データベースは、様々な使用状況に応じて大量の読み込みが必要な場合があります。そのため、最適化が必要です。私は最近、分散データベースの最適化に取り組んでおり、その技術と説明について説明します。
インデックス
ローカルインデックス
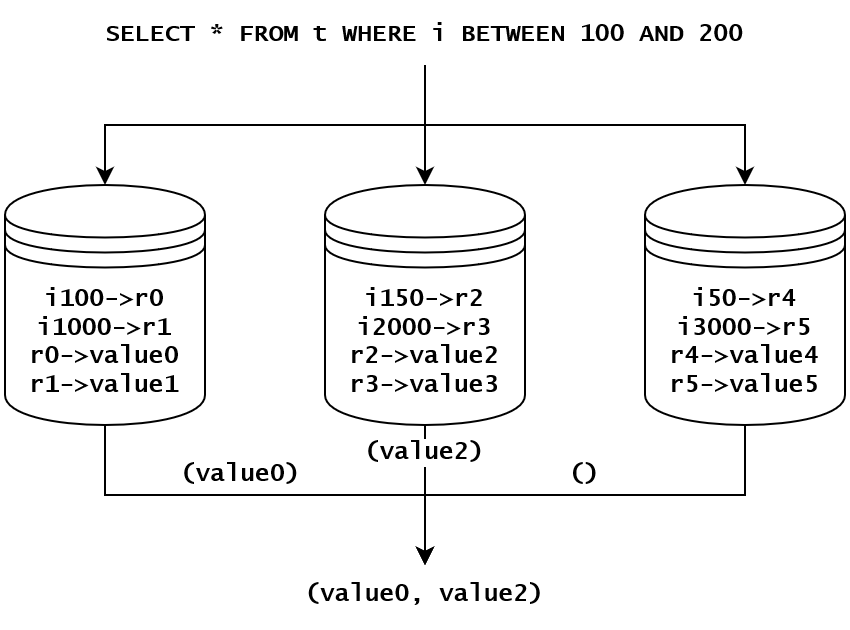
分散データベースは大体二通りあて、ローカルインデックスとグローバルインデックス。ローカルインデックスは普通のデータベースによく似って、最後の結果は複数のノードの結果を重合させてから出きます。下の図のように、このクエリは三つのノードから詮索しなければ完全な結果は出ていない。
グローバルインデックス
グローバルインデックスの分散データベースはこの状況ではもっと複雑なので、効率はより高いかもしれない。下の図のように、このクエリと(r4, r5) が居るノードは全く関係ない。こんな無関係なノードが多い時、グローバルインデックスのパフォーマンスのメリットがある。
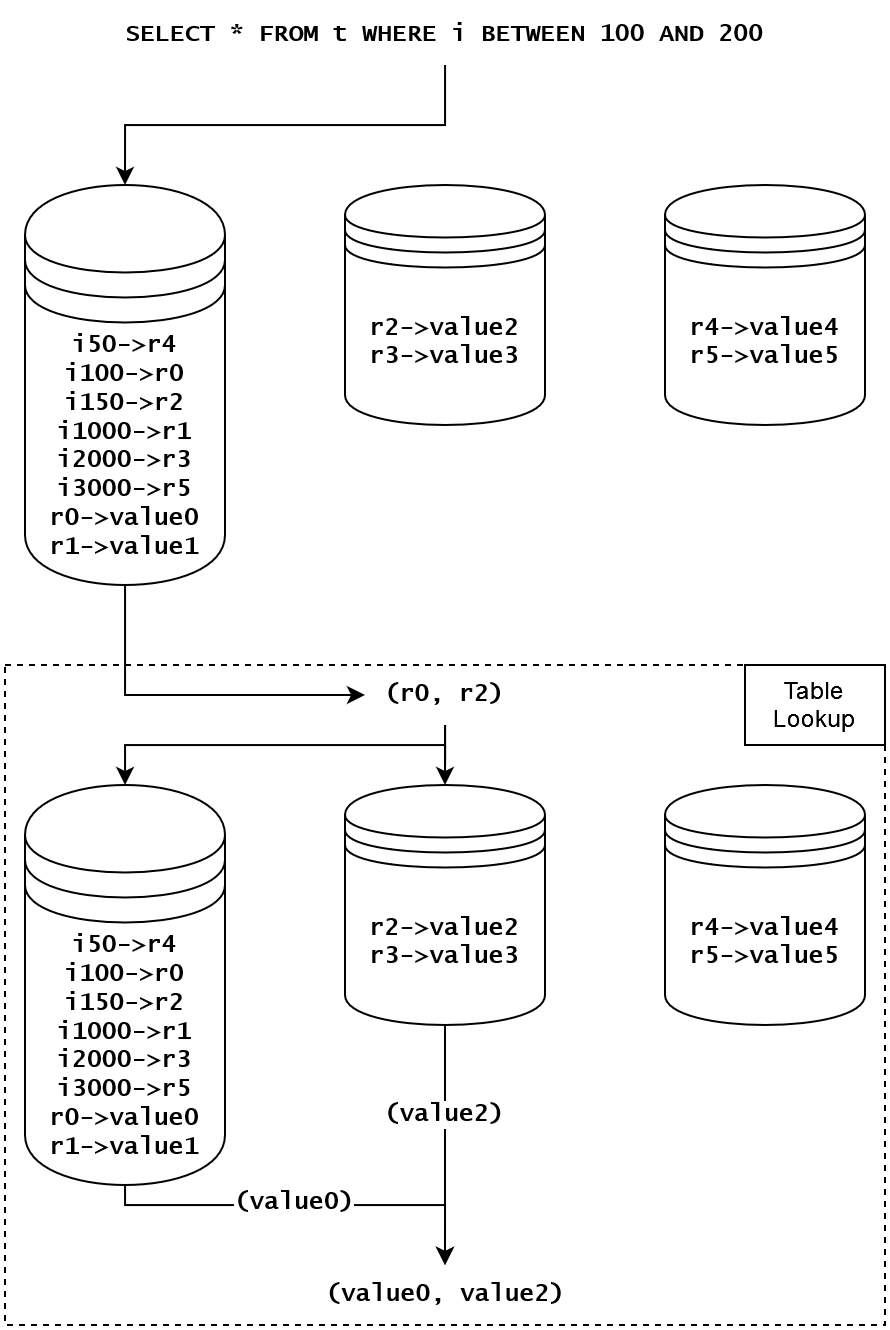
点線のボックスの中には Table Lookup と呼ばれる。グローバルインデックスの利点はインデックスの Key は連続し、ほぼ同じノードにあて、読むことは速いので、この Table Lookup はパフォーマンスの損があるかもしれない、原因は三つ
- Table Lookup の Key は連続ではないの状況は通常ので、Engine の Scan は遅い、RocksDB の場合、Seek のコストは Next より高いです。
- 図のデータベースのノード実は分散データベースのシャード、Table Lookup に関わるシャードの数量が多いの場合、もし強一貫性は必要ならば、オーバーヘッドが多くなる(Raft にとっては Read Index のオーバーヘッド)。
- Table Lookup のバランスは時々悪い、つまり、一つのノードが渋滞する時もある、クラスターの資源があるだが、Table Lookup の性能が悪い。
その中で、二つ目および三番目のは最適化することは可能です。
一貫性の利点
一貫性の意味は一つのスナップショットを読んだ index と row は一対一の関係で、上の例で、i100->r0->value0 と i150->r2->value2 の関係です。この利点のおかげで、Table Lookup のサイズはリクエストを送信する前に既に知られています。小さいな Table Lookup リクエストが多い時、実行するプロセスが多くなることができる。
バッチ処理
Table Lookup を最適化するために、一つの手法はバッチ処理であり、リモートのシャードのデータを読み取るために RPC が必要です。ただし、この RPC のエンコードとデコードのオーバーヘッドは大きく、処理速度に影響を与えます。
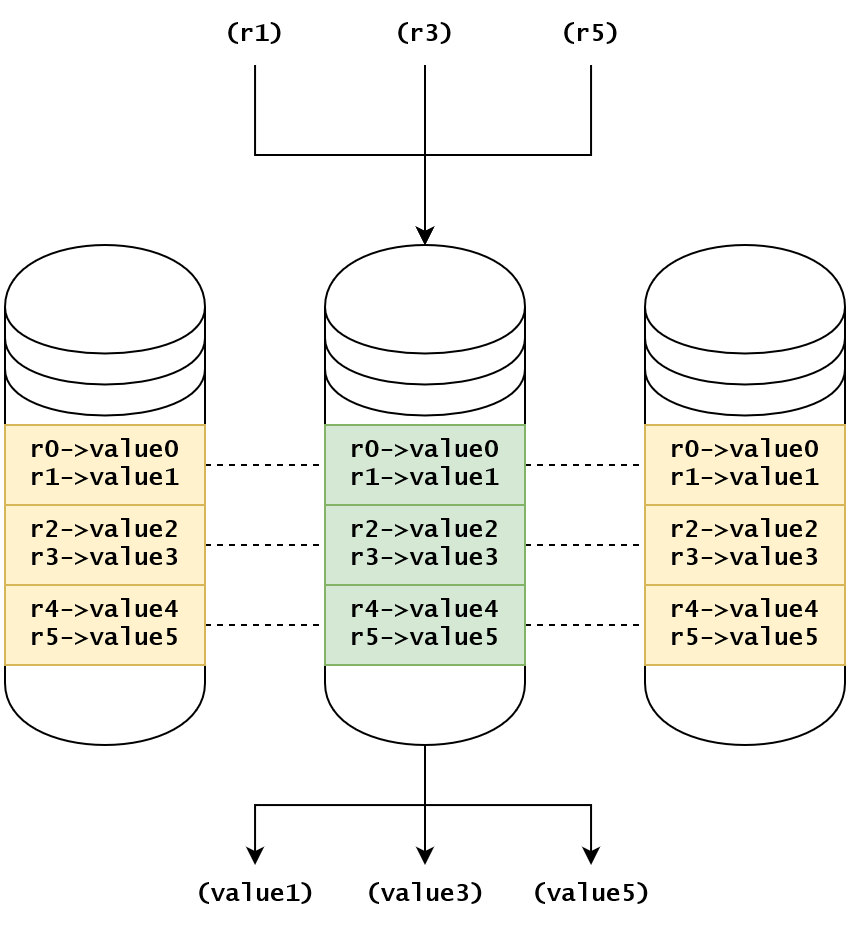
図の中で、レプリカがあるデータベースのシャードには、リーダーレプリカシャードとフォロワーレプリカシャードがあります。緑色のシャードがリーダーで、黄色のシャードがフォロワーです。Table Lookup 以外の説明は図の中で省略します。
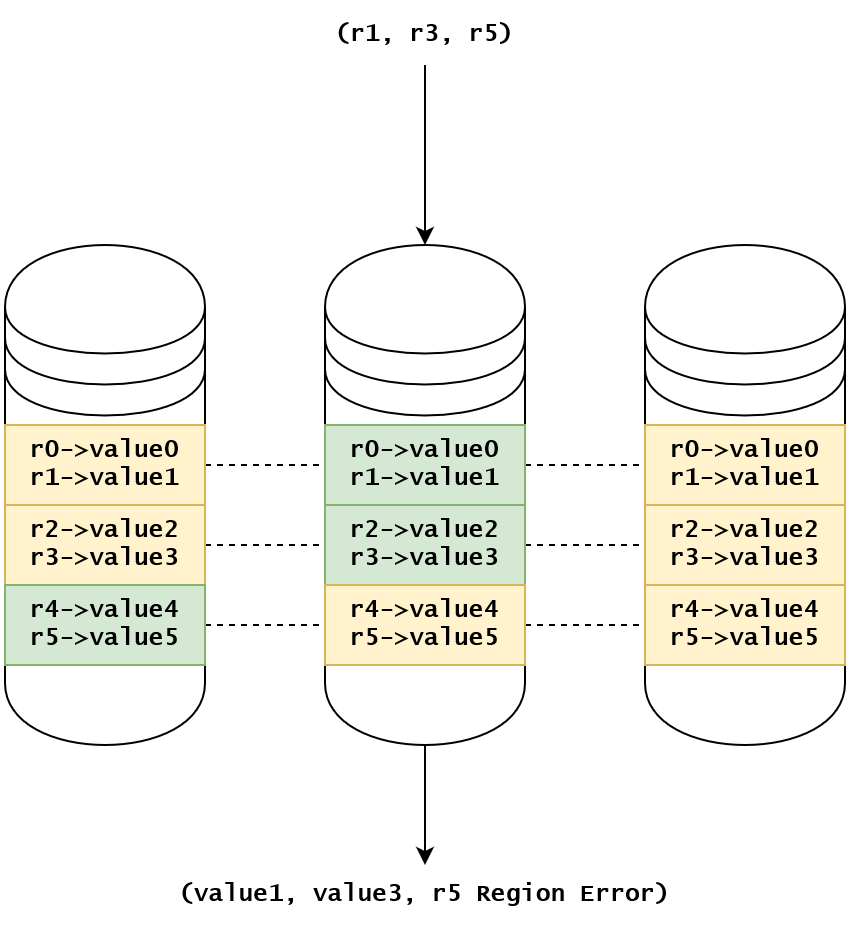
図の中でバッチ処理であり、RPC コンテキストを節約することが出る。r1->value1 と r3->value3 を例にとり、二つの RPC を実行する必要があったものを、ひとつの RPC で解決できるようになりました。ご指摘ありがとうございます。r5を含むシャードがリーダーではないため、リトライが必要であることを示しています。
筆者はここまで実行することができました。もうひとつの最適化は、RocksDB のスナップショットをバッチのリクエストで共有することです。これにより、パフォーマンスがさらに向上するでしょう。
Replica Read
通常、最新のデータを取得するには、クエリはリーダーで実行されます。しかし、一部のクエリはバランスが悪いため、すべてのクエリがリーダーで実行されると、そのリーダーのリソース使用率が高くなり、他のノードのリソースは使用できなくなります。この状況をユーザーが見た場合、「クラスターの資源はまだ残っているが、なぜクエリが遅いのか」という質問に困惑することになります。レプリカリードという機能は、昔に近いレプリカのデータを読み込むことで、リモートリードの遅延やトラフィックを避けることができます。
この文章では、レプリカリードを使用して最新のデータにアクセスするために、コンセンサスアルゴリズムをサポートする方法を略します。簡単に言えば、フォローノードから最新のデータを読むためには、コミットとアプライインデックスを確認する必要があります。Raftには「Read Index」というものがありますが、リーダーが忙しい場合、フォロワーでのRead Indexの性能がより高くなります。
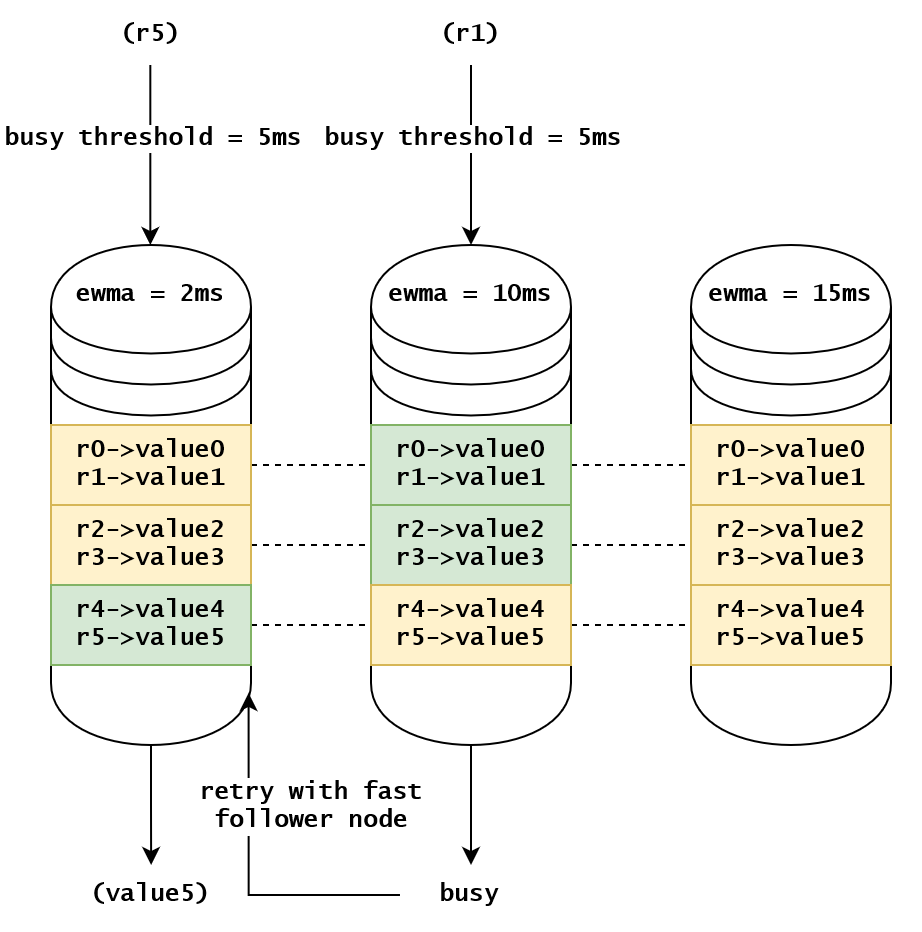
レプリカリードを利用するには、ノードが自分の読み込むタスクのキューイング時間を見積もり(ewma 時間)、クエリの待ち時間があまりにも長い場合(ewma > busy threshold)、ノードが直接 "busy" を返信して、クライアントがリトライします。リトライ時には、ewma が最も低いノードを選択します。
この設計の巧妙なところは、1 つのノードで複数のリーダーシャードが存在し、そのリーダーシャードのフォロワーの分散が広いことです。例えば、10 ノードのクラスターであれば、1 つのノードが忙しい場合でも、最適な状況では 9 つのノードからサポートを受けることができます。