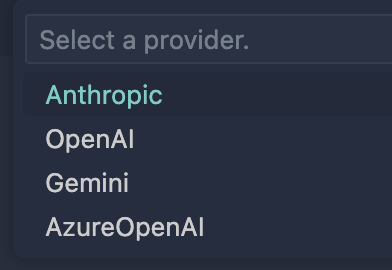
プロバイダーとモデルの設定
プロバーダーは、記事執筆時点では以下が出てきました。
そして、プロバイダーを選んだ後のモデル設定の画面は以下です。
デフォルトで gpt-4o が設定されているようで、それが入力欄に表示されつつ説明書きにいくつかのモデルが例示されていました。

とりあえず、プロバイダー「OpenAI」・モデル「gpt-4o」で設定してみました。
その後に、APIキーの入力を求められたので、自分の OpenAI のアカウントで設定している APIキーを入力しました。
画像を入力してみる
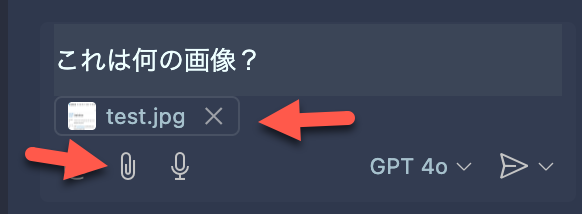
それでは以下のキャプチャ画像を入力として用い、VSCode上での GitHub Copilot を用いたお試しをやってみます。
GitHub Copilot Chat を開いて、画像を添付します。
そして、「この画像は何?」というシンプルなプロンプトを入れてみました。
それを送信すると、以下のように「Vision」という名称での回答が返ってきました。
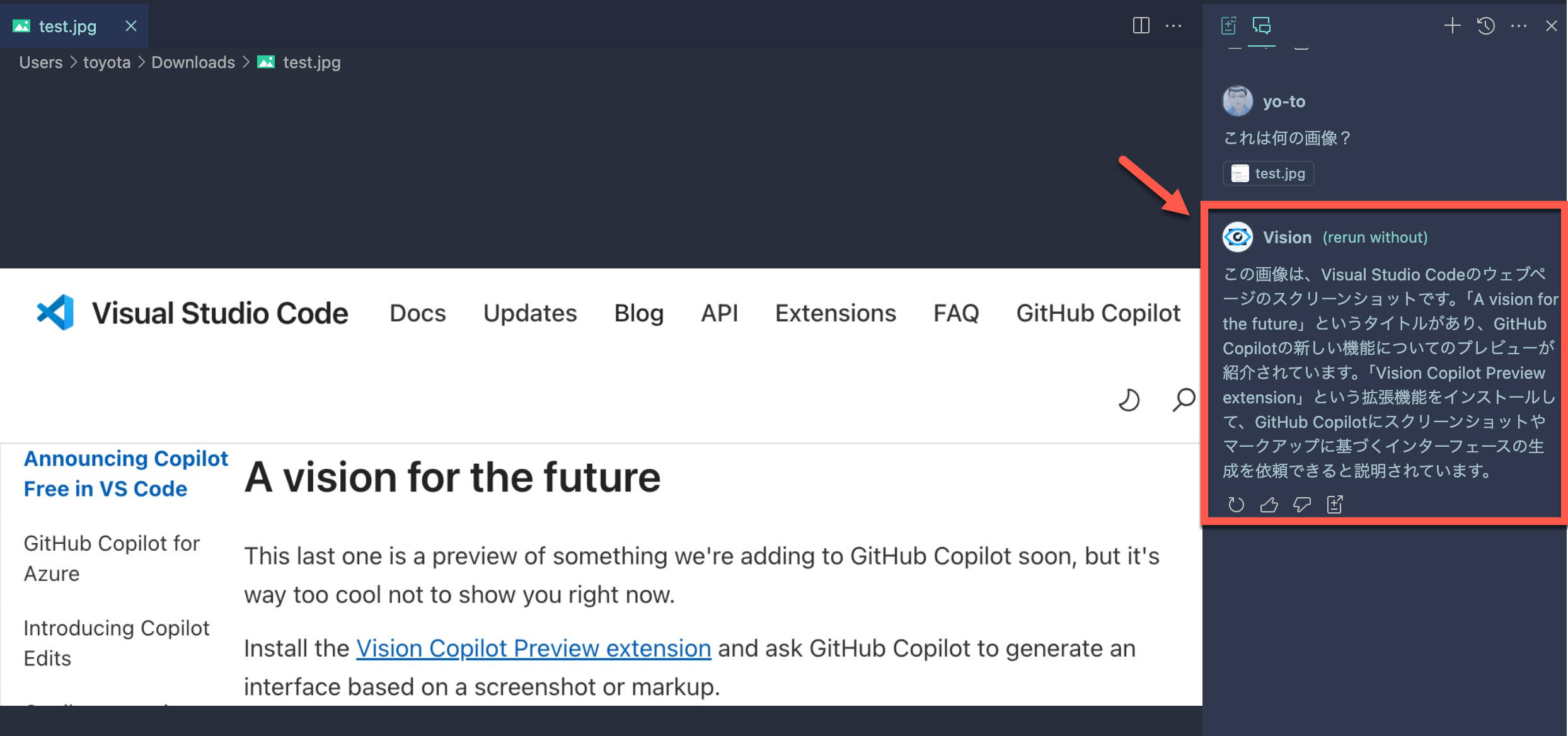
回答で返ってきた内容は、以下のとおりです。
この画像は、Visual Studio Codeのウェブページのスクリーンショットです。「A vision for the future」というタイトルがあり、GitHub Copilotの新しい機能についてのプレビューが紹介されています。「Vision Copilot Preview extension」という拡張機能をインストールして、GitHub Copilotにスクリーンショットやマークアップに基づくインターフェースの生成を依頼できると説明されています。
画像の説明が行われていることが確認できました。
確認をいくつか
上記が API経由で処理されたものか、また「Vision for Copilot Preview」を有効にしていない場合はどうなるかをそれぞれ試してみます。
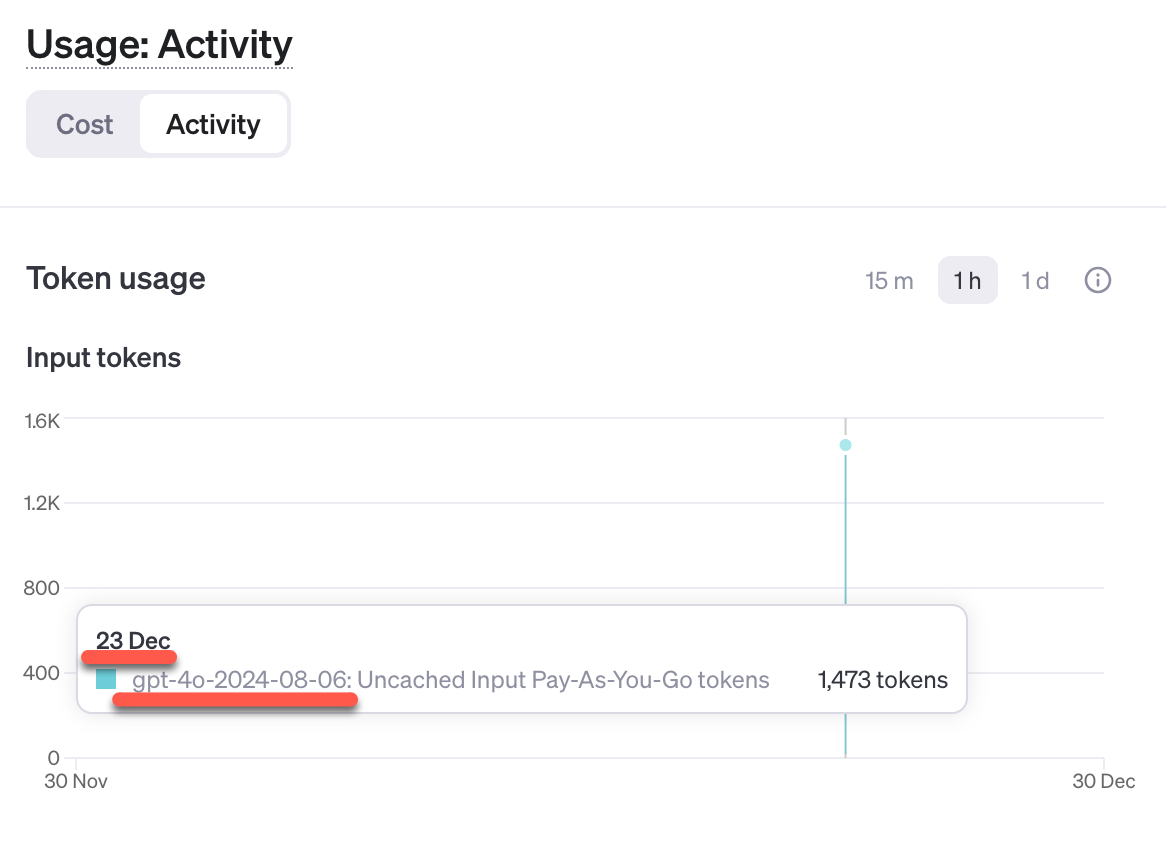
API が利用されたかを確認
OpenAI API の「Usage: Activity」のページを見てみます。
以下のとおり、記事執筆時点での gpt-4o の API利用のログが残っていました。
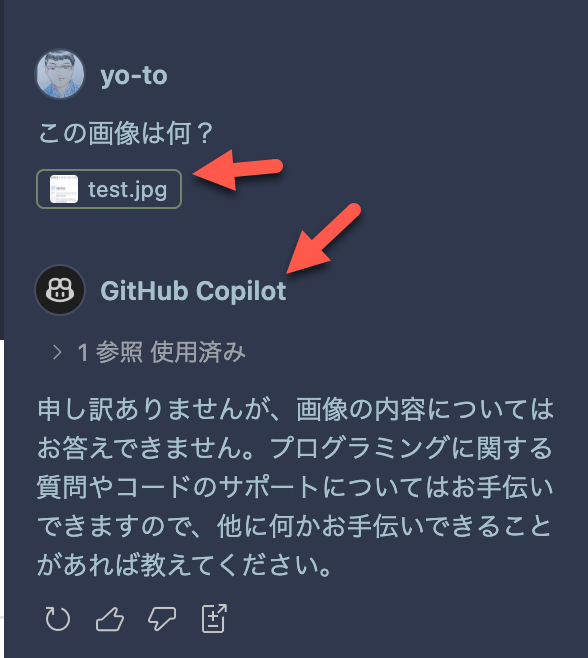
「Vision for Copilot Preview」が有効ではない場合
あとは、「Vision for Copilot Preview」を無効化した状態で、どんな回答が返ってくるかを試してみました。
結果は以下のように、GitHub Copilot が回答する形となり、画像内容は回答できないという内容になりました。
その他
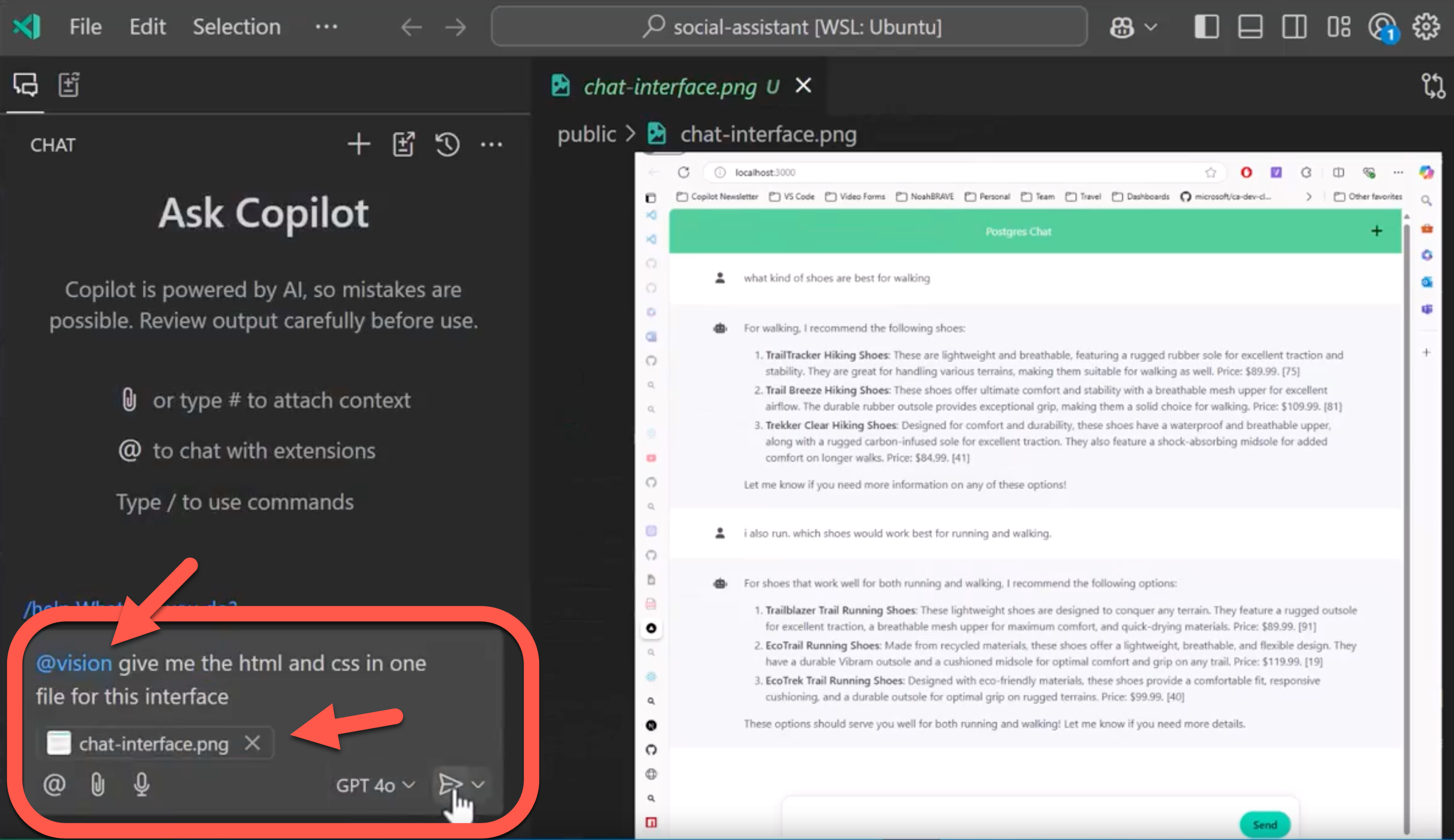
公式のデモ動画の環境
その他、自分が「Vision for Copilot Preview」の公式情報を見た動画では、以下のような @vision という内容を付与してプロンプトを入力しているようでした(こちらは、キャプチャ画像左上のアイコン的に、インサイダービルドで利用しているもののようです ⇒ 自分が今回使っているのは安定版です)。
他の API
プロバイダー・モデルのところで Gemini を使えば、ある程度は画像入力の処理も無料枠でできたりするかも?
●Gemini モデル | Gemini API | Google AI for Developers
https://ai.google.dev/gemini-api/docs/models/gemini?hl=ja
【2024/12/28追記】
その後、 Gemini 2.0 Flash との組み合わせも試して、以下の記事を書いてみました。
●Microsoft製の「Vision for Copilot Preview」と Gemini 2.0 Flash の組み合わせ:GitHub Copilot での画像入力【GitHub dockyard-2】 - Qiita
https://qiita.com/youtoy/items/f5fb3e7e937edf94f180