はじめに
「トランザクションの最先端研究」は、トランザクションに関する最先端の研究内容を皆さんと共有することを目的とします。トランザクションは内容の専門性が高いことから、本稿では順を追った説明を行っていくこととします。後の内容を理解するための土台とするため、まずはトランザクションの基礎理論から話を進めていきます。本稿には次の三つの目的があります。
- トランザクションの独立性を明らかにし、よくある認識の誤りについて説明すること。
- トランザクションの複雑性について理解し、これを簡略化できるようにすること。
- 最先端の研究の焦点について理解し、業務・研究に関する示唆を得ること。
最初に共有する内容は、トランザクションの分離レベルの定義に着目したものです。後の内容は全てこれに基づくものであり、分離レベルの最新の学術的定義は広く受け入れられているものではないため、本稿では分離レベルの定義が提示された順に沿って、各定義の適切性と欠点について分析していきます。
ANSI SQL-92は当初、現在でも最も広く用いられている分離レベルの定義であるREAD COMMITTED、REPEATABLE READ、SERIALIZABLEを提示しました。その後、論文「A Critique of ANSI SQL Isolation Levels」がANSI SQL-92の欠点を指摘したうえで、補足的説明を行いました。論文「Generalized Isolation Level Definitions」は、それまで分離レベルの定義がデータベースの実装に大きく依存していた実態を指摘し、実装に依存しない分離レベルの定義を提示しました。最後に、本稿ではこれらの定義に基づいてMySQLとTiDBの分離レベルを分析し、SNAPSHOT ISOLATION分離レベル下でSNAPSHOT READとCURRENT READが同時に存在する場合に出現するエラー現象の内部要因を正確に把握します。
本稿で取り上げる内容は多岐にわたるため、上・下に分けています。「上」では2PLのデータベースにおける分離レベルへの見方について説明します。「下」ではデータベースの実装に依存しない分離レベルの定義について説明したうえで、TiDBの分析を行います。
トランザクション独立性の基礎概念
トランザクションは一連の操作の集合であり、ACID特性を持っています。ACIDのAは不可分性(Atomicity)、Iは独立性(Isolation)を示します。
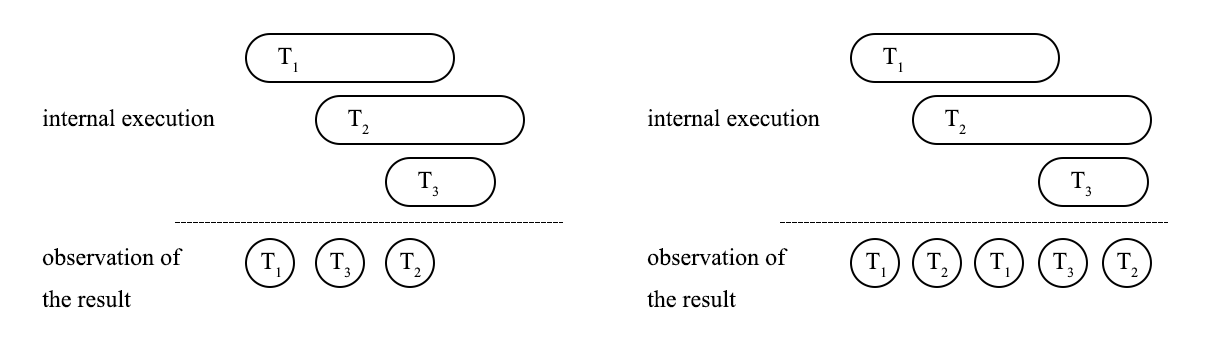
不可分性とは、トランザクションの全ての操作が全て実行されるか、あるいは全く実行されないことをいいます。ただ、不可分性はトランザクションのプロセスも不可分に発生することを保証することはできず、トランザクションプロセスを制約するのは独立性です。理想的なデータベースによって複数のトランザクションが実行されると、結果からは、これらトランザクションは順次実行された、すなわち各トランザクションのプロセスも不可分に発生したとみなされます。図1は外部から見た場合のSERIALIZABLEとNON SERIALIZABLEの違いについて示しています。左図は結果からT1→T3→T2の順に完全に実行したとみなされます。一方、右図ではT1の実行プロセス中にT2の実行が、T2の実行プロセス中にT3の実行が入り込み、意味論的なNON SERIALIZABLEが発生しています。この場合、分離レベルが定義するのはデータベーストランザクション間の分離度となります。
ANSI SQL-92
ANSI SQL-92では、READ UNCOMMITTED(確定していないデータまで読み取る)、READ COMMITTED(確定した最新データを常に読み取る)、REPEATABLE READ(読み取り対象のデータを常に読み取る)、SERIALIZABLE(直列化可能)という代表的な分離レベルが定義されています。
| DIRTY READ | NON-REPEATABLE READ | PHANTOM READ | READ UNCOMMITTED |
|---|---|---|---|
| READ UNCOMMITTED | POSSIBLE | POSSIBLE | POSSIBLE |
| READ COMMITTED | NOT POSSIBLE | POSSIBLE | POSSIBLE |
| REPEATABLE READ | NOT POSSIBLE | NOT POSSIBLE | POSSIBLE |
| SERIALIZABLE | NOT POSSIBLE | NOT POSSIBLE | NOT POSSIBLE |
DIRTY READ、NON-REPEATABLE READは、PHANTOM READと比べればずっと理解しやすいとはいえ、インターネット情報はMySQLのPHANTOM READを誤って説明している(SNAPSHOT READとCURRENT READが出現する現象をPHANTOM READと混同している)ものがほとんどであるため、本稿ではPHANTOM READについてのみ詳細に説明します。
PREDICATEとITEM
PREDICATEは「述語」という意味です。照会条件は厳密に言えば、全て述語に該当します。一方、KVストレージエンジンから特定のKEYを読み取る結果はITEMと呼ばれます。ただ、関係データベースではKVの上にさらにSQLレイヤーが存在します。SQLレイヤーは特定のKEYを読み取った場合であっても、照会条件(PREDICATE)によって記述されます。SQLレベルでPREDICATEであるか、ITEMであるかを議論する場合には、単一照会であるかどうかを考慮する必要があります。単一照会はデータを検索するための方法であり、効果的なユニークインデックスを作成してデータのKEYを指定します。一般的に、必要なデータを非常に高い効率で検索することが可能です。その照会のプロセスは特定のKEYの読み取りと類似しているため、本稿では次のような認識に立ちます。
- 単一照会はITEMタイプの照会条件である
- これ以外の照会は全てPREDICATEタイプの照会条件である
PHANTOM READ
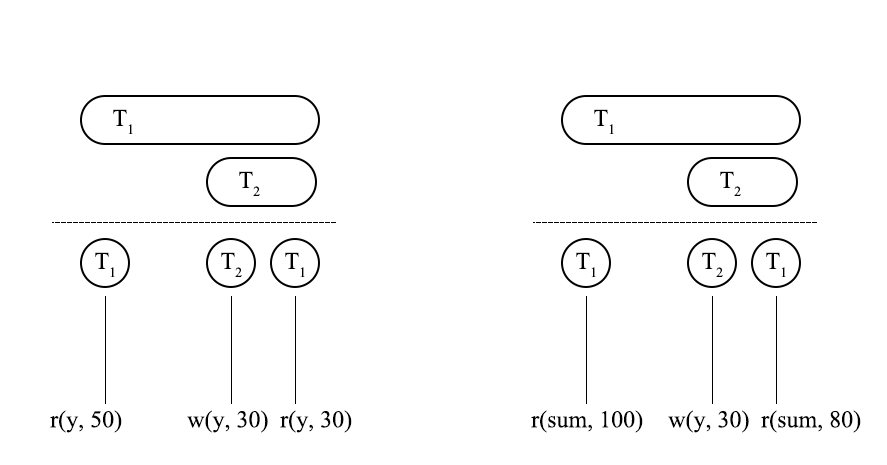
PHANTOM READはNON-REPEATABLE READのPREDICATE版と言えます。この二つのエラー現象は、トランザクションにおいて読み取り操作を2回行う必要があります。NON-REPEATABLE READとは2回のITEMタイプの読み取り操作によって異なる内容を読み取ること、PHANTOM READとは2回のPREDICATEタイプの読み取り操作によって異なる結果を読み取ることをいいます。図2の左側はNON-REPEATABLE READ、右側はPHANTOM READを示しています。
Txn 1 |
Txn 2 |
|---|---|
select * from accounts; -- 0 rows |
|
insert into accounts values(“tidb”, 100); |
|
commit; |
|
insert into accounts values(“tidb”, 1000); -- duplicate entry “tidb” |
|
select * from accounts; -- 0 rows |
|
select * from accounts for update; -- 1 rows |
|
commit; |
例1ではMySQLにおける一般的なPHANTOM READの例を示しています。本稿はこれが「偽のPHANTOM READ」であるという認識に立ちます。これは、その本質的要因がMySQLにおけるSNAPSHOT READとCURRENT READの混同使用にあるためです。CURRENT READは「READ COMMITTED分離レベルにダウングレードされた」と記述されることがあります。この例で示されるのは、二つの分離レベルの混同使用による反直感的な現象です。この後、SNAPSHOT READとCURRENT READに言及する際に、この点についてより詳細に説明します。
まとめ
ANSI SQL-92による分離レベルの定義は広く用いられていますが、今日の分離レベルの指示語の混乱も招いています。これは定義の厳密さを欠くことが理由です。例えば、SERIALIZABLEはDIRTY READ、NON-REPEATABLE READ、PHANTOM READが発生しないように定義されています。ただ、これは真のSERIALIZABLEとは意味論的に等価ではありません。その後提示されたWRITE SKEW現象はSERIALIZABLEに違反する行為ですが、これはANSI SQL-92には含まれていません。
A Critique of ANSI SQL Isolation Levels
論文「A Critique of ANSI SQL Isolation Levels」は、ANSI SQL-92が見落とした問題を指摘するとともに、2PLのデータベースの実装下におけるANSI SQL-92の分離レベルに対してより高い要求を課し、最終的には、SNAPSHOT ISOLATIONの分離レベルを提示しています。
エラー現象
エラー現象のうち、P1〜P3はANSI SQL-92に由来するエラー現象です。ANSI SQL-92には言語的な記述しかなく、これらのエラーが正確に定義されていないため、本稿ではP(PHENOMENON)によりエラー現象が発生する可能性があること、A(ANOMALY)によりエラーが発生したことを示すという二つの解釈を行っています。Pはエラーが発生する可能性があることのみを示すため、拡大解釈(BROAD INTERPRETATION)とも呼ばれます。一方、Aは厳密な解釈(STRICT INTERPRETATION)と呼ばれます。
P0:DIRTY WRITE
DIRTY WRITEは二つのトランザクションが同時に一つのKEYを書き込み、矛盾が生じる現象です。例2のように、2PLのデータベース実装下で二つの未送信のトランザクションが同時に一つのKEYを書き込もうとして失敗した場合、エラーが発生する可能性があることを示します。これには次の二つの要因があります。
- Txn1の送信がまず成功し、その後Txn2にROLLBACKが発生した場合、不明瞭な値にロールバックする必要がある。
- 他のKEYも書き込んだ場合、制約の一貫性が失われることがある。
Txn 1 |
Txn 2 |
|---|---|
w(x, 1) |
|
w(x, 2) |
|
... |
... |
P4:LOST UPDATE
LOST WRITEとは、トランザクションで読み取ったデータに基づいて書き込みを行う前の読み書き操作中、他のトランザクションで別の書き込みが発生して送信に成功し、そのトランザクションの実行が継続されると、送信に成功した書き込みが上書きされ、書き込みが失われることをいいます。例3ではTxn1、Txn2いずれでもxに1を加える必要があります。Txn1では読み取った値10に基づいて11を書き込み、書き込み前にTxn2でも11をxに書き込み、SERIALIZABLEではxは12となります。このとき、一つのトランザクションの書き込みが失われるため、xの最終値は11となります。注:論文の説明によれば、Txn2は必ずしもCOMMITされている必要はありません。ここでは理解しやすいよう、例に少し手を加えています。
Txn 1 |
Txn 2 |
|---|---|
r(x, 10) |
|
w(x, x + 1) |
|
commit |
|
w(x, x + 1) x=10 |
|
commit |
P4C:CURSOR LOST UPDATE
データベースの実装においては、性能を保証するため、読み取り操作をNONLOCKING READとLOCKING READの二つに区分することがあります。LOCKING READによってLOST UPDATEの発生を防止するデータベースもあります。この場合、データベースによってP4C現象の発生が防止されたとみなします。P4C現象については例4で示しています。LOCKING READは関係データベースでは通常、SELECT FOR UPDATEとして実装されます。
Txn 1 |
Txn 2 |
|---|---|
rc(x, 10) |
|
w(x, x + 1) |
|
commit |
|
w(x, x + 1) x=10 |
|
commit |
A5A:READ SKEW
READ SKEW現象とは、二つのステータスのデータを読み取ったことによって制約違反が検知されることをいいます。例5のxとyとの和は100でなければならないところ、Txn1ではx+y=140となっています。READ SKEW現象では同じKEYを重複して読み取っているわけではないため、NON-REPEATABLE READではないという点に注意が必要です。
Txn 1 |
Txn 2 |
|---|---|
r(x, 50) |
|
w(x, 10) |
|
w(y, 90) |
|
commit |
|
r(y, 90) |
A5B:WRITE SKEW
WRITE SKEWは二つのトランザクションの書き込み操作で発生するエラーです。例6ではWRITE SKEW現象について示しています。Txn1でxの値をyに、Txn2でyの値をxに代入しようとした場合、この二つのトランザクションがSERIALIZABLEを実行すると、終了後のxとyは同じ値となる必要がありますが、WRITE SKEWでは同時並行操作なので、双方のトランザクションによってコミットされた値は異なります。
Txn 1 |
Txn 2 |
|---|---|
r(x, 10) |
|
r(y, 20) |
|
w(y, 10) |
|
w(x, 20) |
|
commit |
commit |
r(x, 20) |
|
r(y, 10) |
P1、A1:DIRTY READ
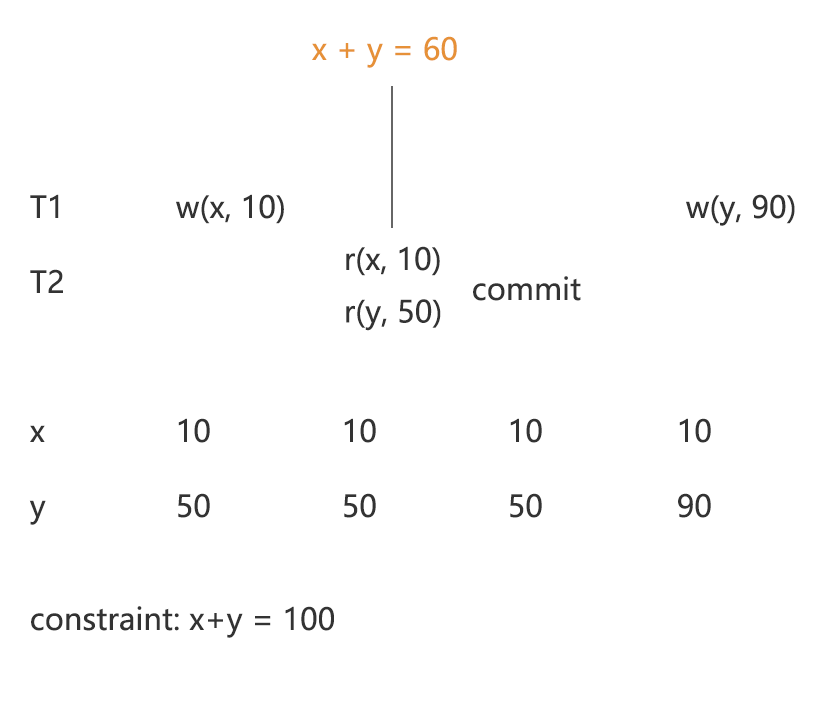
DIRTY READの厳密な解釈では、例7のように、送信に成功したトランザクションが送信されないトランザクションの書き込み内容を読み取る必要があります。一方、拡大解釈では、例8のように、Txn1で未送信のトランザクションの書き込み内容を読み取ると、DIRTY READが発生したとみなされます。図3では拡大解釈をする理由について説明しています。この例では、Txn2はTxn1のx書き込み後の値を読み取っていますが、Txn1のy書き込み前の値を読み取っているため、制約を破棄するデータを読み取ってしまっています
Txn 1 |
Txn 2 |
|---|---|
w(x, 1) |
|
r(x, 1) |
|
commit |
abort |
Txn 1 |
Txn 2 |
|---|---|
w(x, 1) |
|
r(x, 1) |
|
... |
... |
P2、A2:NON-REPEATABLE(FUZZY) READ
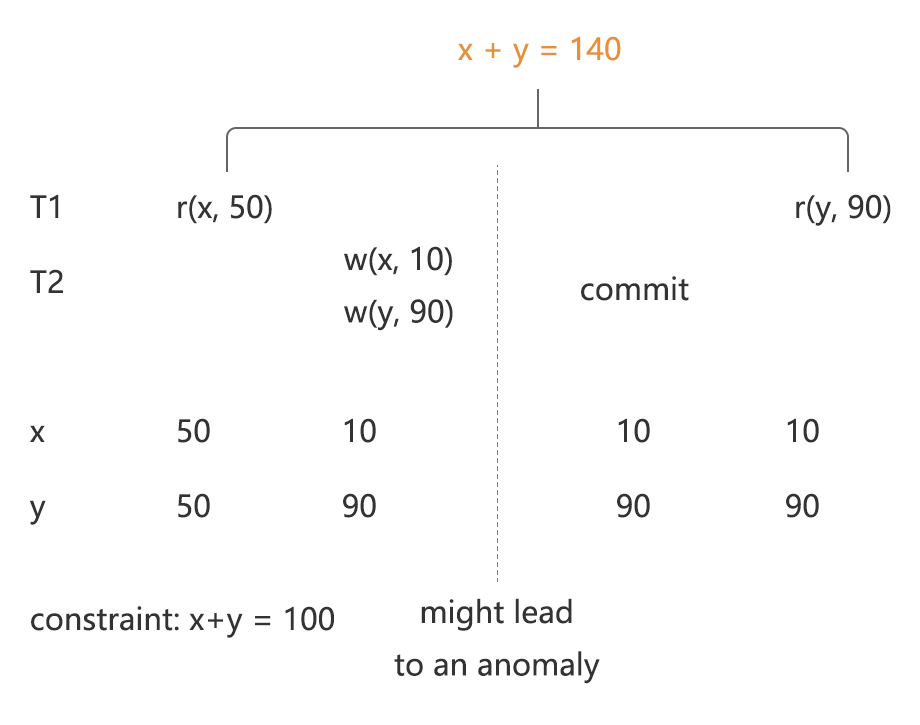
NON-REPEATABLE READとは、2回のITEMタイプの読み取り操作により異なるデータを読み取ることをいいます。例9のように、厳密な解釈では読み取りを完全に2回行う必要がありますが、拡大解釈ではトランザクションがあるKEYを読み取った後、読み取ったトランザクションが送信されておらず、そのKEYの書き込みに成功したトランザクションがあると、エラーが発生する可能性があるとされます。つまり、書き込みリクエストが、読み取りリクエストによってブロックされる必要があるということです。図4では拡大解釈をする理由について説明しています。Txn1のx読み取りによってTxn2のx書き込みがブロックされていないため、その後Txn2が書き込んだyを読み取ってしまっており、その結果、Txn1から見た結果として、x+y=140によって制約が破棄されています
Txn 1 |
Txn 2 |
|---|---|
r(x, 1) |
|
w(x, 2) |
|
commit |
|
r(x, 2) |
|
commit |
Txn 1 |
Txn 2 |
|---|---|
r(x, 1) |
|
w(x, 2) |
|
... |
... |
P3、A3:PHANTOM
ANSI SQL-92が定義するPHANTOM READとは異なり、本稿ではこのエラー現象をPHANTOMと呼びます。例11に代表的なPHANTOM READを挙げています。2回のPREDICATEタイプの読み取り操作によって異なるデータを読み取ることがその特徴です。PHANTOM現象の定義はPHANTOM READより広く、例12のように、PHANTOM現象の拡大解釈では一つのトランザクションがPREDICATEタイプの読み取りを行い、もう一つのトランザクションがその中の特定のKEYへの書き込み操作を行うと、エラーが発生する可能性があるとされます。つまり、PREDICATEタイプの読み取りリクエストによって、これが読み取ったデータの書き込みリクエストがブロックされる必要があるということです。図5では拡大解釈をする理由について説明したうえで、PREDICATE・ITEMタイプで読み取った結果が一貫しない状況について指摘しています。SERIALIZABLEのデータベースで、PREDICATEタイプの照会によって算出されたxとyとの和は、ITEMタイプの照会によって直接に読み取ったsumのKEYと同じ値となる必要があります。
Txn 1 |
Txn 2 |
|---|---|
r(sum(x-y), 11) |
|
w(x, 2) |
|
commit |
|
r(sum(x-y), 12) |
|
commit |
Txn 1 |
Txn 2 |
|---|---|
r(sum(x-y), 11) |
|
w(x, 2) |
|
... |
... |

SNAPSHOT ISOLATION
本稿ではSNAPSHOT ISOLATION(SI)についても言及しておきます。SIの分離レベルでは、トランザクションがその開始時間のSNAPSHOTからデータの読み取りを行います。2PLと異なり、SIは通常、MVCCのNONLOCKING特性によって性能を向上します。SIでは一つのKEYについて複数バージョンのデータを保存できるため、読み込みによる書き込みのブロックのほか、書き込みによる書き込みのブロックさえも発生しません。
TiDBの楽観的トランザクションに詳しい方であればお気づきかもしれませんが、先に示したP0:DIRTY WRITEの定義によれば、SIは「エラー現象が発生する可能性がある」に該当します。楽観的トランザクションでは、二つのトランザクションが同時に一つのKEYを書き込んでも成功しますが、最後の送信時に一つのトランザクションが失敗します。この仕組みは「FIRST-COMMITTER-WINS」と呼ばれます。SIではP0(エラーが発生する可能性がある)が発生する可能性がありますが、DIRTY WRITEのエラー現象は発生しません(これをA0と呼びます)。
P1に記述された現象は、SIにとっては意味を持ちません。これは、SIでは読み取ろうとするバージョンを検索することができ、P1によって制約違反が発生することはないためです。P2、P3に記述された「エラーが発生する可能性がある」ステータスの現象はSIで発生しますが、SIは常にSNAPSHOTバージョンから読み取りを行うため、読み取ったデータは全て同じバージョンのものであり、制約違反は発生しません。このため、SIはA1、A3(厳密な解釈)により制約します。
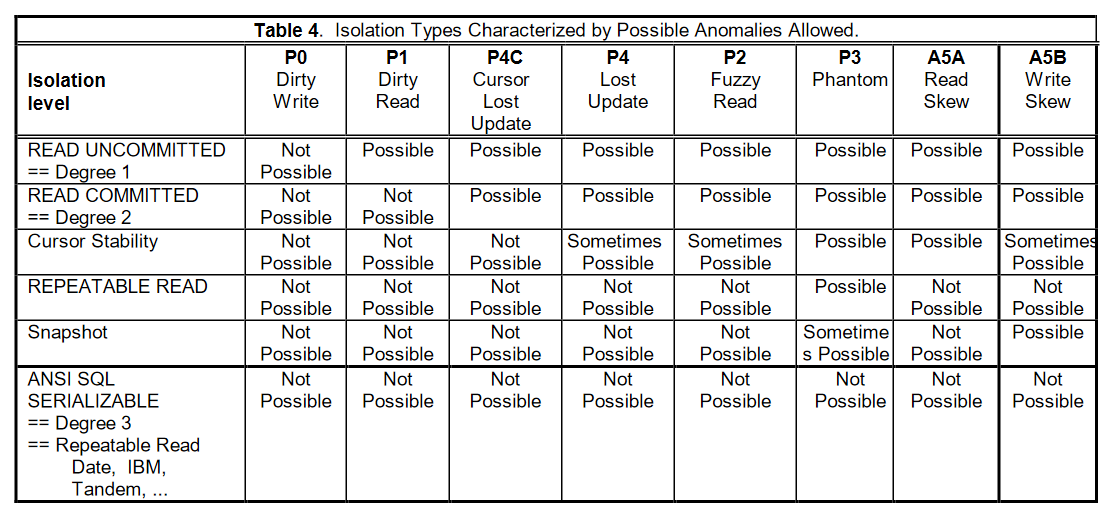
分離レベル
図6には補足後の分離レベルの定義を示しています。ANSI SQL-92にCURSOR STABILITYとSNAPSHOT ISOLATIONの分離レベルを追加しています。CURSOR LOST UPDATEとは、データベースがCURSORによってLOST UPDATEを防止できることをいい、SNAPSHOT ISOLATIONはPHANTOM現象に対して強制要求を行いません。
まとめ
本稿にはマイルストーン的な意義があります。エラー現象に関する補足的説明やSNAPSHOT ISOLATION分離レベルの提示において大きな意味を持ち、これらの概念は今日広く受け入れられています。ただ、その中には今日の状況には合わないものも見受けられます。
- 実装に関しては、P0、P4でエラーについて指摘するとともに、ロックの方法を指定している。
- 論文で示された拡大解釈をする理由については、本稿では制約破棄が発生し、その一貫性が失われるのは、P0(DIRTY READ)でトランザクションの中間ステータス* を読み取り、P1(FUZZY READ)とP2(PHANTOM)で二つのステータスからデータを読み取ってしまうことが真の要因とする認識に立つ。
- 初期設定のSNAPSHOT ISOLATIONは複数のバージョンを保存する分離レベルだが、基準となる定義ではデータベースの実装方式を考慮すべきでない。
- 拡大解釈はSNAPSHOT ISOLATIONでは用いられておらず、ここに基準の不一致が存在する。
- ここで定義されるSERIALIZABLEは、真のSERIALIZABLEとは意味論的に依然として等価ではない。
おわりに
本稿では当初の分離レベルへの見方について紹介しました。こうした見方のほとんどは2PLのデータベースをよりどころとしたものです。その中には今日の状況にそぐわないものもいくらか見受けられます。ただ、こうした見方はすでに広く受け入れられているため、これらのエラー現象の本質的な姿を正しく理解するうえでは必要不可欠なものとなっています。