はじめに
本記事は、Node.js + NoSQL(Couchbase) を使ったアプリ開発をステップバイステップで解説していくシリーズの第二回目になります。
下記の第一回記事も適宜参照していただければ幸いですが、開発の実際に進む前に、まずは表題についての解説から始めます。
Node.js + NoSQL(Couchbase) アプリ開発 ステップバイステップガイド (1)
なぜ、JavaScriptとNoSQLの組み合わせなのか?
NoSQLは、非RDB(RDB以降の技術)であることのみを共通点として、様々な異なる特色を持った技術に対する総称となっていますが、ここで対象とするカテゴリーは、その中でもドキュメント指向データベース(ドキュメントストア)と呼ばれるものです。
ドキュメントストアは、JSONデータを格納することを特徴としており、自ずと、JavaScriptと親和性を持っています(JSON = Java Script Object Notation)。
その一方、RDBから移行するだけの利点があるのか、というのが実際的な関心なのではないかと思います。こちらについては後ほど触れていきます。
CEANスタック紹介
ここで、用いるCEANスタックとは、下記の技術要素からなります。
- C: Couchbase (NoSQLドキュメント指向データベース)
- E: Express (Webアプリケーション・フレームワーク)
- A: Angular (フロントエンド・フレームワーク)
- N: Node.js (サーバサイドJavaScript実行環境)
類似のものとして、MEANスタック、という言葉を聞いたことがある方もいるのではないかと思います(そうは言っても、LAMP程には、浸透していない気もしますが)。この場合のMは、MongoDBとなり、Couchbase同様、JSONデータを扱うことのできるNoSQLデータベースです。
以下では、NoSQL/ドキュメントストアとしてCouchbaseについてのみ記します(MongoDB/MEANスタックについては、様々存在する別の記事・情報に譲ります)。
NoSQL/Couchbaseを選択する理由
慣れ親しんだRDBに替えて、あえてNoSQL/Couchbaseを選択する理由としては、様々な角度から語ることができますが、ここでは、以下の点にフォーカスしたいと思います。
それは、Couchbaseなら、JSONデータとクエリ言語の両方の利点を活用することができる、ということです。
一つずつ、見ていきたいと思います。
JSONデータの利点
これは、RDBの欠点と見ることもできます。つまり...
- アプリケーションが必要とするデータ構造(ドメインオブジェクト)と、RDBが要請する形式(第一正規形テーブル構造)との間には、断絶がある。
- アプリケーションの設計、実装、改善、機能追加など、全ての工程において、データベースとの兼ね合いを図る必要がある(密結合)
これに対して、データ層が、JSONを許容した場合...
- データ層は、第一正規形を要請しないため、アプリケーションが必要とするデータ構造(ドメインオブジェクト)そのものを格納することができる。
- (JSONには、データ構造に関する情報がデータ自体に含まれているため)アプリケーション設計・開発工程において、特にデータ設計の変化に(データベース側の作業を伴うことなく)柔軟に対応できる
クエリ言語の利点
これは、RDBの持つ大きな利点であり、標準化されたクエリ言語(SQL)が様々な異なるデータベースで利用できることは、技術者層の拡大に繋がり、SQLの習得は、(特にオープンシステムのWEBアプリケーション全盛時代には)システム開発者にとって、必須知識といえるものとなっていました。
Couchbaseを選択することで、開発者は、SQLの知識を活用することができます。
サンプル・アプリケーション紹介
CEANスタックで開発したアプリケーションを下記に公開しています。
このアプリケーションは、下記の画面を見ていただければ分かるように、最小限の機能からなるシンプルなものとなっています。
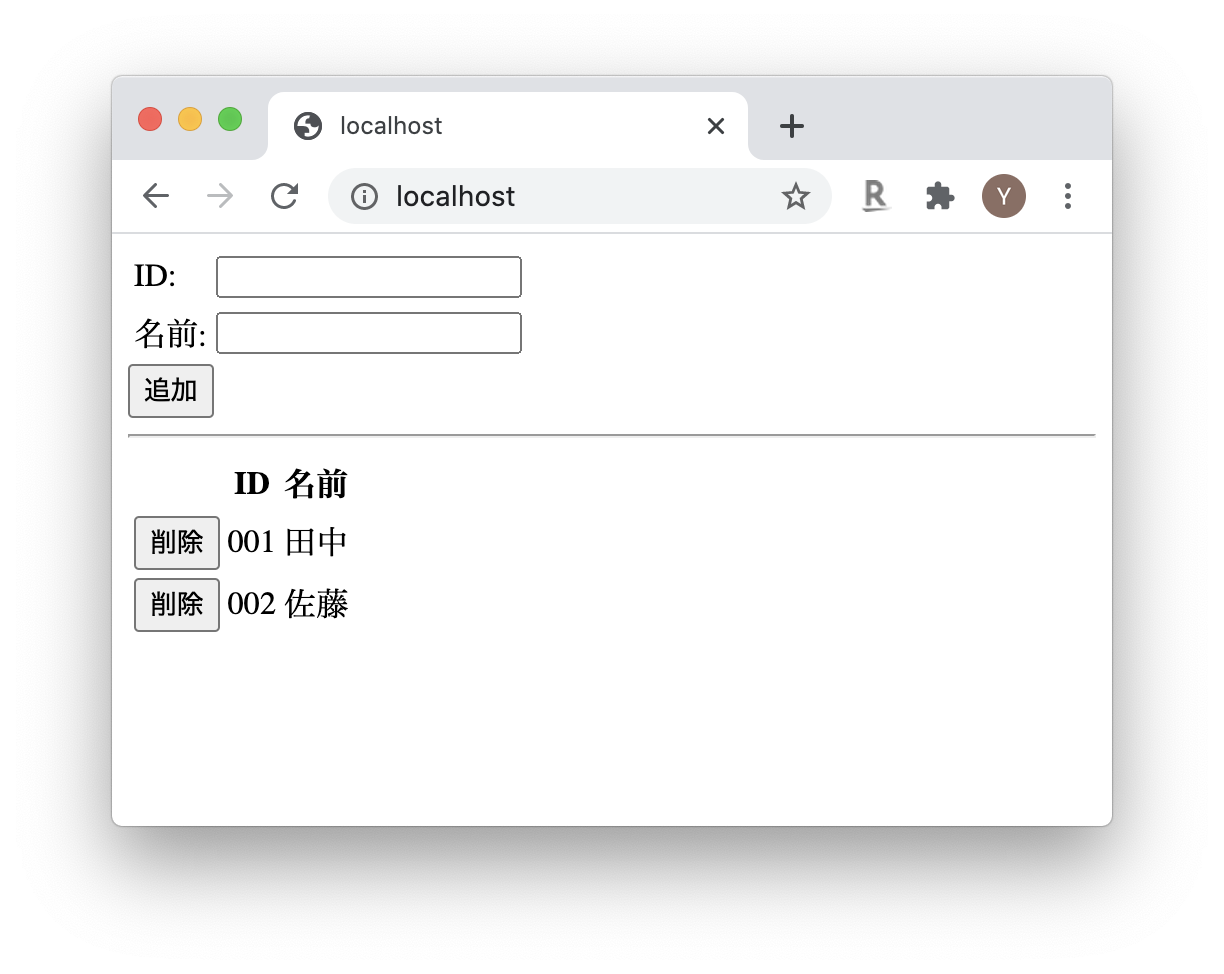
アプリケーション実行方法
上記のリポジトリから、コードを取得します。
$ git clone https://github.com/YoshiyukiKono/couchbase_step-by-step_node_jp.git
$ cd couchbase_step-by-step_node_jp
その中に含まれる、package.jsonには、下記の依存関係が定義されています。
"dependencies": {
"couchbase": "^3.1.0",
"express": "^4.17.1"
}
第一回の内容も合わせて、参照していただきたいと思いますが、このアプリケーションでは、バケット名としてnode_appを使っています。
アプリケーション実行前に、下記のようにインデックスを作成しておく必要があります。
$ cbq -u Administrator
Enter Password:
Connected to : http://localhost:8091/. Type Ctrl-D or \QUIT to exit.
...
cbq> CREATE PRIMARY INDEX node_app_primary ON node_app;
このアプリケーションでは、下記のように、server.jsを使います。
$ node server.js
Server up: http://localhost:80
http://localhost:80にアクセスします。
プログラム解説
routes.jsを見ると、画面のリスト表示のために、下記のようなクエリが使われているのが分かります。
const qs = `SELECT name, id from node_app WHERE type='user'`;
一方、プログラム中のデータ(ドメインオブジェクト)の表現と、そのデータをデータベースへの保存する部分は、下記のようなものです。
const user = {
type: "user",
id: req.body.id,
name: req.body.name,
};
upsertDocument(user);
const upsertDocument = async (doc) => {
try {
const key = `${doc.type}_${doc.id}`;
const result = await collection.upsert(key, doc);
} catch (error) {
console.error(error);
}
};
JavaScriptのディクショナリをそのまま格納しているのが分かります。
最後に
今回は以上です。コードができるだけ分かりやすいものとなるよう、処理やデータ構造は最小限のものとしています。
実は私自身、CEANスタックを用いるのは今回初めてだったのですが、いたずらに複雑でないぶん、コード自体を見ていただくことで、全体の関係が掴みやすいものになっているのではないかと思います。
今後について
ディクショナリ/JSONデータをそのまま使うことで、ORマッピングなどを用いる必要がなく、シンプルに開発ができることがわかったかと思います。一方で、単なるマップ型のデータ構造ではなく、ドメインオブジェクトをクラスとして定義したいというニーズもあるかと思います。Couchbaseには、Ottoman.jsというオープンソースのODM(Object Document Mapping)フレームワークがあり、そうしたニーズにも対応することができます。
こちらについても、今後紹介していきたいと考えています。