以下は、Apache Arrow公式サイトの以下のオーバービューページの翻訳をベースに、自分の理解のための、自由な翻案・省略・追記を含みます。
画像は全て、上記からの引用です。
Apache Arrow の概要
Apache Arrow は、大規模なデータ セットを処理および転送する高性能アプリケーションを構築するためのソフトウェア開発プラットフォームです。
Apache Arrowの設計目標は、分析アルゴリズムのパフォーマンスと、あるシステムまたはプログラミング言語から別のシステムまたはプログラミング言語へのデータ移動の効率の両方の向上です。
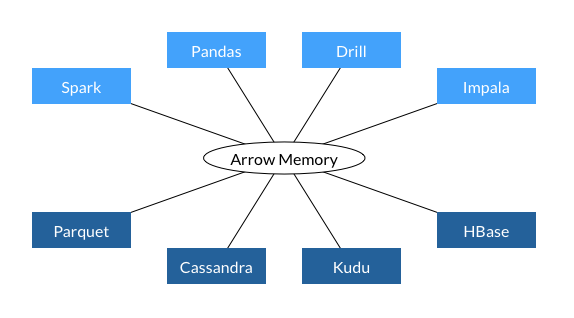
Apache Arrow の重要なコンポーネントは、メモリ内の列形式です。
Apache Arrowは、メモリ内で構造化されたテーブルのようなデータセットを表現するための、言語に依存しない標準化された仕様を設計・実装します。
このデータ形式には、分析データベース システムやデータ フレーム ライブラリなどのニーズをサポートするように設計された豊富なデータ型システム (ネストされたデータ型やユーザー定義のデータ型を含む) が含まれています。
実行効率向上のためのカラムナーデータ型の選択
Apache Arrow 形式を使用すると、計算ルーチンと実行エンジンが、大きなデータ チャンクをスキャンして反復するときに効率を最大化できます。特に、連続した縦列レイアウトにより、最新のプロセッサに含まれる最新の SIMD (単一命令、複数データ) 操作を使用したベクトル化が可能になります。

標準化による保存
標準の列指向データ形式がなければ、すべてのデータベースと言語は独自の内部データ形式を実装する必要があります。これにより、大量の廃棄物が発生します。あるシステムから別のシステムにデータを移動するには、コストのかかるシリアル化と逆シリアル化が必要になります。さらに、一般的なアルゴリズムはデータ形式ごとに書き直さなければならないことがよくあります。
Arrow のメモリ内列指向データ形式は、これらの問題に対するすぐに使用できるソリューションです。Arrow を使用またはサポートするシステムは、ほとんどコストをかけずにシステム間でデータを転送できます。さらに、他のすべてのシステムにカスタム コネクタを実装する必要もありません。これらの節約に加えて、標準化されたメモリ形式により、言語を超えてもアルゴリズムのライブラリの再利用が容易になります。

アローライブラリ
Arrow プロジェクトには、多くの言語で Arrow 列形式のデータを操作できるライブラリが含まれています。C ++、C#、Go、Java、JavaScript、Julia、およびRustライブラリには、Arrow 形式の個別の実装が含まれています。さらに、C (Glib)、MATLAB、Python、R、およびRuby用の Arrow ライブラリが C++ ライブラリ上に構築されています。