はじめに
本稿の目的
本稿は、LangChainという技術について関心を持った方へ向けて、できるだけ前提知識を想定せずに入門するための情報を提供する目的で書かれています。
主な対象読者
本稿は、主な対象読者として、ビジネスアプリケーションに携わる開発者、アーキテクトを想定しています。そのため、テーマの学術的・理論的な側面よりも、実務的な側面(例えば、生成AIを活用したサービス開発からの観点)に比重を置いています。
本稿の構成
本稿の構成は、以下の3ステップからなっています。
- 生成AI活用アプリケーション概要
- ベクトル検索
- LangChain入門
生成AI活用アプリケーション概要
初めに、生成AIを活用したアプリケーションとはどのようなものかについて見ていきます。
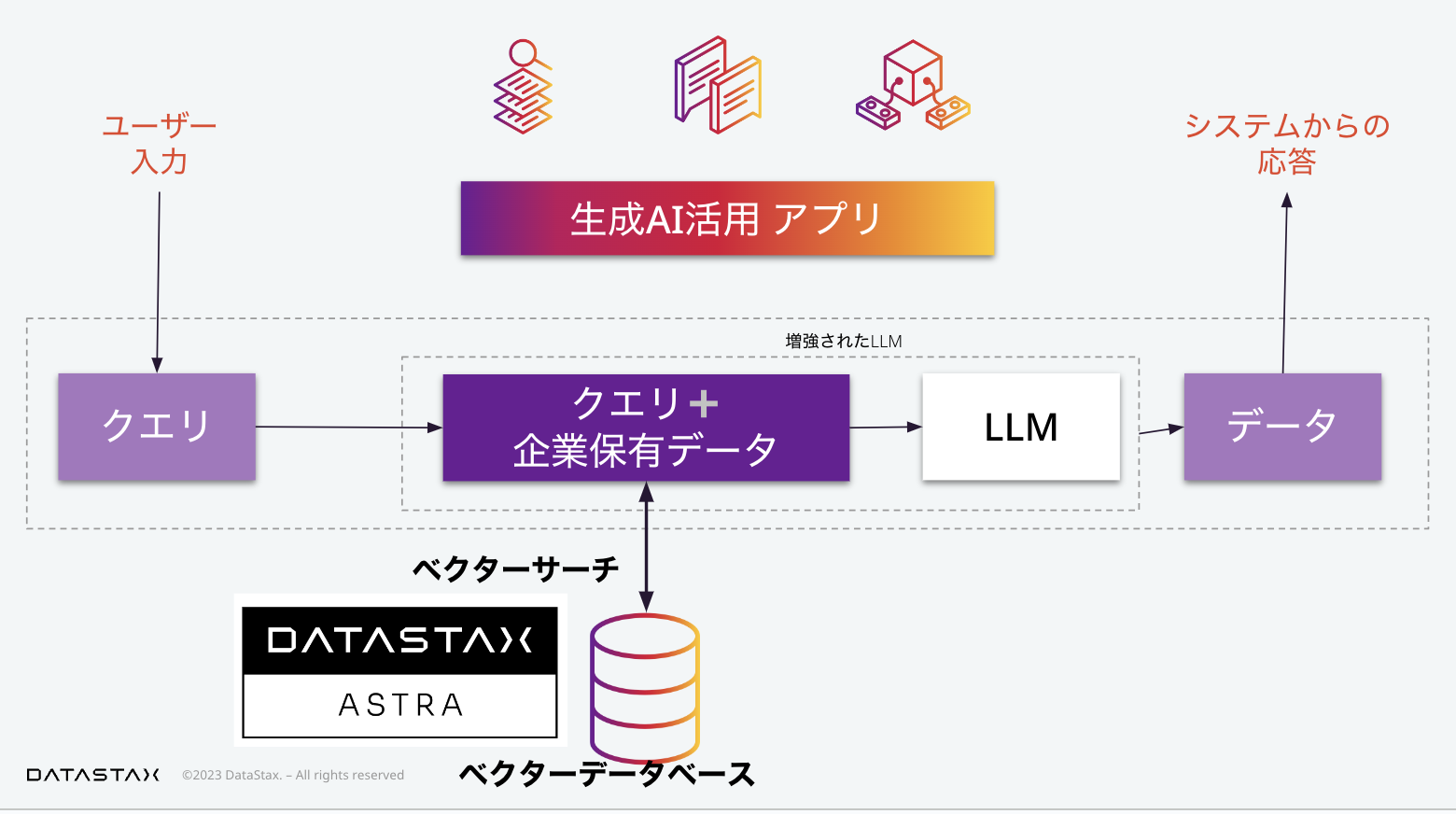
生成AIアプリケーションの内部では、ユーザーが入力したデータが、LLM、大規模言語モデルへのインプットとして扱われます。最もシンプルな構成を考える場合、単に外部のLLM APIをコールしていると考えることができます。
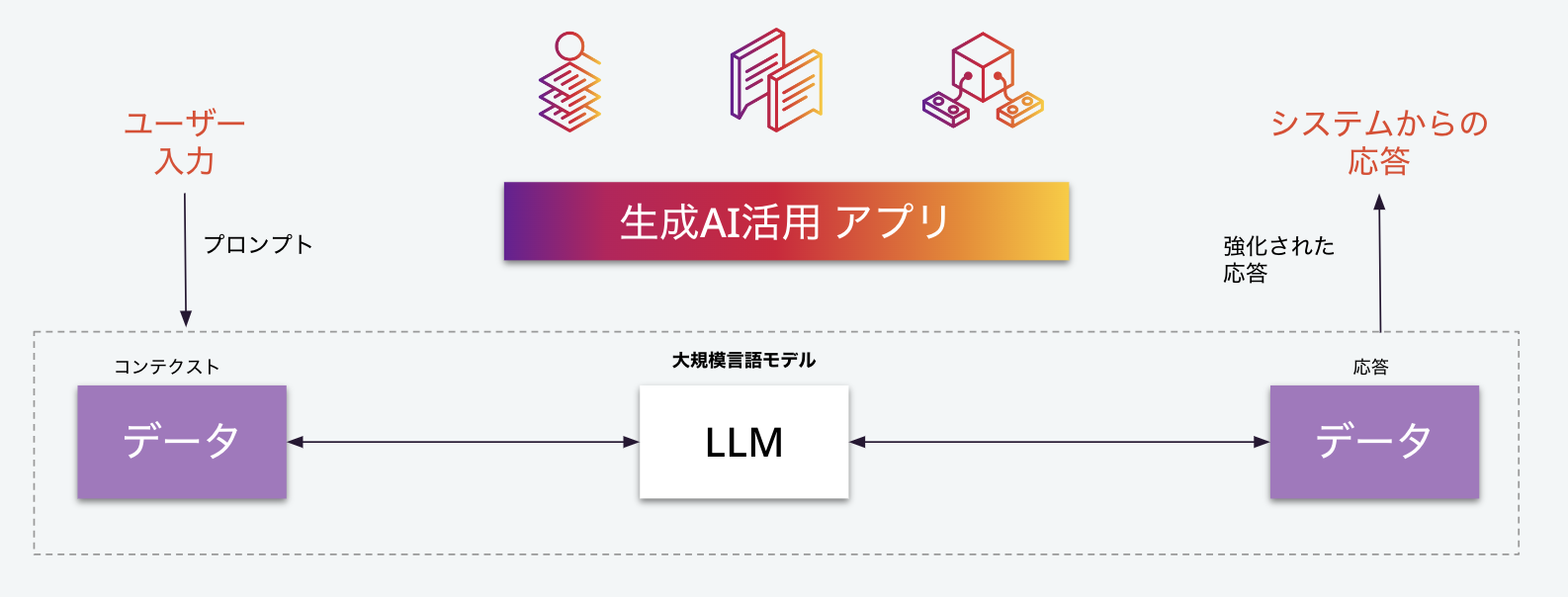
すぐにわかる通り、単に既存のLLMをそのまま使う場合、APIコールであれ、オープンソースのモデルであれ、それだけでは企業のサービスあるいは社内システムとして、本質的な価値を持ちません。ここで、企業の保有するデータを活用することが重要になります。
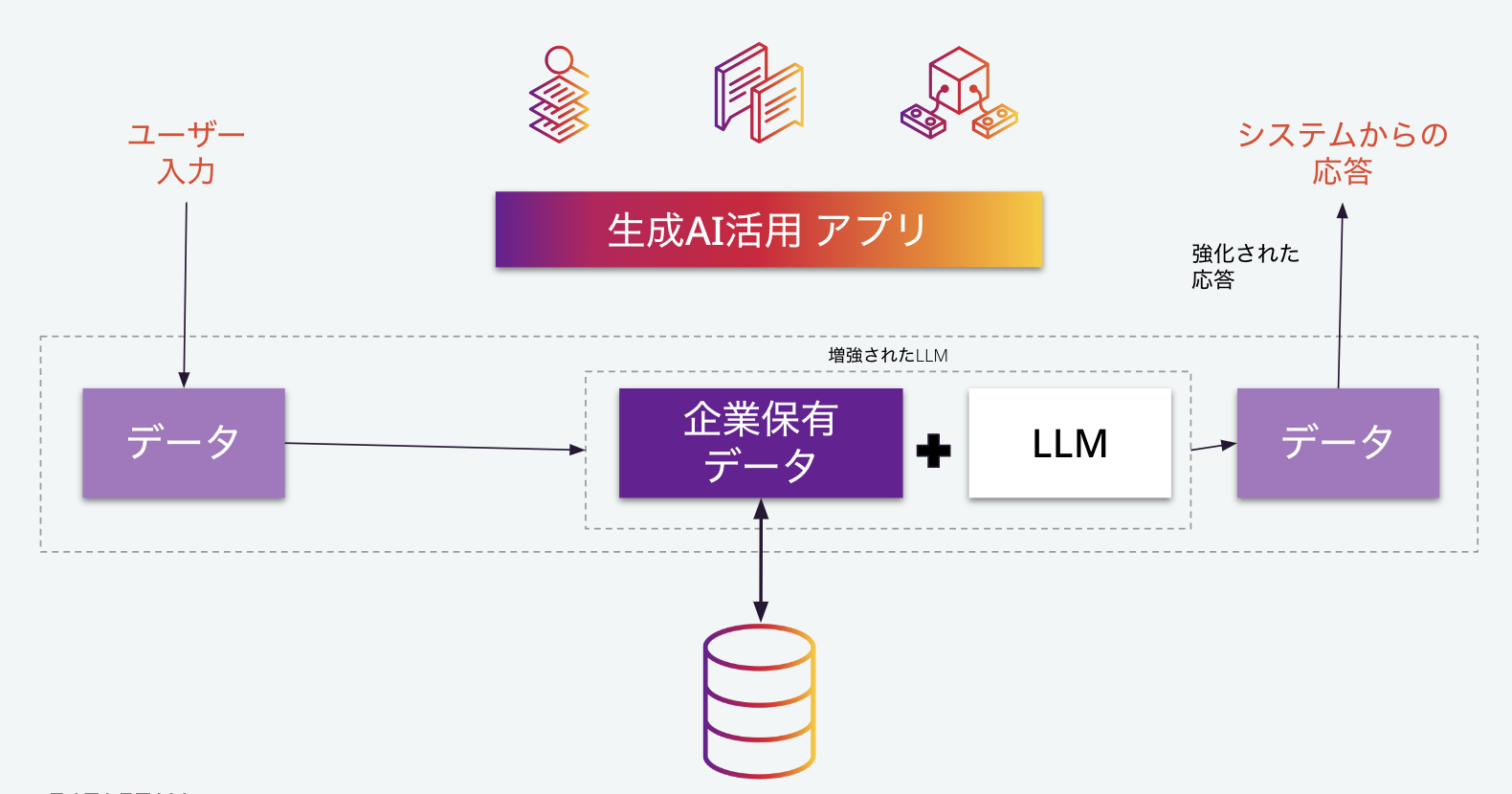
この図では、概念的に「企業保有データ+LLM=増強されたLLM」としていますが、この増強の方法としては、具体的には次で紹介するふた通りの方法があります。
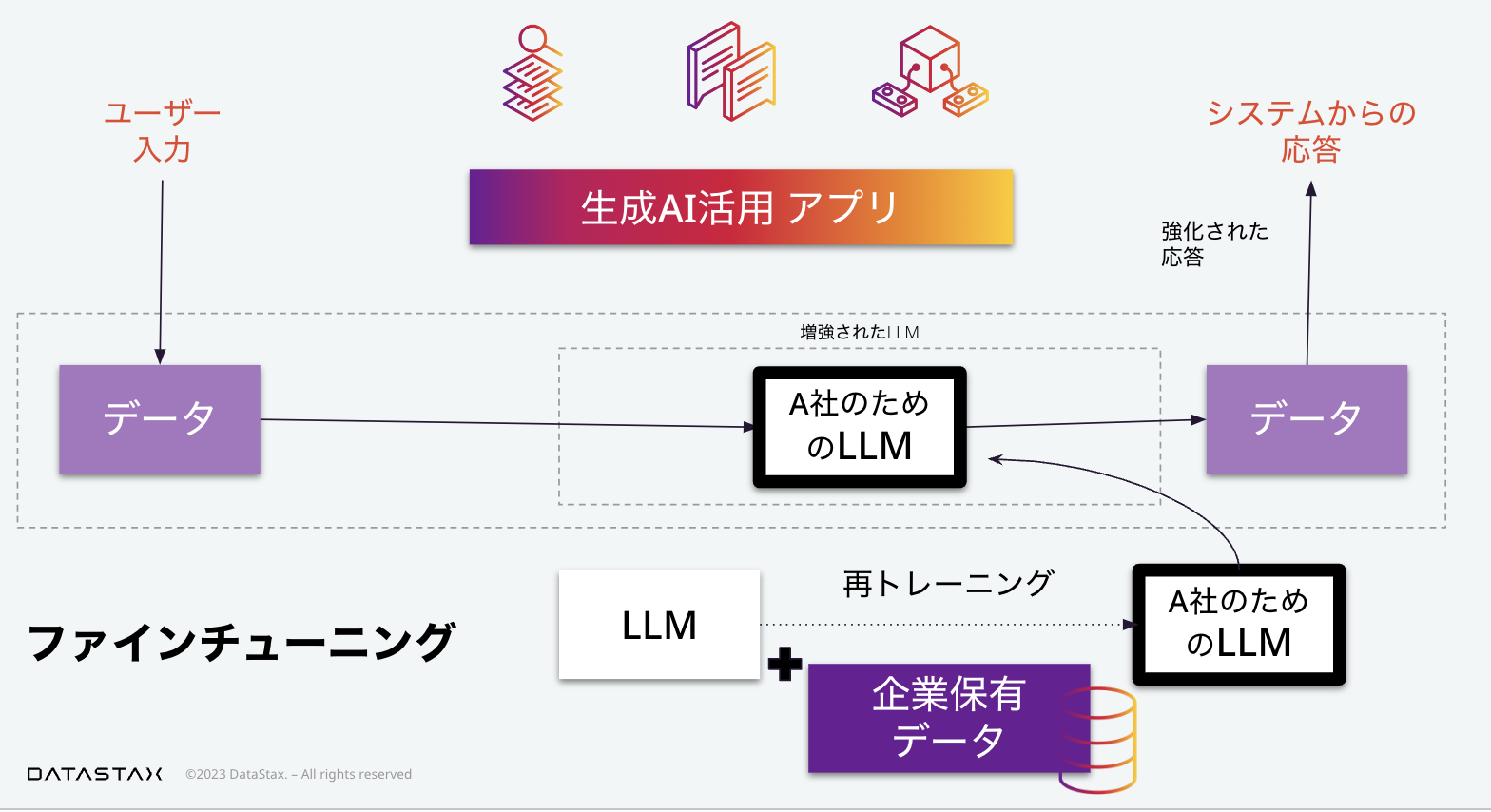
ファインチューニング
一つ目はファインチューニングです。ファインチューニングでは既存のLLMに対して企業保有データを使って再トレーニングすることによって、この企業、仮にA社としますが、A社のための専用のLLMを構築します。
プロンプトエンジニアリング

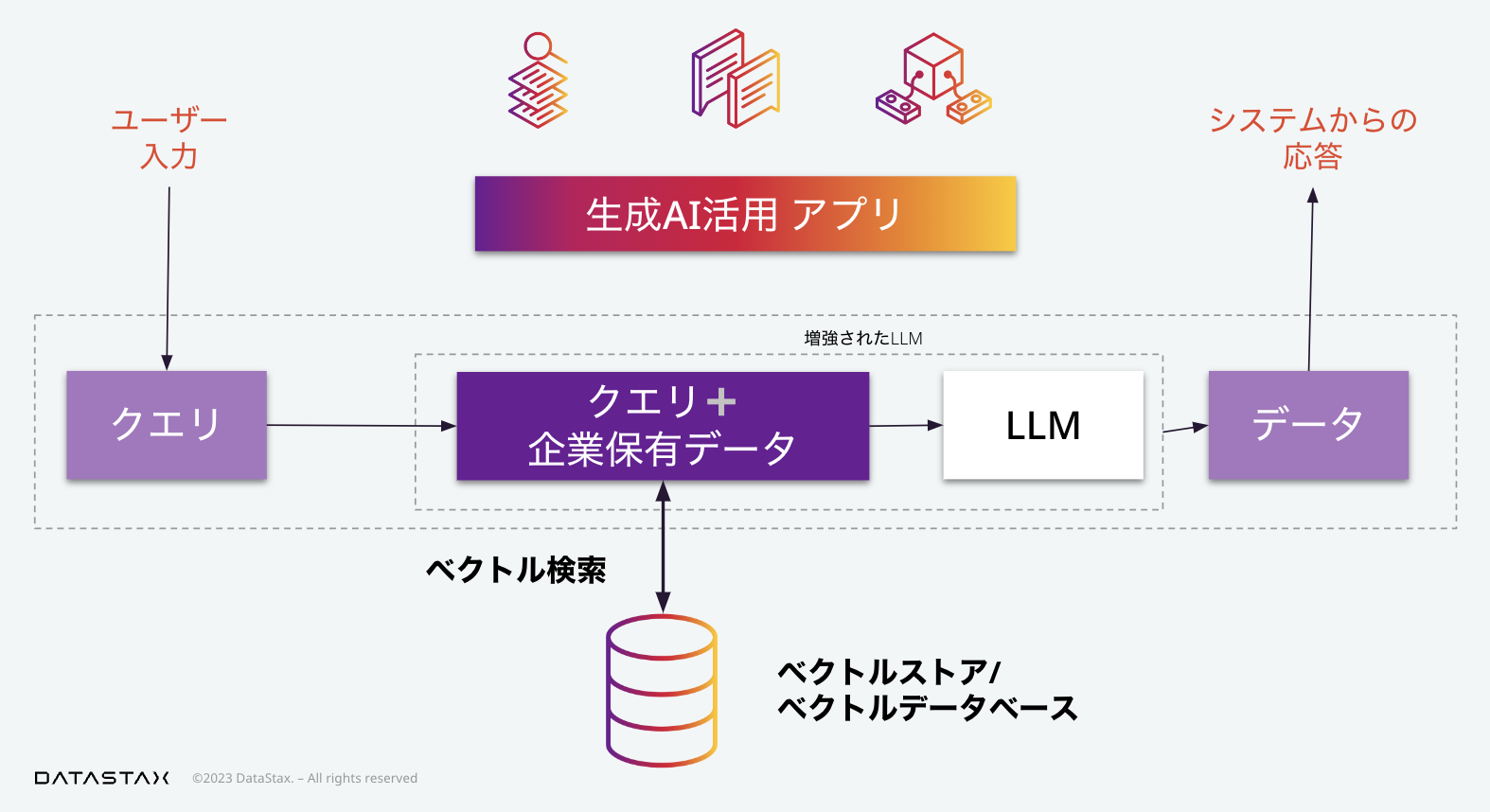
次にプロンプトエンジニアリングがあります。ここで「プロンプト」というのはLLMへの入力と理解していただければ結構です。このLLMへのプロンプトに、ユーザーからのリクエストをそのまま使うのではなく、(そのリクエストに関係のある)企業保有データを用いて加工、つまりエンジニアリングを行うことによって、システムからユーザーへの応答を、企業独自の価値のあるものにすることができます。
「プロンプトエンジニアリング」という用語が、技術者よりの目線を感じさせるのに対して、「コンテキストインジェスチョン」つまり、文脈の挿入、という用語が同じことを指すのに使われてもいます。
ここでLLMへのリクエストは、単純に言えば、(左下の吹き出しにあるように)「何々というユーザーのリクエストに答えよ。その際には、以下に与えるデータを活用せよ」といったものになります。
ここで、企業の保有する大量のデータから、ユーザーの質問に関連する情報を素早く見つけることが重要になります。ここでのデータの検索では、自然言語のような非構造化データを扱えることが求められます(ここで、「扱える」という表現には、単に操作ができるという以上の「自然言語らしい(つまり意味を介した上での)」扱い、という含意があります)。
ベクトル検索
ここで非構造化データの検索、という目的に使われるベクトル検索が重要となります。
そして、登場するのが、ベクトル検索の機能を提供するベクトルストア、またはベクトルデータベースです。現在、多くのベクトル検索エンジン、ベクトルデータベースが登場しています。
ベクトルデータベースは、ベクトルデータを保存していますが、そのベクトルデータをインデックス化することで、ベクトル検索を可能にしています。
ベクトル検索とは何か?
それでは、ベクトル検索とはどのようなものかについて説明します。
ベクトル検索について、Googleのあるブログ記事(「あらゆるデータの瞬時アクセスを実現する Google のベクトル検索技術」)では、あらゆるデータに対して瞬時にアクセスできる技術である、と表現されています。
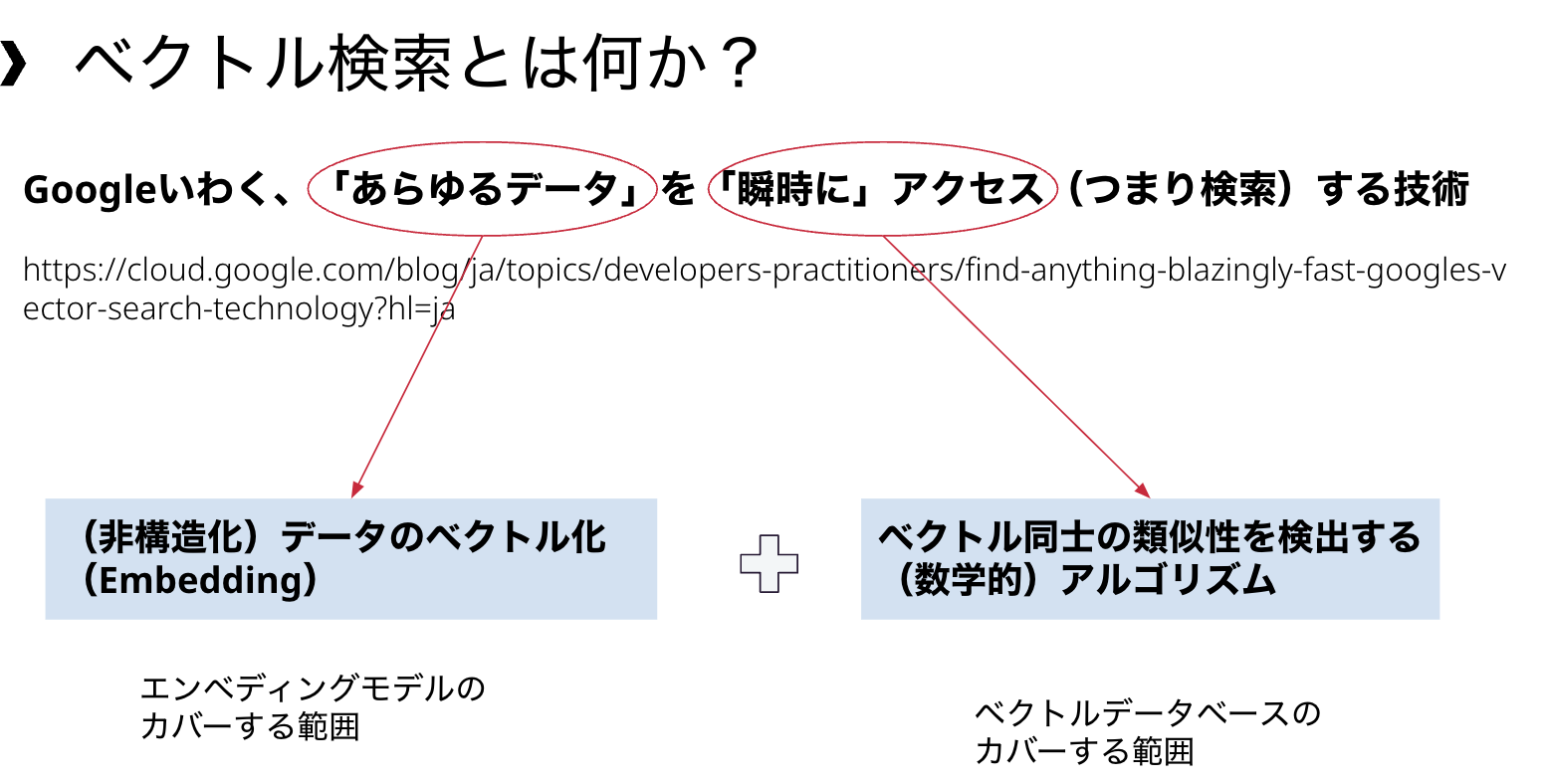
この表現は、あらゆるデータは、「数値のベクトル」に変換できる、という前提に基づいているといます。
それに加えて、文章であれ、画像であれ、データセットをベクトルに変換しさえすれば、数値計算によりデータ間の類似性が比較できるということ、これらがベクトル検索の二つの柱としてあります。
ベクトルデータベースがカバーするのは、この後者、つまりベクトル同士の類似性を検出するアルゴリズムです。このようなアルゴリズムにも、いくつかの種類があり、それぞれのベクトルデータベースにとってカバーする範囲が異なっています。
一方で、データのベクトル化についても、さまざまな手法が存在します。このベクトル化(エンベディング)の持つ意味については、以下の記事を参考にしていただくことができます。
ベクトルデータベースには、PineconeやMilvusのように、ベクトル検索を目的として開発されたものもあれば、PostgreSQLやMongoDBのように既存のデータベースにベクトル検索の機能を追加したものもあります。
DataStax Astraは、Apache Cassandraにベクトル検索の機能を追加することで、生成AI活用アプリケーションのためのベクトルデータベースとして利用可能になっています。
Cassandraのベクトル類似性検索エンジン: JVector
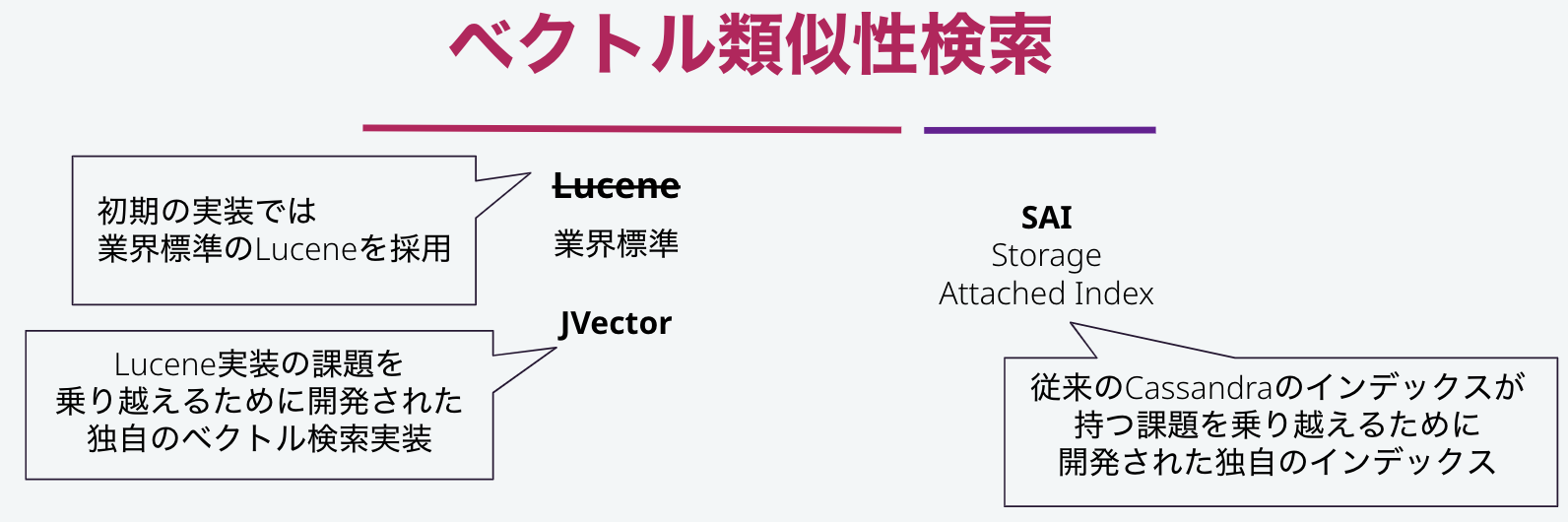
AstraDBに搭載されている,そしてCassandraの次期バージョンに搭載されるベクトル類似性検索エンジンについて、簡単に紹介します。
AstraDBの初期の実装では、業界標準で用いられているLuceneが採用されていました。しかし、このLuceneの実装に包含されている問題に気づいたDataStaxのエンジニアは、JVectorという独自のベクトルエンジンを開発し、Cassandraコミュニティに貢献しました。
また、ベクトル検索エンジンを構成するインデックス機能は、従来のCassandraのインデックスがもつ課題を乗り越えるために開発されたストレージ・アタッチド・インデックスが用いられています。
これらの開発により、AstraDBの検索エンジンは、業界標準のLuceneと比較して12倍以上のスループットを実現しています。
Jvector開発の経緯は、「ベクトル検索における 5 つの困難な問題と Cassandra がそれらを解決する方法」というブログで詳しく説明されていますので、ご興味のある方は是非ご覧ください。
ここでは、その記事の中から、一つの図を引用します。
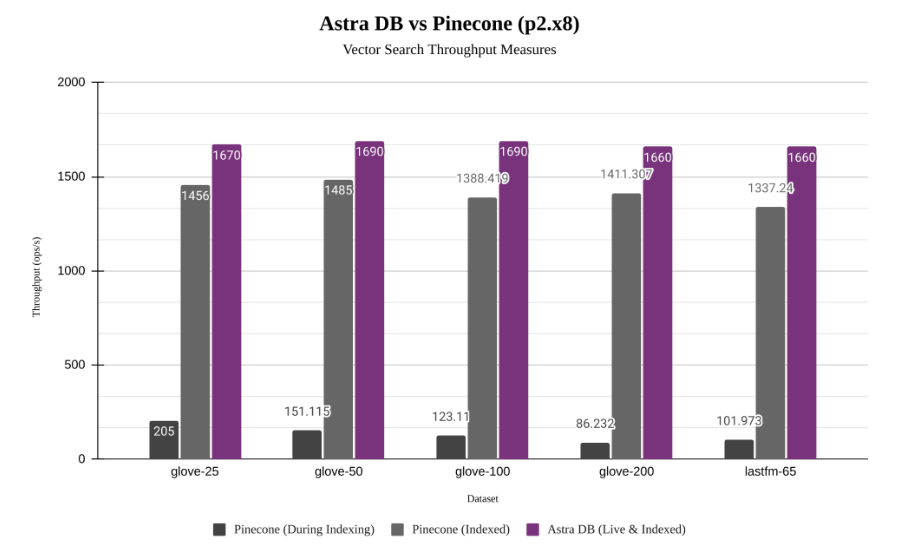
ベクトル検索専用のベクトルストアであるPineconeとAstraDBとのスループット性能比較を行ったものです。
紫がAstraDBであり、グレーがPineconeのものです。
グレーのバーは2本ありますが、濃いグレーのバーは、データベースの中でデータのインデックス化が行われている間の性能を示しています。
このように、専用のベクトルストアでは、データ変更に伴うインデックスの更新による性能影響が顕著に見られる場合があります。
ベクトル検索の機能は、データのインデックス化と、インデックスを利用した検索という2ステップがあります。
このような性能の違いは、これらのうちの前者、つまり運用中のデータ追加・更新というニーズに対する配慮の違いから生じている、ということがいえそうです。ユースケースによっては、それでも十分ということも考えられます。例えば、研究開発のような分野では、このような欠点は問題とならないかもしれません。一方で、ベクトル検索に限らす、一般的なデータベースにとって、データベースに対してのデータの追加・更新が行われている間に、データベース全体の検索性能に影響が生じることは受け入れ難いものです。
SQL+ベクトル検索:容易な操作
AstraDBで、Cassandraへの機能拡張としてベクトル検索が追加されたことによる利点は、他にもあります。

Cassandraは、標準SQLをベースとした、Cassandraクエリ・ランゲージ、CQLを備えています。
Cassandraにベクトル検索機能が導入されるに当たって、ユーザーはCQLの拡張構文として、ベクトル検索機能を利用することができるようになっています。
具体的な拡張として、新たなデータ型としてVECTOR型の導入があります。
この型に対して、インデックスを定義することで、ベクトル検索が可能になります。
そして、CQLクエリの拡張としてANN OFというベクトル検索のためのオペレーターが導入されています。このANNは、approximate nearest neighbor 、つまり、近似最近傍探索を意味します。
Apache Cassandraのベクトル検索機能について解説した、以下の記事があります。
類似度の把握
また、ベクトル類似度を数値で把握するための関数も提供されます。
SELECT
description,
similarity_cosine(item_vector, [0.1, 0.15, 0.3, 0.12, 0.05])
FROM vsearch.products
ORDER BY item_vector ANN OF [0.1, 0.15, 0.3, 0.12, 0.05] LIMIT 1;
ベクトル間の関係は、データ間の「一致」ではなく「類似」によって図られます。つまり、ベクトル検索クエリは、SQLのWHERE句で通常想定される、検索条件、というよりも、ORDER BY句で実現するような、並べ替えの機能を本質としています。そのため、データベースに格納されているデータが貧弱な場合、あるいはクエリのベクトルが、データベースの内容とおよそかけ離れたものである場合、ベクトルデータベースから類似データとして差し出されたものは、およそ関係がありそうにないデータである可能性もあります。ベクトル類似度を数値で把握し、一定の数値を下回るデータを切り捨てることによって、このようなミスマッチを回避することができます。
ベクトルデータベースの持つ3つの課題
最後にベクトルデータベースが持ち得る3つの課題について整理します。
-
検索インデックス更新
- データは更新される
- 専用ベクトルストアは運用中のインデックス更新に難あり
-
スケールアウト
- データは増える
- 性能要件は様々
-
データベースとしての汎用性
- ベクトル検索だけでは事足りない
- 二つのデータベース(汎用とベクトルストア)を運用するか?
- ベクトル検索機能を持った一つのデータベースを運用するのか?
- 開発への影響
- 既存の知識・経験を活かせる利点
- ベクトル検索だけでは事足りない
先に指摘したように、専用のベクトルストアは、運用中のインデックス更新に難がある場合があり、本格的なサービス運用には向かない場合があります。
また、インデックス化中の性能影響を度外視しても、データベースは、扱うデータの増加、そしてサービスとしての利用量の増加、といった変化に晒されます。CassandraのようなNoSQLと呼ばれるデータベースは、このようなスケールアウトという課題に答えるべく開発されました。
また、データベースとしての汎用性は、運用コストの面に直接関係するのはもちろん、開発コストの面にも影響を持ちます。
LangChain入門
それでは、ここからLangChainの入門に移ります。
この一つの記事で、LangChainの全ての機能を等しく語ることはできませんが、特に本番サービス開発での利用を想定した上で有益な情報となるように、これまでの流れを踏まえて説明していきたいと思います。
LLMフレームワーク:登場の背景と利点
生成AI活用の選択肢
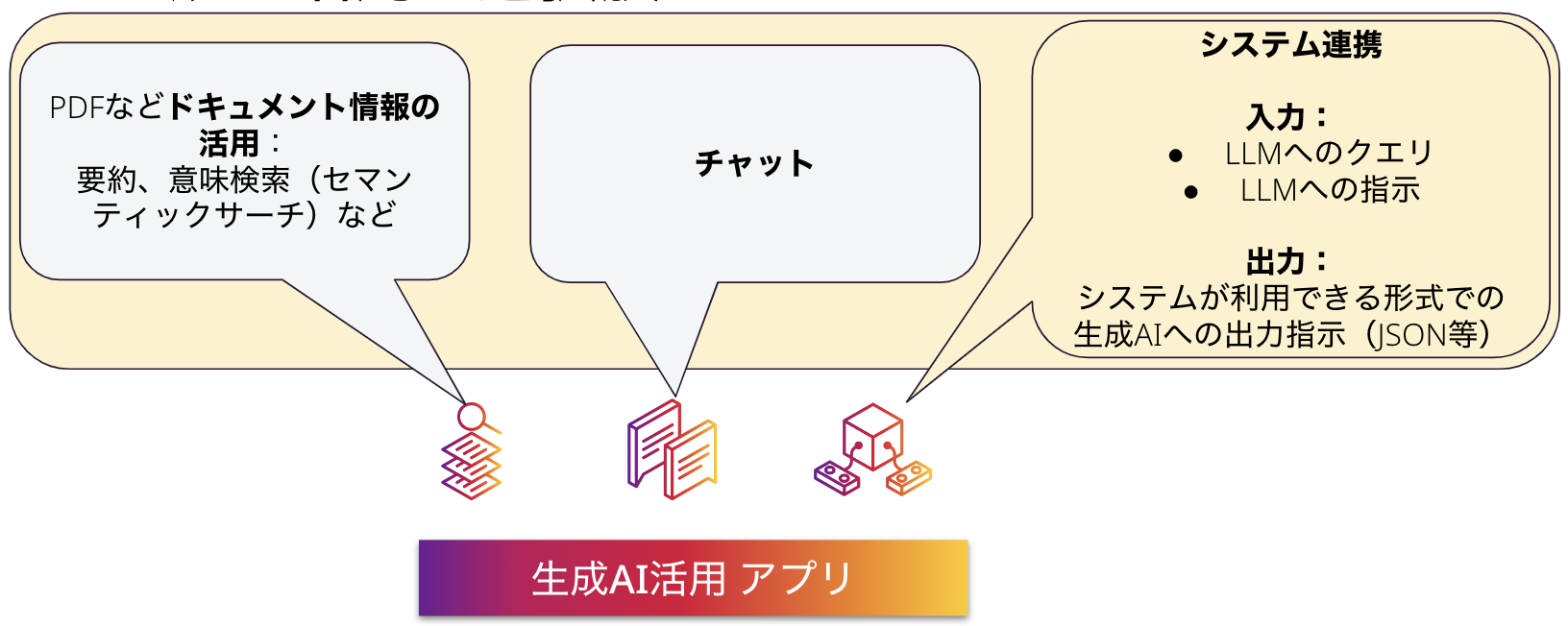
生成AIについては、自然言語を扱う他、画像生成という側面もありますが、これ以降では、特にビジネス上の重要性から、自然言語処理に注目して話を進めます。
自然言語の分野における生成AIが実現するものとして、自然言語による問い合わせの理解とそれに対する応答、という面があります。また、PDFなどのドキュメントのような非構造化データに対する、文章の意味や文脈を理解した上での操作、検索や要約の生成、という面もあります。これらは、ある意味で理解しやすく、LangChainでも、専用のコンポーネントが提供されています。一方で、ビジネスでの活用を考えると、生成AIのポテンシャルは、単にこうしたわかりやすいアプリケーションに止まるものではありません。
特にサービス化においては、チャットのようなユーザーと直接応答するサービスだけでなく、システムの一部として、LLMを活用し、さまざまな他の機能と組み合わせることによって、より価値を発揮します。
LLMを提供する各プロバイダーは、APIを公開しており、そのAPIを活用することで、このようなサービス化は容易に可能になっています。
例えば、ユーザーからのメールなどからの問い合わせに対して、人が確認するというプロセスを経ずに、システムが自動的にメールへの自動送信をすることによる効率化が考えられます。
あるいは、Eコマースにおけるキャンペーンのように、何らかのトリガーを発端として、そのトリガーのコンテキストを踏まえた文章を生成して、サイト上で、プッシュ通知を行ったりすることも考えられます。
LLMは、命令として、応答の出力形式を指示することができるため、JSONやCSVのようなシステムが処理可能な形式を指示することによって、システム連携が容易に可能になります。
実際にLLMを新しいサービスに利用している企業は、このようなシステム連携をうまく実現しているように見えます。一方で、私見ですが、LangChainのドキュメント自体、あるいはそれを元にした解説記事などを見ると、ドキュメントの処理や、チャットインターフェイスというような適用範囲の狭さを感じさせるきらいがあるように思われます。ここでは、できるだけそのような限定的な印象を払拭できるように、解説をしていきたいと思います。
アプリケーション/フレームワークの中心:エージェント
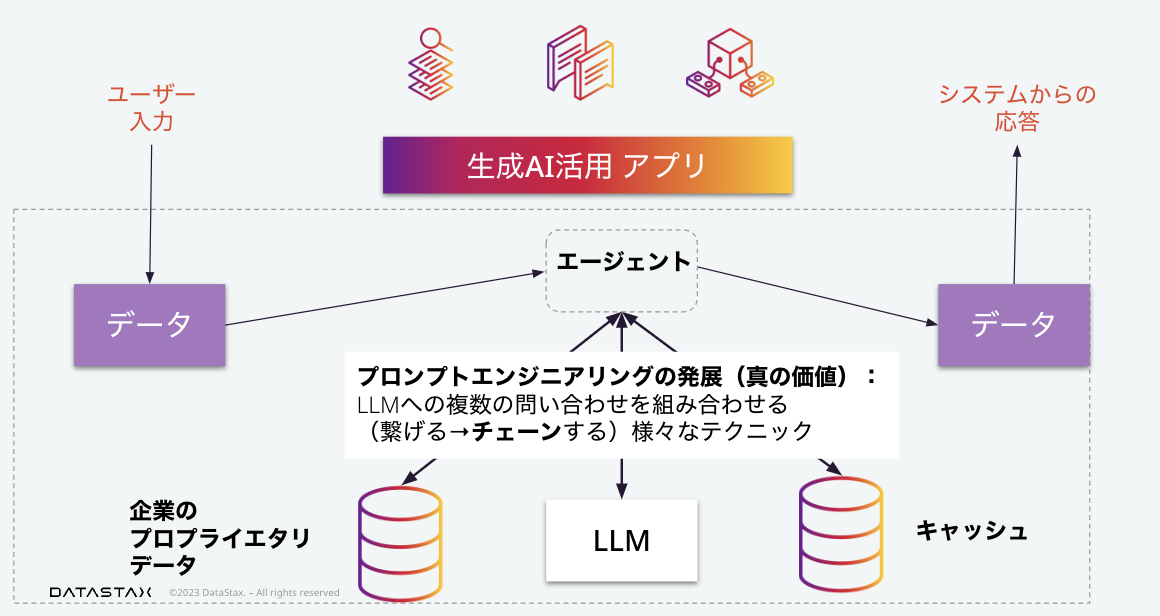
このようなフレームワークを利用した場合の、典型的なアプリケーションの構成として、エージェントと呼ばれるコンポーネントが、その名の通りユーザーの代理人として、さまざまな機能を仲介する役割を持つことになります。役割の一つとしては、プロンプトエンジニアリングの他に、各種キャッシュの操作があります。例えば、LLMの応答をキャッシュし、過去に行われたものと同じリクエストを受け付けた時には、キャッシュから応答を返す、というようなことが行われます。
さらに重要なことは、これらのLLMへの応答を、システムへの一つのリクエストに答える目的のために、複数回実行することができるということです。プロンプトエンジニアリングというテクノロジーの発展の中で、このようなLLMの活用について、さまざまな知見が共有されています。そして、それらの知見がフレームワークという形で利用可能になっています。
このようなフレームワークの代表格として、LangChainがあります。
LangChainを利用する利点
まず、LangChainを利用する利点を整理してみます。
生成AIアプリケーションの典型的な構造の表現
初めに、以下のような、生成AIアプリケーションの典型的な構造の表現があります。
- モデル
- データ
- データソース(典型的なデータソースをベクトルストアにロードする機能)
- ベクトルストア
- エージェント
プロンプトエンジニアリングの様々なテクニックの実装
そして、プロンプトエンジニアリングの成果の様々なテクニックの実装があります。
- ReAct
- Chain Of Thought
- FLARE、等
生成AIアプリケーション構成要素の個別実装
これらに加えて、各種LLMモデルや、ベクトルストアのように生成AIアプリケーションを構成する要素のさまざまな個別の実装が提供されていることがあります。
- LLM:OpenAI等
- ベクトルストア:PineCone, Cassandra等
- データローダー、等
ベクトルストアにデータを登録する際に必要となるデータローダー機能についても、ここに含めて考えることができます。
CassIO
LangChainを利用する利点におけるこの最後の要素について、Cassandraコミュニティでは、CassIOプロジェクトが立ち上げられました。
CassIO の目的は、各種生成AIフレームワークとの組み合わせにおいて、フレームワークがCassandra データベースにアクセスする詳細を抽象化し、Cassandra をシームレスに統合することです。
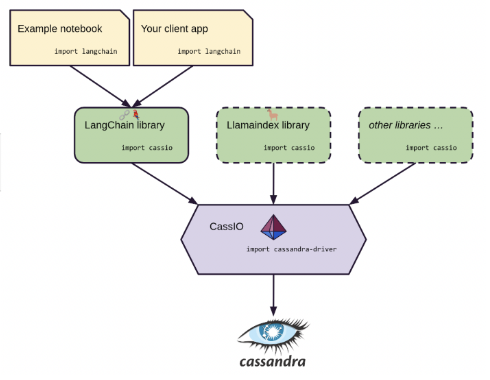
開発の観点からCassIOをみた場合、Cassandraクラスはlangchain.vectorstoreパッケージに包含されています(実装は、import cassioによって提供されます)。

このCassandraクラスは、langchain.vectorstoraパッケージに含まれる他のベクトルデータベースと共通したデザインとなっているため、開発者は、Cassandra固有の技術を必ずしも理解しなくても、Cassandraをベクトルストアとして用いることができる工夫がされています。
LangChain入門:データソースとベクトルストア
ここからはアプリケーション開発のより具体的な側面について見ていきます。
生成AIにおける典型的なデータソースとして、ドキュメントとテキストがあり、それに応じたコンポーネントが用意されています。これらのコンポーネントは、ベクトルストアの構築のために、データソースからデータを読み込み、必要な変換を行った上で、ベクトルストアへロードする、という一連の操作をカバーしています。
ベクトルストアへのデータのロードを担う「ドキュメントローダー」には、以下で確認できるさまざまなものが存在します。
これらは、フレームワークのユーティリティ的な側面であり、ここでは紹介にとどめます。
ベクトルストア:組み込みレベルのベクトルストア
ベクトルストア自体に目を向けてみると、LangChainのドキュメントでまず目にすることになるのが、Chromaというベクトルストアです。
Chramaは、いわば組み込みレベルのデータベースであり、Chromaを使えば、ベクトルデータベースについてデータベースをインストールして、接続ポイントやユーザーを利用したりマネージドサービスに登録して、APIのキーを利用したりしなくてもすみますが、少し考えてわかるように、本格的なアプリケーションでの利用としては、物足りません。
ただし、フレームワークにおいて、ベクトルストアへの操作は、後で紹介するRetrieverというクラスのレベルで抽象化されているため、LangChainの学習をスタートするに当たって、このChromaを使って、手っ取り早く始めることも可能でしょう。
ベクトルデータベース(DataStax Astra)の利用
ここでは、より本格的なアプリケーションでの利用を想定して、AstraDBを利用するケースについて紹介します。
cassandraパッケージを利用して、Cassandraデータベースへのセッションを初期化し、このセッションを引数として、langChain.vectorestoreパッケージのCassandraクラスを初期化することによって、AstraDBをLangChainフレームワーク上のベクトルストアとして利用することができます。
このクラスの初期化によって、AstraDB上に自動的にテーブルの定義とインデックスの定義が行われます。
このクラスによって、自動生成されたテーブルは、当然ですが、名前以外は、共通のモデルになります。

基本的には、ベクトルデータとベクトル化される前のデータによって、レコードが構成されますが、メタデータという項目名と値からなるマップ形式のカラムに、ユースケースに応じた値を格納することができます。
カスタムRetrieverの作成
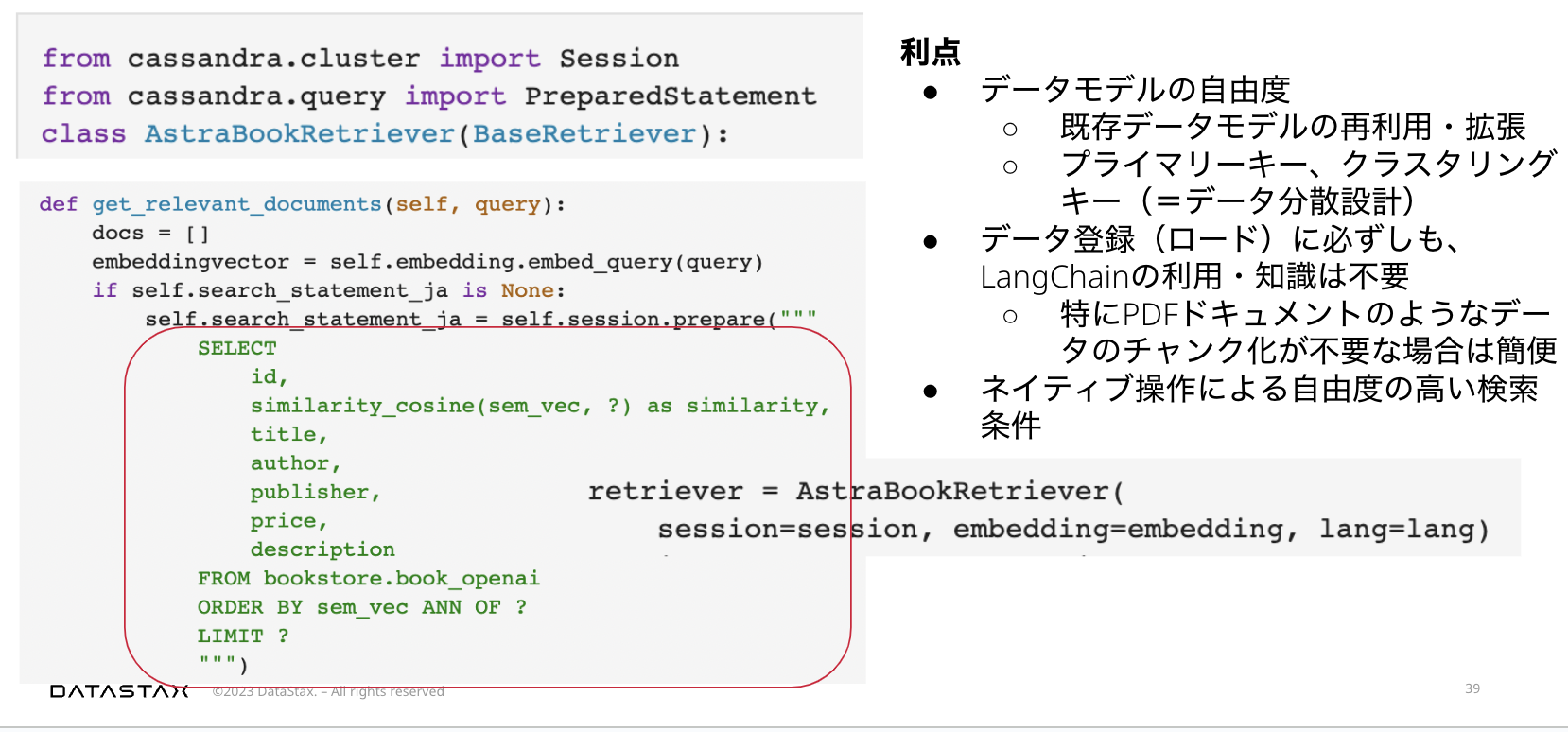
Cassandraやそのほかのベクトル検索機能に対応したデータベースをLangChainのなかで利用する別の方法として、 BaseRetrieverを拡張して独自のRetrieverクラスを定義することもできます。
この場合、そのデータベースが本来持っているポテンシャルを最大限活用することができます。
例えば、組み込みレベルのデータベースでは、考えるべくもない、分散環境における、データ配置の最適化など、ユースケースとデータモデルに即した設計と運用が可能になります。
また、LangChainのベクトルストアクラスを利用する場合には、データベース固有の知識がなくても、メタデータによるフィルタリングや、類似度スコアの取得などの定型的な処理を実行できるのに対して、Retrieverを実装した場合には、データベースに対するクエリを直接記述することになります。
データ層への操作をできるだけ、意識したくない場合には、クラスの利用が理に適っていますが、データベースを使ったシステムの開発経験を備えた開発者にとっては、カスタムRetrieverクラスを開発することで、設計・開発の自由度を最大限活用することができます。
LangChain入門:エージェント
次に生成AIアプリケーションの中心となるエージェントについて解説します。
エージェントの詳細に入る前に、LangChainには、エージェントと似通った目的をもつコンポーネントとしてチェーンがあることに触れておきます。
これはLangChainのドキュメントからの引用ですが、チェーンでは、一連のアクションが (コード内に) ハードコーディングされているのに対して、エージェントでは、言語モデルが推論エンジンとして使用され、どのアクションをどの順序で実行するかを決定します。
整理すると、LangChainでは、LLMを利用するのに、3つの方法があることになります。
- まずは、単純に、モデルを直接実行することができます。
- 次にチェーンを使った場合、ハードコードした一連のアクションを実行可能と説明しましたが、チェーンを使わずにハードコードで順次モデルを実行した場合と比べた利点として、それらのアクションを実行する際のバッチ処理のさまざまな手法を活用できることがあります。
- そしてエージェントを利用した場合には、言語モデルを推論エンジンとして利用することができるという、非常に多くの利点があります。
それでは、ここからはエージェントについてみていきます。
エージェントの構築と利用
ここでは、エージェントとRetrieverとの関係に焦点を絞って解説します。
LangChainのドキュメントでも別々に取り上げられているように、エージェントを構築するにはLangChainの中でもいくつかの方法があります。
ここでは、それらの関係を解きほぐすことによって、今後の学習へ応用するための情報を提供したいと思います。
まず、LangChainの「Agent with retrieval tool」というセクションの解説は、コンストラクターを使ったエージェントの構築というサブセクションから始まります。
個人的に、誤解を招く表現だと感じますが、ここでいうコンストラクターは、クラスの初期化を担う、コンストラクターメソッドではなく、単なる関数、ファンクションに対して使われている、機能の表現です。
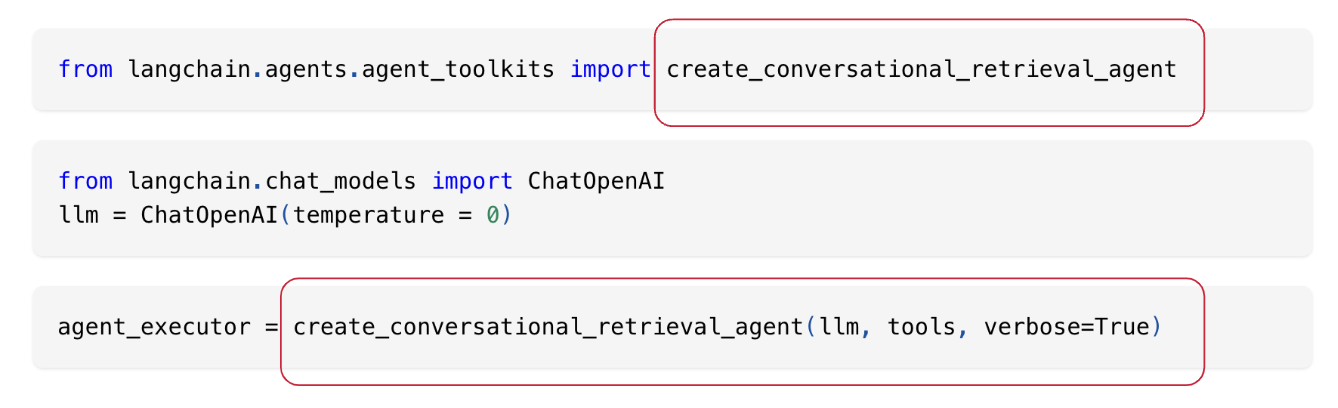
create_conversational_retrieval_agentという長い名前の関数に対して、LLMとツールズを引数に渡すことでエージェントエグゼキューターを構築しています。
また、この関数が含まれるパッケージは、langchain.agents.agent_toolkitsであることも覚えておいてください。
ユーティリティメソッドによるエージェントの作成
この関数の内部(定義)をみてみると、さまざまな付随する処理を実行した上で、OpenAIFunctionsAgentというクラスのインスタンスを作成しています。
つまり、これは、汎用的な関数として設計されているわけではなく、特定の最もメジャーなLLMプロバイダーの利用を前提とした関数になっています。これは、この関数が、ツールキットという名前のパッケージに含まれていることを考えれば、おかしなことではありません。
このように、この関数は、何らかの独自の処理の実装というよりも、LangChainフレームワークを利用する一つのサンプルを示す、ユーティリティー的なものだと考えることができます。
Agentクラスによるエージェント作成
重要なのは、この場合、OpenAI用に実装されたエージェントをそのまま実行するのではなく、AgentExecutorという汎用クラスを作成するというステップです。
ここまでで、さまざまなモデルに対応してエージェントクラスを選択し、初期化のために必要な要素を与え、エージェントを構築し、さらに、このエージェントから、エージェントエグゼキューターを構築する、という構成が理解できたかと思います。
そして、これらの準備において重要な要素の一つとして、LLMやプロンプトといったコンポーネントに加えて、ツールズという要素があります。
エージェントのツールとしてのRetriever
ベクターストアに対する操作の抽象化として説明したRetrieverは、いわばこのツールズの一つとして位置付けられます。
具体的には、Retrieverから、エージェントのツールとして利用できるように、RetrieverToolという形式に変換した上で利用します。
この変換には、エージェントがこのツールをどのように使うことができるかという説明が含まれます。
LangChainのエージェントは、拡張可能な設計がされており、さまざまなプロンプトエンジニアリングの成果を踏まえた、さまざまな拡張クラスの実装も提供されています。
このツールズという要素は、このような抽象化のレベル、LLMを利用する際のさまざまな付随する処理、を吸収するものとなっています。
おわりに
本稿は以上で終わります。
今後の進んだ話題としては、プロンプトエンジニアリングの発展とLangChainにおけるその実装を具体的にみていくのは、大変興味深い取り組みだと思われます。
また、今回は、メモリーキャッシュという機能について触れることができませんでしたが、こちらも別途取り上げるに値するテーマだと考えます。
これらのような、LangChainの中で扱えなかった部分や、LangChain以外の生成AI活用アプリケーションを構築するための、別のフレームワークなどについても、今後、別の機会で取り上げることができればと思っています。