OthloTech Advent Calendar 2018
オスロテック アドヴェント・カレンダー2018企画
成果物イメージ:

[画像1]語源が共有されているかを判定。英語とドイツ語で「このリンゴは充分に赤い」

[画像2]拙作自然言語処理テキストエディタ"IntelligenTXT"上で動作する簡易言語判定機能
概要
本記事では主に、過去作ったことのあるテキストエディタ用のGUIモジュール(本文中にて詳しく説明いたします)を活用しつつ、自然言語処理の各種補助ツールを作成します。複雑なアルゴリズムを駆使するというより、言語学(正書法、子音変化法則)の知識をルールベースに落とし込み、それに基づく判定機能をGUIで実装するものです。そのため、前半にて言語学の背景知識を、後半にてその実装方法を説明いたします。
自己紹介
Yoshiよしと申します。人工知能学会の学生会員で、文系学部に在学しております。在学の専門は語学および言語学の関連分野です。2016年の国際言語学オリンピックを経験する折、言語学に関しては独学していました。
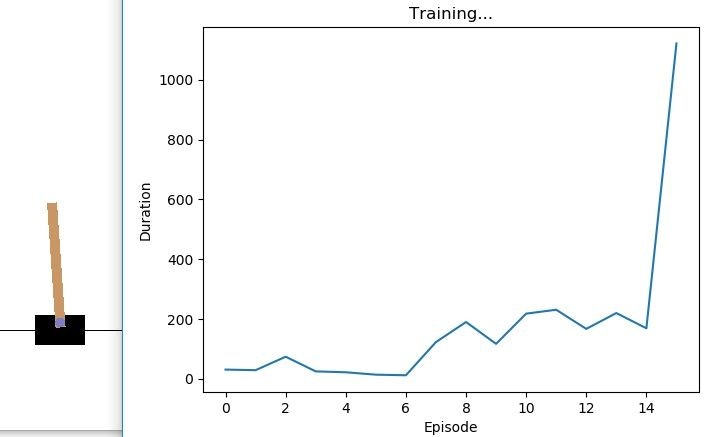
[画像3]PyTorch Double Deep Q-Network(DDQN)によるCartPole記録
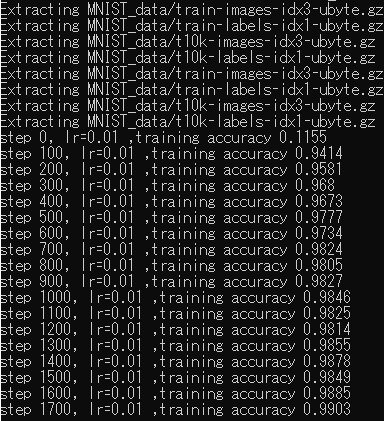
[画像4]北京大学院生さんとのMNIST共同研究
高校でPythonに入門して以来、TensorFlowおよびPyTorchを弄っています。(作品はhttps://github.com/yosiyoshi/YoshiNet )シリコンバレーや中関村(北京)との交流で学ぶことが多いと感じる日々です。最近はGo言語のドローンプログラミングやIoTも試しています。また機会があれば、その知見を記事にまとめたいと考えています。
動作環境
Python 3.6
Anaconda3
Spyder
Tkinter
nltk
背景知識:言語学
最低限の知識を簡潔にまとめてみました。
自然言語処理分野の背景
自然言語処理(NLP: Natural Language Processing)とは言語学と人工知能の融合分野でして、この自然言語(Natural Language)とはそもそも人類がコミュニケーション手段として用いる言語全般を指します。主な内容は形態素解析と構文解析、文脈解析、意味解析を基礎とし、近年では言語理解や感情認識などの研究もみられます。ここで、対極に位置するのが人工言語(Artificial Language)でして、所謂プログラミング言語もこれに含まれます。
今回の対象は文字言語(Written Language)
今回扱う文字媒体はテキスト形式であると同時に、言語学の本質上は文字言語といえます。すなわちテキストは文字を媒体としており、その言語はある正書体や文法に従って書かれるのが一般的です。対する音声言語は、コンピュータ上では会話音声や機械音声などの音声ファイル形式で扱われます。
処理の対象が正書体や文法を持つ以上、同じ文字言語で書かれた文章には共通のスペリングや構文が現れやすくなります。これを特徴として定義しルールベースを作成することで、例えば**言語判定(Language Detection)**が実装可能です。
正書体(Authography)
正書体はある言語の文字や単語を綴る際に定められた、一定のスペリング規則です。たとえば、英語で騎士を"knight"と綴り、ナイトと読むといった、このような規則を言います。ここで"k"は黙字であり発音されず、"-ight"はおおよそ"アイト"と発音されます。しかし、周知のとおり発音とスペリングは往々にして乖離していることも少なくなく、同じ語源、究極的には殆どのヨーロッパ言語が共有するといわれるインド・ヨーロッパ祖語(Proto-Indo-European language)から発生したドイツ語の"Knecht"(クネヒト)とは綴りこそ似ているものの発音は異なります。これは同じゲルマン祖語を発祥としつつも、歴史的な大母音推移(Great Vowel Shift)などの発音変化を通じて音声言語が変化したためです。しかしながら正書体は音声言語の変化にかかわらず、そのまま代々継承されることも少なくないため、結果として歴史上、比較的変化が少ないといえます。
この性質に注目すれば、正書体で定められたスペリングの特徴から言語を判定したり、文字言語の綴りに発音変化の法則を逆用し、両者が語源を共有しているか否かを簡単に導き出すことができます。
同じ音声言語、正書体の相違
同じ話し言葉(文法、語彙や発音の共有により疎通可能)でも筆記に用いられる文字の相違により別の言語として認識されることがあります。例えば、中国語の簡体と繁体、タイ語とラオス語、かつてのマレー語とインドネシア語、ヒンドゥスタン語と呼ばれるヒンディー語とウルドゥー語が挙げられます。
その歴史上、同じ文字を用いてたであろう言語も少なくありません。中国語ならば現在は繁体(日本の旧字体に近い)として知られる、筆画が多い漢字体系を長く用いています。今回扱う自然言語処理の問題では、オランダ語及びアフリカーンス語とインドネシア語がかつてスペリングを共通化していた事実(c.f. ファン・オップハイゼン綴り)を鑑み、判定基準に含めています。Old Indonesianの判定基準は“oe”が検出された母音綴りの中で、最多かどうかです。
実装
前提として自然言語には例外が多くあります。そして精度100%の言語処理アルゴリズムを構築することは至難です
まず、あらかじめ作っておいた以下二種類の拙作モジュールをローカルに利用します。
1: main.pyとmain_mini.py
https://github.com/yosiyoshi/IntelligenTXT/blob/master/main_mini.py
このプログラムは拙作にして現在開発中の自然言語処理専用のテキストエディタです。テキストスペースの大きさにより、二種類の実装があります。それぞれ実行すると、以下のようなTkinterによるGUIが起動します。アジア言語の形態素解析やキーワード抽出、要約、感情認識などの機能を備えています。(また関連記事を書くかも)
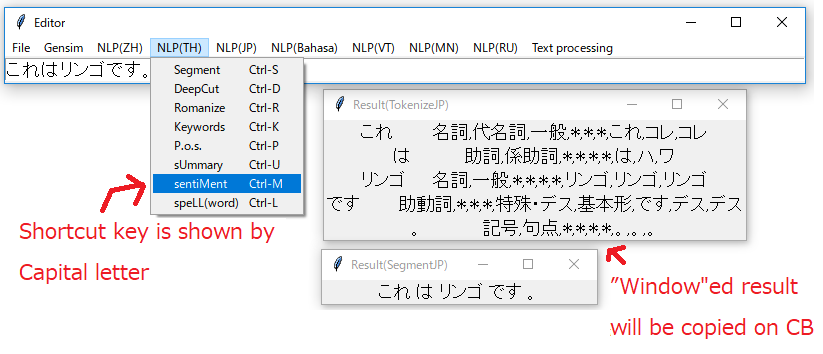
[画像5]main_mini.pyの起動例
今回は、このGUIプログラムを一種のローカルGUIモジュールとして再利用します。
from main import Frame
root = Frame.root
m = Frame.m
menuf0.add_command(label=u"New", command=Frame.new, underline=5, accelerator = 'Ctrl-N')
menuf0.add_command(label=u"addOpen", command=Frame.load, underline=5, accelerator = 'Ctrl-O') menuf0.add_command(label=u"addSave", command=Frame.save, underline=5, accelerator = 'Ctrl-S')
以上のように、関数が再利用されます。
2: ynltk.py
拙作の自然言語処理モジュールです。実装に関しては追って説明いたします。
i.言語判定アルゴリズム
背景知識としての言語学に関する説明で述べた通り、一般的に正書体は原則として発音に対して一種類のスペリングを定めようとします。そのため、ある言語では/u/の子音を"u"であったり、フランス語のように"ou"であったり、あるいはオランダ語由来の"oe"として記述することがあります。
この傾向を
https://github.com/yosiyoshi/IntelligenTXT/blob/master/ynltk.py
にてルールベースへ落とし込みます。
まず、
h=[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
という配列を作成します。
次にパターンマッチを行う対象として、母音の綴りをいくつか選びます。そしてcount関数で数え上げます。
h[0]=txt.count("oo")
h[1]=txt.count("y")
h[2]=txt.count("oe")
h[3]=txt.count("oi")
h[4]=txt.count("ie")
h[5]=txt.count("ee")
今回は合計25個の綴りをパターンマッチで数え上げ、配列hに代入しています。
そして配列内の最大値に関して、存在しない場合には"None"を返します。
if max(h)==0:
result="None"
また、各言語に顕著な綴り、例えば英語の"-y"などの出現回数が最大値の時はこれを検出し、その言語と判定します。"-y"が最頻出の場合はh[1]が最大値となり、以下のif節条件を満たします。
elif max(h)==h[1] or max(h)==h[18] or max(h)==h[19]:
result="English?
return result
ii.インド・ヨーロッパ祖語(印欧祖語/PIE)構築と比較
任意の文字列に対し、印欧祖語から派生したとされる現存の印欧各語派、例えば**ゲルマン語派(英語、ドイツ語)やイタリック語派(フランス語、イタリア語)**への発音変化を正規表現として定義します。与えられた二つの文字列を一旦統合して最初のreplace関数に渡し、出力文字列を次の関数に渡して置き換えを進めます。
Grassmann's lawのように、印欧祖語を構築する際に参考となる変化法則があります。内容は英語版ウィキペディアより引用する次のとおりです:
(from https://en.m.wikipedia.org/wiki/Grassmann%27s_law)```
この内容に基づき、replace関数で次のとおり置き換え処理します。
def compStemmer(self, corpus1, corpus2, skip=0, result=1):
corpus = corpus1 + " " + corpus2
conju0 = corpus.replace("p", "b")
conju1 = conju0.replace("t", "d")
conju2 = conju1.replace("k", "g")
続いて、https://en.wikipedia.org/wiki/Indo-European_sound_laws を参考に同様のパターンを記述します。

[画像6]Indo-European sound laws(en.wikipedia)よりキャプチャした変化法則の図表
ここでは21個のパターンを定義しました。
与えられた二つの文字列に正規表現で置換処理した結果を再分割し、両者を比較します。
s = difflib.SequenceMatcher(None, l1, l2).ratio()
この0≧s≧1の合致率に対して、**s≧0.5であれば同源**と判定します。
https://en.wiktionary.org/wiki/house#Etymology_1
にあるように、"house"の印欧祖語は"```(s)kews-```"ですが、
このアルゴリズムは"house"を"kewso"に変換します。
以上が、今回使用するynltkモジュールの説明です。
## GUI化
"i.言語判定アルゴリズム"と"ii.インド・ヨーロッパ祖語(印欧祖語/PIE)構築と比較"をそれぞれ、main.pyとmain_mini.pyからimportされたモジュールに組み込んで**GUI化**します。
テキストエディタに欠かせないentry(一行のテキスト入力欄)やscrolledtext(複数行のテキスト入力欄)部分を、それぞれ"entry = Frame.entry"と"m = Frame.m"の形で既存のGUIモジュールからそのまま頂戴しましょう。(面倒な記述なしに使いまわせるため)
またI/Oもそれぞれの入力欄に対応する**保存と読み込みの機能を"Frame.save/Frame.load"に定義してある**ので、これも使いまわせます。

[画像7]EntryとTextでは内容文字列に対する**get()関数の使い方**が異なる。widgetに対応した書き込みと読み込みの関数は予め定義しておいた方が便利?
GUIモジュール再利用の結果、**小一時間で30~50行のコード**を書きさえすればツールが完成します。
# 完成&テスト

[画像8]"i.言語判定アルゴリズム"を組み込んだGUIアプリ"LanguageDetector"、ドイツ語の文章

[画像9]"ii.インド・ヨーロッパ祖語(印欧祖語/PIE)構築と比較"を組み込んだGUIアプリ"EtymologyCompare"、「開く」を意味する"open"と"ouvre"は語源上関係なさそう
単純な機能なので、メニュータブを探し回らなくても済むように、処理ボタンを独立させ配置しました。テキストを入力して**"Detect"や"Compare"のボタンを押せば**、すぐに処理が完了し、"Result"の**テキストラベルに結果は表示**されます。
以下が成果物です:
https://github.com/yosiyoshi/IntelligenTXT/blob/master/langdetec.py
https://github.com/yosiyoshi/IntelligenTXT/blob/master/etycompare.py
# 感想
Advent Calender初参加ということで、文章も上手くまとまっていないかもしれません。明らかな錯誤や矛盾があればご指摘ください。