TL;DR
- 過学習を防ぐため、誤差関数に正則化項をいれてもよい
- 正則化が強い予測モデルでは、真の関数へのフィッティング度合いが下がるが、異なる学習データセットで得られた複数の予測モデルごとのばらつきは小さくなる。逆に正則化が弱いモデルでは、真の関数へのフィッティング度合いが上がるが、複数の予測モデルごとのばらつきが大きくなる。
3.1.4 正則化最小二乗法
前記事でやったこと:
- 一般化線形モデル$y(x, w) = \sum_{j=0}^{M-1} w_j \phi_j (x) = w^T \phi(x)$で
入力$x$から出力$y$を推定するとモデル化 - モデルのパラメータである$w$を最尤推定(3.1.1節)
この節でやること:
- 過学習を避けるため、正則化をいれて$w$を推定(3.1.4節)
過学習を避けるため、重み$w$に正則化を導入しよう。
前節で扱ったデータに依存する誤差を$E_D(w)$、正則化項$をE_W(w)$、正則化項をどの程度重視するかを調整する係数を$\lambda$とする。正則化最小二乗法では誤差関数を以下と定義し、これを最小化する。
$$
E_D(w) + \lambda E_W (w) \tag{3.24}
$$
$E_D (w)$を前節と同じ二乗和誤差、正則化項に重みベクトルの二乗和:
$$
E_W(w) = \frac{1}{2} w^T w \tag{3.25}
$$
を使うとすれば誤差関数全体は1.2.5節「曲線フィッティング再訪」の式(1.67)で導出した式と同じ形になる。
$$
\frac{1}{2} \sum_{n=1}^N \{ t_n - w^T \phi(x_n) \}^2 + \frac{\lambda}{2} w^T w \tag{3.27}
$$
この正則化項の選び方は、データのあてはめに不要と判断された重み$w_i$が減衰 (decay) して0に近づいていくので、機械学習の分野でweight decayと呼ばれる1。これまでやってきた最尤推定と同じやり方($w$に関する勾配=0 の方程式を解く)で解が得られる。
また、式(3.27)の正則化項である$w$の二乗和$w^T w = \sum_{j=1}^M |w_j |^2 $をより一般化し、$\sum_{j=1}^M |w_j |^q $として:
$$
\frac{1}{2} \sum_{n=1}^N \{ t_n - w^T \phi(x_n) \}^2 +
\frac{\lambda}{2} \sum_{j=1}^M |w_j |^q \tag{3.29}
$$
という正則化誤差項が用いられることもある。特に$q=1$の場合はlasso (ラッソ) と呼ばれ、よく用いられる。理由はlassoにより、重みベクトル$w$のいくつかの係数$w_j$が0になりやすい(=実際の予測に使われる基底/特徴が減る)という性質があるから。
この性質について幾何的に解釈しよう。ラグランジェの未定乗数法のテクニックにより、式(3.29)の最小化は正則化項$ \sum_{j=1}^M |w_j |^q $がある一定値以下という制約で二乗和誤差を最小にする、という問題に変換することができる。
まず、$q$の値によって正則化項がどのような等高線を描くかを示すと下図になる。
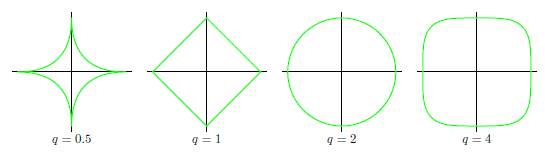
下図赤線および橙領域で表される「正則化項がある値以下」の制約下で二乗和誤差を最小化する問題は、下図青線で表される「二乗和誤差の等高線」と赤線の交点となる。この図より(2次元の場合)、lassoでは$w_1$あるいは$w_2$が0となる重み$w^*$が選ばれやすいことが直観的に分かる。
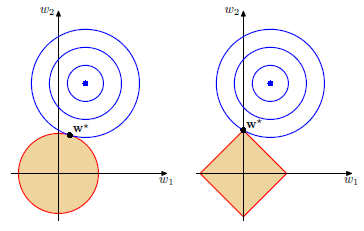
正則化係数$\lambda$をどう決めるの議論は3.3節「ベイズ線形回帰」で扱う。
3.1.5 出力変数が多次元の場合
ここまでは多次元の入力$\mathbf{x}$から1次元(スカラー)の目標変数$t$を予測する問題を考えた。
$$
t = y(x, w) + \epsilon = w^T \phi(x) + ノイズ \tag{3.7}
$$
では、$t$が$K$次元(2次元以上)のときはどう扱うかが本節の内容。
- $t$が$K$次元になる分、$M$次元ベクトルだった重み$w$は$M \times K$の行列$W$になる
- $t$が$K$次元になる分、データ数$N$個の目標変数$ (t_1, \cdots, t_N)^T$をまとめた
$N$次元ベクトル$\mathbf{t}$は$N \times K$行列$T$で表現される
という次元の変更はあるものの、式変形は目標変数が1次元のときと同様。対数尤度関数を行列$W$について偏微分=0 の方程式を解く。これにより:
$$
W_{ML} = ( \Phi^T \Phi )^{-1} \Phi^T T \tag{3.34}
$$
という最尤推定解が得られる。
3.2 バイアス - バリアンス分解
この節で言いたいことは
-
期待損失は以下の3項に分解できる
- 予測値と理想的な回帰関数がどれくらい離れているかを表すバイアスと呼ばれる項
- 予測値がデータ集合によってどれくらいばらつくかを示すバリアンスと呼ばれる項
- データに含まれる本質的なノイズに起因し、我々ではどうにもできない項
-
例えばたくさんの基底関数を使ったモデルみたいな、表現力が高いモデルは理想的な回帰関数にあてはまりやすくなるので、バイアスが小さくなる。一方、データのノイズにも過剰にあてはまるので、データ集合によって予測値がばらつき、バリアンスが大きくなる。
-
逆に、表現力が低いモデル(例えば1次モデル)では、理想的な回帰関数にあてまはりにくくなるので、バイアスが大きくなる。が、予測値のばらつきはあまりなくなるので、バリアンスは小さくなる。
-
結局バイアスとバリアンスはトレードオフの関係である。
この内容を数式変形を混ぜながら示していく。
1.5.5節「回帰のための損失関数」の議論も使うので、ここから始めよう。
損失関数を二乗誤差$ \{ y(x) - t \}^2 $としよう。あらゆる観測値$x$、あらゆる目標変数$t$での期待損失(平均損失)は
$$
\mathrm{E}[L] = \int \int \{ y(x) - t \}^2 p(x, t) dx dt \tag{1.87}
$$
と書けるのだった。ここで積分の中身の二乗の項を変形しよう。
\begin{align}
\{ y(x) - t \}^2 &= \{ y(x) - \mathrm{E}[t|x] + \mathrm{E}[t|x] - t \}^2 \\
&= \{ y(x) - \mathrm{E}[t|x] \}^2
+ 2 \{ y(x) - \mathrm{E}[t|x] \} \{ \mathrm{E}[t|x] - t \}
+ \{ \mathrm{E}[t|x] - t \}^2
\end{align}
なので式(1.87)は以下に書き直せる:
\begin{align}
\mathrm{E}[L] &= \int \int \{ y(x) - \mathrm{E}[t|x] \}^2 p(x,t) dxdt \tag{a} \\
&+ \int \int 2 \{ y(x) - \mathrm{E}[t|x] \} \{ \mathrm{E}[t|x] - t \} p(x,t) dxdt \tag{b} \\
&+ \int \int \{ \mathrm{E}[t|x] - t \}^2 p(x,t) dxdt \tag{c}
\end{align}
式(a)は$ \{ y(x) - \mathrm{E}[t|x] \}^2 $の部分が$t$によらない項2であることに留意すれば$t$に関する積分の際は定数とみなせるので
\begin{align}
(a) = \int \{ y(x) - \mathrm{E}[t|x] \}^2 \left(
\int p(x,t) dt
\right) dx
= \int \{ y(x) - \mathrm{E}[t|x] \}^2 p(x) dx \tag{a2}
\end{align}
式(b)は結論からいうと0になる3。(b)のうち、$ \{ \mathrm{E}[t|x] - t \} p(x,t) $の部分が$t$による項なので、ここだけを考えよう。話を簡単にするため、$x$に関する積分の表記を略して
\begin{align}
\int \{ \mathrm{E}[t|x] - t \} p(x,t) dt
&= \int \mathrm{E}[t|x] p(x,t) dt - \int t p(x,t) dt \\
&= \mathrm{E}[t|x] \int p(x,t) dt - \int t p(t|x) p(x) dt \\
&= \mathrm{E}[t|x] p(x) - p(x) \int t p(t|x) dt \\
&= \mathrm{E}[t|x] p(x) - p(x) \mathrm{E}[t|x] = 0
\end{align}
この結果より、式(b)は0になる。
さて、$\mathrm{E}[L]$を最小にする理想の回帰関数$h(x)$は1.5.5節、式(1.89)の議論により条件付き期待値$E[t|x]$で与えられる。なので、これまでの式変形の結果の$E[t|x]$を$h(x)$に置き換えるとようやく3.2節の以下の式が導出できる。
$$
\mathrm{E}[L] = \int \{ y(x) - h(x) \}^2 p(x) dx +
\int \int \{ h(x) - t \}^2 p(x,t) dx dt \tag{3.37}
$$
式(3.37)の第2項は、我々が作った予測モデル$ y(x) $を含まず、純粋に理想の回帰関数と目標変数の二乗差なので、データに含まれる本質的なノイズ。達成可能な最小の期待損失の値と解釈できる。
第1項は予測モデルに直接的に依存するため、この項を最小にする関数を求めたい。
次に、予測モデルの不確実性を評価することを考える。ベイズの考え方(ベイズ推定)では予測モデルの不確実性は予測モデルの重みパラメータ$w$の事後確率分布で表現される(例えば、$w$の事後分布の分散が大きい=$w$がいろんな値をとりうる=不確実性が高い)。
ここでは頻度主義の考え方による最尤推定を行っており、重みパラメータ$w$は(分布でなく)1つの値に点推定されるので、予測モデルの不確実性を別の方法で評価する。
その方法とは、まず複数の学習データセット$D_1, \cdots, D_N$を用意する。予測モデル$ y(x) $は学習データが変わると異なる重みをとる関数になるので、$D$に依存していることを明示するため$y (x; D)$と表記する。関数が異なるので二重損失の値も異なることに留意。
二重損失が学習データによって変わるので、予測モデルの不確実性である期待損失を、いろんな学習データセットで得られた損失の平均値としよう(=データ集合の取り方に関する期待値)、というのが最尤推定による不確実性の評価方法。
期待二乗損失のうち、予測モデルに依存する項である式(3.37)の第2項の積分の中身に注目しよう。
$$
\{ y(x; D) - h(x) \}^2 \tag{3.38}
$$
これをデータ集合の取り方に関する予測モデルの期待値$ \mathrm{E}_D[ y(x; D) ] $を(上記と同じように)足して引く、という変形を行う。
\begin{align}
\{ y(x; D) &- \mathrm{E}_D[ y(x; D) ] + \mathrm{E}_D[ y(x; D) ] - h(x) \}^2 \\
= &\{ y(x; D) - \mathrm{E}_D[ y(x; D) ] \}^2 + \{ \mathrm{E}_D[ y(x; D) ] - h(x) \}^2 \\
+ &2 \{ y(x; D) - \mathrm{E}_D[ y(x; D) ] \} \{ \mathrm{E}_D[ y(x; D) ] - h(x) \}
\tag{3.39}
\end{align}
式(3.39)全体の、データ集合の取り方に関する期待値をとると以下の式変形により、最後の項は消える。
~~最後の項が消える説明~~
最後の項の$ \{ y(x; D) - \mathrm{E} _ D [ y(x; D) ] \} $ の部分に注目する。ここのデータ集合の取り方に関する期待値をとるのだが、簡単のためデータセットは$D_1, D_2, D_3$の3つとしよう。すると:
\begin{align}
& \mathrm{E}_D \{ y(x; D) - \mathrm{E} _D [ y(x; D) ] \}\\
&= \frac{1}{3}
\biggl(
\{ y(x, D_1) - \mathrm{E}_D[ y(x; D) ] \} + \{ y(x, D_2) - \mathrm{E}_D[ y(x; D) ] \} +
\{ y(x, D_3) - \mathrm{E}_D[ y(x; D) ] \}
\biggr) \\
&= \frac{y(x, D_1) + y(x, D_2) + y(x, D_3)}{3} - \mathrm{E}_D[ y(x; D) ] \\
&= \mathrm{E}_D[ y(x; D) ] - \mathrm{E}_D[ y(x; D) ] = 0
\end{align}
なので、式(3.39)全体の、データ集合の取り方に関する期待値をとると最後の項は消える。
~~最後の項が消える説明 ここまで~~
理想の回帰関数$h(x)$はデータ集合の取り方によらず一定なので$\mathrm{E}_ D[ h(x) ] = h(x)$、期待値の期待値は期待値なので$\mathrm{E} _ D [ \mathrm{E} _ D [ h(x)] ] = \mathrm{E} _ D [ h(x) ]$4
よって、式(3.39)全体の、データ集合の取り方に関する期待値をとると
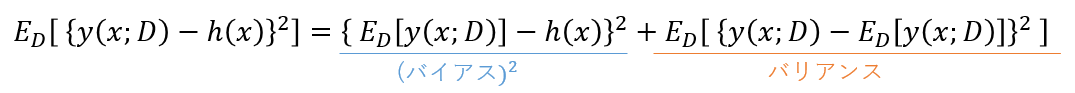
よって式(3.37)第1項の$y(x,D)$と$h(x)$の期待二乗誤差は:
- 二乗バイアスと呼ばれる第1項。データ集合の取り方に関する予測値の平均が理想的な回帰関数からどれくらい離れているか(どれくらい真の分布にフィッティングできているか)
- バリアンスと呼ばれる第2項。あるデータ集合における予測値が平均の予測値とどれくらい異なるかをあらわすばらつきの平均値
の2つの項の和で表せることが分かる。
期待二乗誤差を最小にしたいので二乗バイアス、バリアンスの両方を小さくしたいが、この2つはトレードオフの関係にあるため、両方を小さくすることは難しいことを示す。
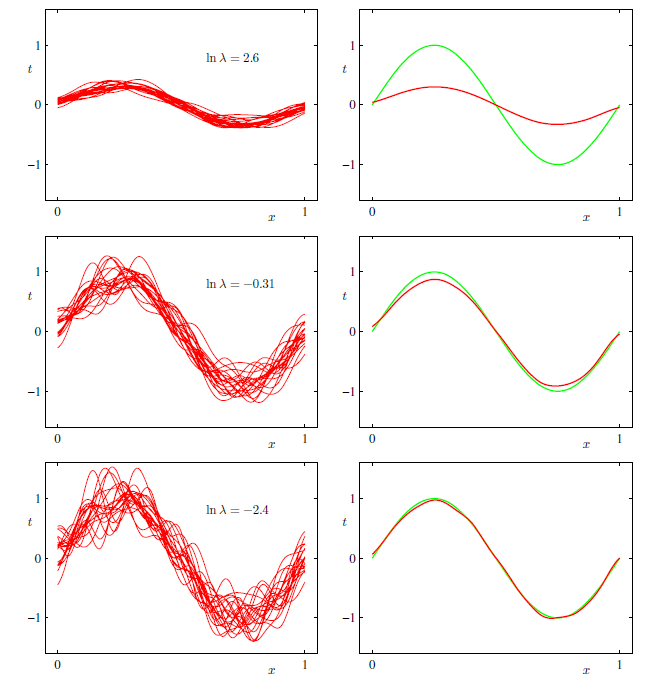
上図上のグラフのように、表現力が低いモデル(正則化係数が大きかったり、少ない基底関数しか使っていないモデルなど)ではそもそもモデルがとりうる形のバリエーションが多くないので、データ集合ごとの予測モデルのばらつきが小さい。つまり、バリアンスが小さい。一方、モデルがとりうる形の制限が強いので右側緑線で表される真の関数にうまくフィッティングできていない。つまり、二乗バイアスが大きい。
逆に上図下のグラフのように、表現力が高いモデルではモデルがとりうる形のバリエーションが多いので、データ集合ごとの予測モデルのばらつきが大きく、バリアンスが大きい。一方、平均的には真の関数にうまくフィッティングできているので二乗バイアスは小さい。
ここまで説明を読み進めた今あらためて、この節の頭に書いたアブストラクトを再掲する。今ならアブストラクトの内容がより理解できないだろうか。
- 例えば無数の基底関数を使ったモデルみたいな、表現力が高いモデルは理想的な回帰関数にあてはまりやすくなるので、バイアスが小さくなる。一方、データのノイズにも過剰にあてはまるので、データ集合によって予測値がばらつき、バリアンスが大きくなる。
- 逆に、表現力が低いモデル(例えば1次モデル)では、理想的な回帰関数にあてまはりにくくなるので、バイアスが大きくなる。が、予測値のばらつきはあまりなくなるので、バリアンスは小さくなる。
- 結局バイアスとバリアンスはトレードオフの関係である。
-
深層学習の分野でもよくつかわれるテクニック ↩
-
期待値の定義 $E[x] = \int x p(x) dx$を思い出せば、$x$について積分消去しているので、$E[x]$が$x$によらない項であることが分かる ↩
-
このブログのおかげで理解できました。https://www.yasuhisay.info/entry/20080807/1218182093 ↩
-
ここの説明をどうすれば分かりやすくできるか分からないが...。簡単な例として、サイコロの目の期待値は3.5。さて、「サイコロの目の期待値」の期待値は「3.5で一定(定数)となる値」の期待値なので3.5。つまり、期待値の期待値は期待値、というイメージ。 ↩