はじめに
今回はElastic社が出しているBeats系の1つであるPacketbeatについて、
解説していこうと思います。
Beatsについて
詳しくは以下のクラスメソッドさんの記事に書いてありますが、
簡単に言うと、各サーバにインストールすることで、様々なデータを収集して、
logstashやElasticsearchなどに取得したデータを送ります。
https://dev.classmethod.jp/articles/beats-entry-matome/
Packetbeatについて
PacketbeatはBeats系の一つでネットワークトラフィックを収集するためのツールです。
Packetbeatで取得できるデータは、TCPを取得するFlowsと、対応しているプロトコルの詳しいデータを取得するTransaction protocolsの2つに分かれます。
ちなみにFlowsとTransaction protocolsで取得するデータは色々書き換えることが可能です。
自分が使った時はデータ量が多すぎたので、以下のように取得するプロトコロルを削りました。
processors:
- drop_event:
when:
- equals:
dest.port: 80
参考: https://www.elastic.co/guide/en/beats/packetbeat/master/filtering-and-enhancing-data.html
Flows
Flowsは簡単に言うとtcpdumpコマンドを叩いて取得しているイメージです。
取得できるデータの中身はどのポートでどのサーバからどのサーバに通信が行われているかを取得できます。サーバで流れているTCPをまるっと取得します。
Transaction protocols
公式ドキュメントにサポートされているプロトコルは記載されてます。
PostgreSQL,MySQL,HTTPなどの基本的なプロトコルがサポートされており、
例えばDBであれば、どのようなSQL文を叩いたのか、HTTPであれば、どのようなパスにトラフィックが流れたのかを取得することが可能です。
参考: https://www.elastic.co/guide/en/beats/packetbeat/current/configuration-protocols.html
ハンズオン
ではPacketbeatのインストールからElasticsearch、Kibanaの設定まで行いましょう。
ただし、こちらのハンズオンではPacketbeatの設定の仕方は記載してますが、Elasticsearch、kibanaのインストールから構築は対象外です。
前提条件
OS: CentOS7
Packetbeat: 7.8
インストール
以下の公式ドキュメントに則ってインストールします。
参考: https://www.elastic.co/guide/en/beats/packetbeat/7.8/setup-repositories.html#_yum
$ sudo rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
$ sudo vi /etc/yum.repos.d/elastic.repo
-------------
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
-------------
$ sudo yum install packetbeat
$ sudo systemctl enable packetbeat
Elasticsearchにindexを作成
PacketbeatはインストールするとデフォルトでElasticsearchのindexテンプレートを持っているので、
それを使って、indexを作成します。
参考: https://www.elastic.co/guide/en/beats/packetbeat/master/packetbeat-template.html
$ /usr/share/packetbeat/bin/packetbeat setup --index-management -c /etc/packetbeat/packetbeat.yml -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
※packetbeatコマンドを実行する時は -c オプションを使わないとカレントディレクトリにpacketbeat.ymlがあること前提に動くので、 -c を指定する必要があります
Kibanaでダッシュボード作成
KibanaのダッシュボードもPacketbeat側でデフォルトで用意しているので、それを使ってダッシュボードを作ります。
参考: https://www.elastic.co/guide/en/beats/packetbeat/master/load-kibana-dashboards.html
/usr/share/packetbeat/current/packetbeat
setup --dashboards -c /etc/packetbeat/packetbeat.yml
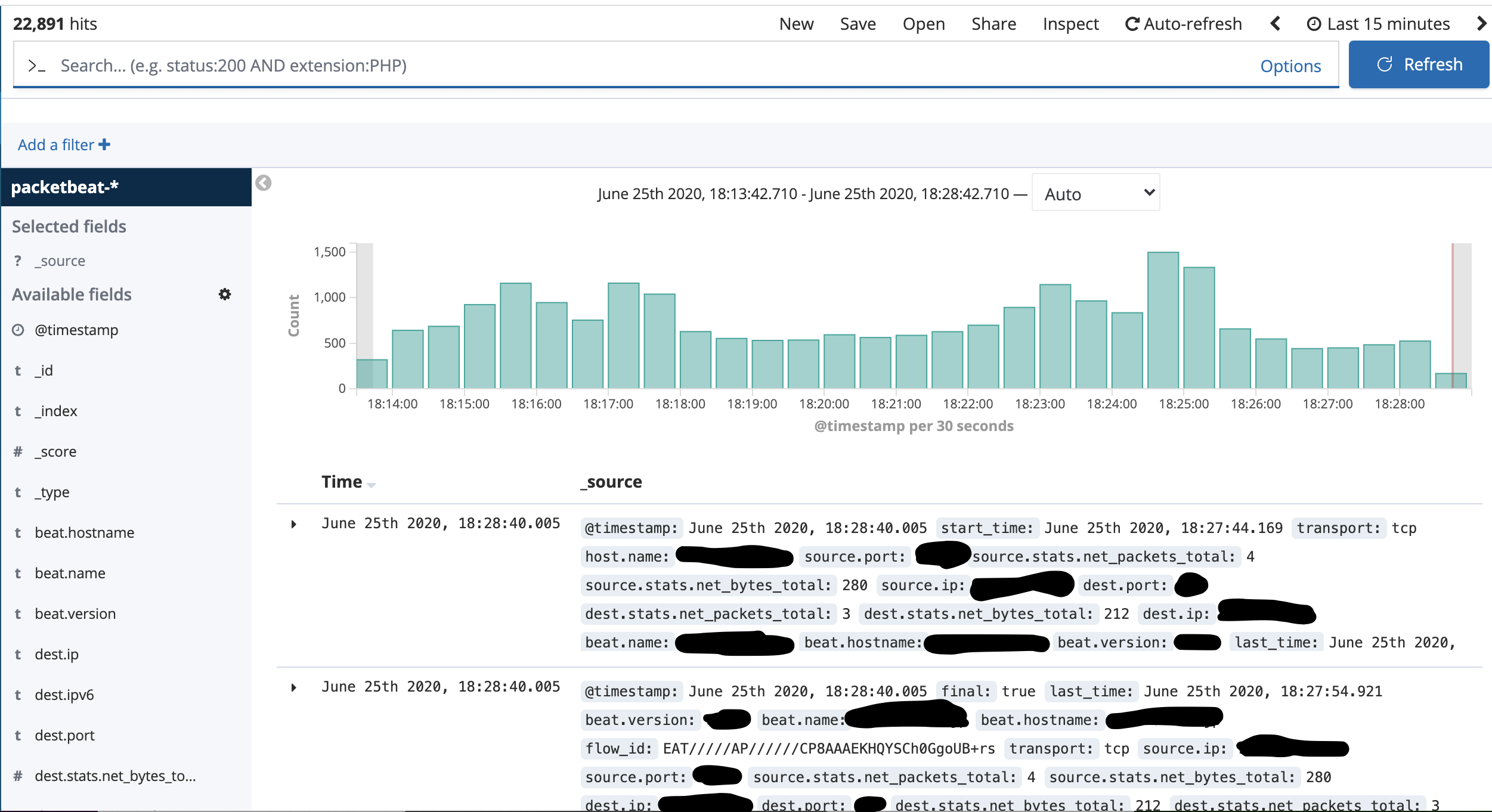
Packetbeatをインストールし、Elasticsearchのindex作成とKibana側のダッシュボード作成が終わればこのような画面になり、様々なパケットデータを取得・可視化することが可能です。
ハマったポイント
これはElasticsearchにデータを集める前提で、
自分がPacketbeatを導入する上でハマったポイントを記載します
Packetbeatのバージョン
Elastic社公式のElasticsearchだと問題がないですが、AWSがOSSとして出している opendistro for elasticsearch を使う場合は、Packetbeatがoss版でないと X-Packのライセンスがありません というようなエラーが出力されて使うことができません。
その場合はこちらにあるOSS版のPacketbeatをお使いください
https://www.elastic.co/jp/downloads/beats/packetbeat-oss
Elasticserarchのデータ量調整
基本的にElasticserarchはデータを溜めるところであって、
どのようなindexを作るか、shard数はどうするか。というのはElasticsearch側で設定するのではなく、
indexを作る側であるPacketbeatの設定によって決まります。
そこを理解していないため、データ量の調整でハマってしまいました。
例えば、Elasticsearchのデフォルトのshards数は5ですが、それよりも小さい3にする場合は /path/packetbeat.yml を以下のように設定し、indexテンプレートを作ります。
参考: https://www.elastic.co/guide/en/beats/packetbeat/master/configuration-template.html#configuration-template
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
終わりに
Packetbeatを導入することにより、サーバ単位、サーバ種別でのネットワークトラフィックの総量がわかるようになり、どこからどこに通信が走ったかを追うことができるようになります。
それにより障害対応や、クラウド移行、アプリケーションリプレースの土台となるデータを取得できます。
ただし、導入してみて感じたことはPacketbeatが取得するデータ量の多さによって、Elasticsearch側が悲鳴をあげたので、そこは覚悟しないといけないです。