はじめに
本稿は、Jonathan Ellisによる以下の記事の内容をベースとして日本の読者向けに執筆した逐語訳に拘らない自由な翻案です。
はじめに
本記事の目的
ベクトル検索は、 生成 AIアプリケーションを構成する重要なコンポーネントです。ベクトル検索を用いることによって、LLMによって実現されるサービスに最新の情報、あるいはカスタマイズされた情報(またはその両方)をもたらすことができます。
2023年以来、ベクトル検索機能を提供する製品が爆発的に増加しており、その中からどれを選択するのが適切かという課題があります。
実際のところ、どうやって選択すれば良いでしょうか?
技術的な選択肢を検討するときは、その技術領域固有の課題の理解が重要です。そうした理解の上に立って、それぞれの選択肢が、課題を解決するためにとっているアプローチを検討することが重要です。
ここでは、ベクトル検索における、そうした典型的な課題について説明し、DataStax Astra DB および Apache Cassandra のベクトル検索の実装のために DataStax がどのように課題に取り組んだかについて説明します。
次元の呪い
ベクトル検索をめぐる問題の核心に、「次元の呪い」と呼ばれるものがあります。2次元または 3次元空間で通用する機能が、ベクトルの次元が数十、数百、あるいは数千に達した場合に、同じように通用するとは限りません。要するに、高次元ベクトルにおいて「完全な」類似性検索は、決して容易いものではないといえます。このような「次元の呪い」を回避する、高次元ベクトルにおける現実的な選択肢として、近似最近傍 (ANN) アルゴリズムがあります。
現在、ベクトル検索に、このアルゴリズムが広く活用されています。しかし、このアルゴリズムを選択しさえすれば全てが解決するというわけではありません。
ここには、以下のような問題があります。
問題 1: スケールアウト(データは増える)
従来の多くのベクトル検索機能は、単一マシンのメモリに収まるデータセット向けに設計されていました。そして、著名なAnn Benchmarks( https://ann-benchmarks.com/ )においても、いまだにこのようなシナリオが用いられています。(Ann Benchmarksでは、テスト環境のリソースが1コアというあまりに貧弱な環境に制限されています!) これは、純粋に学術的な検討では問題なかったかもしれませんが、既に現実を映していないと言えそうです。
データベースのスケールアウトにはレプリケーションとパーティショニングの両方が必要です。また、デッドレプリカの交換やネットワーク分離が発生した際のレプリカの修復などを処理するサブシステムも必要です。ベクトルデータベースであっても、このことは、一般のデータベースと変わらず必要になります。
スケールアウト レプリケーションは Cassandra の基本です。さらに、それを Cassandra-5.0 の新機能 SAI (Storage-Attached Indexing) と組み合わせることができます。
現在のCassandraのベクトル検索実装により、強力なスケールアウト機能が実現されています。
問題 2: 効率的なインデックス更新(データは更新される)
データベースの検索を可能にする「インデックス」について、新規作成・追加だけを考えれば良いわけではなく、インデックスから古い情報を削除すること、つまり不要になったデータを一掃(いわば「ガベージコレクション」)することが必要です。これによって、インデックスの効率的な処理が可能になります。
これは、リレーショナル データベースの世界では 長きにわたって多かれ少なかれ解決されてきた問題です。その意味では、いまさらと感じるかもしれません。しかし、ベクトルにおけるインデックスの扱いに固有の要素があります。
問題は、低遅延の検索と高い再現率の結果の両方を提供する、よく知られた多くのアルゴリズムがグラフベースであることです。グラフベースのもの以外にも多数のベクトルデータのインデックス化のためのアルゴリズムが存在しており、例えば、FAISS というライブラリはそれらのアルゴリズムの多くを実装していますが、それらはすべて、インデックスの構築において、あるいはインデックスを用いた検索において、遅すぎるか、または一般的なアルゴリズムとして使用するために、再現率が低すぎるかのいずれか、悪くすればそれらの両方、です。
多くのベクトル データベースがグラフベースのインデックスを使用していますす。その中で最も単純なものが HNSW です。これは、階層型ナビゲート可能なスモールワールドグラフを意味し、2016 年に Yury Malkov らによって導入されました。
HNSW については以下で詳しく説明します。
グラフ インデックスの課題は、行やドキュメントが変更されたときに古い (ベクトルに関連付けられた) ノードを単純に削除できないことです。削除を数回以上行うと、グラフは目的を実行できなくなります。
したがって、このガベージ コレクションを実行するには、ある時点でインデックスをはじめから再構築する必要があります。しかし、いつ、どのように整理するというのでしょうか? 変更が行われたときに常にすべてを再構築すると、実行される物理書き込みが大幅に増加します。一方、再構築しない場合は、クエリ時に古い行をフィルタリングして除外する追加の作業を実行することになります。
これは、Cassandra が長年取り組んできた問題領域です。SAI インデックスは、読み取りと書き込みの健全なバランスを提供します。
それはそもそも、(ベクトル検索機能に限られない)メイン ストレージのライフサイクルに関連付けられていることからくる利点を持ちます。例えば、従来から用いられている、Cassandraのコンパクションメカニズムの恩恵を受けます。
問題 3: 同時実行性(リクエストは一つずつしか来ないわけではない)
Ann Benchmarks比較では、すべてのベンチマーク比較が1 つのコアの利用を想定したものになっていると述べました。これは比較の環境を平準化する一方で、過去 20 年間にわたるハードウェアの改善の恩恵を利用できる人たちを不利な立場に陥らせることにもなります。
関連する問題は、Ann Benchmarksが一度に 1 種類の操作しか実行しないことです。つまりは、まず最初にインデックスを構築し、そうして次にインデックスをクエリする、というシナリオです。
インデックス構築後のデータ更新に対処する必要がないことがわかっている場合は、人工的なベンチマークでは適切に見える、単純化のための多くの仮定によって立つことができます。
とはいえ、運用開始後にデータ更新が発生する場合、その都度インデックスはアップデータされなければ用をなさないので、上記のような人工的なベンチマークの前提に準拠していることは、現実的な利用に際して、おそらくハンディキャップになる可能性があります。
インデックスの初期構築後にインデックスを更新できることが重視される場合は、インデックスに対して複数の同時操作を実行できること、インデックスがどのように機能するのか、そして、どのようなトレードオフが関係しているのかを理解する必要があります。
まず、私が知っている汎用ベクトル データベースはすべて、グラフベースのインデックスを使用しています。これは、最初のベクトルが挿入されるとすぐにグラフ インデックスのクエリを開始できるためです。他のほとんどのオプションでは、クエリを実行する前にインデックス全体を構築するか、少なくともデータの予備スキャンを実行して統計的プロパティを学習する必要があります。
ただし、グラフ インデックス カテゴリ内にも重要な実装の詳細がまだあります。たとえば、私たちは当初、MongoDB、Elastic、Solr と同じように、Lucene の HNSW インデックス実装を使用することで時間を節約できるのではないかと考えました。しかし、 Lucene が提供するのはシングルスレッドの非同時インデックス構築のみであることがすぐにわかりました。つまり、構築中にクエリを実行したり (これがこのデータ構造を使用する主な理由の 1 つです!)、複数のスレッドで同時に構築することもできません。
HNSW の論文では、きめ細かいロック手法が機能する可能性があることを示唆していますが、私たちはさらに改良を加えて、ノンブロッキング インデックスを構築しました。これはJVectorでオープンソース化されています。
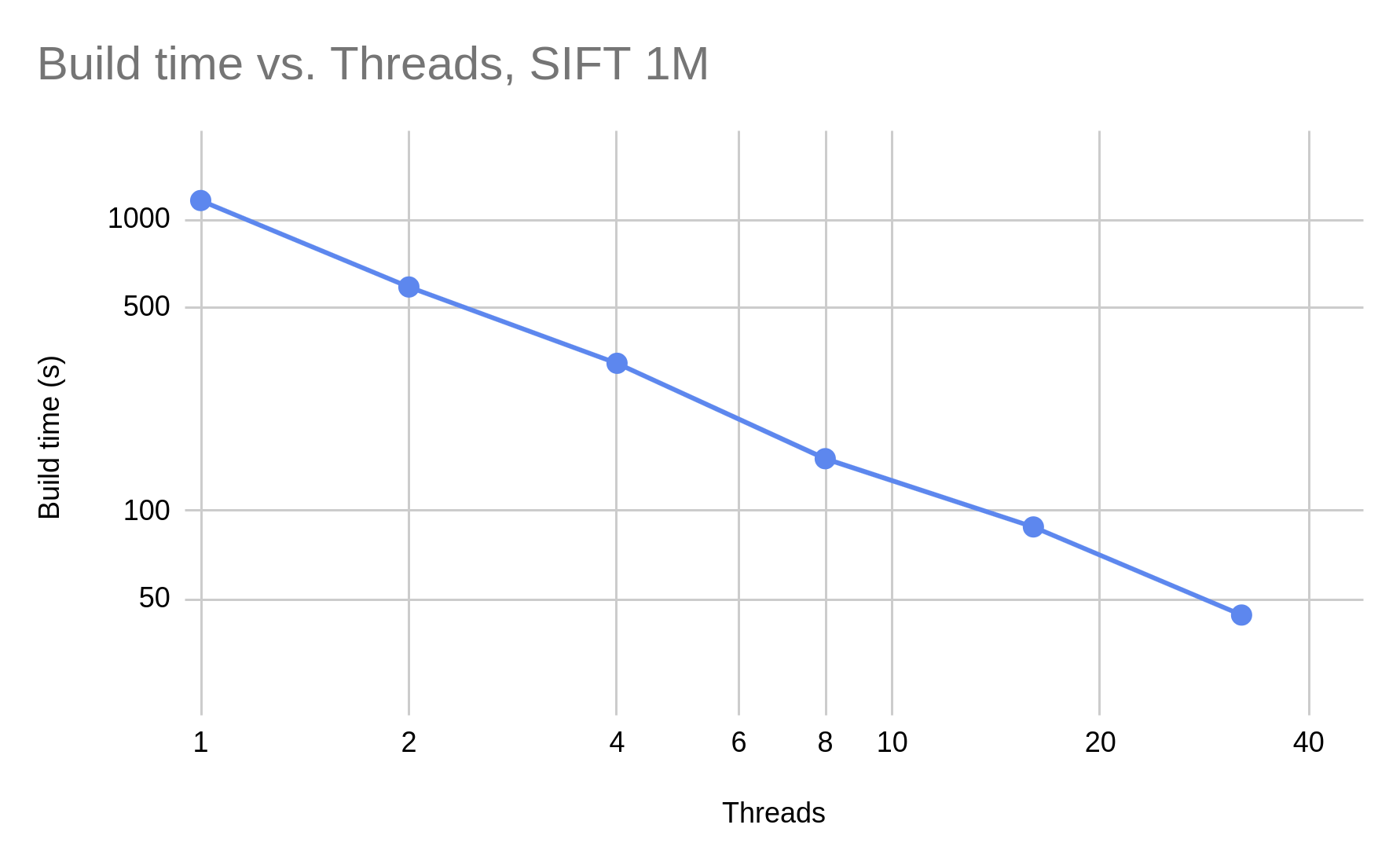
JVector は、同時更新を少なくとも 32 スレッドまで線形に拡張します。このグラフは x 軸と y 軸の両方で対数スケールになっており、スレッド数が 2 倍になるとビルド時間が半分になることがわかります。
JVector のノンブロッキング同時実行性により、検索と更新が混在するより現実的なワークロードにメリットをもたらします。以下は、さまざまなデータセットにおける Astra DB のパフォーマンス (JVector を使用) と Pinecone の比較です。Astra DB は、静的データセットの場合は Pinecone よりも約 10% 高速ですが、新しいデータのインデックス作成も 8 倍から 15 倍高速です。より高いスループットとより低いレイテンシに関する推奨事項に基づいて、Pinecone で利用可能な最適なポッド層 (ポッド タイプ: p2、ポッド サイズ: x8、レプリカごとに 2 つのポッド) を選択しました。Pinecone は、これがどのような物理リソースに対応するかを明らかにしていません。Astra DB 側では、デフォルトの PAYG デプロイメント モデルを選択しましたが、サーバーレスであるため、リソースの選択について心配する必要はありませんでした。テストはNoSQLBenchを使用して実行されました。
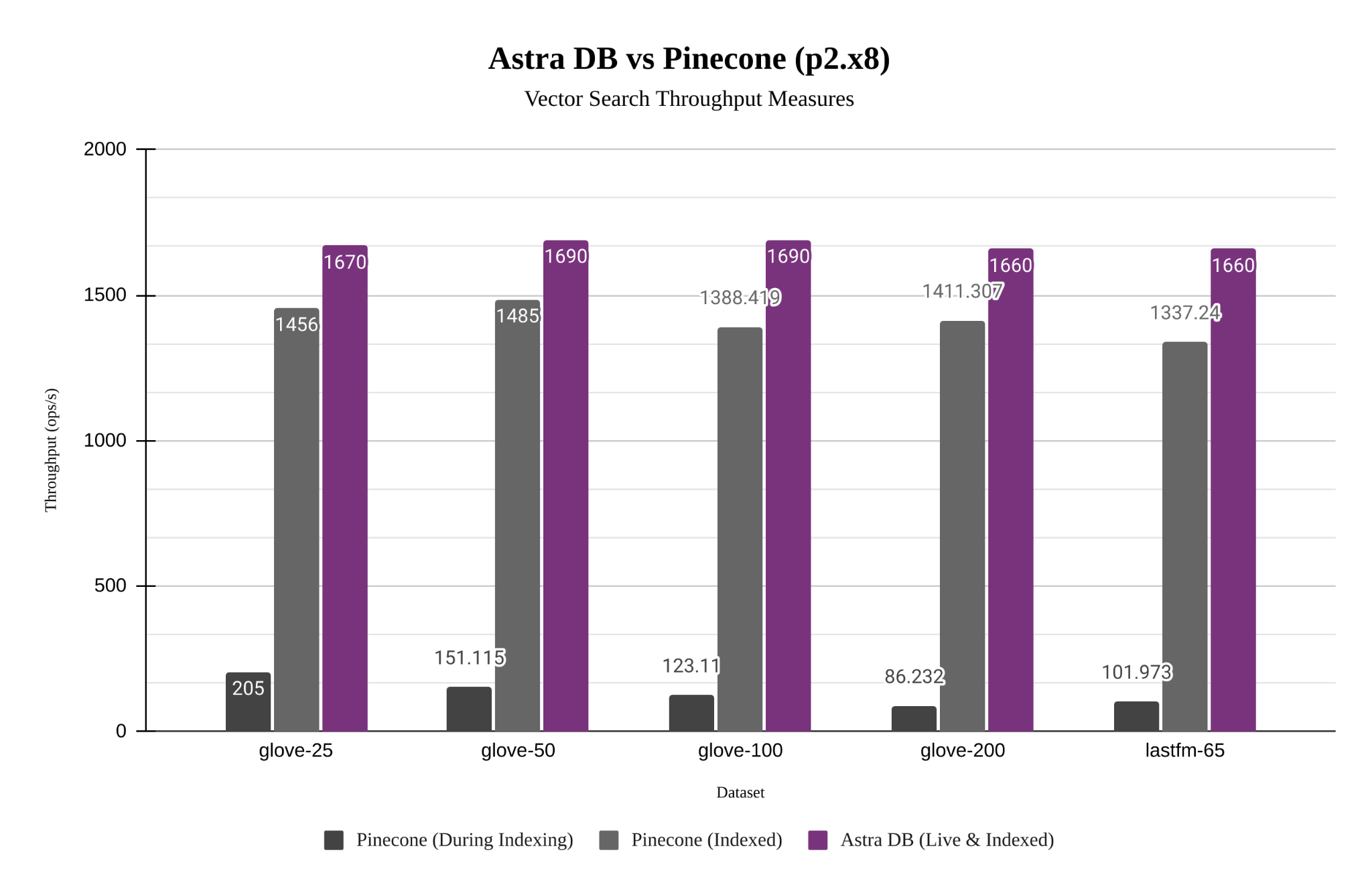
Astra DB は、より高い再現率と精度を維持しながらこれを実行します ( F1 は再現率と精度の組み合わせです)。
問題 4: ディスクの有効活用(その処理は、メモリだけで処理できるか?)
私たちが、HNSW グラフ インデックス アルゴリズムから始めたのは、インデックスの構築が速く、クエリが速く、精度が高く、実装が簡単なためでした。ただし、これには、多くのメモリを必要とするというよく知られた欠点がありました。
HNSW インデックスは複数のレイヤー構造からなり、ベース レイヤーより上の各レイヤーには、前のレイヤーの約 10% のノードがあります。これにより、上位層がスキップ リストとして機能し、すべてのベクトルを含む下位層の右近傍を検索できるようになります。
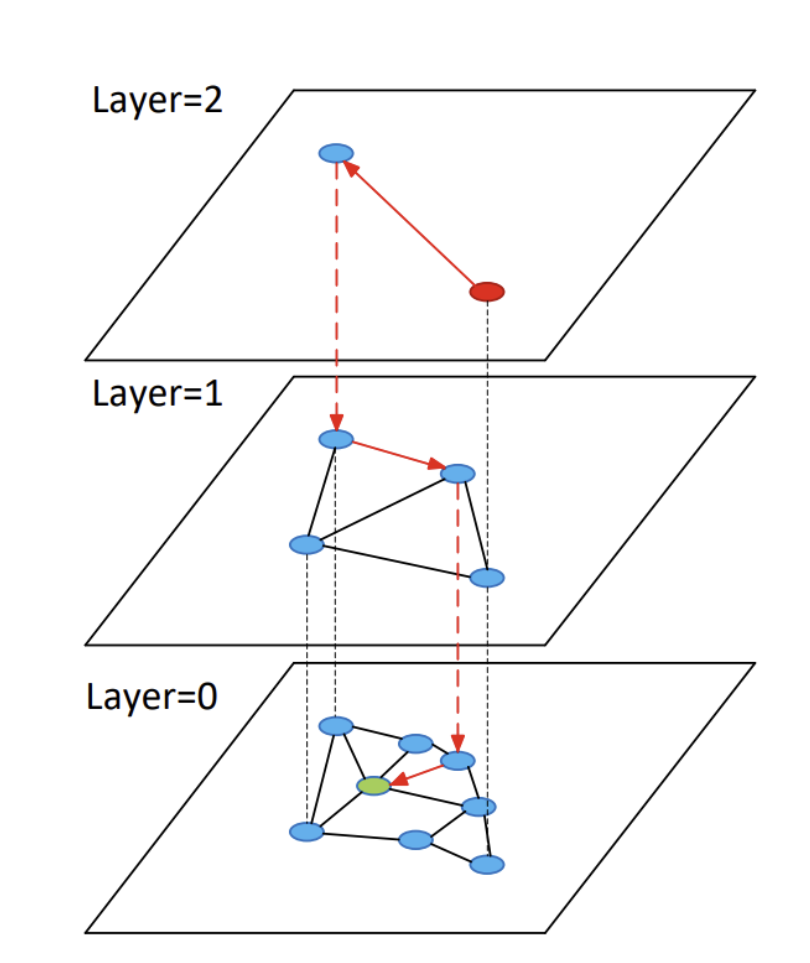
ただし、この設計には、(すべてのグラフインデックスに共通していることですが) 「キャッシュすれば速くなるから」といわれて、それはいかにも尤もらしく聞こえたとしても、いつでも現実的に叶えられるとは限らない、という面があります。これは、通常のデータベース クエリ ワークロードとは異なり、グラフ内のすべてのベクトルがほぼ等しい確率で、検索に関連していることによります。(例外は上位層であり、キャッシュすることができます。)
Lucene を使用していた頃、現実的な規模のベクトル データセット(例えば、Wikipedia 記事チャンクの 1 億件のベクトル データセット。これは約 120 GBのサイズを持ちます)を扱おうとするとき、Cassandra は、ディスクからベクトルを読み取るのを待つことにほぼすべての時間を費やしていました。
この問題を解決するために、DiskANN と呼ばれるより高度なアルゴリズムを実装し、それをスタンドアロンの組み込みベクトル検索エンジンJVectorとしてオープンソース化しました。(具体的には、JVector は、 FreshDiskANNの論文で説明されている DiskANN のインクリメンタル バージョンを実装しています。)
簡単に説明すると、DiskANN は、HNSW よりも長いエッジを持つ単一レベルのグラフと、ベクトルと近傍の最適化されたレイアウトを使用して、ディスク IOPS を削減し、ベクトルの圧縮表現を維持します。類似度の計算を高速化するためにメモリ内に保存されます。これにより、Wikipedia ワークロードのスループットが 3 倍になります。
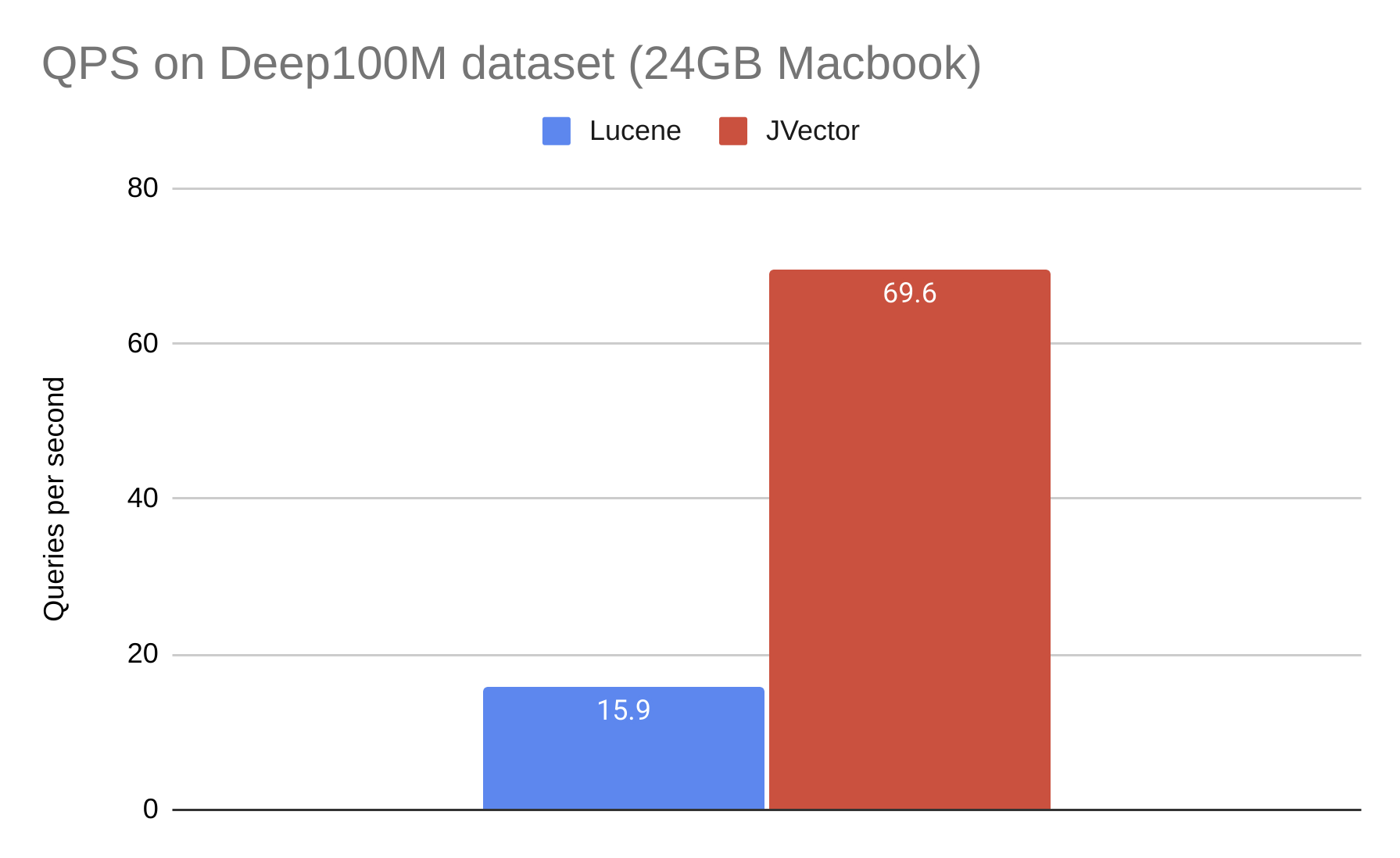
クライアント/サーバー コンポーネントを持たない純粋な組み込みシナリオでの HNSW と DiskANN の比較を次に示します。これは、Lucene (HNSW) および JVector (DiskANN) での Deep100M データセットの検索速度の測定結果です。検索は私の 24GB MacBook で実行され、この MacBook には、RAM にインデックスを保持するのに必要なメモリの約 3 分の 1 が搭載されています。
問題 5: Composability:システム構成の柔軟性(データベースに求められるものは多様〜ベクトル検索だけできれば十分ですか?)
データベース システムのコンテキストにおける「Composability」とは、一貫した方法でさまざまな機能をシームレスに統合する機能を指します。この概念は、ベクトル検索などの新しいカテゴリの機能とのインテグレーションを検討する場合に特に重要です。アプリケーションが単なるトイ・プログラムでなければ、常に従来のCRUDデータベース機能と新しいベクトル検索の両方が必要です。
シンプルなAI チャットボットサンプル アプリケーションを考えてみましょう。これは、純粋な RAG アプリケーションであり、ベクトル検索を使用して適切なドキュメントを LLM に提示した上で、ユーザーの質問に答えます。ただし、このような単純なデモでも、会話履歴を取得するために Astra DB に対して「通常の」非ベクトル クエリを実行する必要があります。これは、LLM が既に行った内容を「記憶」できるように、LLM へのすべてのリクエストにも含める必要があります。したがって、主要なクエリには次のものが含まれます。
- ユーザーの質問に最も関連するドキュメント (またはドキュメントの断片) を見つけます。
- ユーザーの会話から最後の 20 件のメッセージを取得します
より現実的な使用例として、当社のソリューション エンジニアの 1 人が最近、製品カタログにセマンティック検索を追加したいと考えているアジアの企業と協力していましたが、用語ベースのマッチングも可能にしたいと考えていました。たとえば、ユーザーが [「赤」ボール バルブ] を検索する場合、ベクトル埋め込みが意味的にどれほど類似していても、説明が「赤」という用語に一致する項目に検索を制限したいと考えます。したがって、重要な新しいクエリは (セッション管理、注文履歴、ショッピング カートの更新などの従来の機能に加えて)、引用された用語をすべて含む製品に製品を制限し、ユーザーの検索に最も類似したものを見つけます。
この 2 番目の例は、アプリケーションが従来のクエリ機能とベクトル検索の両方を必要とするだけでなく、多くの場合、同じクエリ内でそれぞれの要素を使用できる必要があることを明らかにしています。
この若い分野における現在の最先端技術は、私が「クラシッククエリ」と呼んでいるものを「従来の」データベースで実行し、ベクトル クエリをベクトル データベースで実行し、両方が有効な場合にその 2 つをアドホックにつなぎ合わせることです。しかしながら、これはエラーが発生しやすく、時間がかかり、コストがかかります
Astra DB では、Cassandra SAI 上に、より優れたソリューションを構築 (そしてオープンソース化) しました。SAI では、Cassandra SSTable と圧縮ライフ サイクルにすべて関連付けられたカスタム インデックス タイプを作成できるため、開発者は Astra DB で簡単にブール述語、用語ベースの検索、およびベクトル検索をオーバーヘッドなしで組み合わせることができます。さらに、個別にデータベースシステムの管理を行う必要がなくなり、これにより、生成 AI アプリケーションを構築する開発者は、より高度なクエリ機能を利用できるようになり、生産性が向上し、市場投入までの時間が短縮されます。
結論
ベクトル検索エンジンは、重要な新しいデータベース機能である一方、以下のような複数のアーキテクチャ上の課題を伴っています。
- スケールアウト
- ガベージ コレクション(データ更新への考慮)
- 同時実行性
- ディスクの効果的な使用
- システム構成の柔軟性
参考情報
ベクトル検索アルゴリズムを詳しく知りたい場合は、JVectorリポジトリをご覧ください。
サイドストーリー: クラウド アプリケーションのワークロードの観点からの考察
DataStax Astra DB は、Apache Cassandra 上に構築され、クラウドアプリケーション(インターネット規模のサービス)ワークロード用のプラットフォームを提供します。
例えば、それは、次のようなワークロードです。
- 1 秒あたり数千から数百万のリクエストを同時に大量に実行 これは、コスト的に余裕があったとしても、Snowflake 上で Netflixシステムが実現できなかった理由です。Snowflake や同様の分析システムは、それぞれが数秒から数分、あるいはそれ以上実行される少数の同時リクエストのみを処理するように設計されています。
- メモリよりも大きいデータセットが 1 台のマシンのメモリに収まる場合、どんなツールを利用するかはほとんど問題になりません。SQLite、MongoDB、MySQL — それらはすべて正常に動作します。そうでない場合、事態はより困難になります。そして、重要なのは、ベクトル埋め込みは通常数キロバイトに達するため(これは一般的なデータベースに格納されるデータよりも約 1 桁大きい)、比較的すぐにメモリを超えるサイズに到達してしまうことです。
- アプリケーションの中核データがそれほど重要ではない、または、データが失われても気にしないのであれば、やはり、どのツールを使用するかは関係ないかもしれません。Cassandra や Astra DB などのデータベースは、何があってもデータの可用性と耐久性を維持できるように構築されています。