Google Cloud Dataflow に触る機会があったのですが、いまいちドキュメントが薄く、また自分が分散処理フレームワーク未経験だった事もあり、いろいろハマったので、得られた知見を書いておきます。
本記事は実装編ということで、Dataflow パイプラインのコードを書くに当たっての知見をまとめます。
なお Cloud Dataflow は Apache Beam の実行環境の1つという位置付けです。以下の内容は特に明記していない限り Apache Beam にも当てはまります。
確認した環境は Apache Beam SDK for Java 2.13.0 です。
想定読者は、Beam 関連のドキュメント、特に Beam Programming Guide を読んだことのある方、です。
Window
FixedWindows や SlidingWindows の期間はキリが良い時刻になる
パイプラインに FixedWindows や SlidingWindows を設定すると、パイプライン実行時に生成される各ウィンドウにはそれぞれ期間が設定されますが、それらは入力データやパイプラインの起動時刻などに依存せず、固定の値になり、しかもキリが良い値になります。どういうことかと言うと、例えば、
input.apply(Window.into(FixedWindows.of(Duration.standardMinutes(5))));
とした場合、各ウィンドウに設定される期間は、毎時 00:00〜05:00, 05:00〜10:00, 10:00〜15:00 などとなります。 02:00〜07:00 や、 01:23〜06:23 などにはなりません。
キリが良い、というと定義が曖昧ですが、Unix epoch が起点になります(Javadoc参照)。
期間はキリが良い値からずらすこともできます。withOffset(Duration) を使います。
input.apply(Window.into(
FixedWindows.of(Duration.standardMinutes(5))
.withOffset(Duration.standardMinutes(1))
));
// => 01:00〜06:00, 06:00〜11:00, 16:00〜21:00, ...
Watermark はどんなデータ構造で、何に属しているのか
Beam Programming Guide の 7.4 節 や Streaming 102: The world beyond batch を読むと、Beam の watermark に関してなんとなくは理解できるのですが、実際にコードを書こうとすると、もう少し具体的な watermark のモデルが知りたくなります。
WatermarkManager の Javadoc が参考になりそうです1。これによると:
- watermark 自体は単にタイムスタンプ値である
- PTransform にはそれぞれ入力と出力の watermark がある
- PCollection にはそれぞれ watermark がある
- PCollection の watermark はそれを生成した PTransform の出力の watermark と同じである
また、Dataflow の Monitoring UI で transform (Step) を選択すると Watermark の項目があります。

UI 上は分かりづらいですが、transform 毎にこの項目があり、それぞれ異なった値を示すことがあります。ここで表示されているのはおそらく各 transform の入力の watermark です。
withAllowedLateness とは何なのか
Beam Programming Guide を読んでも Window#withAllowedLateness(Duration) の挙動がよくわかりません。
Streaming 102: The world beyond batch の Figure 8 を見るとわかりやすいです。なおこのドキュメントは Beam で Window を扱う上では必読だと思います。
Figure 8 の設定では、2分間隔の FixedWindow を設定しており、 .withAllowedLateness() に「1分」が指定されています。
下の図で、水平の太い白線は、現在時刻(Processing Time) を示しており、太い緑線は watermark を表しています。
赤矢印の箇所に注目してください。[12:00, 12:02) Lateness Horizon という記述が、Event Time での 12:03 の位置にあります。
これは一番左側にある Window [12:00, 12:02) の終端から 1分経過した位置にありますよね。これが、.withAllowedLateness() によって設定された限界点、Lateness Horizon です。同様に、各 Window に対して Lateness Horizon は存在します。
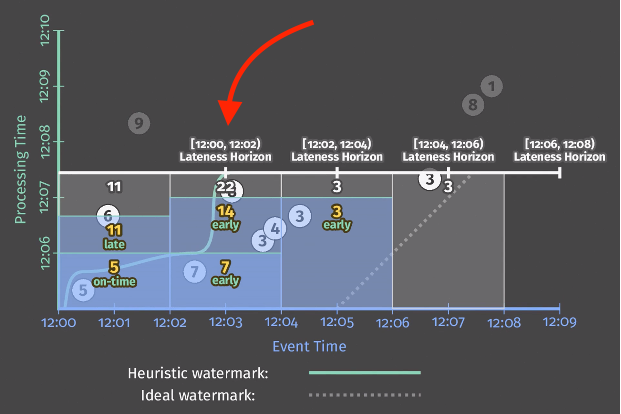
Beam の処理が進むと、図の太い白線が上昇していきます。それに伴い、現在いつの event time を処理しているかを表す太い緑線 = watermark が右に進んでいきます。 processing time が 12:07 プラス25秒ぐらいに来た時、watermark が 12:03 に達し、[12:00, 12:02) の Window は「閉じ」られます。それ以降その Window に入るはずのデータが来ても、破棄されます(図で言うと丸の9は破棄される)。
Figure 8 の最終的な状態の図を見ると、watermark が各 Lateness Horizon に達した点から水平に白い点線が伸びています。これは各 Window が閉じられたタイミングを表しています。
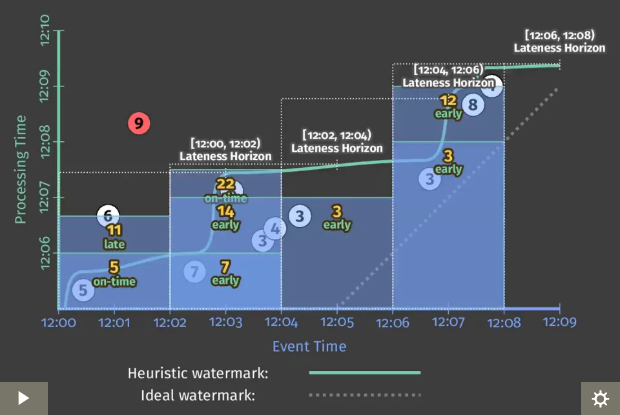
まとめると、
-
.withAllowedLateness()の指定は Window の終端からの Duration になる -
.withAllowedLateness()の指定は Event Time ベースである
AfterWatermark トリガーを読み解く
Beam Programming Guide やサンプルコードなどで、よく以下のようなトリガー設定が出てきます。どういう意味なのでしょうか。
input.apply(
Window.<String>into(FixedWindows.of(Duration.standardMinutes(5)))
.triggering(
AfterWatermark.pastEndOfWindow()
.withLateFirings(AfterProcessingTime
.pastFirstElementInPane().plusDelayOf(Duration.standardMinutes(30))))
.withAllowedLateness(Duration.standardDays(1)));
まず、AfterWatermark.pastEndOfWindow() は決まり文句で、他の組み合わせはありません。watermark が Window の終端まで進んだ時、その時の window の内容 (pane) を出力することを意味します。
他に何も指定しなければ、pane の出力はこの1回きりになりますが、 .withLateFirings() により、それ以降特定の条件を満たす毎にその時点での pane が出力されます。
AfterProcessingTime.pastFirstElementInPane() も決まり文句で、他の組み合わせはありません。pane 内に1つでもデータが入ってきたら、即時 pane を出力するという指定になります。
ただし、ここで .plusDelayOf() の指定があります。これはレシーバーのトリガーに対して、pane の出力を指定した時間だけ遅らせる、という指示になります。結果、pane 内にデータが入ってきても、すぐには pane は出力されず、一定時間待った後に、(待っている間に pane に入ってきたデータがあればそれも含めて) pane を出力することになります。
I/O
PubsubIO の読み込みではタイムスタンプを後付けで変更できない
入力データの中にタイムスタンプ情報が含まれるとき、それをウィンドウ処理の event time として扱うために、入力データを parse して PCollection の要素にタイムスタンプを付与する、ということをしたくなります。
PCollection<Record> timestampedRecords =
input.apply(ParDo.of(new ParseRecords()))
.apply(WithTimestamps.of((Record rec) -> rec.getTimestamp()));
ところが、入力データを PubsubIO から読み込む場合、後付けでタイムスタンプを付与することができません。PubsubIO から読み込んだデータにはデフォルトでは publish された時点のタイムスタンプが付きます2。それを上記のようなコードでタイムスタンプを付け直そうとすると、通常は元のタイムスタンプより古いタイムスタンプを付与することになり、以下のエラーが発生します。
java.lang.IllegalArgumentException: Cannot output with timestamp 2019-06-20T12:34:00.000Z. Output timestamps must be no earlier than the timestamp of the current input (2019-06-20T12:34:56.000Z) minus the allowed skew (0 milliseconds). See the DoFn#getAllowedTimestmapSkew() Javadoc for details on changing the allowed skew.
WithTimestamps#withAllowedTimestampSkew(Duration) メソッドを使えば、エラーメッセージにもある allowed skew を変更してこの問題に対処することができるようです。ですがこのメソッドは deprecated ですし、使った場合データが late data として扱われるそうで、色々トラブルの元になりそうです。
正当なやり方としては、Cloud Pub/Sub にメッセージを publish するときに、追加の属性としてタイムスタンプを設定する方法が示されています。そして PubsubIO をコンストラクトする時にタイムスタンプの属性名を渡します。
// publish側 (w/Google Cloud Client Library)
Publisher publisher = Publisher.newBuilder(topic).build();
long timestamp = Instant.now().getMillis();
PubsubMessage message = PubsubMessage.newBuilder()
.setData(bytes)
.putAttributes("ts", String.valueOf(timestamp)).build();
publisher.publish(message);
// 読み込み側 (Dataflow)
PCollection<String> input =
p.apply(PubsubIO.readStrings().withTimestampAttribute("ts"));
これだと Pub/Sub に publish する側の処理にも手を入れる必要がありますが、現状は他に方法は無さそうです。
参考:
- https://github.com/GoogleCloudPlatform/DataflowJavaSDK/issues/65
- https://issues.apache.org/jira/browse/BEAM-644
Runner
DirectRunner では PubsubIO と AfterWatermark Trigger の組み合わせがうまく機能しない
DirectRunner にはいくつか制約があるようで、必ずしも DataflowRunner と同一の挙動になりません。
私が遭遇したのは、 PubsubIO から読み取って GroupByKey のようなウィンドウ処理をし、 AfterWatermark のトリガーで出力するというケースで、GroupByKey 以降の処理がいつまで経っても進まず、パイプラインから何も出力されないという事がありました。 DirectRunner から DataflowRunner に変更することで解決しました。
原因としては DirectRunner では PubsubIO の watermark 処理に問題があるとのことです。
DirectRunner は手軽に動かせるので開発中はついつい頼りがちになりますが、怪しいと思ったらすぐ DataflowRunner で試しましょう。
参考:
その他SDK関連
PipelineOptions#as(Class) の挙動
PipelineOptions#as(Class) で PipelineOptions インスタンスを任意の PipelineOptions のサブインターフェースにキャストできますが、ちょっと振る舞いがわかりにくいです。 as() のレシーバと返り値のオブジェクトはどういう関係にあるのか。
PipelineOptionFactory.create() や PipelineOptionFactory.fromArgs(String[]) を呼び出して PipelineOptions インスタンスを生成すると、内部的に key-value の組を保持する Map が作られます。 PipelineOptions#as(Class) を呼び出すと、その Map に対して読み書きするようなプロキシオブジェクトが作られ、返されます。
従って実体の Map は1つなので、 PipelineOptions#as(Class) の呼び出しを繰り返しても、以前にセットしたプロパティは維持されます。例えば、以下のようなコードは妥当です。
PipelineOptions options = PipelineOptionFactory.fromArgs(args).create();
Pipeline p = Pipeline.create(options);
p.getOptions().as(MyOptions).setMyFlag(true);
// 後から p.getOptions().as(MyOptions).getMyFlag() で取得できる
Unit Test
TestPipeline は Pipeline と何が違うのか
ユニットテストの時は TestPipeline を使えとドキュメントに書いてありますが、通常の Pipeline クラスと何が違うのでしょうか。
ざっくりソースコードを眺めて調べました。
まず TestPipeline クラスは Pipeline クラスを継承しており、基本的に Pipeline クラスの代替として使うことができます。
TestPipeline は JUnit の TestRule として実装されており、利用する際は @Rule アノテーションを付けて定義します。
@Rule public TestPipeline p = TestPipeline.create();
@Rule アノテーションを付けない場合、テスト実行時にエラーになります(ドキュメントはこれに従っておらず、内容が古いです)。
@Rule アノテーションにより、TestPipeline は個々のテストケースの開始と終了をフックして処理を行うことができます。これを利用して、テスト終了後にいくつかのチェックを行っています。
- Pipeline#run() を呼び出し忘れていないか
- パイプラインに接続されていない PTransform がないかどうか
- パイプラインに接続されていない PAssert がないかどうか
- パイプライン中の PAssert が全て実行されたかどうか
正直、そんなに有り難みは感じないですね。将来的にもっと有用なチェックが追加されるかもしれませんが。
なお PAssert は TestPipeline に限らず Pipeline クラスにおいても使えます。
その他
Dataflow でやらない方が良いタスク: 待ち時間のある処理
Dataflow は大量のデータを並列に処理してくれて非常に便利ですが、やらない方が良いタスクもあります。待ちが多いタスクです。
例えば外部のサーバーに対してHTTP通信をするようなケースです。何らかバッチ的な処理をするために他のサーバーに処理を移譲しているようなケースで、1回のHTTPレスポンスが帰ってくるまでに 10〜30分かかる、それを大量に並列に実行する、、というようなシチュエーションを想像してください。
このようなシチュエーションでは、パイプラインの内容によっては、レスポンスを待つ間 Dataflow は何も出来ない可能性があります。Dataflow の料金モデルはインスタンスに対する時間課金なので、何もしない時間は無駄なコストになります。
もし待ちが多い処理を実行する場合は、Dataflow のジョブを分割して Dataflow ワーカーがブロックしないようにすることをお勧めします。
-
WatermarkManager は DirectRunner の内部実装 ↩
-
protected method の doc comment に書かれています: https://beam.apache.org/releases/javadoc/2.13.0/org/apache/beam/sdk/io/gcp/pubsub/PubsubClient.html#extractTimestamp-java.lang.String-java.lang.String-java.util.Map- ↩