概要
フューチャー Advent Calendar 2020 の22日目の記事です。
私は2019年7月に新卒でフューチャーに入社し、現在は小売プロジェクトで需要予測の業務に携わっています。
最近の業務では予測が外れた要因分析や、予測の外れ要因を学習データに追加することで精度が向上するかの検証などをしていて、仮説をクイックに検証する重要性を感じています。
そんな中で、PyCaretというローコード機械学習ライブラリの存在を知りました。
本記事ではPyCaretとウォルマートの売上データを使って、モデルの生成と売上の予測をしてみます。
PyCaretとは何か

PyCaretは、Pythonのローコード機械学習ライブラリです。
PyCaret is an open source, low-code machine learning library in Python that allows you to go from preparing your data to deploying your model within minutes in your choice of notebook environment.
機械学習モデルを生成するのに必要なこと(データ前処理、モデルの選定、精度検証など)が数行のコードで出来るライブラリです。
PyCaretは、コーディングに費やす時間を減らし、ビジネス上の問題に集中する時間を増やすことを目的としています。
早速使ってみる
実際の小売の実績データを利用して、ある商品の売上数を予測するモデルを作成してみます。
小売の実績データはKaggleの「M5 Forecasting - Accuracy」というコンペで使われた実績を使わせていただきます。

こちらのコンペは、世界最大の売上高を誇るウォルマートの売上データを使って、各商品の未来28日間の売上数を予測し、その精度を競います。
データは、実績売上数だけでなく、販売価格、プロモーション、曜日、特別イベントなどの説明変数も含まれています。これらを合わせて予測売上数の精度を競い合うコンペです。
このコンペでは、10店舗×3049商品×1941日分の実績が与えられています。この中から平均販売数が一番多い商品の実績を使わせていただきます。
データの説明
あらかじめ平均販売数が一番多い商品の抽出、不用カラムの削除、新しい特徴量の作成をしておきました。
そのデータを読み込みます。
import numpy as np
import pandas as pd
df = pd.read_csv('./datasets/train.csv', index_col=0)
df.head()
こちらが読み込んだデータの内容となります。
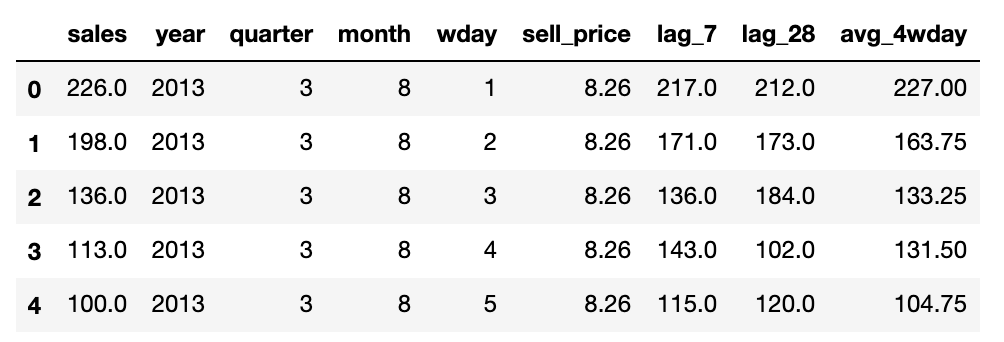
| カラム名 | 説明 |
|---|---|
| sales | 実績売上数 |
| year | 年 |
| quarter | 四半期 |
| month | 月 |
| wday | 曜日 |
| sell_price | 単価 |
| lag_7 | 7日前の実績売上数(1週間前実績) |
| lag_28 | 28日前の実績売上数(4週間前実績) |
| avg_4wday | 直近4週間の同曜日の実績売上数の平均 |
具体的な商品名は与えられていないのでわかりません。
※上に表示した5日の実績からは、食料品で8.26ドルで販売されていて、1日100~226個売れているくらいしか読み取れません。
天気傾向やプロモーション情報、立地など、需要に関わりそうな要因を追加した方が良いのですが、今回は簡略化するために、単価と直近同曜日の実績とカレンダー情報のみで予測します。
また、古い期間の実績を削除し、欠損データも削除した結果、実績が989日分となったため、未来28日分をテストデータ、残りの961日分を学習データとして利用します。
train = df[0:-28]
test = df[-28:]
これを予測したい
まずは予測したい期間の売上実績を確認します。
test['sales'].plot(figsize=(10,5))
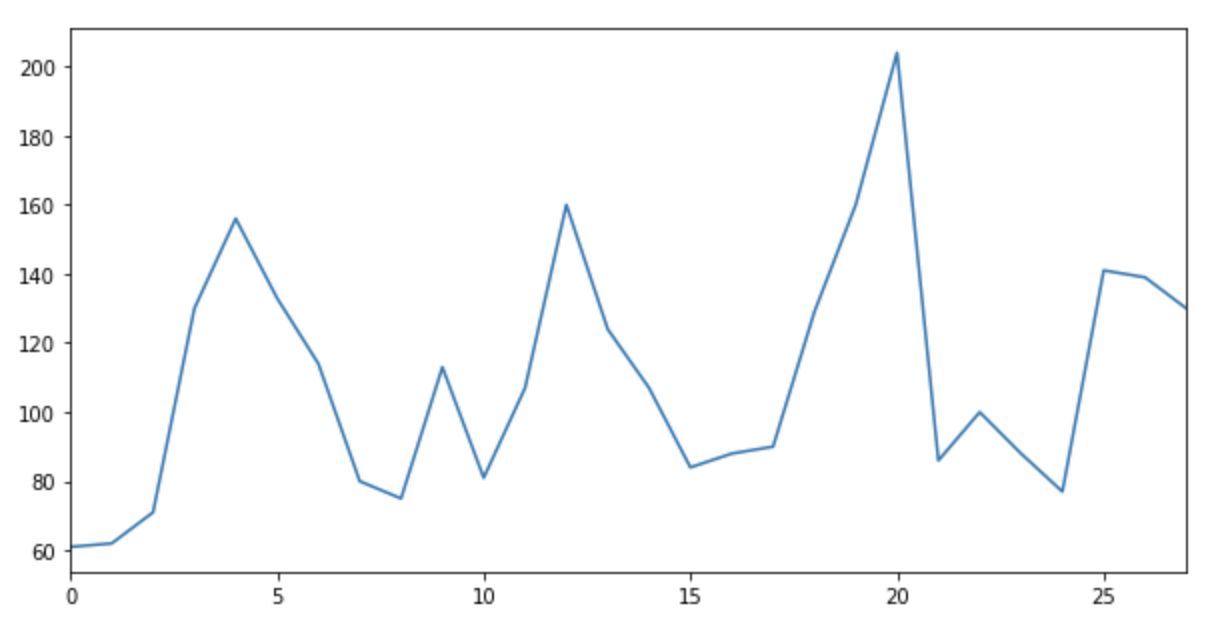
横軸が日、縦軸が売上数です。
未来28日においては、最低で約60個、最大で約200個ほど売れています。
このように売上数が多い日や少ない日の波形を、機械学習でどれだけ捉えることができるかをPyCaretで確認してみます。
PyCaretの環境設定
setup関数で、pycaretの環境を初期化します。pandasのDataFrameでデータを渡し、targetに予測したい目的変数を設定します。
from pycaret.datasets import get_data
from pycaret.regression import *
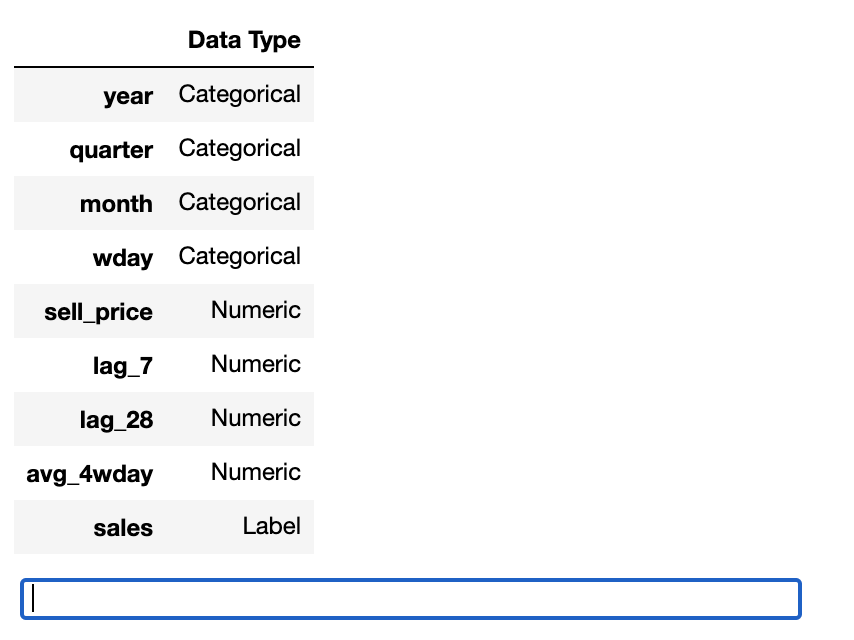
reg1 = setup(train, target = 'sales')
setup関数が実行されると、PyCaretの推論アルゴリズムが各データのデータ型を自動的に推論します。
今回の場合、カレンダー系の情報はカテゴリ変数で、単価や過去実績は連続変数なので正しく推論ができていますね。
全モデルの比較
compare_models関数で、クロスバリデーションを使用して20以上のモデルを学習し、評価します。また、最もパフォーマンスの高い指標はハイライトされます。
たった1行で複数のモデルの評価ができるのはすごいですね。。
best_model = compare_models(fold=5)
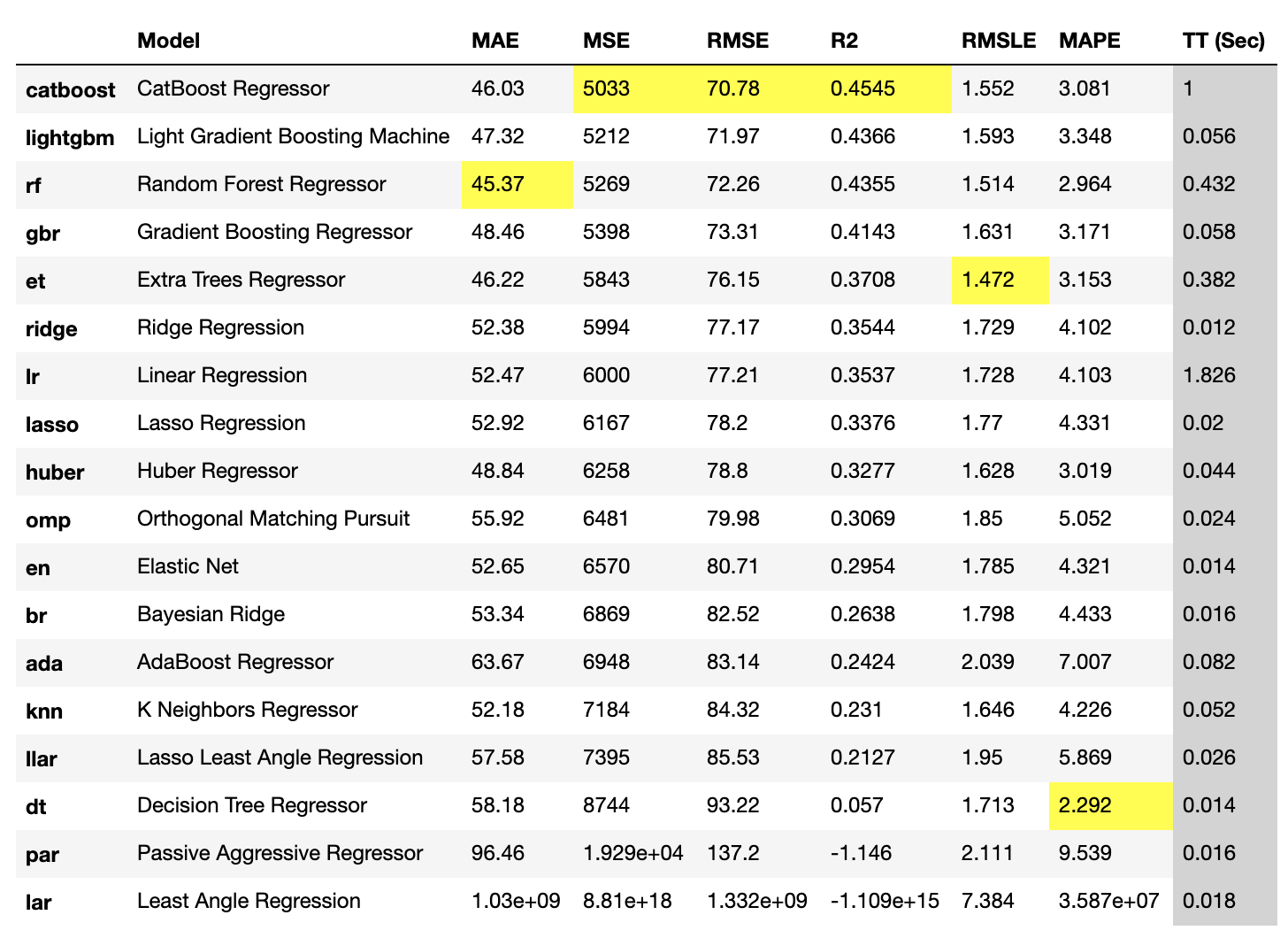
最もパフォーマンスが良い「CatBoost Regressor」と、個人的に気になった「Linear Regression」のモデルを作成してみます。
モデルを作成する
create_model関数は、クロスバリデーションを使ってモデルを訓練し、評価します。出力は、MAE, MSE, RMSE, R2, RMSLE, MAPEをfoldごとにスコアグリッドで表示します。
lr = create_model('lr')

catboost = create_model('catboost')
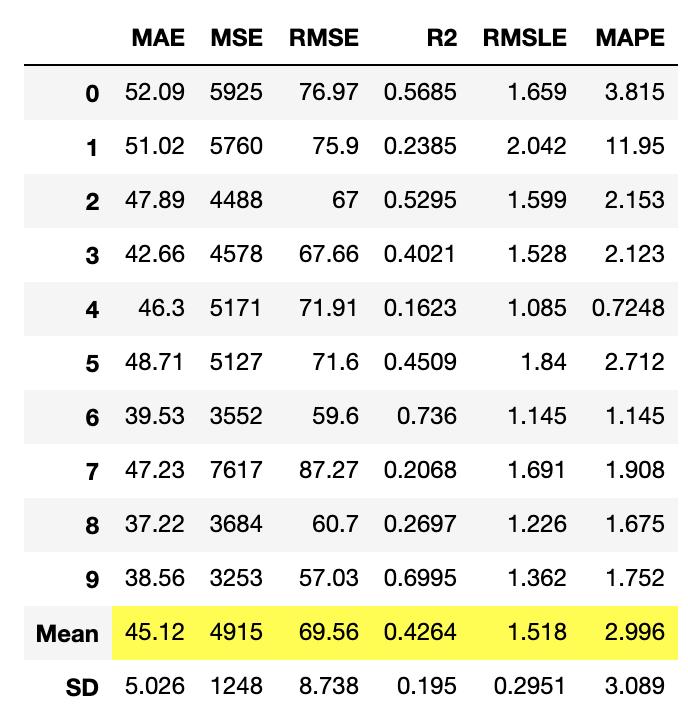
create_model関数を使用してモデルを作成すると、モデルを訓練するためにデフォルトのハイパーパラメータを使用します。
ハイパーパラメータを調整するには、 tune_model関数を使用します。
モデルをチューニングする
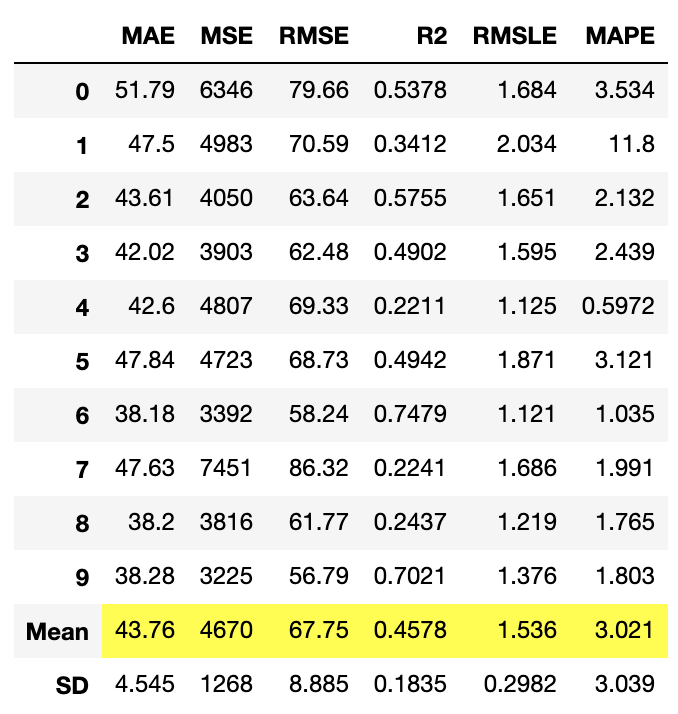
tune_model関数は、事前に定義された探索空間上でランダムグリッド探索を使用して、モデルのハイパーパラメータを自動的に調整します。
出力は、MAE、MSE、RMSE、R2、RMSLE、MAPEをスコアグリッドで表示します。また、tune_model関数でcustom_gridパラメータを渡すことで、グリッドサーチによるチューニングもできます。
tuned_lr = tune_model(lr, n_iter=50, optimize = 'RMSE')

tuned_catboost = tune_model(catboost, n_iter=50, optimize = 'RMSE')
未来28日の売上を予測する
モデルのチューニングが完了したので、実際に未来28日の売上数を予測してみます。
predict_model関数は、予測に利用するモデルと予測対象期間のデータを渡して予測を行います。それでは早速予測を行い、結果を可視化してみます。
pred_tuned_lr = predict_model(tuned_lr,data=test)
pred_tuned_catboost = predict_model(tuned_catboost,data=test)
pred = pd.DataFrame()
pred['sales'] = pred_tuned_lr['sales']
pred['lr'] = pred_tuned_lr['Label']
pred['catboost'] = pred_tuned_catboost['Label']
pred.plot()
青色が予測したい売上数(正解)です。
赤色が「CatBoost Regressor」で予測した結果で、緑色が「Linear Regression」で予測した結果です。
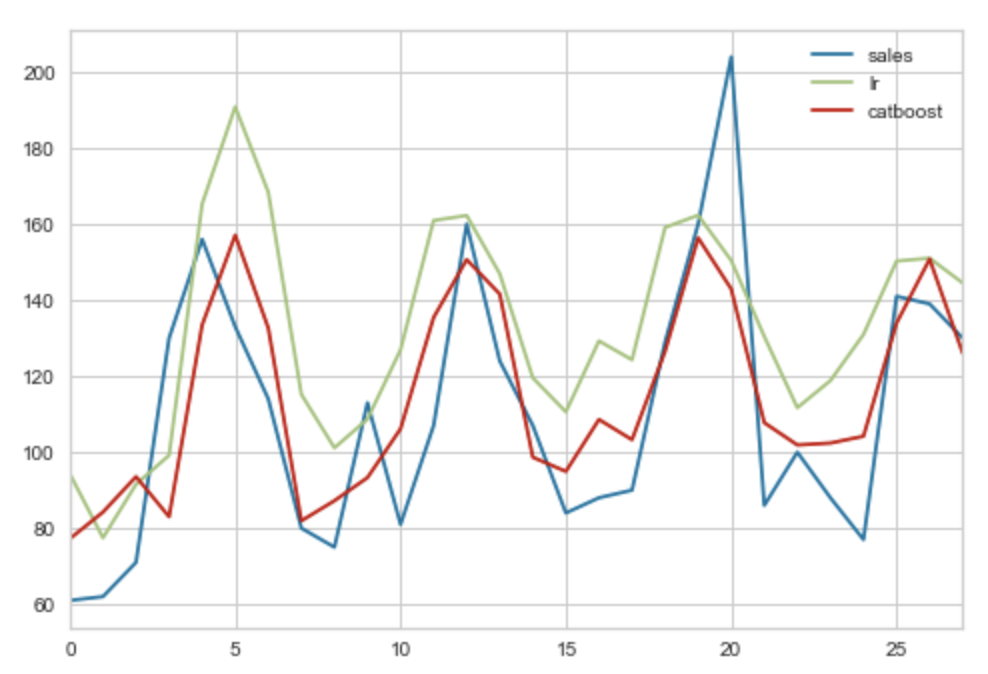
パッと波形をみた感じだと、「CatBoost Regressor」の方が需要を捉えているように見えます。
ただどちらのモデルも、売上数が約200になった日を捉えられていないです。(外れた要因がわかれば説明変数に追加することで精度が上がるかもしれません。)
それでは最後に、どの説明変数が販売数を予測する上で重要だったかを可視化します。
説明変数の重要度をプロットする
plot_model関数を使用して、残差プロット、予測誤差、特徴の重要度など、さまざまな側面から性能を分析することができます。
今回は特徴の重要度をプロットしてみます。
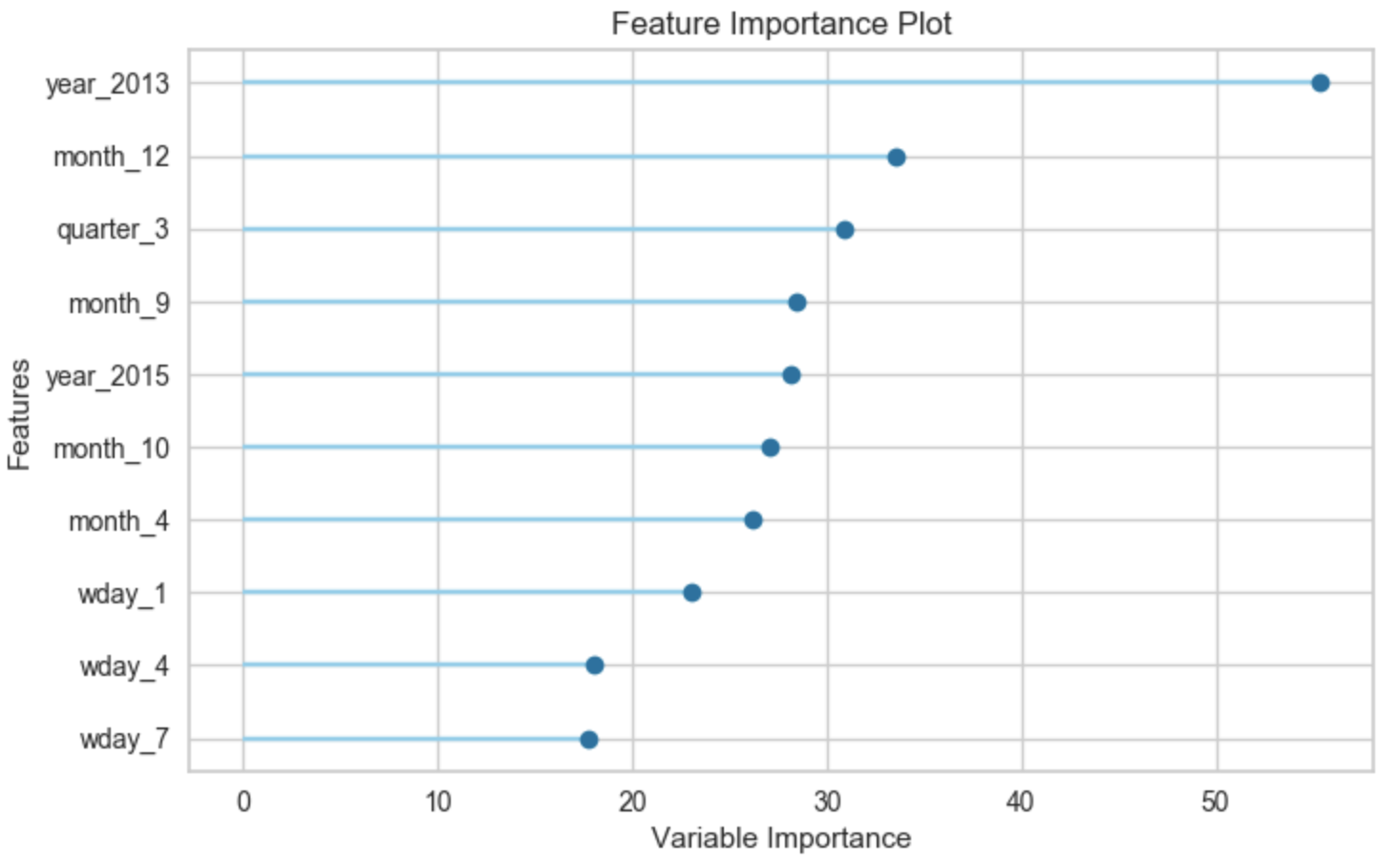
plot_model(tuned_lr, plot = 'feature')
「Linear Regression」において重要度が高い説明変数は、「year_2013」「month_12」「quarter_3」のようなカレンダー系の情報のようです。
plot_model(tuned_catboost, plot = 'feature')
「CatBoost Regressor」において重要度が高い説明変数は、「lag_28」「lag_7」「year_2013」となり、1週間前の実績、4週間前の実績が出てきました。
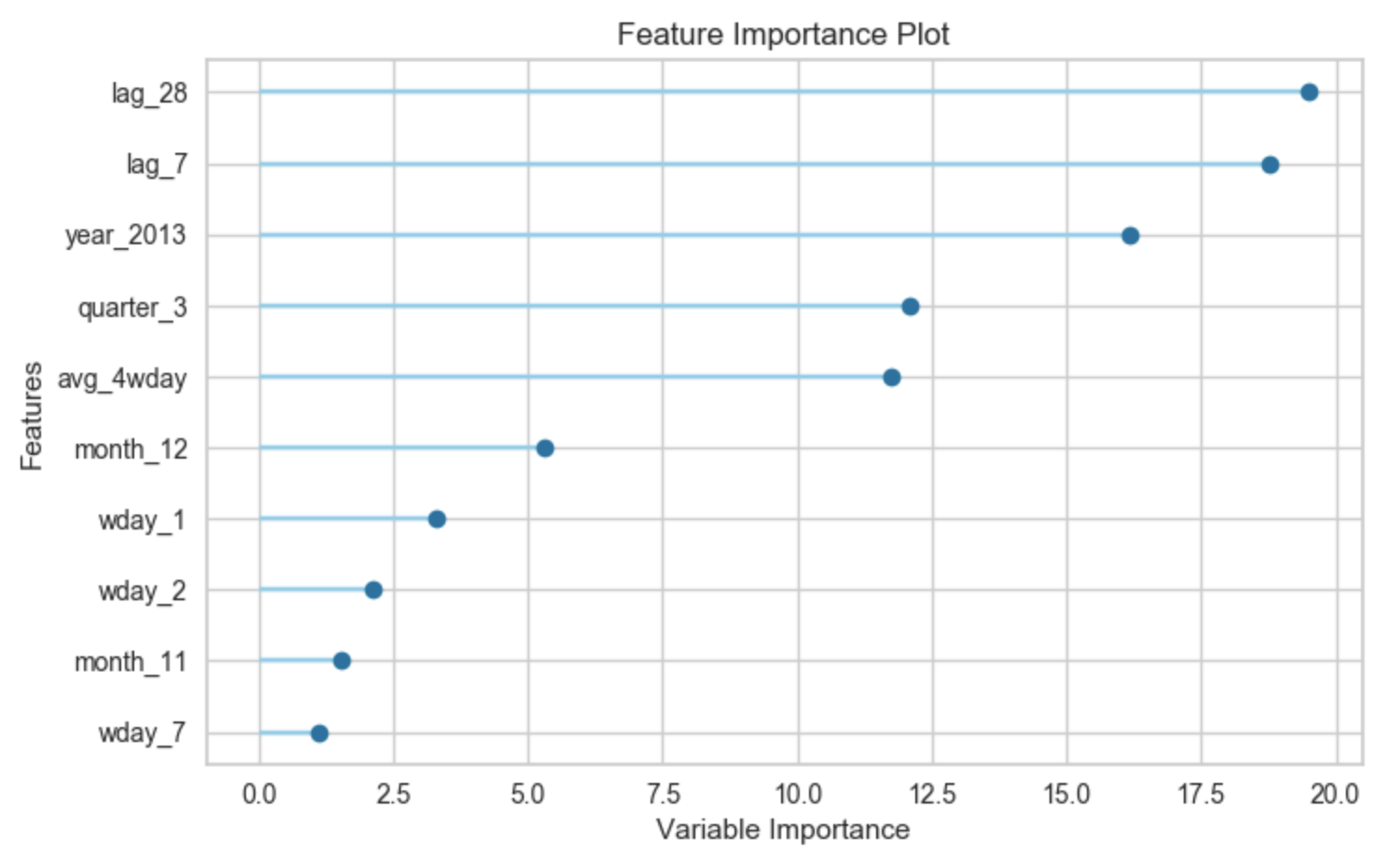
同じ学習データを用いても、モデルによって説明変数の重要度がこれだけ違うのは、興味深いですね。
終わりに
本記事ではPyCaretを使って、実際の小売の実績からモデルを生成し予測してみました。少ないコードだけでモデルの生成や予測、モデルの評価ができる点が素晴らしいですね。
データが揃っている状態で、ある値を機械学習で予測できるかどうか検証したい、という場合の初手としては使いやすいのではないかと感じました。