この記事の内容は、オフラインでリアルタイム音声認識ができ、日本語にも対応している以下の「VOSK」を試してみた話です。
●VOSK Offline Speech Recognition API
https://alphacephei.com/vosk/
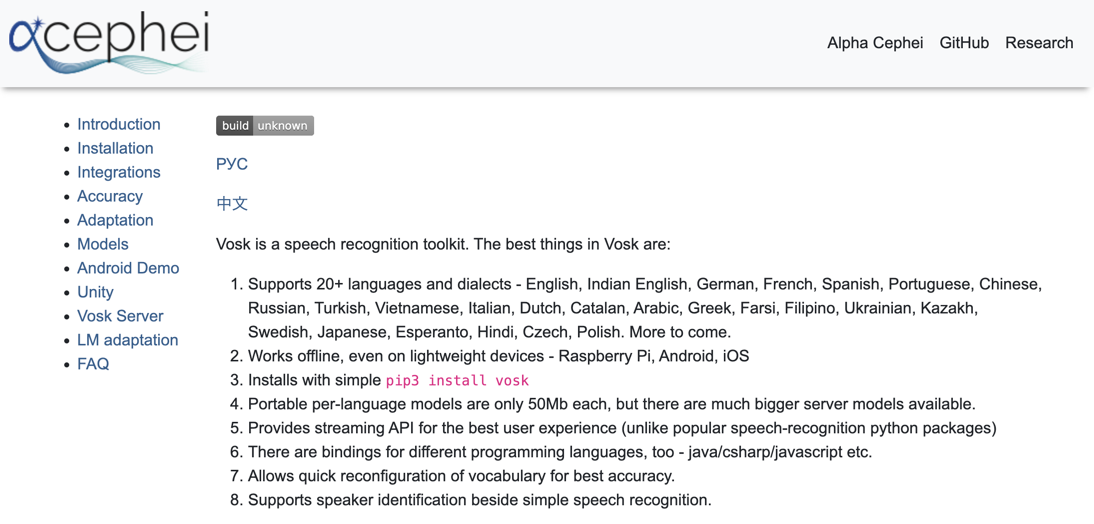
そして今回の記事で、VOSK を扱う開発言語・環境は「JavaScript(Node.js)」です(自分がよく使っているから、という選定理由です)。
なお、対応している他の開発言語などは、公式ページの「Installation」を見ると確認でき、例えばスマホ向け(Android・iOS)や Python・Java・C# などもあるようです。
VOSK を「JavaScript(Node.js)」で扱う
それでは、タイトルや冒頭にも書いた JavaScript(Node.js)で VOSK を扱う話へと進んでいきます。
公式ドキュメントの情報を確認する
公式ページ内の「Installation」で、以下の「Javascript/Nodejs」と書かれた部分を見ていきます。
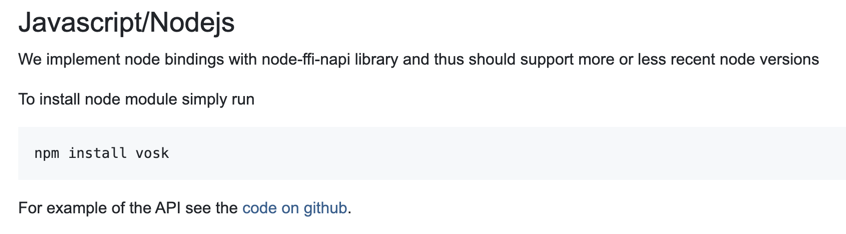
上記のキャプチャ画像のとおり、準備はとてもシンプルです。
以下の npmコマンドを実行するのみ、となります。
% npm install vosk
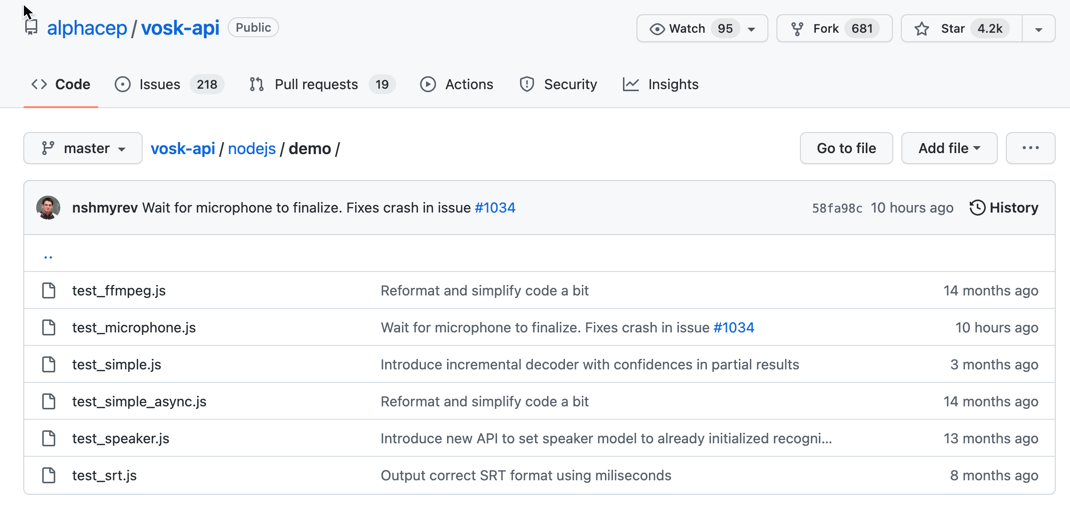
また、JavaScript用のサンプルが GitHub の以下にあるという情報が書かれています。
https://github.com/alphacep/vosk-api/tree/master/nodejs/demo
まずは軽いお試し
マイクからの入力を利用するサンプルをそのまま利用してみる
上記のサンプルの中で、まずは 1つを選んで試してみます。
マイクから入力して動かしてみたかったので、それができそうな名前の「test_microphone.js」を試すことにしました。
●vosk-api/test_microphone.js at master · alphacep/vosk-api
https://github.com/alphacep/vosk-api/blob/master/nodejs/demo/test_microphone.js
それでは、npmコマンドでパッケージのインストールを行い、その後に上記のサンプルを nodeコマンドで実行してみます。
サンプルに関して、最初の行の var vosk = require(".."); を var vosk = require("vosk"); に書きかえるということだけは、実行前に対応しました。

そうすると、上記のとおり Please download the model from https://alphacephei.com/vosk/models and unpack as model in the current folder. というメッセージが表示されました。
どうやら https://alphacephei.com/vosk/models という URL にアクセスし、音声認識用の機械学習モデルをとってくる必要があるようです。
日本語音声用の機械学習モデルを取得
それでは、上で出てきた URL にアクセスし、機械学習モデルを取得することにします。
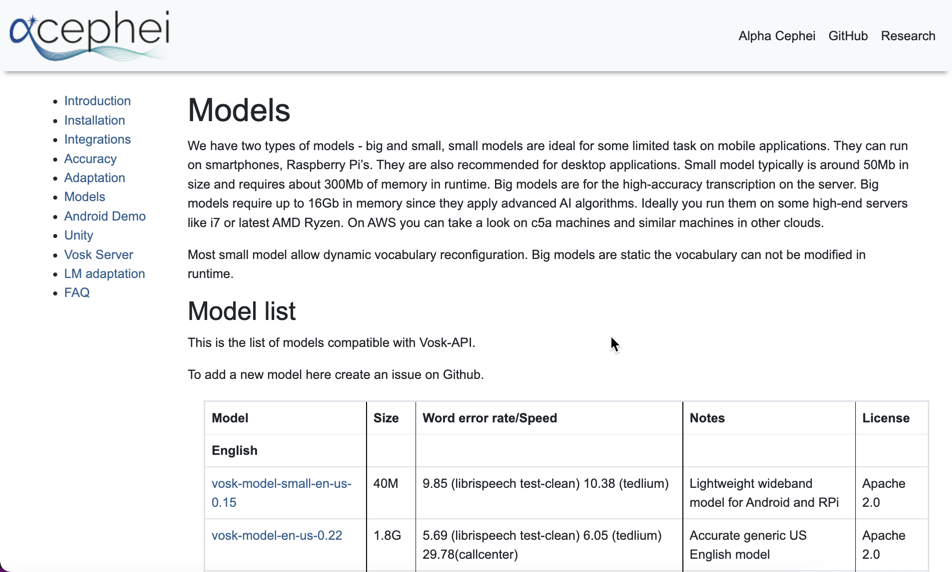
上記のページの「Model list」を下へたどっていくと、日本語用の「vosk-model-small-ja-0.22」という項目がありました。

この部分をクリックすると、「vosk-model-small-ja-0.22.zip」という名前の ZIPファイルがダウンロードでき、その ZIPファイルを解凍すると以下のファイルなどを得られました。
それでは、ここで得られたファイルなどを使って、お試しの続きを進めていきます。
サンプルを使ったお試しの続き(音声認識が実行できた状態)
先ほどのサンプルの JavaScript の処理をあらためて見てみると、 MODEL_PATH = "model"; という部分があるため、nodeコマンドを実行したフォルダと同じ階層に「model」という名前のフォルダを作成し、そこに ZIPファイルを解凍して得られたファイル一式を置けば良さそうに見えます。
そのようにしてみてから、再度、nodeコマンドでサンプルを実行してみると、以下のように日本語の音声認識の出力を得ることができました。
(ちなみに、この時にテストでしゃべった内容は「マイクのテスト」⇒「日本語の音声認識のテスト」⇒「マイクのテスト」という 3つの文で、適当な間を空けてしゃべりました)
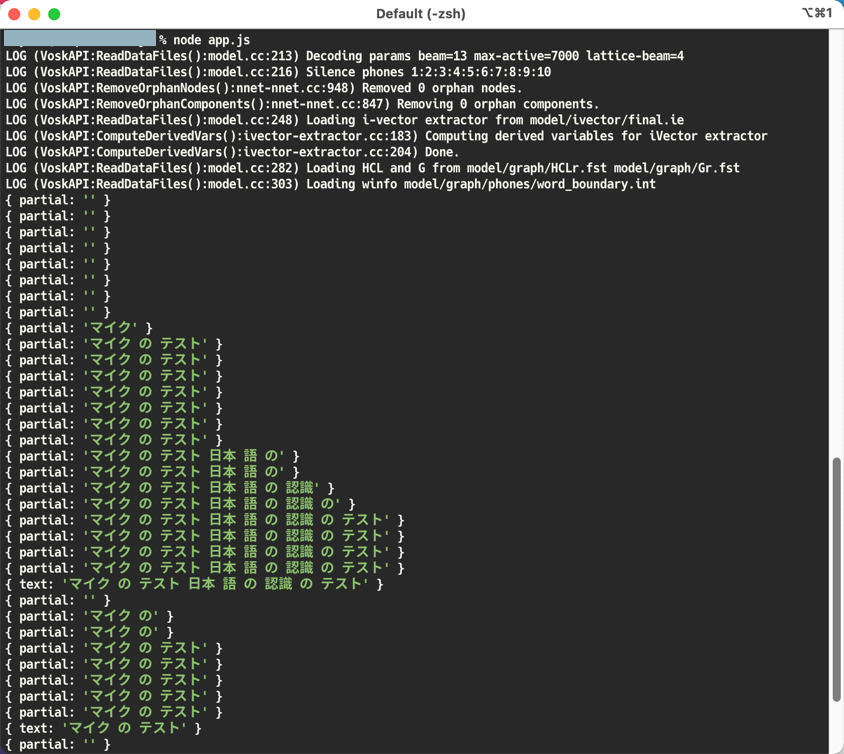
結果を見てみると、しゃべった内容がうまく認識され、テキストで出力されているのが分かります。
さらに、少ししゃべる内容を変えた別のお試しもやってみました。
こちらは動画で処理の様子をキャプチャしたものですが、画面キャプチャソフトの設定で、デスクトップ上の画面キャプチャと PC のマイク入力とを、合わせて 1つの動画に収録しています。
動画の中でマイクにしゃべっている内容は、「オフラインでのマイク入力の音声認識を試します」⇒「マイクのテストです」⇒「日本語の音声認識のテストです」となっています。
とりあえずの簡単なお試しでしたが、この内容なら精度・処理速度もすごく良い感じでした。
さらに、これを活用した作品を作ってみたいな。
用いたプログラム(書きかえ前の内容もコメントアウトして残したもの)
今回実行した、JavaScript(Node.js)のプログラムを以下に書いておきます。
上で書いていたように、冒頭の1行目を書きかえただけで、あとは元のサンプルそのままです(個人的には、ちょこちょこ書き直したい部分とかがある...)。
// var vosk = require("..");
var vosk = require("vosk");
const fs = require("fs");
var mic = require("mic");
MODEL_PATH = "model";
SAMPLE_RATE = 16000;
if (!fs.existsSync(MODEL_PATH)) {
console.log(
"Please download the model from https://alphacephei.com/vosk/models and unpack as " +
MODEL_PATH +
" in the current folder."
);
process.exit();
}
vosk.setLogLevel(0);
const model = new vosk.Model(MODEL_PATH);
const rec = new vosk.Recognizer({ model: model, sampleRate: SAMPLE_RATE });
var micInstance = mic({
rate: String(SAMPLE_RATE),
channels: "1",
debug: false,
device: "default",
});
var micInputStream = micInstance.getAudioStream();
micInputStream.on("data", (data) => {
if (rec.acceptWaveform(data)) console.log(rec.result());
else console.log(rec.partialResult());
});
micInputStream.on("audioProcessExitComplete", function () {
console.log("Cleaning up");
console.log(rec.finalResult());
rec.free();
model.free();
});
process.on("SIGINT", function () {
console.log("\nStopping");
micInstance.stop();
});
micInstance.start();
【追記】 記事公開後の追加のお試し
記事を公開した後、上で用いていたサンプルの中身を見直してみました。
そして、ここで得られた音声認識の結果を使った、何らかの続きの処理を付け加えていくために、その下準備となることを少しやってみました。
サンプルプログラムのちょっとした書きかえ
サンプルを見ていて、 micInputStream.on() という処理の中の rec.result() を使ってやると良さそうかと思い、以下のような書きかえをして実行してみました(あと、所々で var が混じってたのが気になったので、その部分の書きかえもしてみたり)。
const vosk = require("vosk"),
fs = require("fs"),
mic = require("mic");
const MODEL_PATH = "model",
SAMPLE_RATE = 16000;
if (!fs.existsSync(MODEL_PATH)) {
console.log(
"Please download the model from https://alphacephei.com/vosk/models and unpack as " +
MODEL_PATH +
" in the current folder."
);
process.exit();
}
vosk.setLogLevel(0);
const model = new vosk.Model(MODEL_PATH),
rec = new vosk.Recognizer({ model: model, sampleRate: SAMPLE_RATE });
const micInstance = mic({
rate: String(SAMPLE_RATE),
channels: "1",
debug: false,
device: "default",
});
const micInputStream = micInstance.getAudioStream();
micInputStream.on("data", (data) => {
if (rec.acceptWaveform(data)) {
const recognizedResult = rec.result();
const recognizedText = recognizedResult.text;
console.log(recognizedResult);
console.log(recognizedText);
} else console.log(rec.partialResult());
});
micInputStream.on("audioProcessExitComplete", function () {
console.log("Cleaning up");
console.log(rec.finalResult());
rec.free();
model.free();
});
process.on("SIGINT", function () {
console.log("\nStopping");
micInstance.stop();
});
micInstance.start();
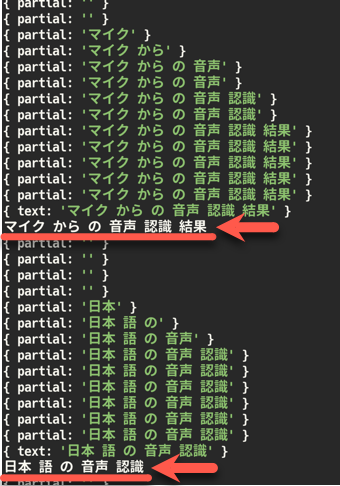
書きかえ後のプログラムを動かしてみたところ、以下の矢印で示した部分で、認識結果を取り出せているのが分かります。
あとは、結果の文字列にスペースが入っているように見えるので、それは除去する必要がありそうです。
そして、認識結果の中に何か特定のキーワードが含まれるかをチェックして、そのキーワードの有無に合わせた処理をするとか、そういったことをやれば良さそうかな。
【追記2】 日本語音声用のビッグモデルの追加
Twitter で情報を見かけて知ったのですが、ビッグモデルが追加されたようです。