tl;dr
トラフィックが多いL4ロードバランサーなどのサーバーでは、BBRを有効にし、キューイングアルゴリズムをfqにするとソケットバッファ(以下バッファと呼ぶ)が枯渇するので、fqにするのはお勧めしないというお話です。
前提
この記事ではBBRとはなんぞや、keepalivedはなんぞやということは説明しておりません。
前提として、BBRの概要、keepalivedの概要がわかっていることで話をします。
以下が今回検証した環境です。
OS: Ubuntu20.04
keepalived: 2.0.19
はじめに
TCPの輻輳制御のアルゴリズムであるBBRを有効にしたら、TCPの速度がはやくなるのではないかという話になり、BBRを有効にしてkeepalivedを動かしたら以下のエラーが出力されてサーバとの通信ができなくなりました。
Keepalived_vrrp[6098]: Error 105 (No buffer space available) sending gratuitous ARP on eth0 for XXXX
BBRを有効にするためにはカーネルパラメータは以下のパラメータを設定。
net.core.default_qdisc = fq
net.ipv4.tcp_congestion_control = bbr
ここで、 net.core.default_qdisc をfqにしているのですが、こちらの設定でなにやらバッファを使い果たしていそうでした。
net.core.default_qdiscとは何者か
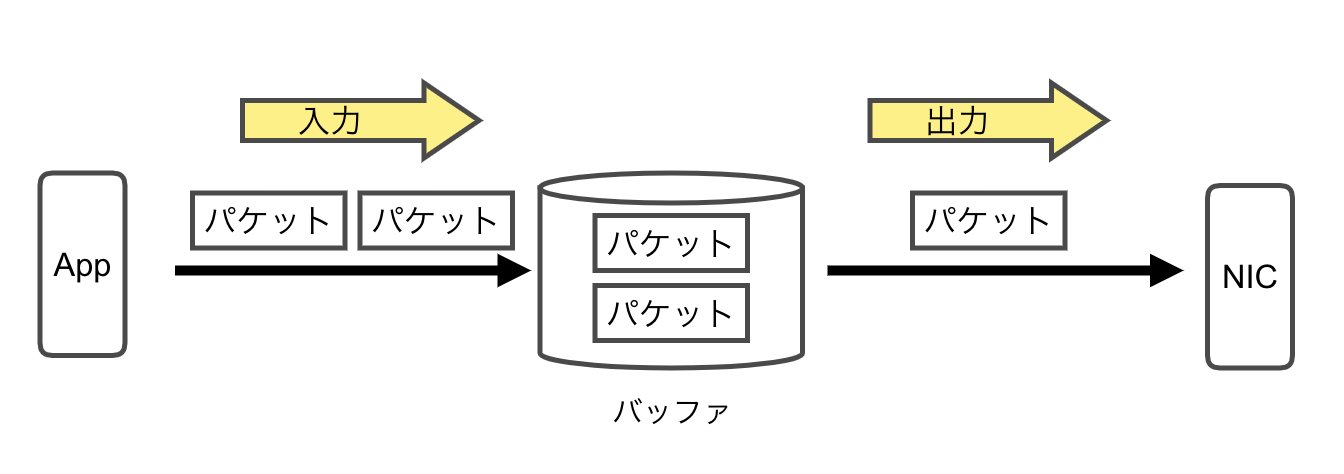
パケットスケジューラーのキューイングアルゴリズムを決めるカーネルパラメータになっています。
このパラメータで指定したアルゴリズムでバッファからパケットをどのように取り出して、
パケットをNICから出力するかが決まります。
キューイングアルゴリズムはいろいろありますが、今回は以下の3つで検証しました。
- pfifo_fast
- fq
- fq_codel
選定理由としては、pfifo_fastはsystemdのバージョン217までのデフォルトのアルゴリズムで、
それ以後のデフォルトのアルゴリズムがfq_codelのためです。
fqは後述しますが、BBRの推奨のアルゴリズムになっております。
参考資料: https://wiki.archlinux.org/index.php/Advanced_traffic_control
キューイングアルゴリズムの概要
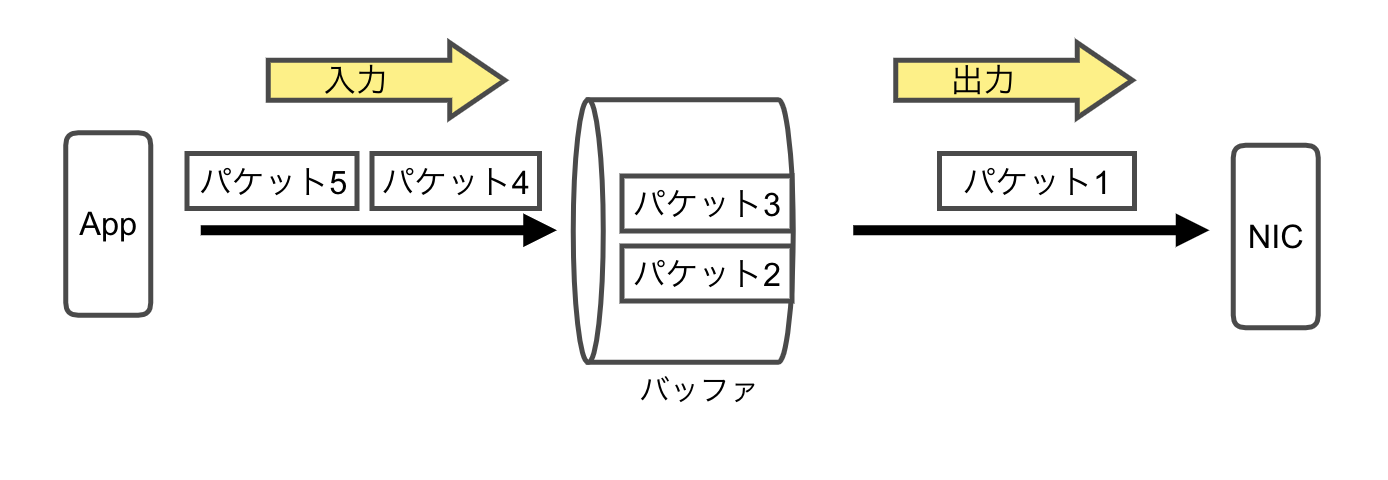
pfifo_fast
FIFO(First In First Out)のアルゴリズムでバッファから取り出されてパケットを出力します。
バッファに最初に入れたものが最初に出力される仕組みです。
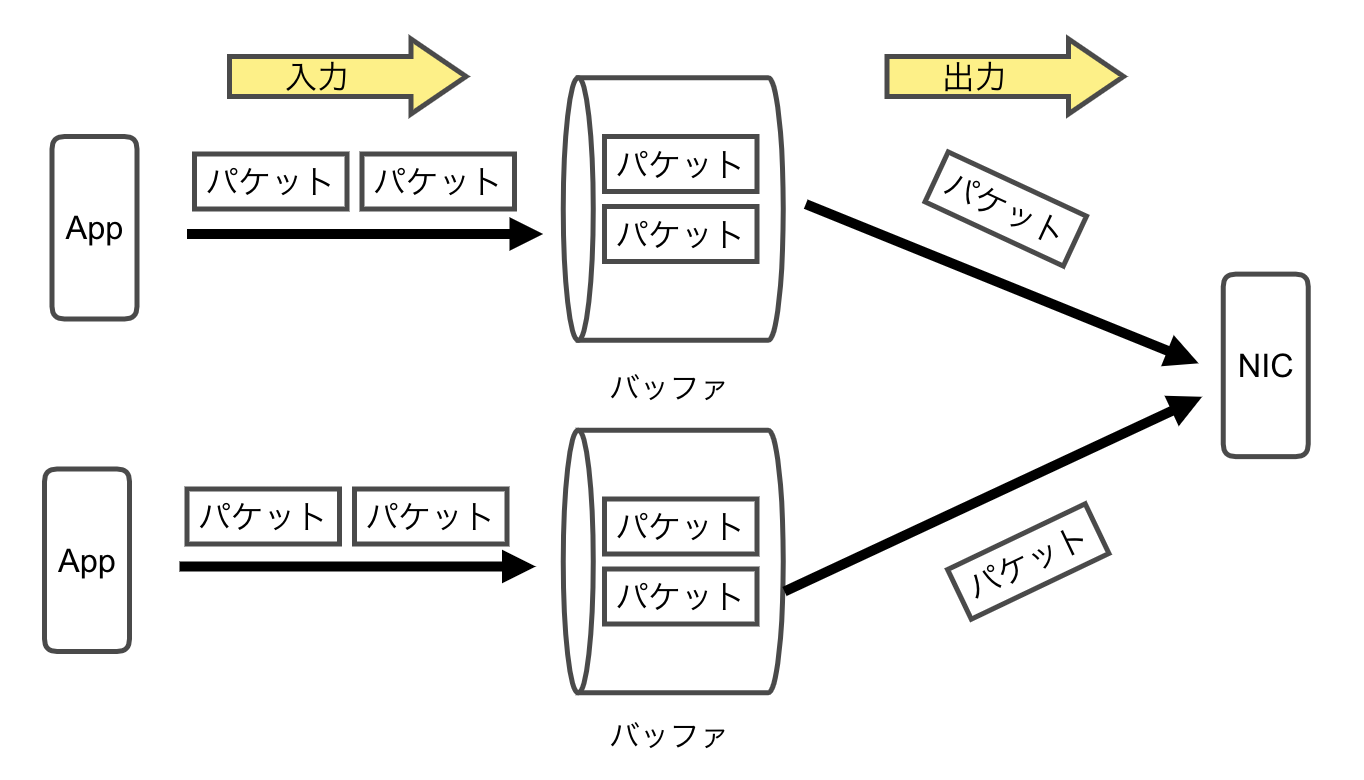
fq(Fair Queuing)
公平キューイング(Fair Queuing)はバッファを分割し、トラフィックに対して公平に帯域を割り振るアルゴリズムになります。
fq_codel(Fair Queuing + Codel)
公平キューイング(Fair Queuing)だが、pacingによってパケット間の空き時間を作るのではなく、遅延によって一定の速度でデータを通信させます。
BBRのキューイングアルゴリズムについて
IETFの資料(参考資料: https://www.ietf.org/proceedings/97/slides/slides-97-iccrg-bbr-congestion-control-02.pdf) ではBBRを使ううえで、FQは必須ではないが、BBRはpacingが必要であると書いています。

※pacingとはパケットとパケットの間に意図的に空き時間を作り,一定の速度でデータを通信するというもので、 ネットワーク上で最もボトルネックになる部分の速度に合わせてデータを通信すれば,他のパケットが混在しない限りはパケットの廃棄は発生せず,最も効率よくデータが転送できます
また、現状の実装だと、BBRはpacingが使える必要があり、
それを実装しているキューイングアルゴリズムがfqであるともIETFの資料に書いてます。

そのため、BBRはキューイングアルゴリズムとして、FQは必須ではないが、
pacingを実装しているキューイングアルゴリズムが現状(2020/08/13現在)fqのみなので、実質fqはBBRに必要だと考えます。
ちなみにキューイングアルゴリズムがfq以外でもBBRを設定することは可能ですが、
BBRはpacingを利用できることを前提としているので、ネットワークに余分な負荷をかける可能性があります。
検証
BBRを有効にしたkeepalivedでバッファを枯渇させないための検証をおこないました。
BBR+fq以外のアルゴリズム
以下のように net.core.default_qdisc をfq以外にすることで、
バッファが枯渇せずに正常に動きました。
検証値1
net.core.default_qdisc = pfifo_fast
net.ipv4.tcp_congestion_control = bbr
検証値2
net.core.default_qdisc = fq_codel
net.ipv4.tcp_congestion_control = bbr
いままでは、fqのpacingがネットワーク上で最もボトルネックになる部分の速度に合わせてデータを通信するので、未送信のパケットがバッファに積み上がってましたが、fq以外にするとpacingされないのでパケットが積み上がらずバッファが枯渇しないとためと想定されます。
TCP_NOTSENT_LOWATを設定する
BBR+fqで設定しているものを探したところ、CloudFlareの記事で以下の設定を設定していました。
net.core.default_qdisc = fq
net.ipv4.tcp_congestion_control = bbr
net.ipv4.tcp_notsent_lowat = 16384
参考資料: https://blog.cloudflare.com/http-2-prioritization-with-nginx/
net.ipv4.tcp_notsent_lowat の設定値が不明でしたが、調べたところ以下の意味合いがあることがわかりました。
このTCP_NOTSENT_LOWATの値を設定すると未送信のデータサイズを明示的に制限することができます。そのため、低速回線環境下でもカーネルに送信データを飲み込まれることなく、SPDYサーバプロセスが優先度に応じたデータ送信を制御できることになります。
これにより、バッファに積み上がる未送信データサイズを制限することができ、それにより様々なネットワーク環境下で最適な通信速度を実現できます。
参考資料: https://jovi0608.hatenablog.com/entry/20140207/1391732796
自分たちの環境の場合、低速ネットワーク環境下でpacingを行ったため、 バッファからパケットを取り出して通信するよりもバッファにパケットが積み上がるのが早く、そのためバッファが枯渇していたと考えます。
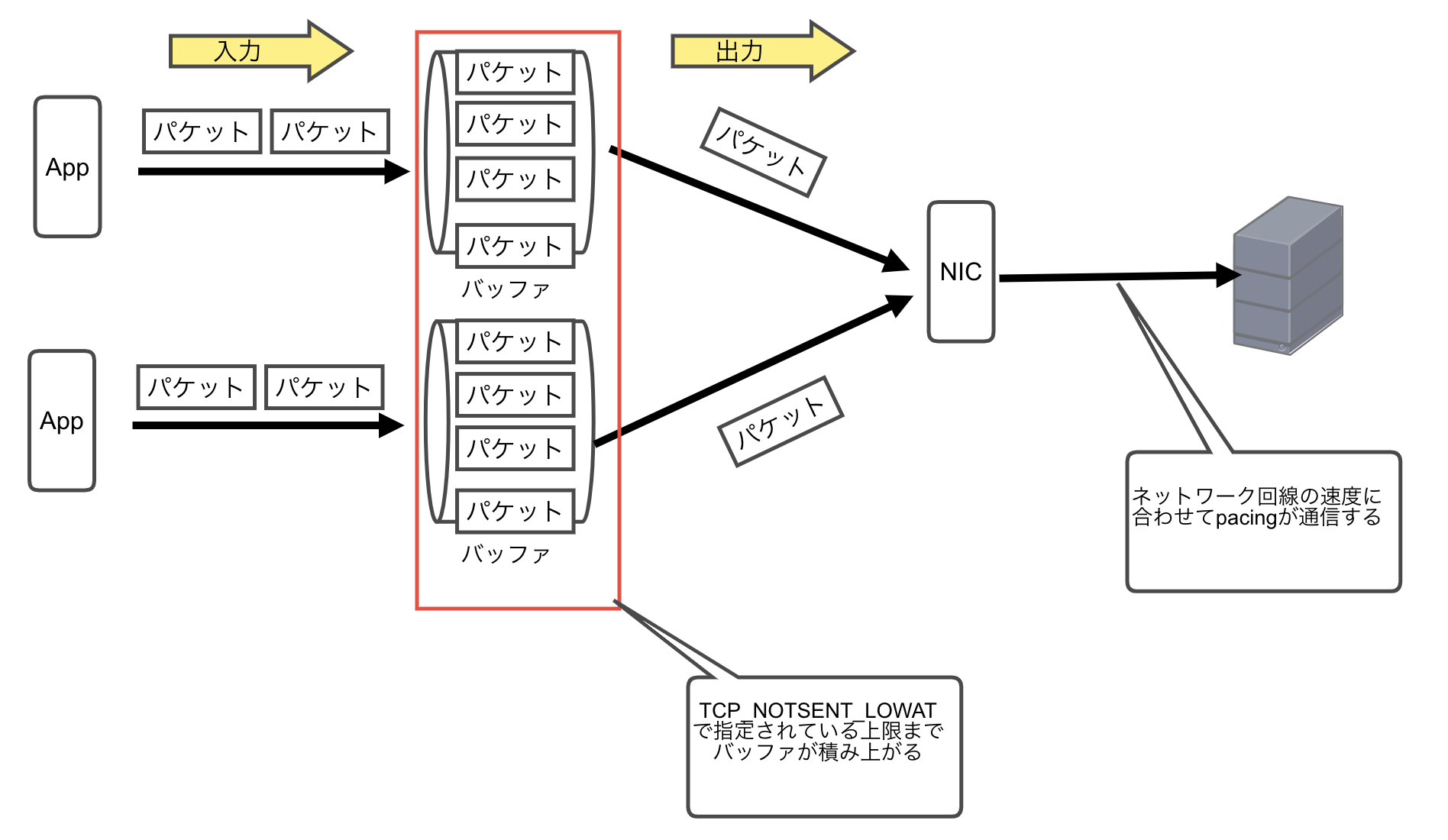
現在使っている TCP_NOTSENT_LOWAT は4GBと大きく、低速環境に向かないため、
net.ipv4.tcp_notsent_lowat = 4294967295
Cloudflareの設定値と同じ16KBと小さくして検証を行いました。
net.ipv4.tcp_notsent_lowat = 16384
その結果、keepalivedでBBRを有効で、キューイングアルゴリズムをfqにしてもバッファサイズが枯渇することはなくなりました。
TCP_NOTSENT_LOWATの適切な値は?
適切な値は参考資料とおりだと、カーネルをセルフビルドするしかなさそうです。。
W. Chanがブログで書いているようクライアントのネットワーク環境に依存するんですが、いったいどうやって決めたらいいでしょうか。 ちょうど先日チューリッヒで IETF httpbis WG の HTTP/2.0に関する中間会議があり >W. Chan と直接会う機会がありましたので聞いてみました。
私: 「ブログに書いてあるTCP_NOTSENT_LOWATの値って簡単に決められないよね。」
Chan: 「そう、ネットワーク環境によって違うからちゃんとモニターして決めないと。」
私: 「Googleではどうしているの?」
Chan: 「データ送信キューの遅延をモニターして値を決めてるよ。」
私: 「えっ! どうやって? ユーザーランドからはそんなのわかんないよ。」
Chan: 「そりゃカーネルに手を入れて測定しているさ。」
さすがGoogle・・・
参考資料: https://jovi0608.hatenablog.com/entry/20140207/1391732796
結論
TCP_NOTSENT_LOWAT の最適値をだすためにはカーネルのセルフビルドをさせる可能性があるため、
keepalivedでの TCP_NOTSENT_LOWAT 設定はデフォルト値にしました。
また fq_codelのwikiには以下のような記載がありました。
net.core.default_qdisc = fq_codel - best general purpose qdisc
net.core.default_qdisc = fq - for fat servers, fq_codel for routers.
参考資料: https://www.bufferbloat.net/projects/codel/wiki/
keepalivedなどのL4ロードバランサーはトラフィックが多いので、
fq_codelがオススメとのこと。
そのため、キューイングアルゴリズムはfqを見送り、BBRも有効にさせませんでした。
蛇足
今回の件で、キューイングアルゴリズムによりパケットがどうなっているのかを監視するためにmackerelのpluginを作りました。これにより、キューがどのくらい積まれているのか、どのくらい確立済みソケットがあるのかを監視できます。もし、このプラグインのqlenやbacklog、tx_dropsが積み上がっているとしたらなんらかのネットワークチューニングが必要だと考えます。