はじめに
背景 〜 ベクトルデータベースとしてのApache CassandraとDataStax Astra DB
2022年からの生成AIの隆盛に対して、Apache Cassandraに対して、DataStaxエンジニアによりベクトル検索機能の拡張提案が提案され、DataStax社のCassandraマネージドサービスであるAstra DBで利用可能になっています。
本記事シリーズは、このような動向の一環として同社から発表されたホワイトペーパーの内容に基づきます。
出典と日本語版
このシリーズ記事の原典は、以下で入手可能です。
ブログ記事では、忠実な訳出ではなく、読みやすさを重視して、一部省略しています。
省略のない日本語版のホワイトペーパーの入手を希望される方はinfo-jp@datastax.comまでご連絡いただければ、提供させていただきます。
【生成AIアプリのためのベクトル検索】④ 検索拡張生成(RAG)パターン
LLMの限界とRAGの中心アイディア
LLMには、それが素のままで用いられた場合、生成された応答が特定のアプリケーションでは用をなさない可能性がある、という限界があります。これは、LLM に保存されている知識が通常そのモデルのトレーニングに用いられたデータに限定されており、インターネット上で一般に入手できないような、最新のデータや、特定のドメインに関連するプロプライエタリデータが含まれていないことに由来します。
検索拡張生成(RAG)の中心となるアイディアは、LLM とユーザーが実行を依頼するタスクの解決に関連する独自のドキュメントとを統合することです。
RAGアプリケーションの基本フロー
次の図3は、RAGを用いたアプリケーションがどのように動作するかを示しています。
図3. RAGパターンを用いたアプリケーションの基本フロー
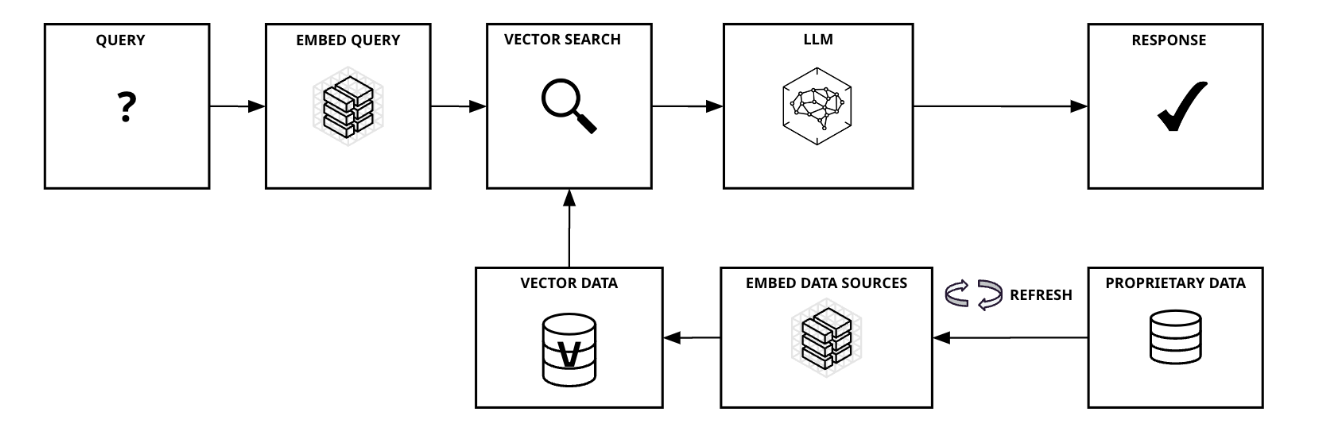
まず、クエリがアプリケーションに対してサブミットされます。生成AIアプリでは、クエリの表現は、様々な形式をとり得ます。それは、例えば、検索エンジンタイプ、つまり「ジョージ・ワシントンの歴史」というようなキーワード、または「ジョージ・ワシントンはいつ生まれたか」のような具体的な質問文、さらには「ジョージ・ワシントンの生涯についてのエッセイを書け」という命令文、といったように。
訳者追記:このようなLLMへのクエリは、(SQLのように構造化されているわけではなく)自然言語によるものです。そこで、「クエリ間の類似性」といった問題系が登場します。 例えば、(直感的に、わかりやすい例を挙げるのであれば)言い回しだけが異なる、同じ質問を過去に行ったことがあれば、LLMをコールしなくても、解答履歴から解答を行うことができるかもしれません。また(より実践的な意味のある用法としては)クエリの中にサンプルの解答を示すようなケースがあり、そうした(上記のような単なるタスク指示とは異なる)情報を含める際に、有用です。
独自データソースのエンベディングに使用したものと同じエンベディングモデルを使用してクエリのエンベディングを行い、そのクエリのエンベディングを使用してベクトル検索を行うことによって、そのクエリに最も類似するデータを検索することができます。このようなデータ間の類似性に基づく効率的な検索は、ベクトル検索によって実現される重要な機能です。
このアプローチには、次の利点があります。
ハルシネーションの軽減(精度の観点)
AIの分野では、一見すると尤もらしく見えるものの、事実とは異なる、あるいは文脈に適さない回答が出力されることを「ハルシネーション(Hallucination:幻覚)」と呼びます。 RAGデザインパターンは、ベクトル検索によって抽出されたドキュメントに焦点を当てるように LLM に指示して、応答を生成します。 LLMのトレーニングに用いられたデータセットの全体ではなく、より文脈に適したドキュメントセットを使用することで、クエリへの応答は、ユーザーの意図をより正確に汲み取ったものになります。
プロプライエタリデータの活用
企業がLLMアプリケーションを開発する場合、LLMの生成する応答を、その企業の製品・サービスとユースケースに対応した内容にするために、そのアプリケーションの要件に関連した企業の保有する情報・ドキュメントを、LLMに直接提供することができます。
LLM 「トレーニング」の簡便さ(実現容易性の観点)
RAGパターンは、特定のアプリケーションに合わせてモデルを調整する方法の中でも、実装および保守が容易です。プロプライエタリデータへの新しいドキュメントの追加、既存のドキュメントの変更、または新しいデータソースが利用可能になったときにも、エンベディングデータを更新して、モデルを最新の状態に、そしてその応答を正確なものに保つことが容易です。
訳者追記:ハルシネーションの軽減や、プロプライエタリデータの利用は、RAGのようなプロンプトエンジニアリングのケースのみではなく、ファインチューニングにおいても、共通する要素です。一方、プロンプトエンジニアリングにおいて、ベクトルデータベースとの組み合わせることの利点として、ユーザーのクエリに対して、動的に対応できることがあります。ファインチューニングでこれを実現しようとする場合、ユーザーのクエリを想像することから始めることになります。
アプリケーション構成とエージェント
次の図3.1は、RAGを使用したアプリケーションまたはサービスを実行するためのアーキテクチャの概要を示しています。
図 3.1 RAGパターンを用いたアーキテクチャ
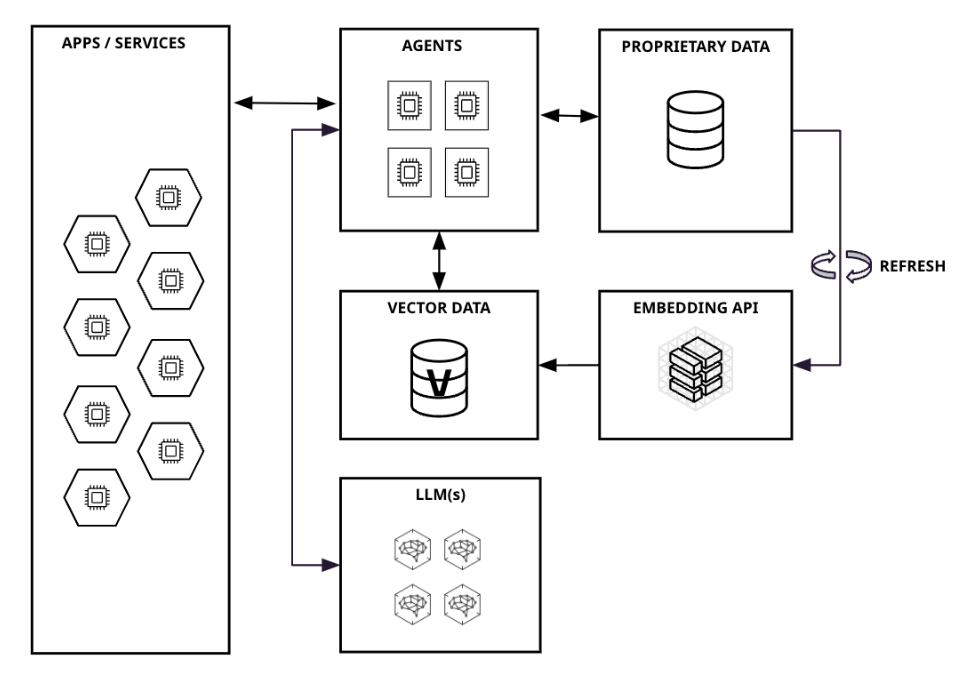
このアーキテクチャでは、エージェントという概念が導入されています。エージェントとは、自動化された推論・意思決定エンジン(コンポーネント)だと言えます。エージェントは、ユーザーからの入力すなわちクエリを受け取り、それに応じて何を行うかを決定します。
図3で紹介した例では、エージェントのタスクは、ユーザークエリのエンベディング、ベクトル検索の実行、検索結果を含むLLMのプロンプトの作成といった一連の基本的なプロセスからなっていました。
より複雑なアプリケーションでは、タスクを複数のサブタスクに分割した上で、問題を解決するために外部ツール(インターネット検索など)を使用する必要があるかどうかを判断したり、アプリケーション用のメモリを使ってデータを保存し維持するために、エージェントが利用される場合があります。
ベクトルデータベースの意義
ここで、エンベディングデータの保存とベクトル検索の実行にベクトルデータベースを採用すると、利用可能なデータ量を非常に大規模なデータセットに拡張しながら、ドキュメント検索速度の性能を維持できるという利点を得ることができます。ベクトルデータベースは、類似性検索を高い効率で実現する機能を備えています。