はじめに
前回の 「Deep Learning入門(1) - Chainerを理解し、使えるようになろう -」 にて、Chainerについて使い方をまとめていきました。
リファレンスを一通り追えると大体の使い方が分かってきました。
機械学習を勉強する際には簡単な回帰問題を想定し、その予測モデルを構築できるところまでをできるようになると「理解した使える!」と自分の中で決めています。
そこで、今回は具体的に、非線形なsin関数のデータを生成し、この関数をChainerで構築したモデルにより非線形回帰を行います。
ここまで一通り終えられると、画像判別など発展版に進んでも、理解できるのではないでしょうか。
開発環境
・OS: Mac OS X EI Capitan (10.11.5)
・Python 2.7.12: Anaconda 4.1.1 (x86_64)
・chainer 1.12.0
今回のゴール
下の画像のように、sin関数をバッチリ捉えることができるような非線形回帰モデルを構築します。

非線形回帰モデルを構築
プログラムの全体像
# -*- coding: utf-8 -*-
from chainer import Chain
import chainer.links as L
import chainer.functions as F
class MyChain(Chain):
def __init__(self):
super(MyChain, self).__init__(
l1 = L.Linear(1, 100),
l2 = L.Linear(100, 30),
l3 = L.Linear(30, 1)
)
def predict(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
# -*- coding: utf-8 -*-
# 数値計算関連
import math
import random
import numpy as np
import matplotlib.pyplot as plt
# chainer
from chainer import Chain, Variable
import chainer.functions as F
import chainer.links as L
from chainer import optimizers
from MyChain import MyChain
# 乱数のシードを固定
random.seed(1)
# 標本データの生成
# 真の関数としてsin関数を
x, y = [], []
for i in np.linspace(-3,3,100):
x.append([i])
y.append([math.sin(i)]) # 真の関数
# chainerの変数として再度宣言
x = Variable(np.array(x, dtype=np.float32))
y = Variable(np.array(y, dtype=np.float32))
# NNモデルを宣言
model = MyChain()
# 損失関数の計算
# 損失関数には自乗誤差(MSE)を使用
def forward(x, y, model):
t = model.predict(x)
loss = F.mean_squared_error(t, y)
return loss
# chainerのoptimizer
# 最適化のアルゴリズムには Adam を使用
optimizer = optimizers.Adam()
# modelのパラメータをoptimizerに渡す
optimizer.setup(model)
# パラメータの学習を繰り返す
for i in range(0,1000):
loss = forward(x, y, model)
print(loss.data) # 現状のMSEを表示
optimizer.update(forward, x, y, model)
# プロット
t = model.predict(x)
plt.plot(x.data, y.data)
plt.scatter(x.data, t.data)
plt.grid(which='major',color='gray',linestyle='-')
plt.ylim(-1.5, 1.5)
plt.xlim(-4, 4)
plt.show()
標本データの生成
今回の非線形回帰モデルを構築するための教師データを生成します。
今回は1入力1出力のsin関数を使用します。
# 標本データの生成
# 真の関数としてsin関数を
x, y = [], []
for i in np.linspace(-3,3,100):
x.append([i])
y.append([math.sin(i)]) # 真の関数
# chainerの変数として再度宣言
x = Variable(np.array(x, dtype=np.float32))
y = Variable(np.array(y, dtype=np.float32))
モデルの定義
Deep LearningのモデルをChainerにより構築します。
今回は入力層、隠れ層1、隠れ層2、出力層の4層構成にしました。
ノードの数は適当に決めました(この辺りは前回も書きましたが、経験と勘です)。
興味のある方は、ここの値を編集してみると良いと思います。
隠れ層が2層ある理由は、1層で回帰してみると、うまく特徴を捉えられていなかったため、もう一層増やしたといったところです。
# -*- coding: utf-8 -*-
from chainer import Chain
import chainer.links as L
import chainer.functions as F
class MyChain(Chain):
def __init__(self):
super(MyChain, self).__init__(
l1 = L.Linear(1, 100),
l2 = L.Linear(100, 30),
l3 = L.Linear(30, 1)
)
def predict(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
ポイントとしては、活性化関数にreluを使用しているところでしょうか。
少し前だと、この活性化関数にシグモイド関数を使用することが定番でしたが、最近では、誤差逆伝播法でパラメータを学習させる際に、後ろのそうに行くほど学習率が下がっていく問題を回避するために、reluをよく使うそうです。
この辺りは、私自身も感覚でしか知らないので、もう少し勉強が必要です。
活性化関数については、他にも色々と解説記事があるので、そちらをどうぞ。
参考:【機械学習】ディープラーニング フレームワークChainerを試しながら解説してみる。
未学習の状況で確認
全く学習させていない状況でどうなっているかを確認してみました。
最終的に出てくる結果だけでなく、途中経過も見ることで、全体感を把握できるようになると思っています。
## NNモデルを宣言
model = MyChain()
# プロット
t = model.predict(x)
plt.plot(x.data, y.data)
plt.scatter(x.data, t.data)
plt.grid(which='major',color='gray',linestyle='-')
plt.ylim(-1.5, 1.5)
plt.xlim(-4, 4)
plt.show()

未学習の状況だと、真の関数の特徴を全く捉えられていないといったことがわかるかと思います。
パラメータを学習させる
パラメータを学習させるにあたり、まず損失関数を定義します。
今回は自乗誤差 (MSE; Mean Squared Error) を損失関数として使用します。
{\rm MSE} = \dfrac{1}{N} \sum_{n=1}^{N} \left( \hat{y}_{n} - y_{n} \right)^{2}
※ $N$: サンプル数、 $y_{n}$: $n$ 番目の出力変数、$\hat{y}_{n}$: $n$ 番目の出力変数の推定値
mnistの例だと交差エントロピー関数を使用されていますね。
# 損失関数の計算
# 損失関数には自乗誤差(MSE)を使用
def forward(x, y, model):
t = model.predict(x)
loss = F.mean_squared_error(t, y)
return loss
この損失関数を定義しておくことにより、Chainerでは optimizer の勾配計算を自動的に行うことができます。
# chainerのoptimizer
# 最適化のアルゴリズムには Adam を使用
optimizer = optimizers.Adam()
# modelのパラメータをoptimizerに渡す
optimizer.setup(model)
# 勾配の更新
optimizer.update(forward, x, y, model)
これで基本的な流れはおしまいです。
学習を繰り返す
さきほどの optimizer.update() を何度か繰り返すことにより、良いパラメータへと収束していきます。
今回は教師データを同じもので何度も学習させていますが、本来は、バッチデータとして、標本集団の中からいくつか取り出し、それらを教師データとして学習させ、次のサイクルでは別の標本をバッチデータとして使用するといった流れです。
# パラメータの学習を繰り返す
for i in range(0,1000):
loss = forward(x, y, model)
print(loss.data) # 現状のMSEを表示
optimizer.update(forward, x, y, model)
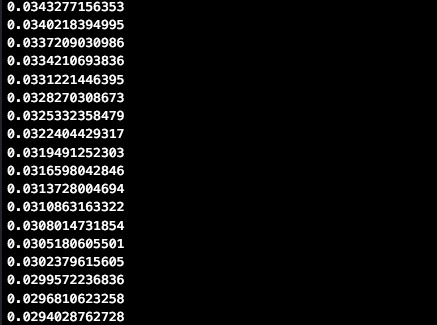
学習を繰り返すごとに、自乗誤差が小さくなっていることがわかると思います。
これで学習を終えれば、非常になめらかに関数を近似出来ました。
参考
1.Chainerの公式リファレンス
色々と日本語で書いてあるものもありましたが、バージョンの変更などで対応できない部分に遭遇することが多く、英語ですがこちらが一番安定していました。
2.Deep Learning入門(1) - Chainerを理解し、使えるようになろう -
おまけ
フォローお待ちしています!
Qiita: Carat 吉崎
twitter:@carat_yoshizaki
はてなブログ:Carat COOのブログ
ホームページ:Carat
機械学習をマンツーマンで学べる家庭教師サービス「キカガク」
「数学→プログラミング→Webアプリケーション」まで一気に学べる「キカガク」に興味のある方はお気軽にご連絡ください。