TL;DR
- 線形回帰モデルをベイズ的に扱うことにより、回帰モデルの重み$w$の事後分布や予測値$t$の事後分布が得られる
3.3 ベイズ線形回帰
解こうとする問題に合わせてモデルの複雑さ(基底関数の数)を決める必要があるが、3.2節までの内容から、最尤推定では複雑すぎるモデル(過学習)が選ばれる危険性があることが分かった。
そこで、線形回帰モデルをベイズ的に扱うことでモデルの複雑さを自動的に決定する方法をこれから示していく。
3.3.1 パラメータの分布
ベイズ的に$w$の分布を推定したいので、まずは$w$の事前分布を導入する(こうだと前提を置いて決めてしまう)。
尤度
訓練データ集合$X$, 重み$w$が固定されているとしたときに、目標変数集合$\mathbf{t}$が得られる確率(=尤度)は、すでに3.1.1節の式(3.10)で導出している。
$$
p( \mathbf{t} | X, w, \beta ) = \prod_{n=1}^N N(t_n | w^T \phi(x_n), \beta^{-1} ) \tag{3.10}
$$
事前分布
尤度関数のexpの中身が$w$の二次関数(ガウス)となっているので、事前分布もexpの中身が$w$の二次関数となるようにすると事後確率もガウスとなって計算が簡単(共役性)。なので、事前分布は以下のようなガウス分布とする。
$$
p(w) = N(w | m_0, S_0) \tag{3.48}
$$
事後分布
事後分布は尤度関数と事前分布の積に比例すること、共役性により事後分布もガウス分布になることを用いると以下の結論を導出できる(導出過程は下記の演習3.7で)。
\begin{align}
p(w | \mathbf{t} ) &= N(w | m_N, S_N) \tag{3.49} \\
m_N &= S_N (S_0^{-1} m_0 + \beta \Phi^T t) \tag{3.50} \\
S_N^{-1} &= S_0^{-1} + \beta \Phi^T \Phi \tag{3.51}
\end{align}
事前分布の共分散行列$S_0$が無限に大きい($w$の分布に関する事前情報がない)場合、$S_0^{-1} = 0$となることから、
\begin{align}
S_N^{-1} &= 0 + \beta \Phi^T \Phi \\
&= \beta \Phi^T \Phi \\
S_N &= ( \beta \Phi^T \Phi )^{-1} \\
m_N &= S_N ( 0 + \beta \Phi^T t) \\
&= ( \beta \Phi^T \Phi )^{-1} ( \beta \Phi^T t) \\
&= ( \Phi^T \Phi )^{-1} \Phi^T t
\end{align}
となり、最尤推定解の式(3.11)と等しくなった。
つまり、事前分布という概念がない最尤推定による解と、分散が無限という事前情報がないことを示す事前分布を用いたときのMAP推定1による解が等しくなった!
また、2.3.5節と同じ逐次推定の考え方も用いることができる。つまり、
- データが1つも観測されていないときの、狭義での事前分布がある。
- 1つめのデータが観測されたら、事前分布と尤度の積で事後分布が求まる
- 2つめのデータが観測されたら、1つめのデータ観測後の事後分布を事前分布として、
事前分布と尤度の積で事後分布が求まる - 3つめのデータが観測されたら、2つめのデータ観測後の事後分布を事前分布として、
事前分布と尤度の積で事後分布が求まる - 以後同様...
逐次更新を視覚的に理解する
以降は簡単のために、$w$の事前分布を単一の精度パラメータ$ \alpha $で記述できるガウス分布とする。
$$
p(w | \alpha ) = N(w | 0, \alpha^{-1} I ) \tag{3.52}
$$
直線フィッティングの例を考えよう。$ y = -0.3 + 0.5 x$という真の直線にガウスノイズを加えた値が観測できる条件下で、線形モデル$ y(x, w) = w_0 + w_1 x $の重み$w_0, w_1$がどのように逐次推定されるかを見ていく。
観測値が1つもない状態での$w$の事前分布は式(3.52)なので、下図1行目中央のように中心が原点のガウスノイズ。この分布から$w$をいくつかサンプリングして$ y(x, w) = w_0 + w_1 x $を何本か引いたものが1行目の右。$w$はいろんな値をとりうるので、直線もいろんな方向に引かれている。
次に2行目右の青丸で示される観測値が得られたとしよう。青丸を通るような直線の重みは下々図の青線のようにたくさんある。このような重みは尤度が高くなり、2行目左のようになる。この尤度と事前分布の積で得られる事後分布は2行目中央となる。
事前分布より事後分布の方が狭くなっている。数学テクニックを使うことで、**事後分布は事前分布より必ず狭くなる(新しいデータを観測すると事後分布は必ず狭くなる)**ことが証明できる(らしい。演習3.11)。
この事後分布より$w$をいくつかサンプリングして直線を数本引いたのが2行目右。事後分布が狭まった影響で直線の向きが1行目よりまとまっていて、さらに青丸付近を通る直線が増えていることが分かる。
さらに2個目の観測値が得られた様子が3行目に示されている。以後同様。観測値を得るごとに事後分布が狭まり、線形モデル(の傾き、切片)もだんだんと似たものが増えていく様子が分かる。


3.3.2 予測分布
実際の場面では$w$の分布ではなく、目標変数である$t$の分布が知りたい。最尤推定で$w$がただ1つの値に決まっているならば、式(3.8)の目標変数の条件付き分布$ p(t | w, \beta) $と使えばよいのだが、ベイズ予測だと$w$は分布となっているので、以下の式で$w$に関する積分をとって、あらゆる$w$に関する平均の$t$の分布の平均のようなものを計算する。これは予測分布 (prdictive distribution) と呼ばれる。
\begin{align}
p(t | \mathbf{t} , \alpha, \beta ) &= \int p(t | w, \beta) p(w | \mathbf{t}, \alpha, \beta ) dw \tag{3.57} \\
p(t | w, \beta) &= N(t | y(x,w), \beta^{-1} ) \tag{3.8} \\
p(w | \mathbf{t}, \alpha, \beta ) &= N(w | m_N, S_N ) \tag{3.49}
\end{align}
式(3.57)は2つのガウス分布$p(t|w) \times p(w) = p(t, w)$から同時分布$p(w)$を求める計算と同じなので、2.3.3節のガウス変数に対するベイズの定理 で導出した定理が使える。
下図中の式のように、2.3.3節の変数を本節の変数にそのまま置き換えるとテキスト(3.58, 3.59)の予測分布が導出できる。

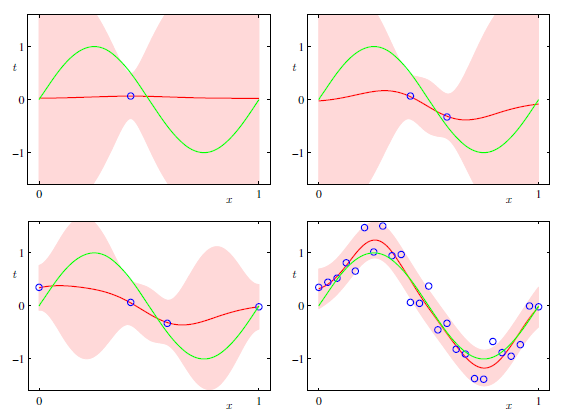
これで目標変数$t$の予測分布がガウス分布で表すことが出来た。横軸を$x$, 縦軸を$t$ととり、観測データ数が増えたときの予測分布の平均および平均±標準偏差を示したのが下図になる。
Python, Rなどにある回帰ライブラリを使うと下図ピンク領域のように、「この範囲に値が収まる確率が90%(90%信頼区間)」というものを図示してくれることがよくある。今回のようにガウス分布な予測分布2であれば、ガウスの平均±数シグマで信頼区間が簡単に求められる。ライブラリの内部でもこのような計算が行われているのだろう(自信ない)
3.3.3 等価カーネル
ここは6章で出てくるガウス過程の導入にあたる節...なのだが、あまり理解できないのでさらっと。
3.3.1節で導入した$w$の事後分布の平均は以下であった。
$$
m_N = S_N (S_0^{-1} m_0 + \beta \Phi^T t) \tag{3.50}
$$
事後分布はガウス分布なので、事後確率が最大となるのは期待値。つまり、事後確率を最大にする重み$w_{MAP}$は$m_N$である(MAP推定)。
なので$w=m_N$として線形モデル$ y(x, w) = w^T \phi(x) $に代入しよう。すると、
$$
y(x, m_N) = \sum_{n=1}^N \beta \phi(x)^T S_N \phi(x_n) t_n \tag{3.60}
$$
となり、パラメータ$w$を用いずに、訓練データ集合のみから予測値が得られるように変形できた。
式(3.60)右辺は訓練データの目標変数$t_n$の線形結合となっているので、
\begin{align}
y(x, m_N) &= \sum_{n=1}^N k(x, x_n) t_n \tag{3.61} \\
k(x, x') &= \beta \phi(x)^T S_N \phi(x') \tag{3.62}
\end{align}
と書き直すことができ、式(3.62)の関数を等価カーネルと呼ぶ。
式(3.62)の右辺は、係数$\beta$とベクトル$ \phi(x) $と$ \phi(x') $の要素の線形和$ \phi_0(x) \phi_0(x') + \phi_1(x) \phi_1(x') + \cdots $に共分散行列$S_n$の要素が重みのようにかけられた$ s_0 \cdot \phi_0(x) \phi_0(x') + s_1 \cdot \phi_1(x) \phi_1(x') + \cdots $となっている。
これは$ \phi(x) $と$ \phi(x') $の内積のようなものなので、これら2つのベクトルが似ているときに大きな値をとる。すなわち、等価カーネル$ k(x, x') $は2入力$x, x'$が似ているときに大きな値を返す類似度のような指標であると見れる。
次に式(3.61)を見ると、等価カーネルと(訓練データの)目標変数の積が訓練データの数だけシグマで足しあわされている。つまり、評価を行いたい入力データ$x$とある訓練データ$x_i$が似ていれば$x_i$に対応した目標変数$t_i$に大きな重み、逆に$x$とある訓練データ$x_j$が似ていなければ$t_j$に小さな重みをつけて、訓練データの目標変数の重み付き総和で目標値を予測している。
等価カーネルは、新しいデータの予測値を算出するたびに、すべての訓練データとの内積を計算するため計算量が多く、あまり実用的でない。この課題に対するアプローチが6章で学ぶガウス過程である(?)
演習3.7 事後分布の導出
事前分布は
$$
p(w) = N(w | m_0, S_0 ) \propto \exp \left\{ - \frac{1}{2}
(w - m_0)^T S_0^{-1} (w - m_0)
\right\}
$$
尤度は
$$
p( \mathbf{t} | w ) = \prod_{n=1}^N N(t_n | w^T \Phi (x_n), \beta^{-1} )
\propto \prod_{n=1}^N \exp \left\{
- \frac{\beta}{2} \left(t_n - w^T \phi(x_n) \right)^2
\right\}
$$
事後分布は事前分布と尤度の積なので
\begin{align}
p(w | \mathbf{t} ) &\propto \exp \left[
- \frac{1}{2} (w - m_0)^T S_0^{-1} (w - m_0)
\right]
\prod_{n=1}^N \exp \left[
- \frac{\beta}{2} \left(t_n - w^T \phi(x_n) \right)^2
\right] \\
&= \exp \left[
- \frac{1}{2} (w - m_0)^T S_0^{-1} (w - m_0) -
\frac{\beta}{2} \sum_{n=1}^N \left(t_n - w^T \phi(x_n) \right)^2
\right]
\end{align}
この事後分布のexpの中身を$w$の次数ごとに整理していこう。
2次の項は
\begin{align}
- \frac{1}{2} w^T S_0^{-1} w - \frac{\beta}{2} \sum_{n=1}^N \{ w^T \phi(x_n) \}^2
\end{align}
ここで$\sum$を変形しよう。計画行列$\Phi$と$w$の積 $ \Phi w = [ w^T \phi(x_1), w^T \phi(x_2), \cdots ]^T $は$w^T \phi(x_*)$を要素とするベクトルになる。
このベクトルどおしの内積をとれば$ \sum_{n=1}^N { w^T \phi(x_n) }^2 $と同じ演算になるので、テキスト付録の式(C.1)を使うと
$$
\sum_{n=1}^N { w^T \phi(x_n) }^2 = ( \Phi w )^T \Phi w = w^T \Phi^T \Phi w
$$
よって2次の項は
\begin{align}
& - \frac{1}{2} w^T S_0^{-1} w - \frac{\beta}{2} \sum_{n=1}^N \{ w^T \phi(x_n) \}^2 \\
=& - \frac{1}{2} w^T S_0^{-1} w - \frac{\beta}{2} w^T \Phi^T \Phi w \\
=& -\frac{1}{2} w^T ( S_0^{-1} + \beta \Phi^T \Phi ) w
\end{align}
1次の項は
$$
w^T S_0^{-1} m_0 + \beta w^T \sum_{n=1}^N t_n \phi(x_n)
$$
2次の項のときと同じように$\sum$を変形しよう。
$ w^T \sum_{n=1}^N t_n \phi(x_n) = t_1 w^T \phi(x_1) + t_2 w^T \phi(x_2) + \cdots $というスカラーであることを意識し、式(3.50)と同じ形であるベクトル$\mathbf{t}$が右側にある形に変形するには
\begin{align}
\begin{pmatrix}
w^T \phi(x_1) & w^T \phi(x_2) & \cdots
\end{pmatrix}
\begin{pmatrix}
t_1 \\\
t_2 \\\
\vdots
\end{pmatrix}
= w^T
\begin{pmatrix}
\phi(x_1) & \phi(x_2) & \cdots
\end{pmatrix}
\mathbf{t}
= w^T \Phi^T \mathbf{t}
\end{align}
となる。なので1次の項は、
\begin{align}
& w^T S_0^{-1} m_0 + \beta w^T \sum_{n=1}^N t_n \phi(x_n) \\
=& w^T S_0^{-1} m_0 + \beta w^T \Phi^T \mathbf{t} \\
=& w^T ( S_0^{-1} m_0 + \beta \Phi^T \mathbf{t} )
\end{align}
よって、事後分布は
\begin{align}
p(w | t) &\propto \exp \left\{
-\frac{1}{2} w^T ( S_0^{-1} + \beta \Phi^T \Phi ) w +
w^T ( S_0^{-1} m_0 + \beta \Phi^T \mathbf{t} ) + const.
\right\}\\
\end{align}
$w$の2次の項、1次の項にかかっている行列やベクトルを係数を$a, b$と考えると
\begin{align}
& - \frac{1}{2} a w^2 + bw = - \frac{a}{2} \left( w^2 - 2 \frac{b}{a} w \right)
= - \frac{a}{2} (w - b)^2 + const.
\end{align}
と平方完成できる。これを使って事後分布を変形すると
\begin{align}
p(w | t) &\propto \exp \left\{
-\frac{1}{2} w^T ( S_0^{-1} + \beta \Phi^T \Phi ) w +
w^T ( S_0^{-1} m_0 + \beta \Phi^T \mathbf{t} ) + const.
\right\} \\
&= \exp \left\{
- \frac{1}{2} (w - m_N)^T S_N^{-1} (w - m_N) + const.
\right\}
\end{align}
となり、事後分布が式(3.49)~(3.51)で与えられることが示せた。