はじめに
各種ソフトウェア会社が、自社のサービスをクラウド上でのマネージドサービスとして提供を始める流れの中で、NoSQLデータベースについても、サービスが出揃って来た様です。(下記のリスト中の項目名は、Google検索結果の見出しから取りました。また順番については、検索件数順です)
- MongoDB Atlas Database - Cloud DBaaS for MongoDB
- Redis Enterprise Cloud – Fully Managed Cloud Service
- couchbase cloud™ – database-as-a-service
- Multi-cloud DBaaS built on Apache Cassandra™
そんな中、Altoros社による、マネージドサービスとしてのNoSQLドキュメント指向データベース(Couchbase Cloud, MongoDB Atlas, AWS DynamoDB)を対象としたパフォーマンス評価の結果が、2020年末に発表されています。
このペーパーを読んで、日頃、Couchbase Serverに触れている立場として気がついたところ(端的にいえば、違和感を感じた部分)を記事にしようと思います。
ホワイトペーパーの内容に進む前に、まず、Couchbaseのアーキテクチャー上の特徴について触れます。
Couchbaseにおけるデータ検索の特殊性
これ自体、別の記事を書かなければいけないくらいのものですが、ここでは、できる限りポイントを絞って整理します。
クエリ/インデックス・サービスの特殊性
Couchbase Serverにおいて、データベースへの検索リクエストに応答する役割を担うクエリサービスと、そのクエリサービスを成立させるために使われるインデックスサービスは、オプショナルなものとして、中核を担うデータサービスとは独立しており、利用しない選択をした場合には、「サービス」という単位で存在しない(起動していない)状態を選択することができます。
これは、RDBMS(や他の多くのNoSQLデータベース)の経験・知識を元にした発想からは、一見腑に落ちるまでに抵抗があるものではないかと思われます。
プライマリインデックスの特殊性
Couchbaseには(「にも」というべきか)、プライマリインデックスとセカンダリインデックスがあります。ただし、その意味するところは、RDBMS等の他のデータベースとは大きく異なっています。
その違いは、ベストプラクティスガイドにおける一つのTipsに顕著に現れています。曰く「Never Create a Primary Index in Production」。そこでは、以下の様に書かれています。
プライマリインデックス・スキャンは、RDBにおけるフルテーブル・スキャンに相当します。
Couchbaseのプライマリインデックスは、「テーブル」単位で作成する、特定の「キー」を指定しない、インデックスです。
対して、Couchbaseのセカンダリインデックスは、検索条件となる(そして特には検索対象データともなる)「カラム」を「キー」として(時に複数)使い、構築するものです。
「決して本番で使うな」と言われているプライマリインデックスの存在意義は、開発時にインデックスの作成・適正化を実施していない間であっても、クエリを試してみることを可能にする、というただそれだけのためにあります。
一つ付け加えると、分析者がアドホックなクエリを実行する、という要件のためには、また別のアナリティクス・サービスというものが用意されています。
レンジ・スキャンの特殊性
Couchbaseの中核を担うデータセービスは、キー・バリュー・ストアとして構成されており、リード・アクセスは、(ドキュメントの)キー(ドキュメントID)を介して行います。
そして、この「キー」によるアクセスのインターフェイスとして、キーの一定の範囲をレンジとして指定する(低レベルの)APIは存在しません(これは、効果的な複数キーを用いたアクセスの方法がないことを意味しません。これについては後ほど述べます)。
これは、カラムナーなどのNoSQLに慣れている人にとっても、違和感を覚えるものではないかと思われます。
しかし、これはCouchbaseのアーキテクチャーを理解することで氷解する、ともいえます。
① まず、Couchbaseは分散システムです(「いや、それは分かってるよ」)。
② そして、Couchbaseに格納されるドキュメントは、ハッシュ値をベースに分散されます(「まあ、特に珍しくない」)。
③ Couchbaseには、クライアントからインターフェイスの役割を担う特別なノードはありません(「...」)。
④ Couchbaseのクライアント(SDK)は、データとノードのマップを用いて、データが格納されているノードへ直接アクセスします(「なるほど...それで?」)。
だから、Couchbaseには、レンジスキャンのAPIは存在しないのです(ご理解いただけたでしょうか?)。
最後の③と④は、一つのことの裏表を述べただけで、本来一文であるべきかもしれませんが、③は、分散システム(データストア)のある種のカテゴリーに慣れた人にとっての先入観への応答として、④は、Oracle Coherence等、ある種のインメモリデータベースのカテゴリーでは、特に珍しくないアーキテクチャーとして、二つの形で表現してみました。
Altorosパフォーマンス評価に対する違和感
違和感は、まさに上で触れたレンジスキャンの要件に関わる部分(Workload E: Scanning short ranges)です。
下記がこの検証に用いられたアクセス方法の一覧です。
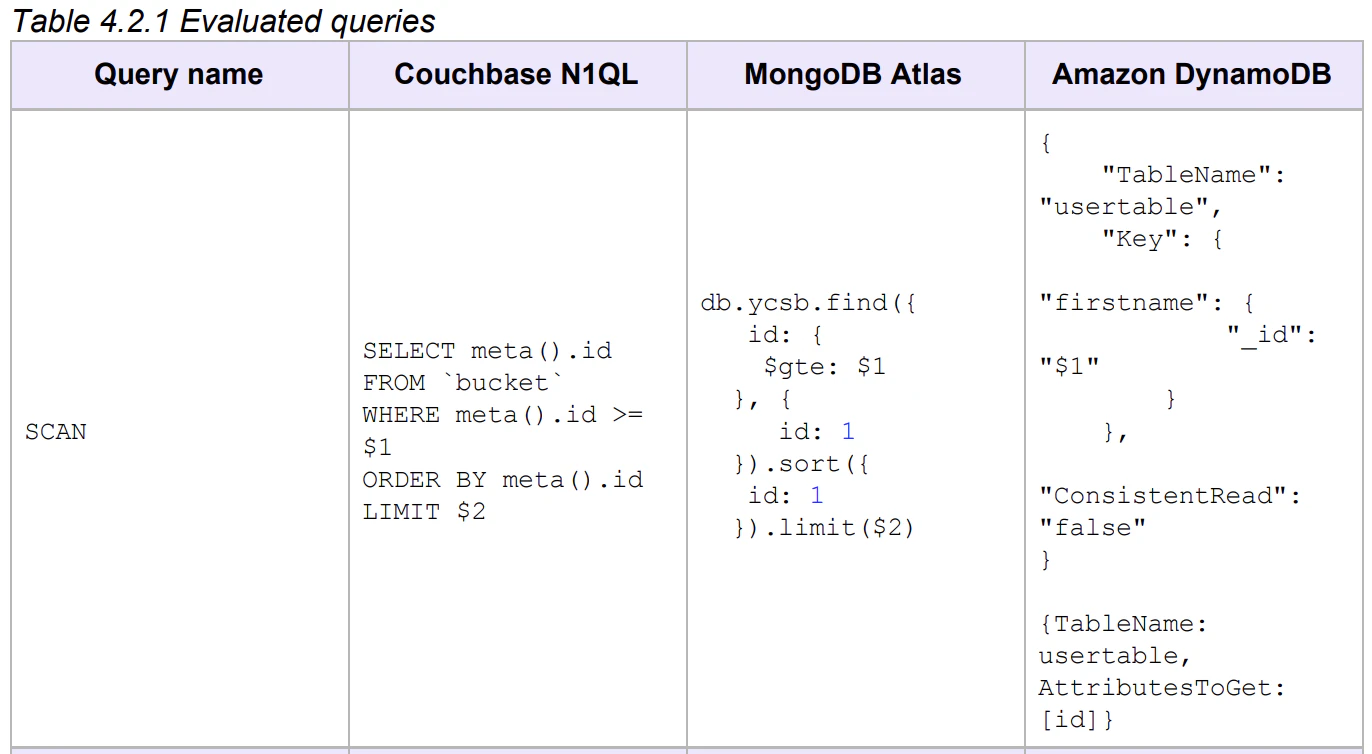
Couchbaseに対するアクセスは、「キー」を用いたものですが、N1QL(というクエリ言語)を用いて実行されています。つまり、クエリサービスとインデックスサービスに依存しています。
Couchbaseでレンジスキャンを実現する妥当な方法
Couchbaseで「キー」のみによるレンジスキャンを行うのであれば、下記の様なAPI呼び出し側での制御を行うことが妥当(Apple-to-Appleな比較)と考えます。
同期型の例
protected List<Object> get() {
for (String key : keys) {
GetResult result = collection.get(String.valueOf(key));
listResults.add(result);
}
return listResults;
}
非同期の例
protected List<Object> get() {
ReactiveCollection reactiveCollection = collection.reactive();
Flux<Object> resultFlux = Flux.fromArray(keys.toArray())
.flatMap( k -> reactiveCollection.get(String.valueOf(k)));
List<Object> listResults = resultFlux.collectList().block();
return listResults;
}
確かに、上記のコードのみでは、idが、ある値以上のものを全て取得する、というクエリを、(キーの設計に全く前提を置かずに)実現することはできていません。
しかし、キーの範囲でデータを取得する際に、キーの値に対して、全く前提を置かない(UUIDを用いた場合の様な)ことは合理的でないと考えます。
キーが単純な増分であれば、キーが存在しない時に処理を中止するという処理で十分対応可能でもあるし、そもそも、キーの値は上限と下限を持った上で、あらかじめ特定されているのが、典型的ではないかとも思われます。
なぜ、Couchbaseは、キーのシーケンスに頼らなくとも、パフォーマンスにおいて他を凌駕することができるのか?
問題としているホワイトペーパー中でも説明されていますが、MongoDBでは、キーのシャーディングのために、「レンジ」と「ハッシュ」を選択する仕様となっています。その上で、上記の性能比較では、レンジが採用されています。
MongoDB Atlas distributes data using a shard key. There are two types of shard keys supported by this database: range- and hash-based. The range-based partitioning supports more efficient range queries. Given a range query on a shard key, a query router can easily determine which chunks overlap this range and routes the query to only those shards that contain such chunks. However, the range-based partitioning can result in an uneven data distribution, which may negate some of the benefits of sharding.
一方で、Couchbaseでは、シャーディングのロジックは、ハッシュに統一されています。
ではなぜ、Couchbaseは、一連のデータへのアクセスのために、レンジパーティションに比べて、多くのノードへアクセスしなければならないという不利を抱えていながら、MongoDBと同等の性能を実現しているかといえば、それは、下記の記事で書いた様に、Couchbaseのアーキテクチャーが、(むしろOracle CoherenceやRedisと比較する方が適切な)メモリファーストアーキテクチャーであり、ディスクによる制約を受けない構造となっているからです。
インメモリDBという選択肢(Oracle Coherence、Redis、そしてCouchbase) ①データ永続化との関係

上記で「同等の性能」と書きましたが、ここでの私の主張は、レンジスキャンであっても、クエリサービスを介さずに、データサービスのAPIを直接使うことによって、上記の図よりも、格段に高い性能を導くはずだというものです。
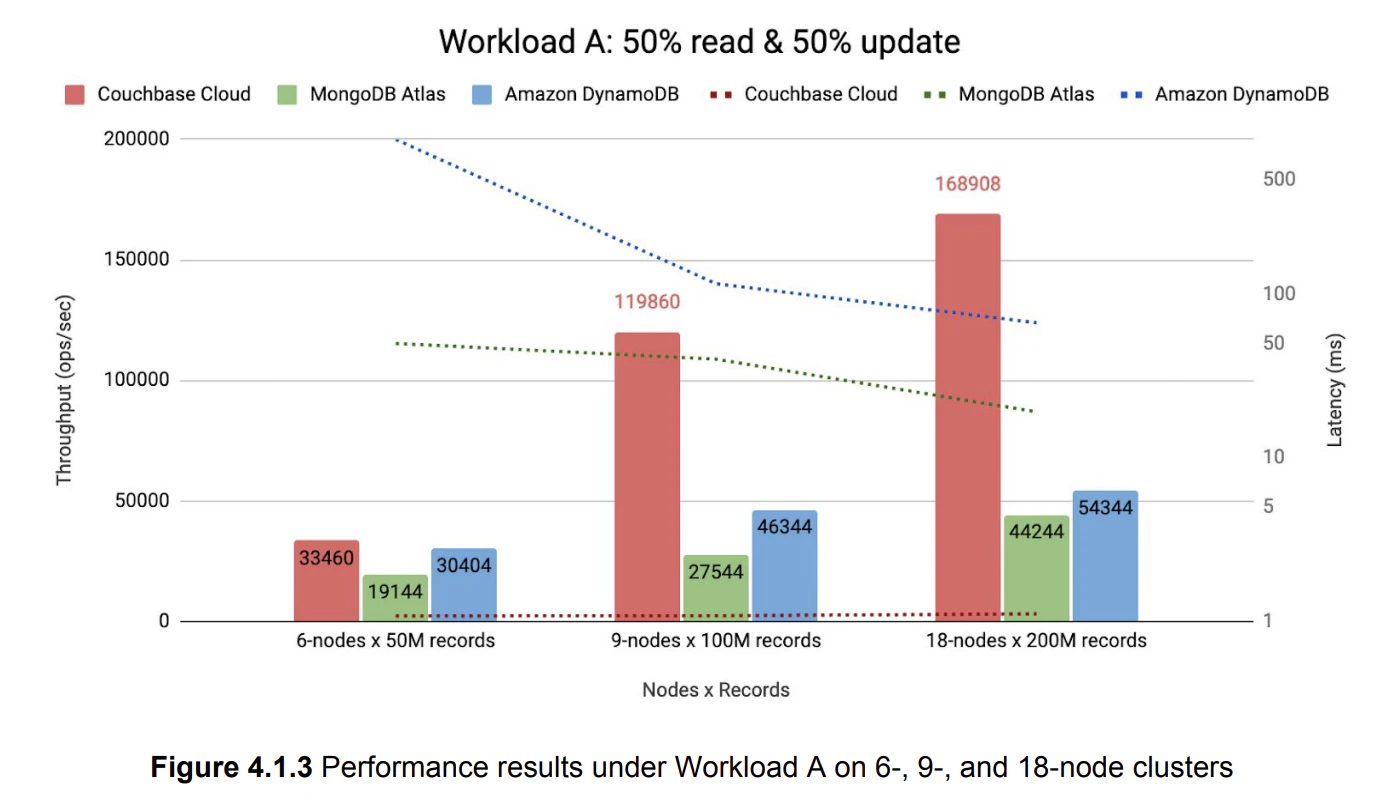
その証拠に、というか、ここで詳説したワークロード以外では、下記の様に次元の違う成果を出しています。
このワークロードAは、キーを直接指定したアクセスを比較したもので、この性能の比較は、「メモリファーストアーキテクチャー」により導き出されたと言えるでしょう。
下記のJOINワークロードは、複数ドキュメントを結合するケースを比較したもので、セカンダリーインデックスを利用したクエリ/インデックスサービスの利点を生かした結果となっています。

最後に
エンジニアにとって、性能比較の結果を知るよりも、その原因を理解することが重要であると考えます。
一方で、性能比較を実施する立場としては、適切な性能を実現する方法を選択することが重要であり、その結果をレポートするまでが、責任範囲であることは理解でき、アーキテクチャー上の特徴や違いにまで言及するのは、性能評価レポートの域を超えていると言って良いでしょう。
しかし、今回のレポートでは、内部のアーキテクチャーへの洞察があれば、より適切な検証方法を選択できたはずだと思える部分があり、今回の記事の形になりました。
その意味でも、データベース毎の評価は、本記事の目的を超えていますが、興味を持たれた方のために、最後に
総合評価について、原文を引用しておきます(とはいえ抜粋でしかないため、興味を持たれた方は、是非、本文全体を参照いただく様お願いします)。
付録. 総合評価の引用と翻訳
Couchbase Cloud showed better performance across all the evaluated workloads in comparison to other databases. In case of queries, Couchbase Cloud provides sufficient functionality to handle the deployed workloads. Furthermore, the query engine of Couchbase Cloud supports aggregation, filtering, and JOIN operations on large data sets without the need to model data for each specific query. As clusters and data sets grow in size, Couchbase Cloud ensures a satisfactory level of scalability across these operations.
Couchbase Cloudは、評価されたすべてのワークロードにおいて、他のデータベースと比較して、優れたパフォーマンスを示しました。クエリのケースでは、Couchbase Cloudは、デプロイされたワークロードを処理するのために十分な機能を提供します。さらに、Couchbase Cloudのクエリエンジンは、、大規模なデータセットでの集計、フィルタリング、およびJOIN操作をサポートしており、それぞれの特定のクエリごとにデータを(再)モデル化する必要がありません。クラスターとデータセットのサイズが大きくなった場合にも、CouchbaseCloudはこれらの操作全てに渡って、十分なレベルのスケーラビリティを保証します。
MongoDB Atlas produced comparatively decent results. MongoDB is scalable enough to handle increasing amounts of data and cluster extension. Under this benchmark, the only issue we observed was that MongoDB did not support JOIN operations on sharded collections out of the box. This resulted in a negative impact and poor performance in JOIN Workload.
MongoDB Atlasは、比較的にいって、かなり良い結果を生み出しました。 MongoDBは、増加するデータ量とクラスターの拡張に対応できるだけ十分にスケーラブルであるといえます。このベンチマークでは、MongoDBがシャードコレクションのJOIN操作を、アウト・オブ・ボックスでサポートしていないことが唯一の問題でした。そのため、JOINワークロードに悪影響とパフォーマンスの低下が生じました。
Amazon DynamoDB is significantly different from the other databases, because it looks like a pure service without proper tuning. Only two parameters can be changed:read and write capacities. In this case, read and write capacities have been calculated depending on the cost of other databases for each workload. Unfortunately, Amazon DynamoDB did not provide competitive results. It produces a large volume of failed requests. Additionally, Amazon DynamoDB did not take part in several workloads, because the data model had to be changed to get competitive results and, thus, cannot be compared to other databases.
Amazon DynamoDBは、他のデータベースとは著しく異なっています。というのも、それはあたかも純粋なサービスであり、適切なチューニングとは関係のないように見受けられます。変更できるパラメーターは、読み取り容量と書き込み容量の2つだけです。今回のケースでは、読み取りおよび書き込み容量は、ワークロードごとの他のデータベースのコストに応じて計算されました。残念ながら、Amazon DynamoDBは競争力のある結果を提示しませんでした。また、大量のリクエストの失敗を生み出しました。さらに、Amazon DynamoDBでは、競争力のある結果を得るためには、データモデルを変更する必要があり、他のデータベースと比較できないため、いくつかのワークロード評価に含めることができませんでした。