この記事はタイタニック号をデータ分析する投稿の第三章になります!
記事全体を通して、データ解析やタイタニック号の生還にどのような因果関係があるか調べていきます!
以前の記事はこちらからご確認区ください!
①章
②章
準備するもの
・python3系(Python 3.5.2 |Anaconda 4.2.0 (x86_64))
・anacondaで科学計算ライブラリをインストール
・dataset:seabornにあるtitanic号のデータ
・jupyternotebook(他の方法でも出来ますが、このやり方がインタラクティブでおすすめです!)
知れること
今回の章では家族(子供、兄弟)でタイタニック号に乗船した人々は、生存率が高かったかどうかを調べることにしたいと思います!
目的1:家族連れだったかどうか(yes or no)を値に持つ、'family'というカラムを作成する。
目的2:countplotやfactorplotを利用してデータを描画し、事故後の生還に家族連れだったことがつながっているか調べる。
前回と同様にライブラリのインポートを始めます!
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
データのインポートを行います!
titanic_dataframe = sns.load_dataset('titanic')
kaggleのtitanic号に関するcsvを持っている方は、csvを同じディレクトリにおいて呼び出すことも出来ます!
# pandasをつかってcsvを呼び出す
titanic_df = pd.read_csv('csvの名前')
データセットの中身を調べてみます!
titainic_dataframe.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 15 columns):
survived 891 non-null int64
pclass 891 non-null int64
sex 891 non-null object
age 714 non-null float64
sibsp 891 non-null int64
parch 891 non-null int64
fare 891 non-null float64
embarked 889 non-null object
class 891 non-null category
who 891 non-null object
adult_male 891 non-null bool
deck 203 non-null category
embark_town 889 non-null object
alive 891 non-null object
alone 891 non-null bool
dtypes: bool(2), category(2), float64(2), int64(4), object(5)
memory usage: 80.2+ KB
"""
目的1:家族連れだったかどうか(yes or no)を値に持つ、'family'というカラムを作成する。
まずは、前回と同様に、どのようなカラムがあるか確認してみましょう!
titanic_dataframe.head()
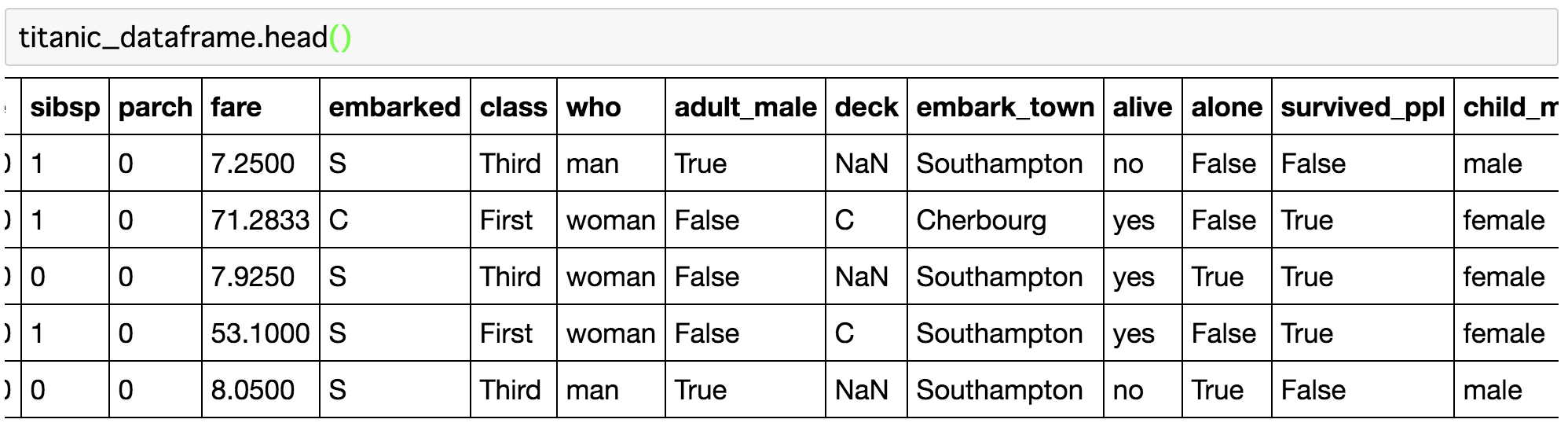
どうやら、aloneというカラムが、家族と一緒に乗っていたかを示しているようです。
それ以外に、sibsp(兄弟の有無についてのカラム)、parch(親か子供がいたかというカラム)があるそうです。
parchは「何かを船上で購入した(purchase)」という意味ではないので、ご注意ください!
それでは、データを作成する方法を見ていきましょう!
titanic_dataframe['family'] = titanic_dataframe.sibsp + titanic_dataframe.parch
先程あげたコードですが、兄弟の有無と親や子供の有無をfamilyカラムに代入しています!
この値を条件ごと(0であればno,0以上でればyes)に入れるプログラミングをしていこうと思います。
そのまえに、ちゃんと値が入っているか確認してみましょう!
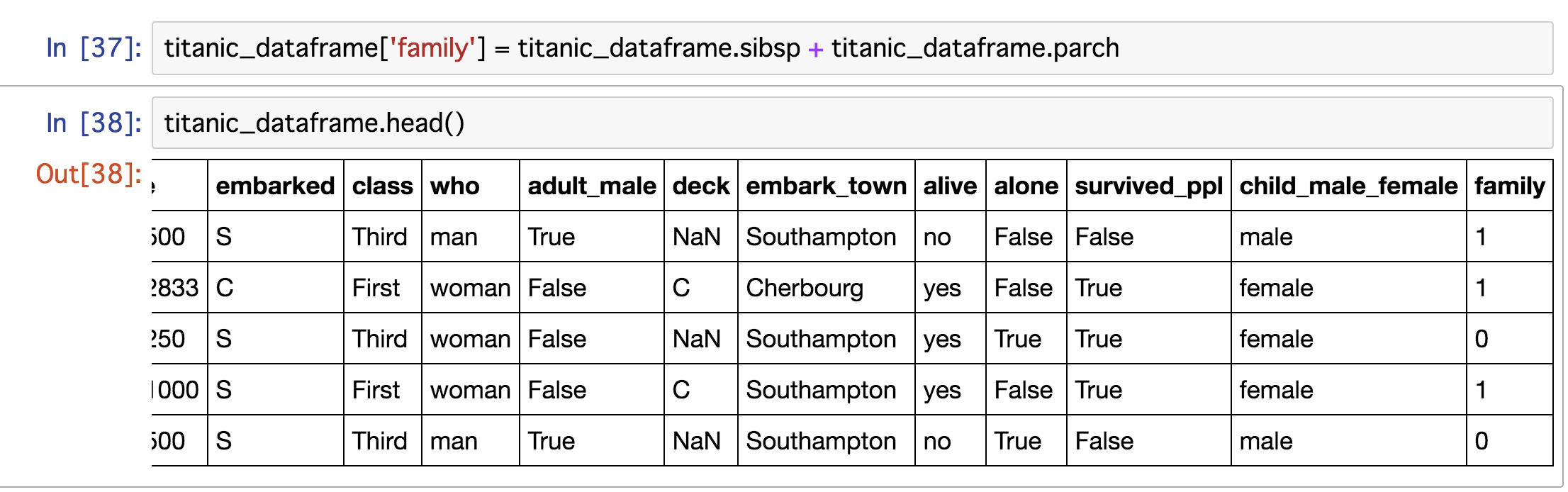
合計した値が0と1しかありません。
合計値を代入しているので、4や3などの数字があってもおかしくないはずです。
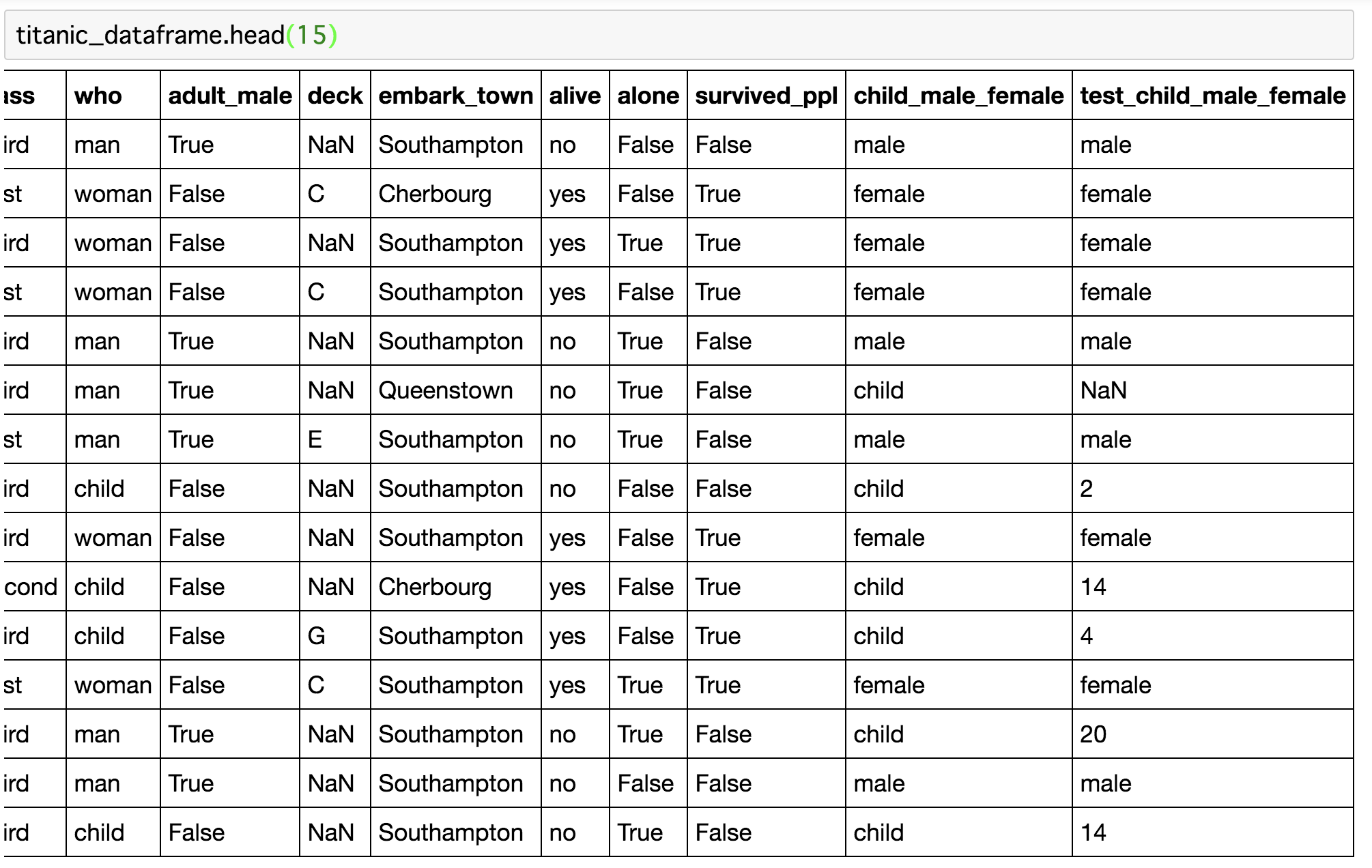
head関数の引数に15を渡して、頭から15行目までを調べてみましょう。
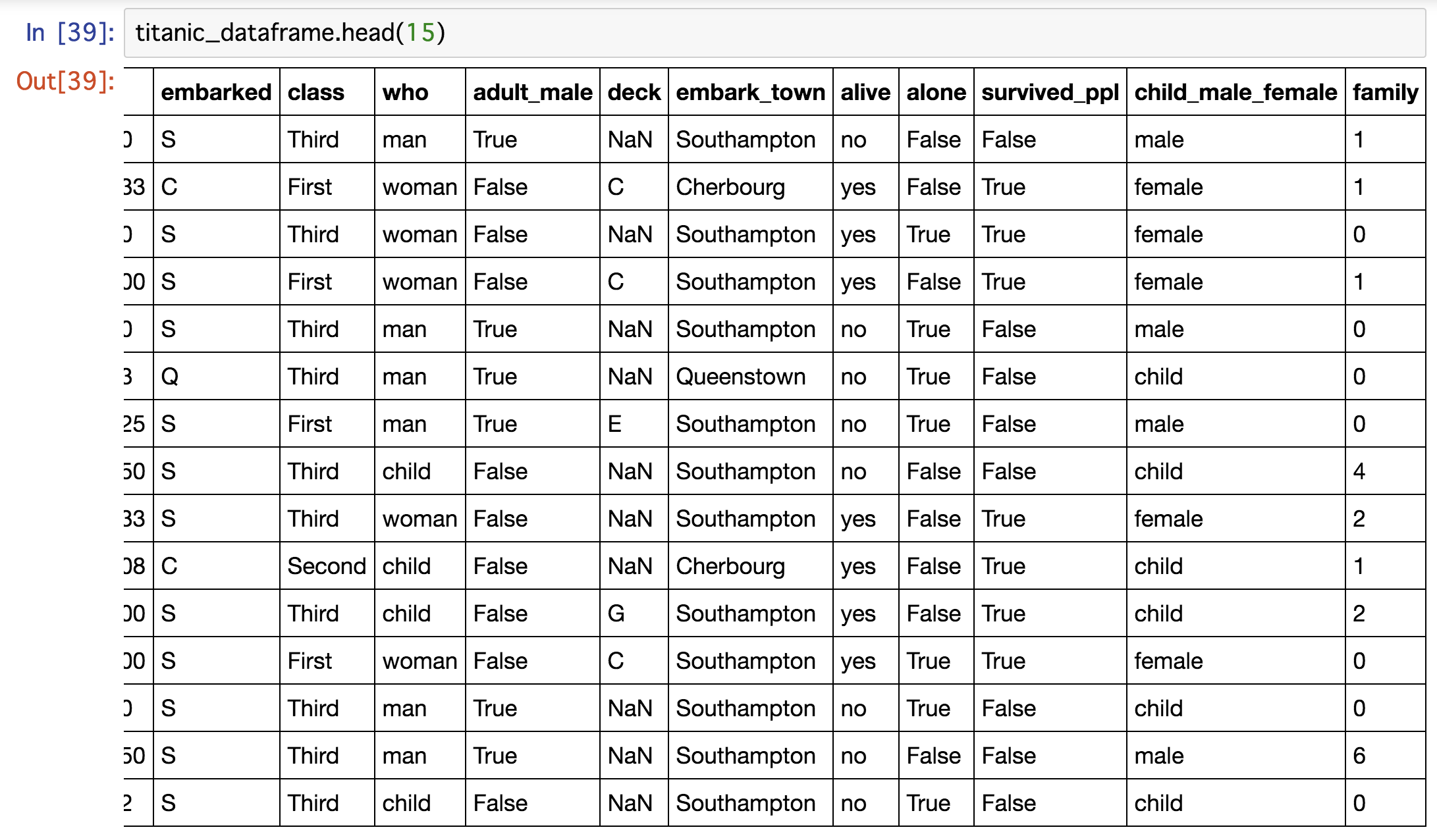
2,4,6などの数字が入っていることが確認できますね!
次は値を条件文ごとに入れ替える方法を記載していきます!
# familyの値が0以上の場合、家族がいることになるのでyesを入れる
titanic_dataframe['family'].loc[titanic_dataframe['family'] > 0] = 'yes'
# familyの値が0と同じ場合、家族がいないことになるのでnoを入れる
titanic_dataframe['family'].loc[titanic_dataframe['family'] == 0] = 'no'
そして、何故かわかりませんが、titanic_dataframe['family'].loc[titanic_dataframe['family'] == 0] = 'no'のコードを後に実行しないと、エラーが出ます!
# 前のコードと実行する順序が逆です!
titanic_dataframe['family'].loc[titanic_dataframe['family'] == 0] = 'no'
titanic_dataframe['family'].loc[titanic_dataframe['family'] > 0] = 'yes'
"""
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-51-d9eb05c97aa2> in <module>()
1 titanic_dataframe['family'].loc[titanic_dataframe['family'] == 0] = 'no'
----> 2 titanic_dataframe['family'].loc[titanic_dataframe['family'] > 0] = 'yes'
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
エラーの詳細は長いので省略します。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
pandas/lib.pyx in pandas.lib.scalar_compare (pandas/lib.c:14261)()
TypeError: unorderable types: str() > int()
"""
integerに対しての条件文なのに、文字列入れないでくれよ!ということですね。
head関数で、どうなっているか調べてみましょう。
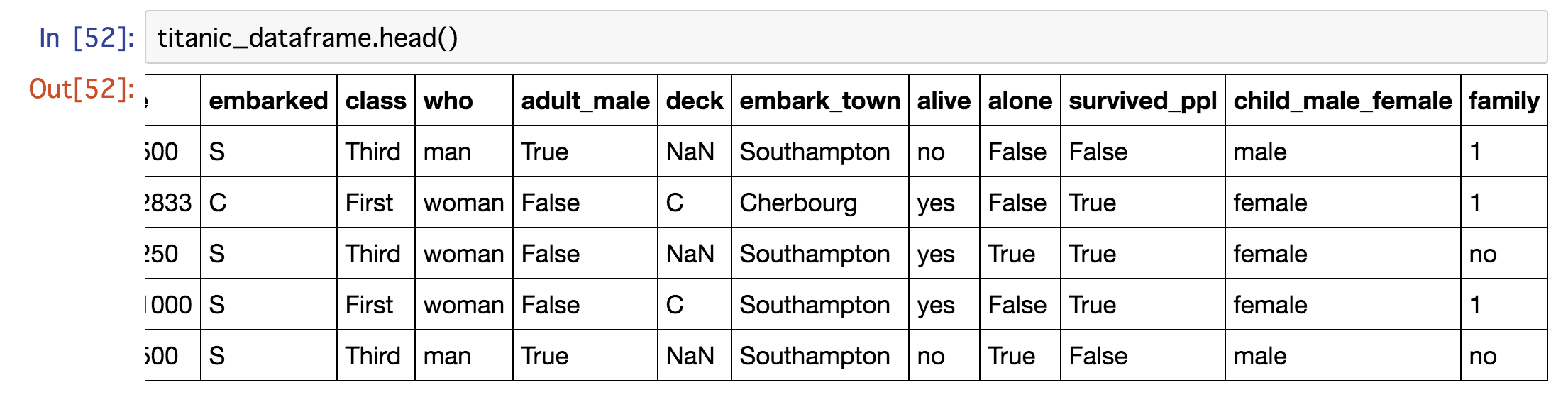
どうやら、noだけが先に入ってしまったことが原因のようです。
詳しい理由はわからないので、誰かわかるかたがいらっしゃったらおしえていください!!
もう一つわからないことがあったんですが、二章で20歳以上であれば性別を、以下であればchildを値に持つカラムを作成する際に、このようなコードを書きました。
titanic_dataframe['test_child_male_female'] = titanic_dataframe.age
titanic_dataframe['test_child_male_female'].loc[titanic_dataframe['test_child_male_female'] > 20] = titanic_dataframe.sex
titanic_dataframe['test_child_male_female'].loc[titanic_dataframe['test_child_male_female'] <= 20 ] = 'child'
しかし、実行すると同じエラーが出ました。
TypeError Traceback (most recent call last)
<ipython-input-55-5d5b8c27f669> in <module>()
2
3 titanic_dataframe['test_child_male_female'].loc[titanic_dataframe['test_child_male_female'] > 20] = titanic_dataframe.sex
----> 4 titanic_dataframe['test_child_male_female'].loc[titanic_dataframe['test_child_male_female'] <= 20 ] = 'child'
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
エラーの詳細は長いので省略します。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
pandas/lib.pyx in pandas.lib.scalar_compare (pandas/lib.c:14261)()
TypeError: unorderable types: str() <= int()
head関数で値を確認してみましたが、childだけがうまくいっていないようです。
Anyway!!
とにかく!新しいカラムが作成できたので、目的2に進もうと思います!
目的2:countplotやfactorplotを利用してデータを描画し、事故後の生還に家族連れだったことがつながっているか調べる。
まずは家族で乗船している人がどれだけいたか調べてみます!
くわしいcountplotのやり方は、第一章をご確認ください!
# countplot
sns.countplot('family', data=titanic_dataframe, palette='Set2')
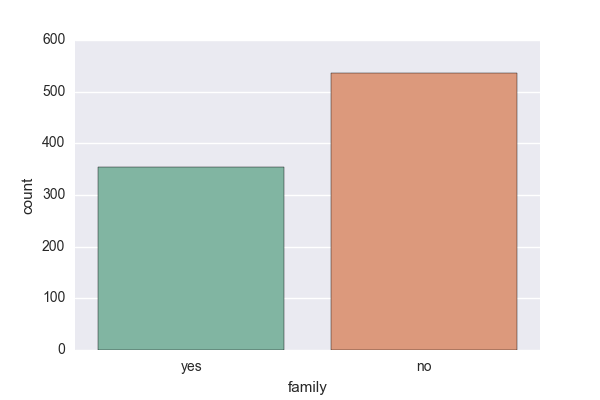
家族連れは全体に見ると少なかったようです!
次に乗船階級別に、家族で乗船している人がどれくらいいたのか調べてみます!
# countplot
sns.countplot('family', data=titanic_dataframe, hue='pclass', palette='Set2')
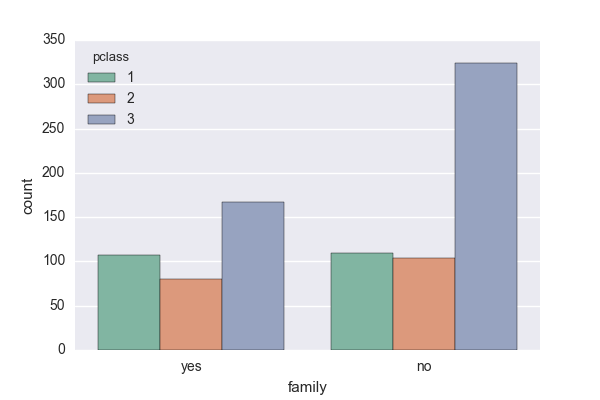
第1,第2階級に乗船されている方は、家族連れと独身の方が同等の人数いたようですが、第3階級に乗船されている方は、独り身の方が圧倒的に多かったようです!
生還したことが、家族連れだったことと関係があるか調べます!
# countplot
sns.countplot('survived_ppl', data=titanic_dataframe, hue='family', palette='Set2')
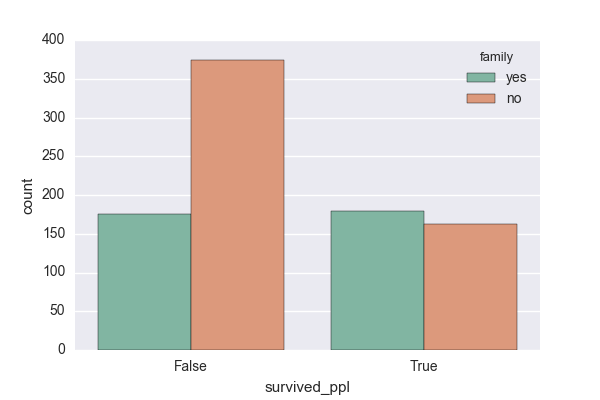
独身の方で亡くなられた方は多いようですが、家族連れだったことが生還の理由になったかどうかはわかりません。
次は2章でご紹介したfactorplotでデータを描画してみましょう!
factorplotを利用して、家族連れだったことが生還の理由になったかどうか調べる
# factorplot
sns.factorplot('family', 'survived', data=titanic_dataframe, aspect=3, palette='Set2',legend=True, hue='child_male_female')
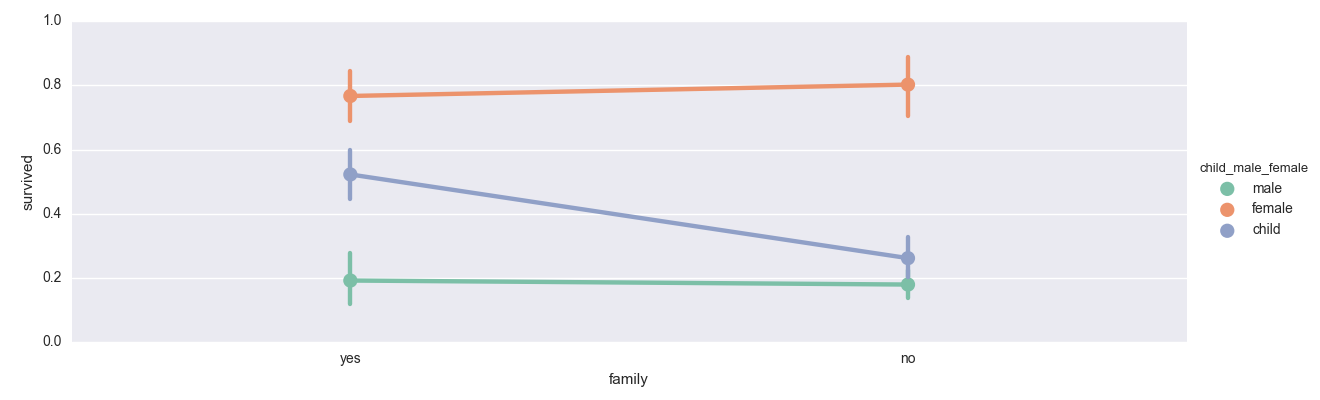
大変不幸な話ですが、女性と男性に関しては家族がいたことが生還の理由になったかというと曖昧です。
しかし、子供は家族がいたことが生還の理由になったと考えることが出来るのではないでしょうか!
おわりに
まだまだわからないことがたくさんある(特にデータ処理)ので、どのような描画方法がどのような場面に適しているのかをしっかり理解するのが今後の目標になるかなと思っています!
統計学の勉強も楽しいですが、描画方法やデータの因果関係を見つける方法を少しづつ理解できるようになり少しうれしいです!
これからも投稿していくので、もしよかったらまた見に来てください(^^)!
最後までありがとうございました!