はじめに
この記事では、Couchbase、Kafka、Spark、HBaseを利用したシステム連携について解説します。
連携のイメージは、以下のようなものです。
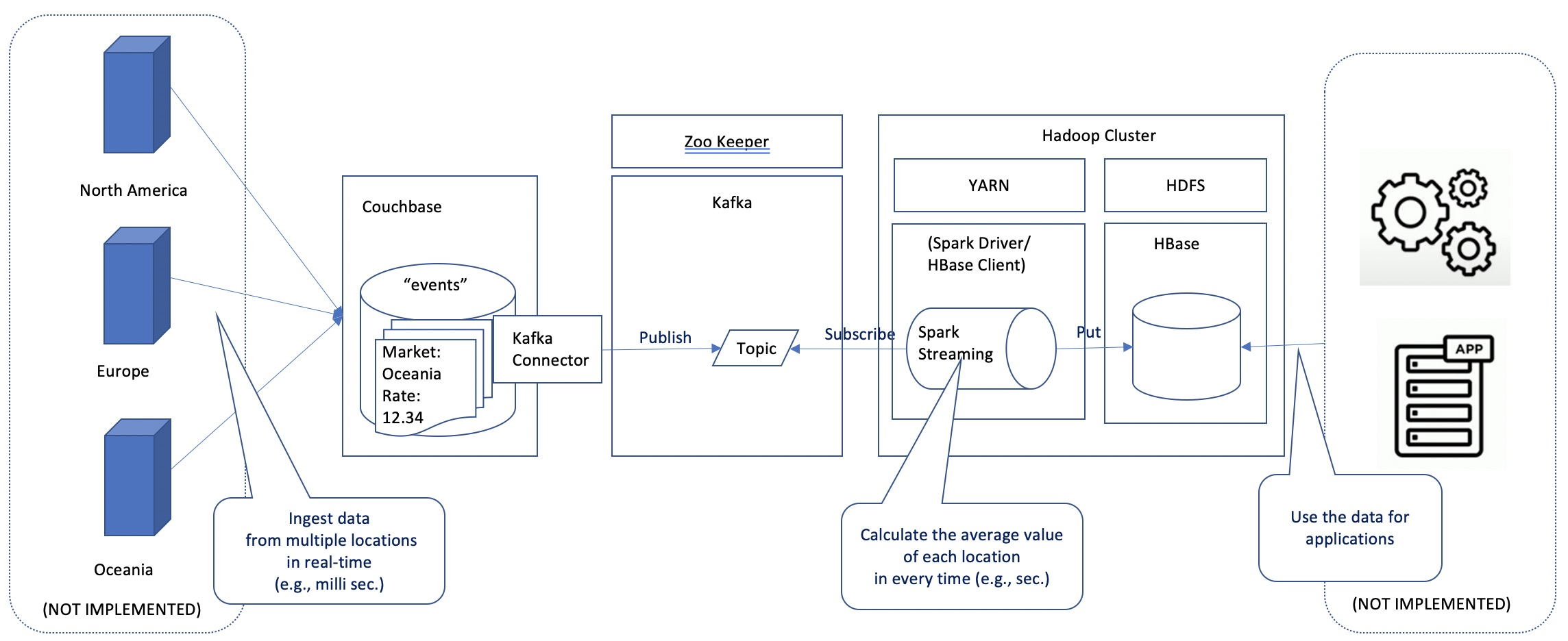
本記事の目的
本記事の目的は、以下の二点です。
- Couchbase Kafkaコネクター紹介
- Couchbase + Kafka + Spark + HBase 連携の検証記録(情報共有)
技術要素説明
- Couchbase Server
- NoSQLドキュメント指向(JSONネイティブ)データベース。シェアードナッシング型の分散システムであり、メモリファーストアーキテクチャーにより、(Redisや、Oracle Coherencenの様なメモリレイヤを別途フロントに持つ必要なく)シングルプラットフォームで、ミリ秒以下の書込・読込性能を実現できる特徴を持つ
- Kafka
- 分散イベントストリーミング(メッセージキュー)プラットフォーム。記事の最後に触れるConfluentは、Kafkaの商用パッケージを提供している。
- Apache Spark (Streaming)
- 分散コンピューティングフレームワーク。ここで扱うSpark Streamingは、Spark APIのストリーミング処理のための拡張
- Apache HBase
- 列指向の分散データベース
ここでは、以下の2つの独立したテーマとして説明していきます。
- Couchbase + Kafka 連携
- Kafka + Spark Streaming + HBase 連携
Couchbase + Kafka 連携
Couchbase Connectorについて
Couchbaseは、外部システムと連携するためのConnectorを提供しています。Couchbase Connectorには、以下があります。
- Elastic Search
- Kafka
- Spark
ドキュメントURL: https://docs.couchbase.com/server/current/connectors/intro.html
Kafka Connector
Kafka Connector は、Kafka Connectフレームワークのプラグインの形をとっています。
下記のURLからダウンロード可能です。圧縮ファイルを解凍して利用します。
$ curl -OL https://packages.couchbase.com/clients/kafka/4.0.0/couchbaseinc-kafka-connect-couchbase-4.0.0.zip
Apache KafkaとCouchbase Kafka Connectorのセットアップおよび動作確認手順を以下で整理していますので、適宜ご参照ください。
https://github.com/YoshiyukiKono/couchbase_kafka
設定ファイルにて、簡素な設定(接続先、ユーザ名、パスワード)を行うことで、容易にCouchbaseとKafkaとの連携が実現可能であることがお分かりいただけるかと思います。
Kafka + Spark + HBase 連携
検証環境
KafkaについてはApache Kafkaを用いていますが、SparkとHBaseについては、Cloudera社のCDH6.3.2に含まれるものを利用して動作確認しています(検証用に1ノードのみからなるクラスタとして構築)。
ご参考まで、下記に今回の検証環境の構築手順を整理しています(Cloudera Managerのテンプレート機能を使うことで、コマンドラインベースでクラスターの構築が可能です)。
https://github.com/YoshiyukiKono/SingleNodeCDHCluster
Kafka + Spark 連携
今回、KafkaとSparkの連携については、下記を参考にしました。
SparkからHBaseへのデータ投入については、試行錯誤しましたが、以下の記事を参考に最終的に解決することができました。
Ok, I finally fixed the issue. 2 things needed to be done:
1- Import implicits:
Note that this should be done only after an instance of org.apache.spark.sql.SQLContext is created. It should be written as:
val sqlContext= new org.apache.spark.sql.SQLContext(sc) import sqlContext.implicits._2- Move case class outside of the method:
case class, by use of which you define the schema of the DataFrame, should be defined outside of the method needing it. You can read more about it here:
上記が適切に実施された上で、実際にデータ投入する部分は、(今回の検証では)以下の様なものです。
sc.parallelize(events)
.toDF.write.options(Map(HBaseTableCatalog.tableCatalog -> catalog_event, HBaseTableCatalog.newTable -> "5"))
.format("org.apache.hadoop.hbase.spark").save()
実装の全体については、今回の検証にて動作確認を行った、下記ソースコードを参照ください。(動作確認の前提となる、HBaseのテーブル準備などの手順も同じリポジトリに整理しています)
Couchbase + Confluent Kafka + HBase
Confluent Kafkaからは、HBase Connectorが提供されており、Spark Streamingによる処理の要件がなく、Confluentディストリビューションが使われている場合は、直接連携することが可能です。
この場合、プログラミングは介在せず、各コンポーネント(Couchbase Kafka Connector, Confluent HBase Connector)の設定にて完結する形となります。
こちらのケースについては、適宜下記をご参照ください。
https://github.com/YoshiyukiKono/couchbase_confluent-kafka_hbase
最後に
冒頭でも、軽く仄かしてしまったことですが、(複数の異なる目的を提示している様に)記事単体としてファーカスが定まっておらず、また内容の記述的にも記事単体で完結していない(引用先への参照が頻出する)形式をとっており、発表することに若干疑問を持ったまま公開しましたが、この記事が、今回の記事の何かの要素に関心のある方の参考となれば幸いです。