はじめに
LambdaでPdfを画像化します。windowsであればpopplerのstatic buildがあるので比較的簡単にできますが、Lambdaの環境ではコンテナを使わないとその方法では実行できません。コンテナの勉強を兼ねて作りました。
前提
- Dockerの実行環境
- AWS CLIとaws configureの設定
やること
- Dockerイメージの準備
- ECRの準備
- Lambdaの作成
Dockerイメージの準備
以下のようなファイル構成です。
CreatePdfThumbnail
│ app.py
│ Dockerfile
│ env.txt
└─ requirements.txt
Dockerfileは以下のようになっています。
FROM public.ecr.aws/lambda/python:3.6
# ベースイメージはPython3.6環境を使いたいのでpublic.ecr.aws/lambda/python:3.6
RUN yum -y install poppler-utils
# poppler-utilsをインストール
# apt-getは使えないので注意
COPY app.py ${LAMBDA_TASK_ROOT}
COPY requirements.txt .
RUN pip3 install -r requirements.txt --target "${LAMBDA_TASK_ROOT}"
# 必要なライブラリのインストール
CMD ["app.lambda_handler"]
以下のapp.pyがLambdaの本体です。
import json
import os, io
from pathlib import Path
from pdf2image import convert_from_bytes, convert_from_path
import boto3
import PIL
import requests
def lambda_handler(event, context):
pdf_name = event['queryStringParameters']['pdfName']
# queryStringParamtersはAPI Gateway用
bucket_name = 'my-bucket'
s3 = boto3.client('s3')
response = s3.get_object(Bucket=bucket_name, Key=pdf_name)
data = response['Body'].read()
pages = convert_from_bytes(data)
# pagesはPILのImageリストなのでbyteに変換
img_bytes = io.BytesIO()
pages[0].save(img_bytes, format='PNG')
img_bytes = img_bytes.getvalue()
base = os.path.splitext(os.path.basename(pdf_name))[0]
s3.put_object(Body=img_bytes,Bucket=bucket_name,Key=base+'.png')
return {
'statusCode': 200,
'body': 'DONE!'
}
pdfの一ページ目を画像にしてS3に保存します。pdf2imageを使ってます(これにpopplerが必要)。
requirements.txtでは必要なライブラリを記述します(boto3はいらないかも)。
pdf2image
boto3
requests
ローカルでテストするときは、Dockerfileのあるディレクトリで以下のコマンドでイメージをビルドしてrunしてください。
docker build -t test .
docker run -p 9000:8080 test:latest
コードでboto3などを使っていてcredentialが必要な場合は、env.txtに以下のように記述して実行時に渡します。
AWS_DEFAULT_REGION=ap-northeast-1
AWS_ACCESS_KEY_ID=IAMで発行する適切な権限を持つアクセスキー
AWS_SECRET_ACCESS_KEY=そのシークレットキー
docker run --env-file ./env.txt -p 9000:8080 test
あとはhttp://localhost:9000/2015-03-31/functions/function/invocationsにPOSTリクエストを投げてあげるとテストができます。↓Pythonの例
import requests
data = {
'queryStringParameters': {
'pdfName': 'test.pdf'
}
}
response = requests.post("http://localhost:9000/2015-03-31/functions/function/invocations",json=data)
ECRの準備
ECRは基本的にボタンをポチポチするだけです。すごく便利。
↓次にECR側です。コンソールからElastic Container Registryを選択し、リポジトリを作成をクリック。

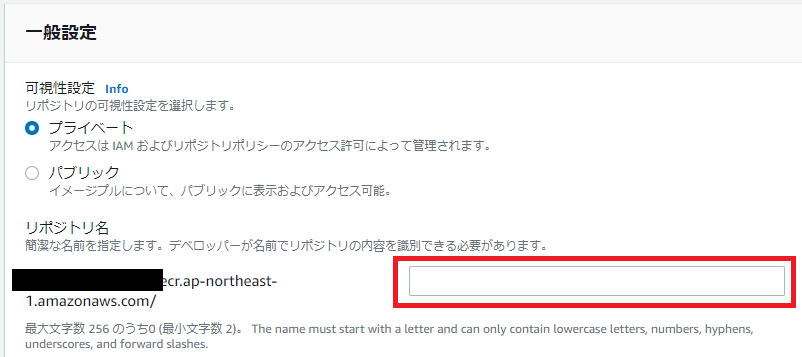
↓リポジトリ名を入力し、下にスクロールしてリポジトリを作成をクリック。
↓プッシュコマンドの表示をクリック。
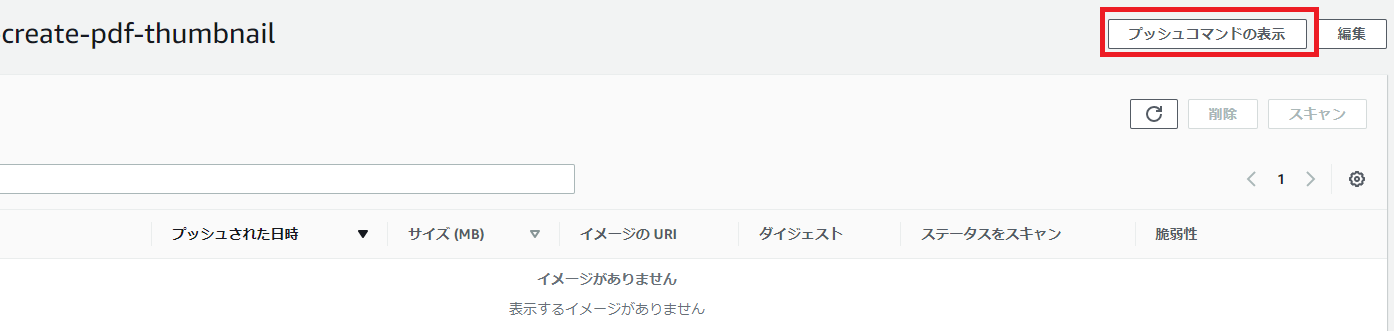
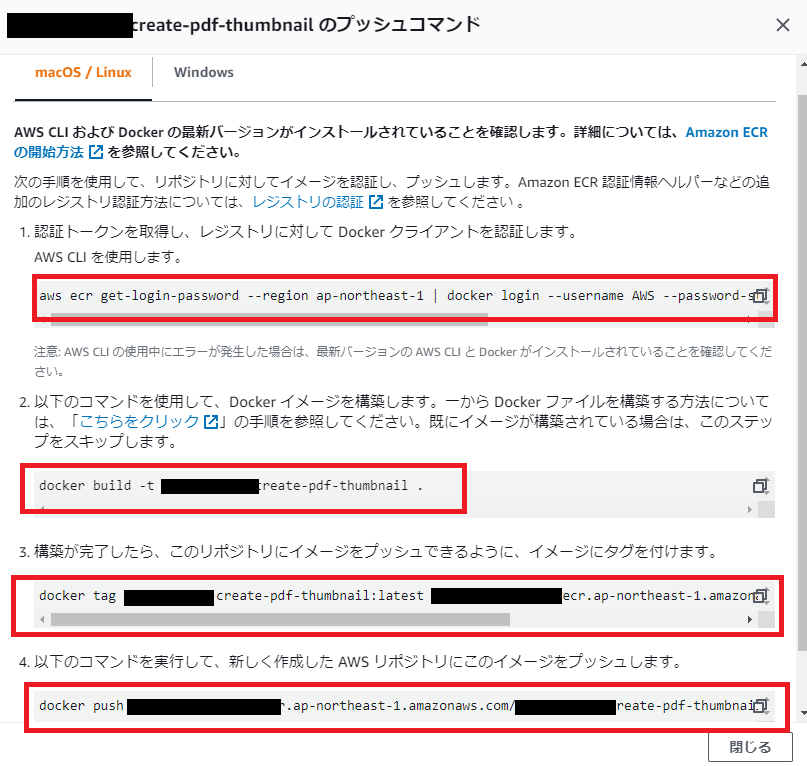
↓出てきたコマンドをDockerfileのある場所でコマンドプロンプトからたたけばイメージがECRにpushされる(WindowsでもmacOS/LinuxタブのコマンドでOK)。
↓こんな感じでpushされてればOK。

Lambdaの作成
コンソールからLambdaを開いて関数の作成をクリック。以下の画像のように「コンテナイメージ」を選択し、関数名と先ほど作成したコンテナイメージURIを入力したあと関数の作成をクリック。関数名はECRのリポジトリ名と同じにする。
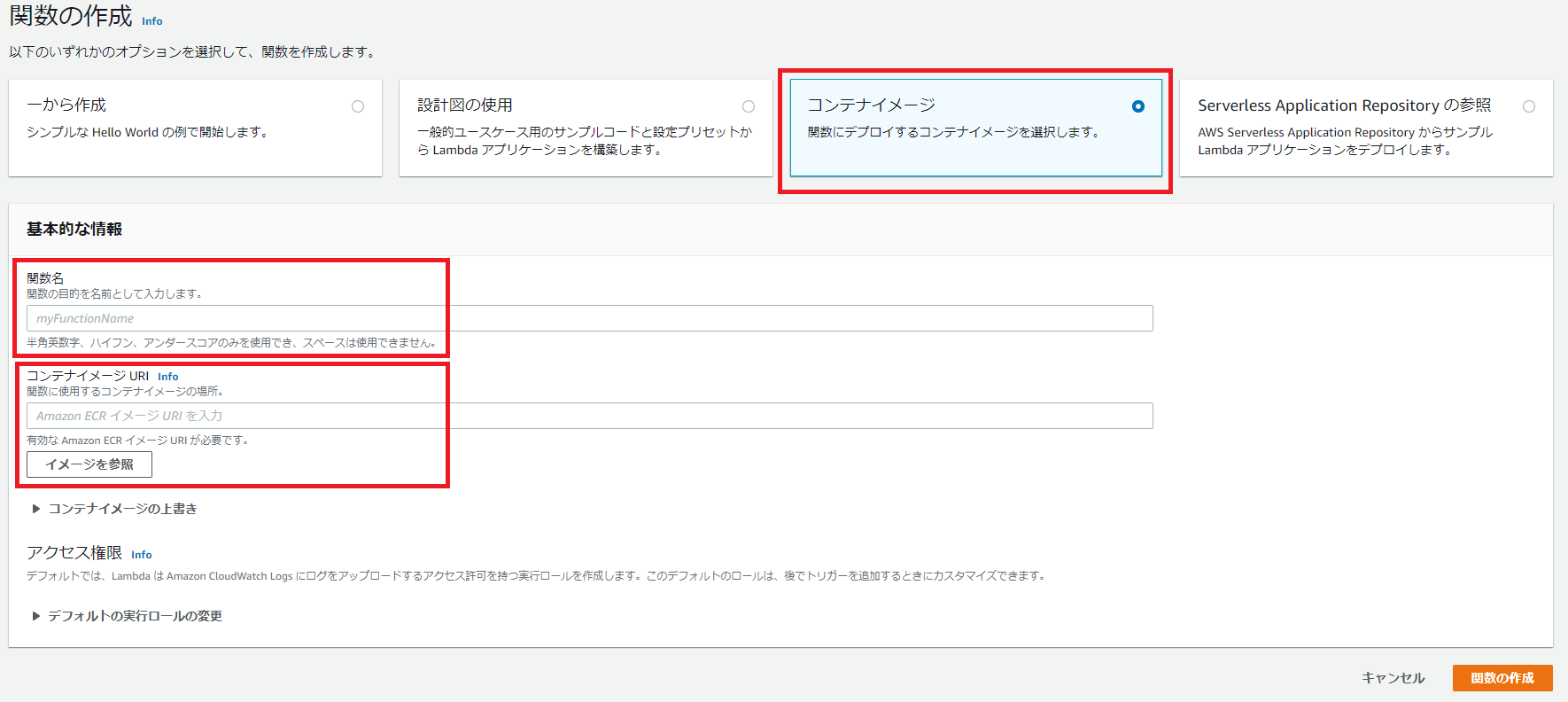
S3やDynamoDBにアクセスする際には、設定タブの「一般設定」→「編集」→「IAMコンソールで~~~のロールを表示します」からS3やDynamoDBの適切なポリシーをアタッチしてください。
以上。コードのプレビューはできませんが、テストタブからテストはできます。エイリアスやバージョンの設定も触っていきたい。
おわりに
OpenGL対応のFaaSってないですか。間違い等ありましたらご指摘よろしくお願いします。
追記
→OSmesaを使ってOpenGLの機能をLambdaで利用する方法を記事に書きました。(https://qiita.com/yosiiii/items/1f33ddb10a48103f30c5)