はじめに
生成AIの登場により、ベクターデータベースが注目を集めています。
「ベクターデータベースといえばコレ」というような、ある種のデファクトスタンダードは、何だろう?どうなっていくのだろう?という関心から、この記事を整理しています。
まず、ベクトルデータベースの比較について下記記事を参考にさせていただきました。
上記記事(2023年8月4日発表)から以下抜粋。
| DB 名 | スター数 | 開発言語 | ライセンス | 主要開発者の所属 |
|---|---|---|---|---|
| milvus | 20 k | Go | Apache-2.0 | zilliz (中国企業) |
| qdrant | 11.1k | Rust | Apache-2.0 | qdrant (ドイツ企業) |
| weaviate | 6.4k | Go | 3条項BSD | weaviate (オランダ企業) |
| cozodb | 2.5k | Rust | MPL-2.0 | ケンブリッジ大学 (英国大学) |
| volox | 2.5k | C++ | Apache-2.0 | Meta (米国企業) |
概要
Milvusについて、下記で公開されている概要を、翻案して記します。
Milvusとは何か?
Milvus は、ディープ ニューラル ネットワークやその他の機械学習 (ML) モデルによって生成された大規模な埋め込みベクトルを保存、インデックス付け、管理するという 1 つの目標を掲げて 2019 年に作成されました。
Milvus は、入力ベクトルに対するクエリを処理するために特別に設計されたデータベースとして、1 兆規模のベクトルにインデックスを付けることができます。Milvus は、事前定義されたパターンに従って構造化データを主に扱う既存のリレーショナル データベースとは異なり、非構造化データから変換された埋め込みベクトルを処理するために設計されています。
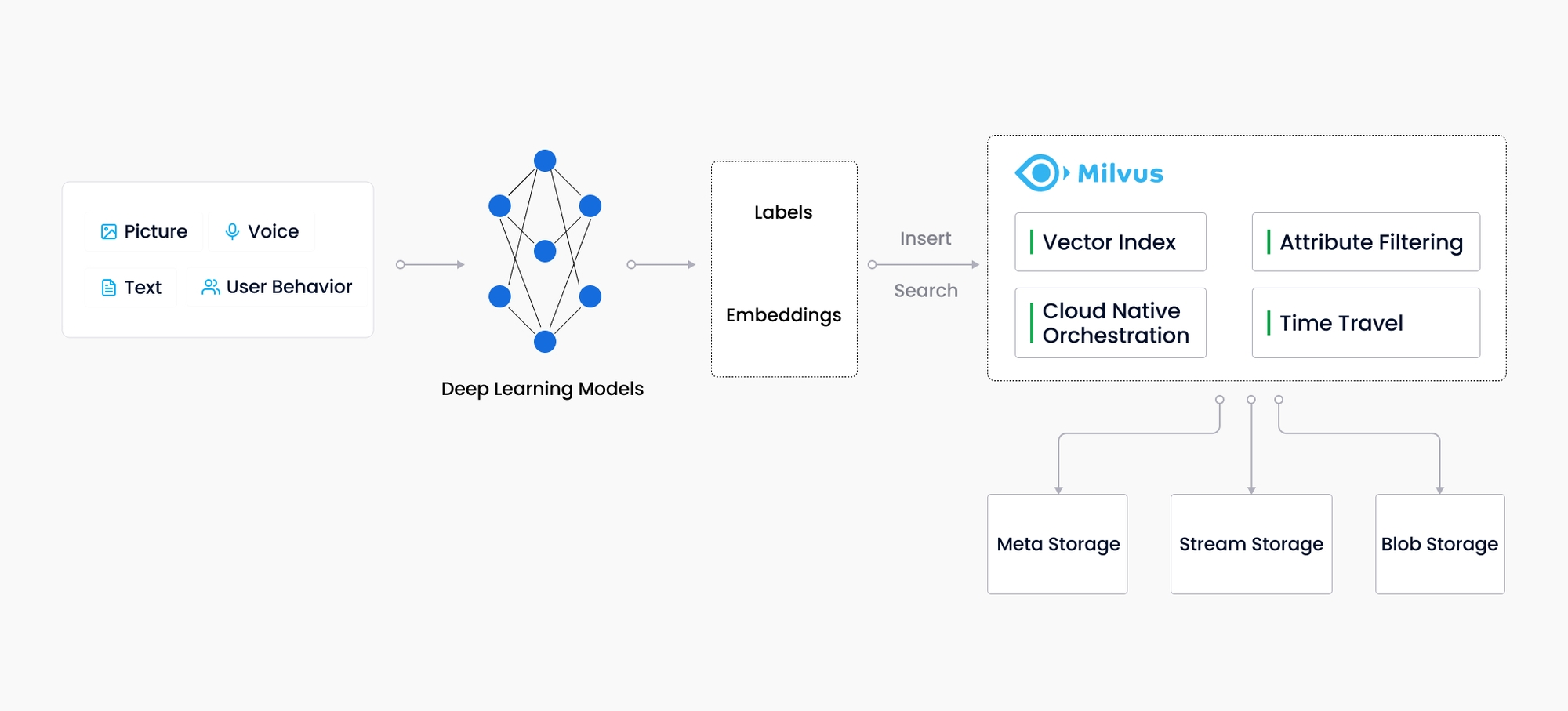
埋め込みベクトルと非構造化データの重要性
インターネットが成長し進化するにつれて、電子メール、論文、IoT センサー データ、Facebook の写真、タンパク質構造などを含む非構造化データがますます一般的になりました。コンピューターが非構造化データを理解して処理できるようにするために、非構造化データは埋め込み技術を使用してベクトルに変換されます。Milvus はこれらのベクトルを保存し、インデックスを作成します。Milvus は、類似距離を計算することで 2 つのベクトル間の相関を分析できます。2 つの埋め込みベクトルが非常に似ている場合は、変換前の元のデータソースも似ていることを意味します。
主要な概念
ベクトル データベースと類似性検索の世界に初めて触れる場合は、以下のキー概念の理解が重要になります。
非構造化データ
画像、ビデオ、音声、自然言語などの非構造化データは、事前に定義されたモデルや編成方法に従わない情報です。このデータ タイプは世界のデータの約 80% を占めており、さまざまな人工知能 (AI) および機械学習 (ML) モデルを使用してベクトルに変換できます。
ベクトルの埋め込み(エンベディング)
埋め込みベクトルは、電子メール、IoT センサー データ、Instagram の写真、タンパク質構造などの非構造化データの特徴を抽象化したものです。数学的に言えば、埋め込みベクトルは浮動小数点数またはバイナリの配列です。最新の埋め込み技術を使用して、非構造化データを埋め込みベクトルに変換します。
ベクトル類似性検索
ベクトル類似性検索は、ベクトルをデータベースと比較して、クエリ ベクトルに最も類似したベクトルを見つけるプロセスです。近似最近傍 (ANN) 検索アルゴリズムを使用して、検索プロセスを高速化します。2 つの埋め込みベクトルが非常に似ている場合は、元のデータ ソースも似ていることを意味します。
なぜMilvusなのか?
- 大規模なデータセットに対してベクトル検索を実行する場合の高いパフォーマンス。
- 多言語サポートとツールチェーンを提供する開発者優先のコミュニティ。
- クラウドの拡張性と、障害が発生した場合でも高い信頼性を実現。
- スカラー フィルタリングとベクトル類似性検索を組み合わせることにより、ハイブリッド検索を実現。
どのようなインデックスとメトリクスがサポートされていますか?
インデックスはデータの編成単位です。挿入されたエンティティを検索またはクエリする前に、インデックス タイプと類似性メトリックを宣言する必要があります。インデックス タイプを指定しない場合、Milvus はデフォルトでブルートフォース検索を実行します。
(Zillizでは、インデックスタイプの選択は自動化できるようです)
インデックスの種類
Milvus でサポートされているベクトル インデックス タイプのほとんどは、次のような近似最近傍検索 (ANNS) を使用します。
-
FLAT :
FLATは、100 万規模の小規模なデータセットに対して完全に正確で正確な検索結果を求めるシナリオに最適です。 -
IVF_FLAT :
IVF_FLATは量子化ベースのインデックスであり、精度とクエリ速度の理想的なバランスを求めるシナリオに最適です。GPU バージョンのGPU_IVF_FLATもあります。 -
IVF_SQ8 :
IVF_SQ8は量子化ベースのインデックスであり、ディスク、CPU、GPU のリソースが非常に限られているため、これらのメモリ消費量を大幅に削減するシナリオに最適です。 -
IVF_PQ :
IVF_PQは量子化ベースのインデックスであり、精度を犠牲にしてでも高いクエリ速度を求めるシナリオに最適です。GPU バージョンGPU_IVF_PQもあります。 -
HNSW :
HNSWはグラフベースのインデックスであり、検索効率に対する要求が高いシナリオに最適です。
類似性メトリクス
Milvus では、類似性メトリックを使用してベクトル間の類似性を測定します。適切な距離メトリックを選択すると、分類とクラスタリングのパフォーマンスが大幅に向上します。入力データ形式に応じて、最適なパフォーマンスを得るために特定の類似性メトリックが選択されます。
浮動小数点埋め込みに広く使用されているメトリクスは次のとおりです。
- ユークリッド距離 (L2) : このメトリクスは通常、**コンピューター ビジョン (CV) **の分野で使用されます。
- 内積 (IP) : このメトリクスは通常、**自然言語処理 (NLP) **の分野で使用されます。
バイナリ埋め込みに広く使用されているメトリクスには次のものがあります。
- ハミング: このメトリクスは通常、自然言語処理 (NLP) の分野で使用されます。
- Jaccard : この指標は分子類似性検索の分野で一般的に使用されます。
アプリケーション
Milvus を使用すると、類似性検索をアプリケーションに簡単に追加できます。Milvus のアプリケーション例は次のとおりです。
- 画像類似検索: 画像を検索可能にし、大規模なデータベースから最も類似した画像を瞬時に返します。
- 動画類似性検索: キー フレームをベクトルに変換し、その結果を Milvus にフィードすることで、数十億のビデオをほぼリアルタイムで検索し、推奨できます。
- オーディオ類似性検索: 音声、音楽、効果音、表面の類似音など、大量のオーディオ データを迅速にクエリします。
- レコメンダーシステム:ユーザーの行動やニーズに基づいて情報や商品を推奨します。
- 質問応答システム: ユーザーの質問に自動的に回答する対話型デジタル QA チャットボット。
- DNA 配列分類: 類似した DNA 配列を比較することにより、遺伝子の分類をミリ秒単位で正確に分類します。
- テキスト検索エンジン: テキストのデータベースとキーワードを比較することで、ユーザーが探している情報を見つけられるようにします。
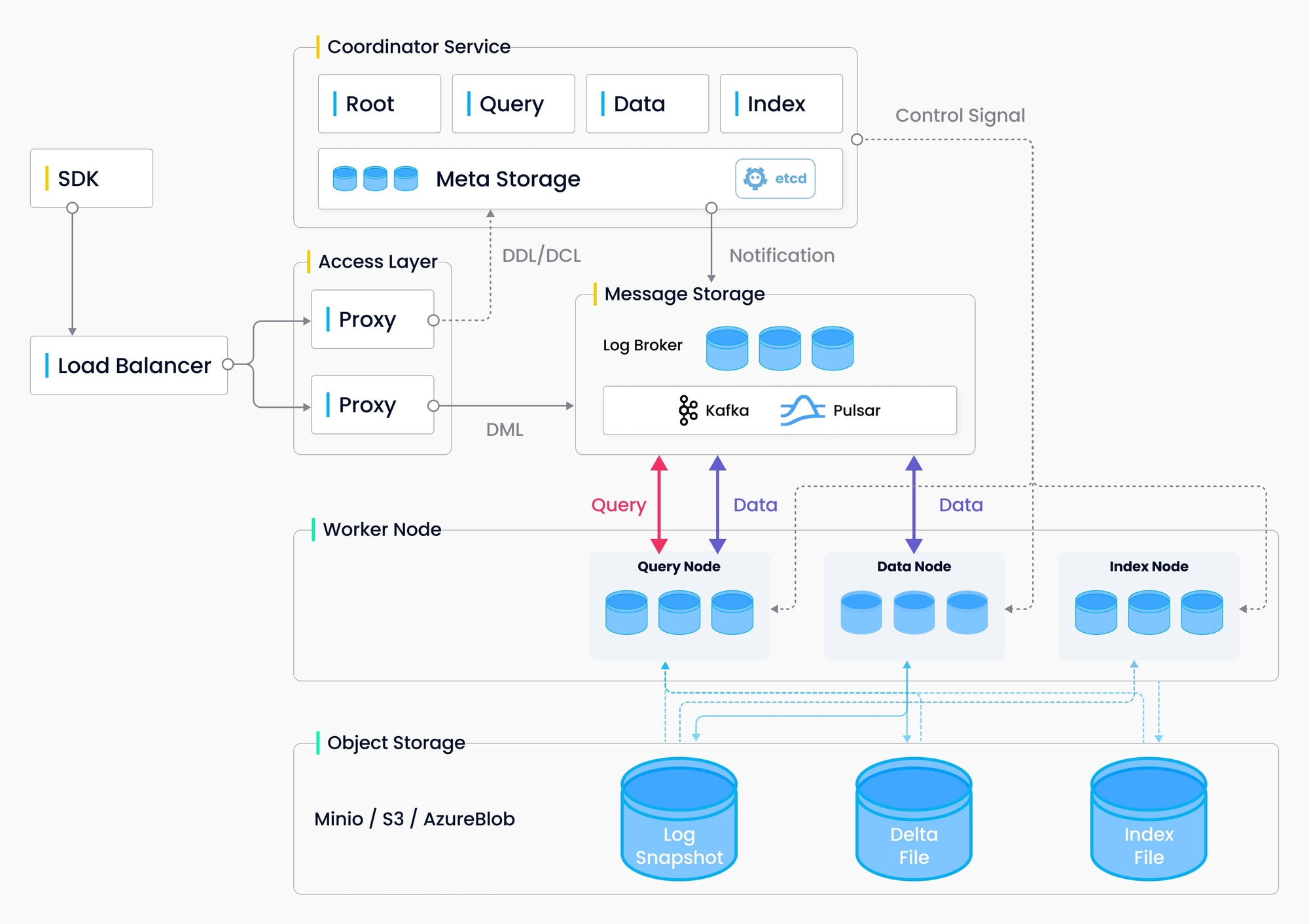
Milvusのシステム構成
クラウドネイティブのベクター データベースとして、Milvus は設計によりストレージとコンピューティングを分離します。弾力性と柔軟性を高めるために、Milvus のすべてのコンポーネントはステートレスです。
システムは 4 つのレベルに分かれています。
- アクセス層: アクセス層はステートレス プロキシのグループで構成され、システムのフロント層およびユーザーに対するエンドポイントとして機能します。
- コーディネーター サービス: コーディネーター サービスは、ワーカー ノードにタスクを割り当て、システムの頭脳として機能します。
- ワーカー ノード: ワーカー ノードは手足として機能し、コーディネーター サービスからの指示に従い、ユーザーがトリガーした DML/DDL コマンドを実行するダム実行プログラムです。
- ストレージ: ストレージはシステムの骨子であり、データの永続性を担当します。メタストレージ、ログブローカー、オブジェクトストレージで構成されます。
Milvusのアーキテクチャ
開発者ツール
Milvus は、DevOps を促進するための豊富な API とツールによってサポートされています。
APIアクセス
Milvus には、アプリケーション コードからプログラムでデータを挿入、削除、クエリするために使用できる、Milvus API 上にラップされたクライアント ライブラリがあります。
- PyMilvus
- Node.js SDK
- Go SDK
- Java SDK
Milvus エコシステム ツール
Milvus エコシステムは、次のような便利なツールを提供します。
- Milvus CLI
- Attu: Milvus のグラフィカル管理システム
- Milvus DM (Milvus Data Migration): Milvus でデータをインポートおよびエクスポートするために特別に設計されたオープンソース ツールです
- Milvus サイジング ツール: さまざまなインデックス タイプを持つ指定された数のベクトルに必要な生のファイル サイズ、メモリ サイズ、および安定したディスク サイズを見積もるのに役立ちます。
参考情報
Dockerによるスタンドアローンインストール
Appendix.
上記のチュートリアルや記事を参考に、Milvus環境としては、マネージドサービスのZillizを使って、LangChainでMilvusを動かしてみた記録(Collaboratory用Jupyterノートブック)。