はじめに
KaggleのPublic Kernelには有用なものが多いが、時折超縦長のNotebookに遭遇することがある。
(▲スクロールバーの小ささに絶望する)
こういったKernelを作ると後々見返すのがツライので、Public Kernelをうまく活用しつつ、自分流で見通しのよいKernelが書けるよう意識していることを紹介してみる。
結論
- 可視化を最小限にする
- 処理の中心となるオブジェクトを明らかにする
- キーを意識する
- 処理を関数にまとめる
1. 可視化を最小限にする
可視化はEDA用のKernelに書き、学習用のKernelでは可視化を最小限にしている。
Public Kernelの中には特徴量を生成する根拠を残しておくため、可視化と特徴量生成が同じKernelに書かれていることが多く第三者がKernelを読む上では非常に重要なのだが、[データ加工]と[可視化]という目的の違うコードが混じってしまう & 出力される図表がかなりの行数をとってしまうため。
2. 処理の中心となるオブジェクトを明らかにする
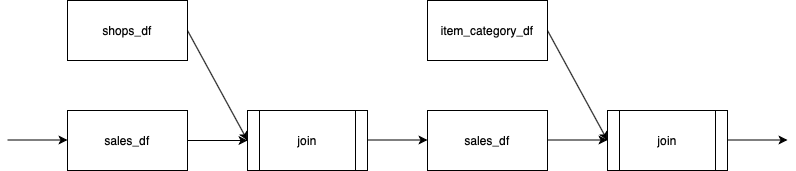
特徴量生成でよくあるのが、処理の中心となるオブジェクト(DataFrame)があり、そこに他のDataFrameを結合して情報を付与していくことで列が増えていくパターン。
処理の中心となる(=後続に繋がる)DataFrameと、その場しか使わないDataFrameを見分けるようにするとデータの流れを捉えやすい。
以下の例ではsales_dfが処理の中心で、shops_dfやitem_category_dfからそれぞれ情報を付与している。
# Input: sales_df
# date item_id num shop_id
# 0 20201201 500 1 100
# 1 20201202 501 2 101
# 2 20201203 502 5 102
# Input: shops_df
# shop_id shop_name
# 0 100 shop-1
# 1 101 shop-2
# 2 102 shop-3
# Input: item_category_df
# item_id category
# 0 500 food
# 1 501 drink
# 2 502 cloth
# 店の情報を付与
sales_df = sales_df.join(shops_df.set_index('shop_id'), on='shop_id', how='left')
# 商品カテゴリの情報を付与
sales_df = sales_df.join(item_category_df.set_index("item_id"), on="item_id", how="left")
# Output: sales_df
# date item_id num shop_id shop_name category
# 0 20201201 500 1 100 shop-1 food
# 1 20201202 501 2 101 shop-2 drink
# 2 20201203 502 5 102 shop-3 cloth
3. キーを意識する
pandas.DataFrameのメソッドはSQLライクな操作を行うので, キーを指定して処理することが多い。キーを意識して読むとやりたいことが分かる。
- 主キー
- 集約キー(groupby)
- 結合キー(join, merge)
例えば以下の例ではsales_dfにshops_dfから情報を付与するためjoinを使用する。キーはon="shop_id"を指定しているので、店ごとの情報を付与していることがわかる。
# 例. "shop_id"列をキーに結合する場合
sales_df = sales_df.join(shops_df.set_index("shop_id"), on="shop_id", how="left")
4. 関数にまとめる
比較的長い処理や繰り返し使う処理は関数にまとめてしまうとよい。
全ての処理を関数化する必要はないのでお好みで。
- 処理のinput/outputが明確になる
- 同じ処理を使い回しやすい
- 中間DataFrameをいちいち削除しなくてもメモリを圧迫しない
といったメリットがある。
# 例. 店の情報を付与する関数
def add_shops(df, shops_df):
return df.join(shops_df.set_index('shop_id'), on='shop_id', how='left')
sales_df = add_shops(sales_df, shops_df)