はじめに
2024/10/18 の公式からのポストで「OpenAI の Chat Completions API でオーディオを扱う機能がリリースされた」という話が投稿されていました。
今月始めにオーディオ系APIで「Realtime API」が出ていましたが、それとは別のもののようです。
●Introducing the Realtime API | OpenAI
https://openai.com/index/introducing-the-realtime-api/
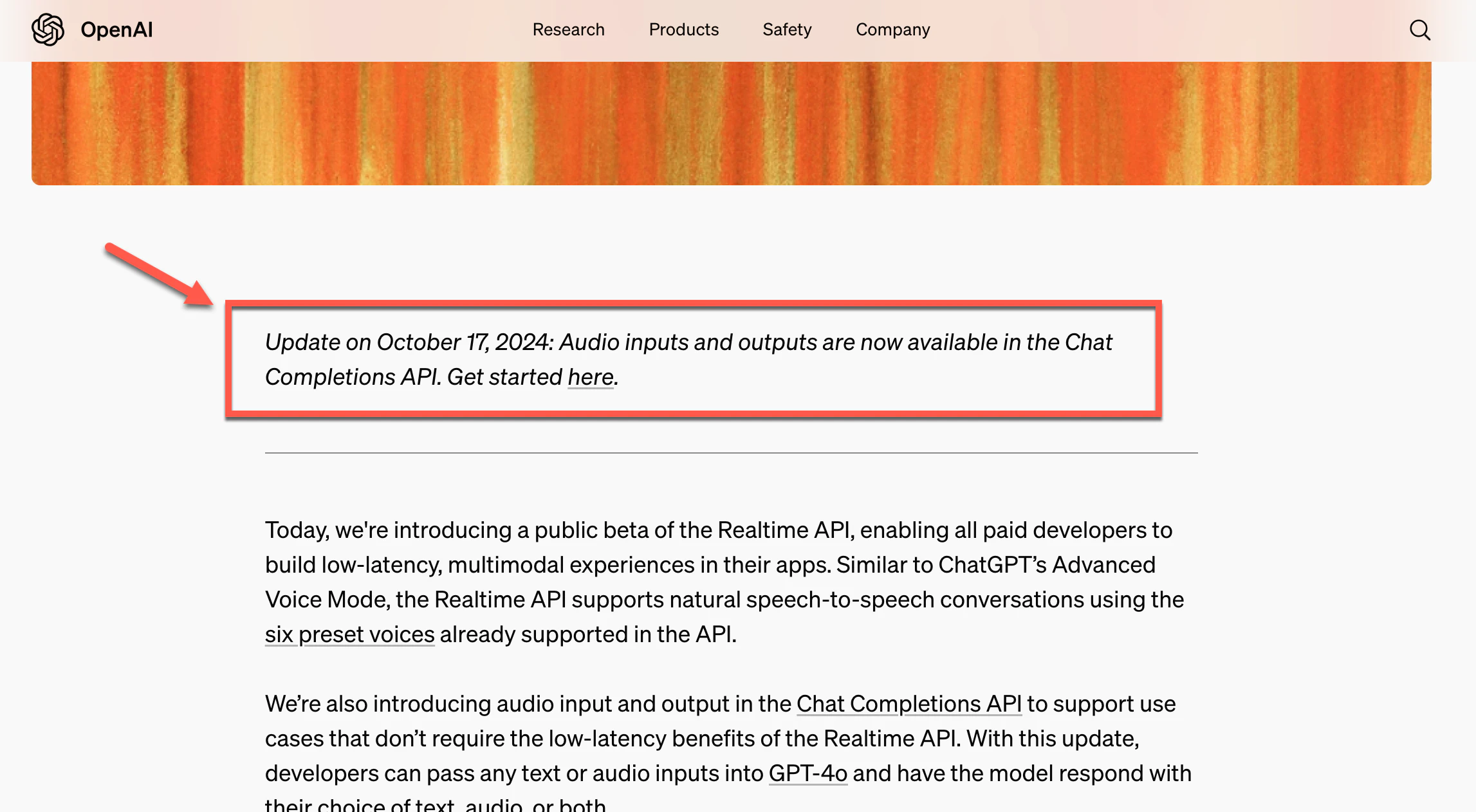
上記の Realtime API に関する記事の冒頭を見ると、下記の記載が追記されていたようでした。
「Update on October 17, 2024: Audio inputs and outputs are now available in the Chat Completions API. Get started here(opens in a new window).」
公式ドキュメントの情報
APIドキュメントの該当箇所
上で紹介した公式のポストでも、Realtime API の記事の冒頭に追加されていたテキストでも、Chat Completions API でオーディオを扱う機能に関するリンクとして、以下のページへのリンクが掲載されていました。
●Audio generation - OpenAI API
https://platform.openai.com/docs/guides/audio
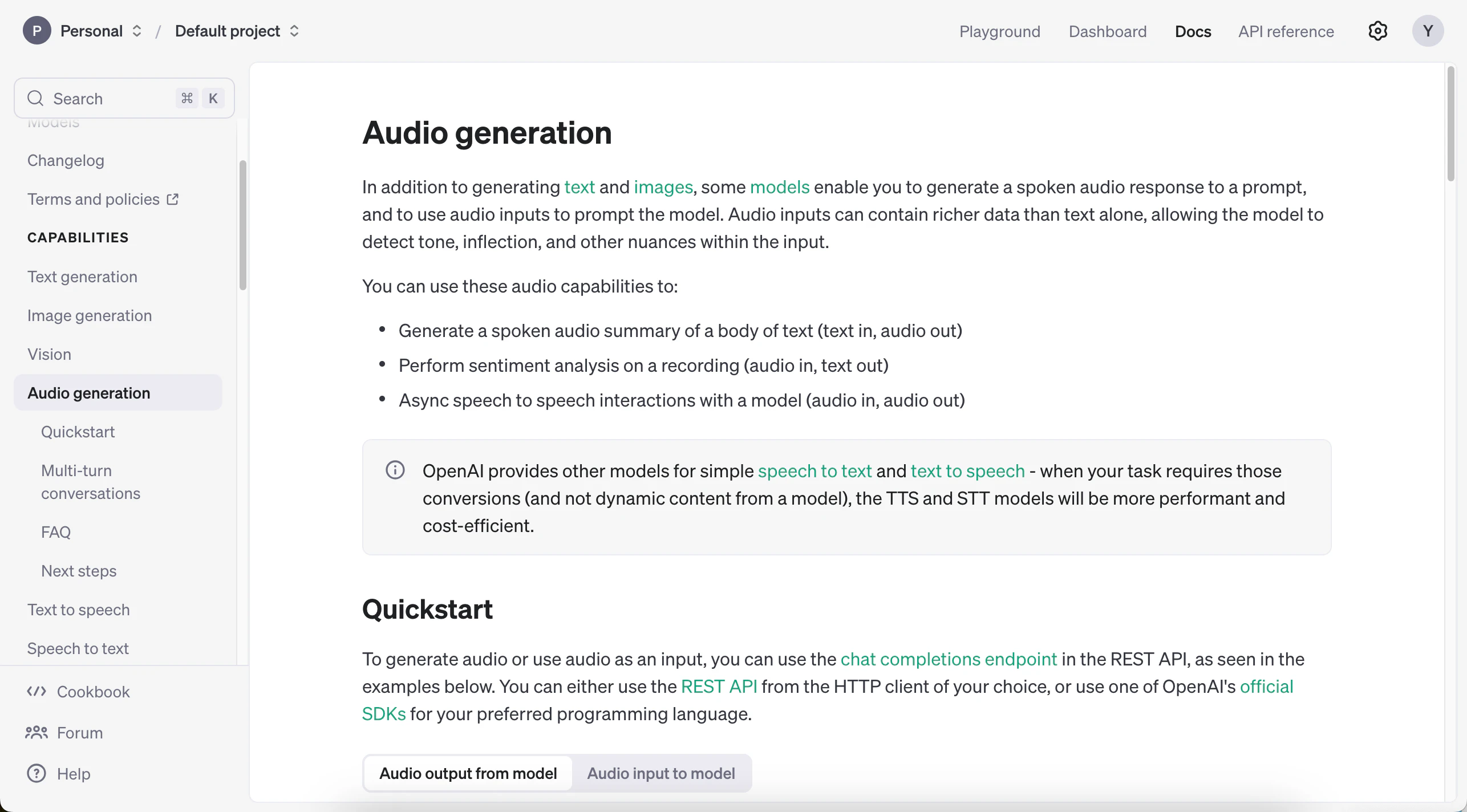
冒頭に箇条書きとともに書いてある説明を抜粋して、少し訳をつけてみます。
- You can use these audio capabilities to:
- Generate a spoken audio summary of a body of text (text in, audio out): 【テキスト入力、オーディオ出力】テキストの要約を音声で出力する
- Perform sentiment analysis on a recording (audio in, text out): 【オーディオ入力、テキスト出力】録音されたオーディオに対して感情分析を行う
- Async speech to speech interactions with a model (audio in, audio out): 【オーディオ入力、オーディオ出力】モデルとの非同期の音声のやりとりをする
単純な音声合成や音声認識を行う場合
その下には、単純に音声合成や音声認識をやるだけなら、以前から提供されている API を使うほうがコストが安い、という注意書きも書かれていました。
以前からある API、というのは以下のものです。
●Speech to text - OpenAI API
https://platform.openai.com/docs/guides/speech-to-text
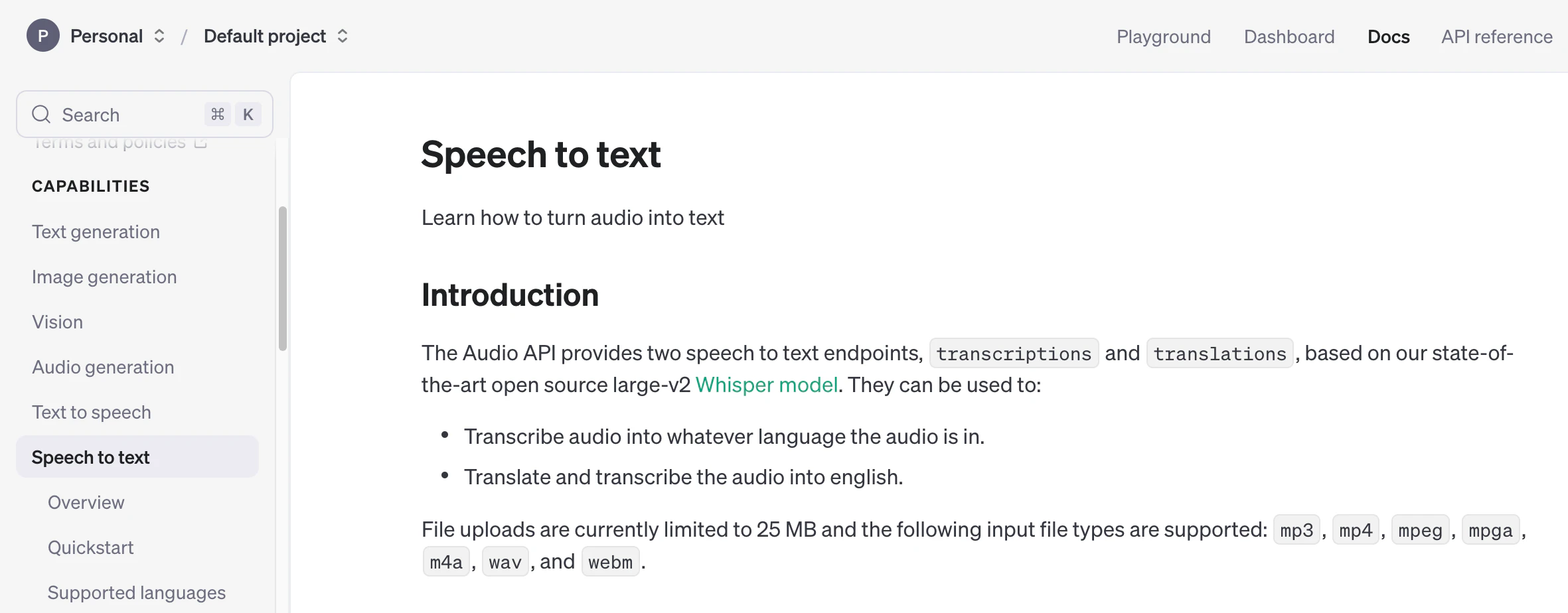
●Text to speech - OpenAI API
https://platform.openai.com/docs/guides/text-to-speech
クイックスタート
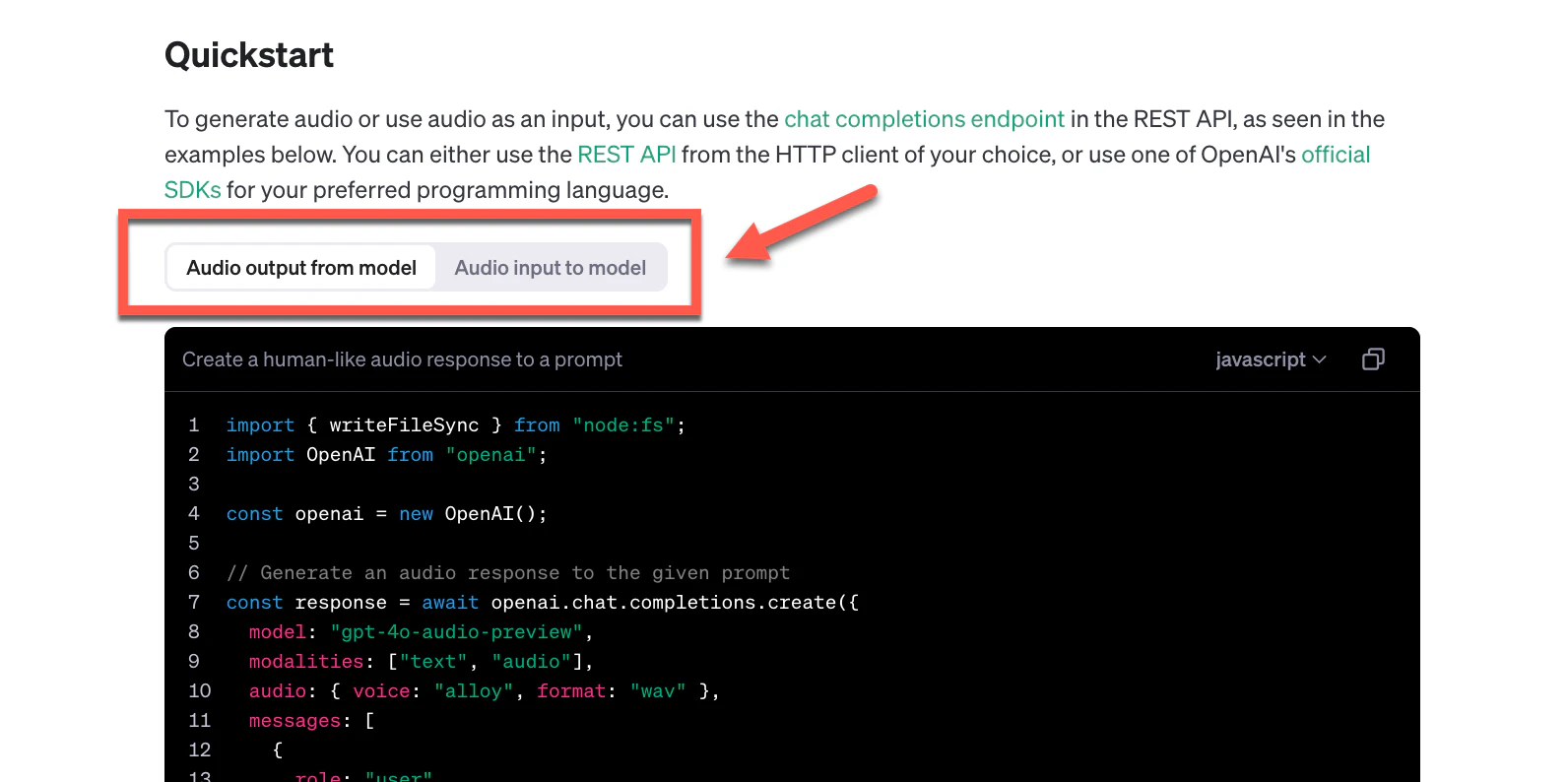
さらに、公式ドキュメントを見ていくと、クイックスタートの情報もありました。
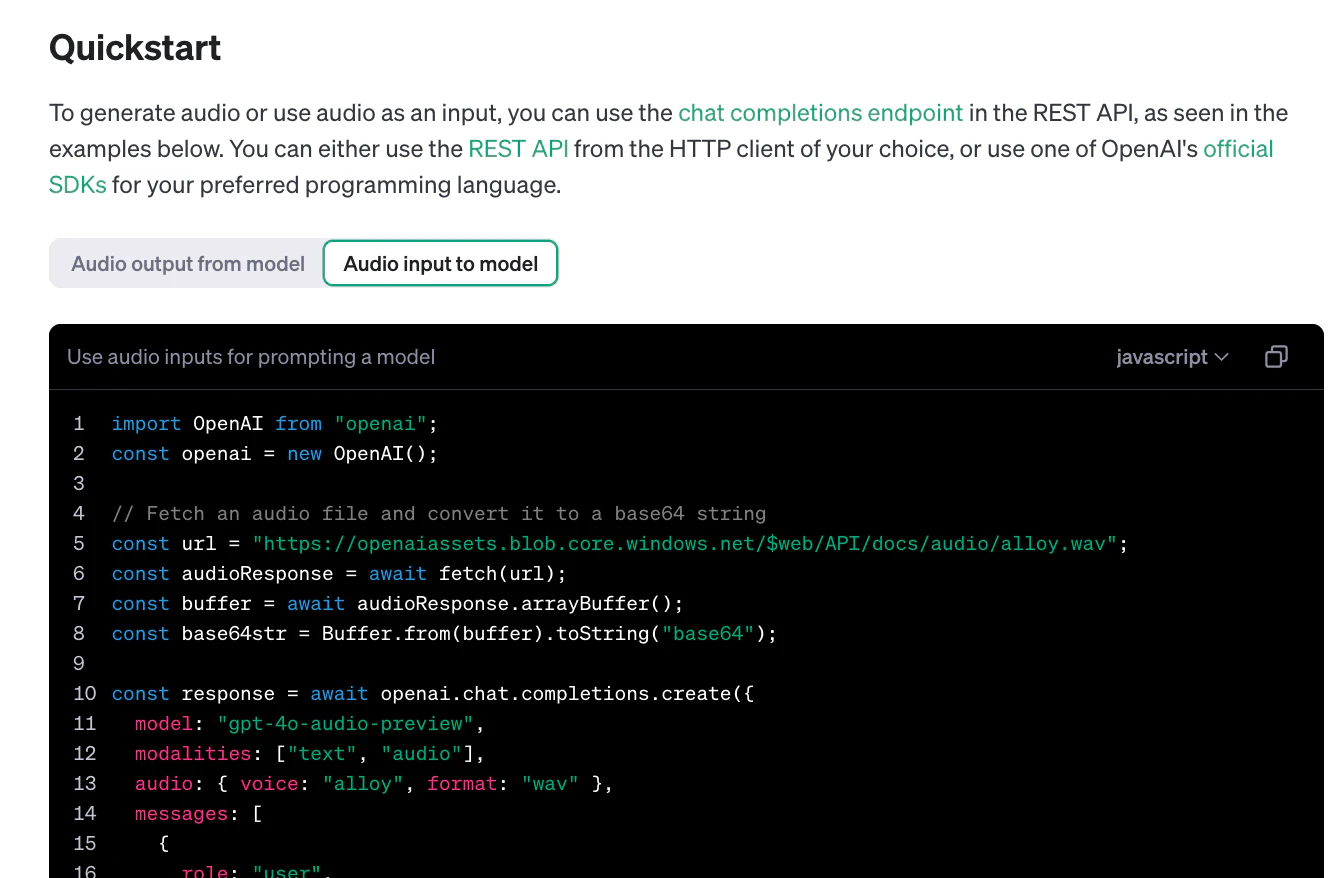
画面上部を操作して切り替えを行うと、「Audio output from model」と「Audio input to model」の 2種類の内容を見ることができるようになっています。
どちらも、サンプルコード内で指定しているモデルは 「gpt-4o-audio-preview」 となっています。
また、サンプルコードが表示されている部分の右上部分で、「JavaScript」「Python」「curl」を切り替えられるようでした。
curl のサンプル
例えば、curl のサンプルだと以下が表示されました。
curl "https://api.openai.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o-audio-preview",
"modalities": ["text", "audio"],
"audio": { "voice": "alloy", "format": "wav" },
"messages": [
{
"role": "user",
"content": "Is a golden retriever a good family dog?"
}
]
}'
curl "https://api.openai.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o-audio-preview",
"modalities": ["text", "audio"],
"audio": { "voice": "alloy", "format": "wav" },
"messages": [
{
"role": "user",
"content": [
{ "type": "text", "text": "What is in this recording?" },
{
"type": "input_audio",
"input_audio": {
"data": "<base64 bytes here>",
"format": "wav"
}
}
]
}
]
}'
ドキュメントの続き
さらにドキュメントを見ていくと「Multi-turn conversations」や「FAQ」といった項目の記載がありました。
FAQ の部分では、「gpt-4o-audio-preview で扱える入出力の種類の詳細」や「Realtime API との違い」についてなどが書かれています。

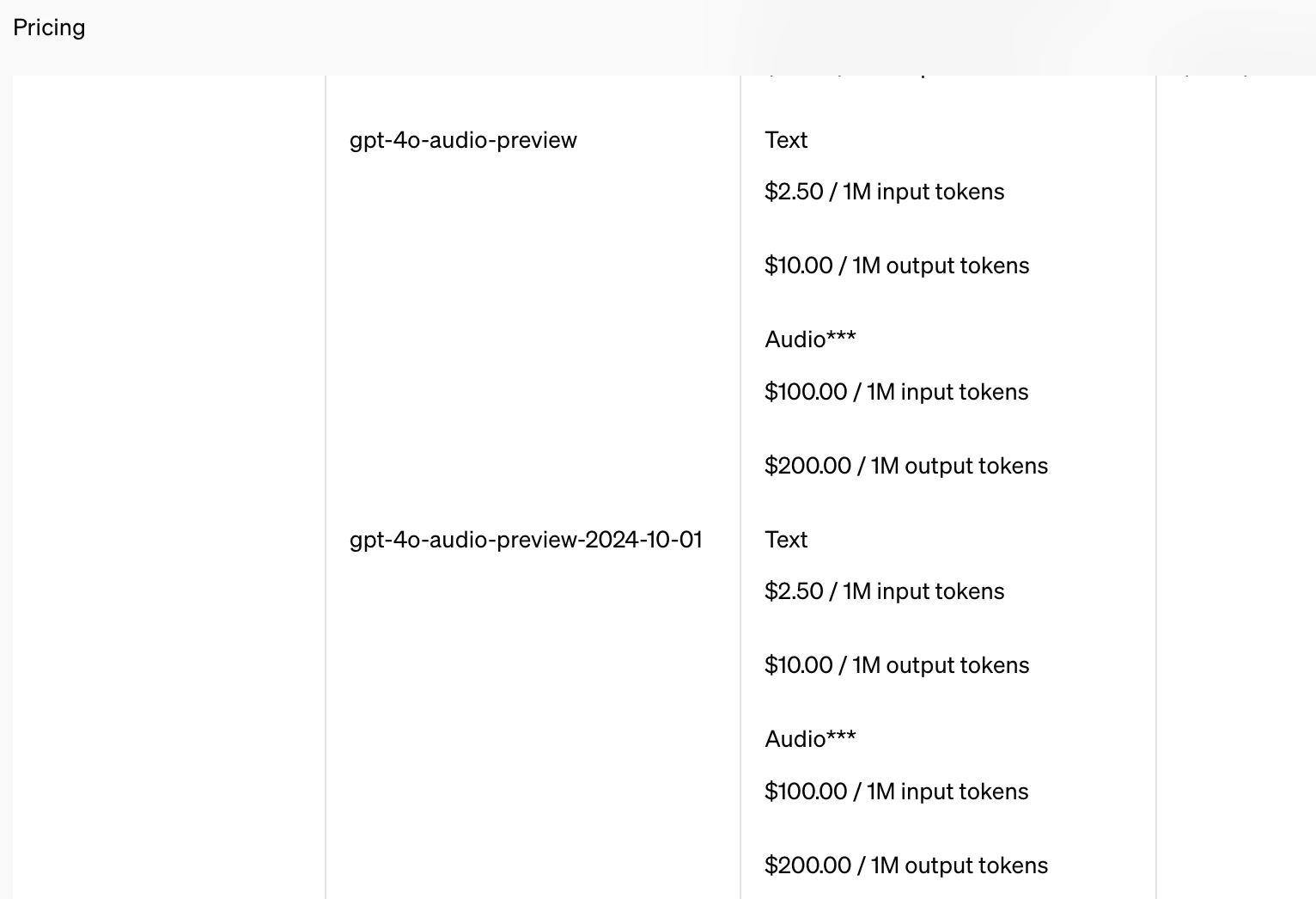
価格のページ
利用時の価格については、Pricing のページの、以下の「gpt-4o-audio-preview」に関する箇所を見れば良さそうでした。