はじめに
Cassandra Day Tokyo
今年、2023年6月1日に、Cassandra Dayが日本でも開催されます。
Cassandra Dayは、昨年、ベルリン、ロンドン、アムステルダム、ハノイ、ジャカルタ、ヒューストン、サンタクララ、シアトル、シンガポールでも開催されました。
今回の東京での開催に向けて、Apache Cassandraに関する記事を発表していきます。

Apache Cassandraについて
Apache Cassandraとは、一言でいうなら、オープンソースの分散データベース管理システムです。
他の分散データベース管理システム同様、複数の汎用サーバーを用いて、ひとつのデータベースを構築します(開発などの目的のため、一つのサーバーのみで構成することも可能です)。
ここでは、詳しい説明は割愛し、興味のある方へのご紹介の役割は、公式サイトやWikipediaに譲ります。
現代における「リアルタイム」とは何か?: LambdaアーキテクチャからKappaアーキテクチャへ
この記事について
この記事は、Kai Waehnerによる下記のブログ記事の内容を日本語読者向けに換骨奪胎して、紹介します。
記事の成り立ちについて、作者は以下のように書いています。
この投稿は、2014 年 (!) の Jay Kreps の記事「Questioning the Lambda Architecture 」に大きく影響を受けており、彼の考えを 2021 年の現実世界の状況に当てはめています。
私が、Kappaアーキテクチャーを意識したのは、2022年に、機械学習の「オンラインストア」といった概念を意識したのとあわせての出来事でした。
確かに、Lambdaアーキテクチャーが登場してだいぶ経つ気がしますが、日本では、「スケーラブルリアルタイムデータ分析入門 - ラムダアーキテクチャによるビッグデータ処理」が出版されたのが、2016年ですから、Jay Krepsの記事は確かにかなり先進的な立場(「!」マークは、Kai Waehner自身によるもの)と言えそうです。
では、以下は上記記事の自由な翻案として記します。
レガシーとしてのラムダ(Lambda)アーキテクチャー
リアルタイム データは低速データに勝ります。これは、ほぼすべてのユースケースに当てはまります。それにもかかわらず、多くの企業のアーキテクトは、バッチ レイヤーとリアルタイム レイヤーで構成されるLambda アーキテクチャを使用して新しいインフラストラクチャを構築しています。
以下では、Kappa アーキテクチャと呼ばれる単一のリアルタイム パイプラインの卓越性の理由を探ります。
Kappaアーキテクチャは、Disney、Shopify、Uber、Twitter などの企業で実際に採用されてます。
記事中では、そうした実際の例が、本稿の趣旨にどのように関係してくるかについても触れてられています。
今日、ほぼすべてのビジネス ソリューションは、エンタープライズアーキテクチャーの構成要素の全て(例えばデータ ストレージ、分析プロバイダー、ビジネス アプリケーション、イベントストリーミングといった)にまたがって、非同期の、つまり真の意味で分離されたイベントベースの通信パラダイムをデータ処理に活用します。
これは、ある意味で、Lambda から Kappa アーキテクチャへの移行に対応しています。
Apache Kafka Pulsar Data Lakes の Kappa アーキテクチャと Lambda アーキテクチャの比較
最新のエンタープライズ アーキテクチャ
最新のエンタープライズ アーキテクチャは、柔軟性、弾力性、自動化、異なるアプリケーション間の真の分離、リアルタイム機能 (必要な場合) など、クラウド ネイティブの特性を提供します。
真のデカップリング(疎結合)のためのマイクロサービス、データ メッシュ、およびドメイン駆動設計
今日、ほとんどの人が最新のエンタープライズ アーキテクチャをどのように構築しているかを理解するために、流行語を簡単に調べてみましょう。
- ドメイン駆動設計 (DDD) は、サービス通信と分散型アプリケーション ランドスケープの間に厳密な境界を適用します。
- マイクロサービスを使用すると、さまざまなプログラミング言語と通信パラダイムを使用して、柔軟で分離されたアプリケーションを構築できます。
- データ メッシュを使用すると、データに関するサービスを設計できます。データは、データ メッシュの積です。セルフサービス機能とフェデレーションにより、ビジネス ユニットはビジネス上の問題に集中できます。
私のブログ投稿「マイクロサービス、Apache Kafka、およびドメイン駆動設計」では、この議論をより詳細に調査しました (執筆時点では「データ メッシュ」という流行語は存在しませんでしたが)。TL;DR: Apache Kafka などのイベント駆動型のストリーミング インフラストラクチャは、適切なデカップリングとリアルタイムのデータ処理を独自に可能にします(従来の Web サービス / REST / HTTP ベースのマイクロサービス アーキテクチャや、従来のメッセージング システム (MQ、ESB) とは対照的です)。Kafka と MQ/ETL/ESBに関するブログ投稿も、詳細を知るのに役立つ場合があります。
Data-at-RestとData-in-Motion
データを用いるサービス、そしてそれを実現するアプリケーションについて考えてみる時、リアルタイムデータはスローデータに勝る、このステートメントは、ほとんどの場合に当てはまることに気が付きます。
データのリアルタイム性が高まることによって、収益の増加、コストの削減、リスクの削減、または顧客体験の向上、といった結果につながります。Data-in-Motionの重要性がとり立たされる所以です。
一方、Data-at-Restとは、データベース、データ ウェアハウス、またはデータ レイクにデータを保存することを意味しますが、もちろん、Data-at-Restが無意味という訳ではありません。レポート (ビジネス インテリジェンス)、分析 (バッチ処理)、モデル トレーニング (機械学習)などのいくつかのユース ケースは、このアプローチで非常にうまく機能します。しかし、その他の多くのユースケースでは、リアルタイムがバッチに勝ります。
このコンテキストを念頭に置いて、Lambda アーキテクチャを再検討します。
ラムダ アーキテクチャ
Nathan Marz は Lambda アーキテクチャを作り出しました。これは、バッチ処理とストリーム処理の両方の方法を利用して大量のデータを処理するように設計されたデータ処理アーキテクチャです。
Lambda アーキテクチャには、バッチ、スピード、およびサービング レイヤーが含まれます。このアプローチにより、データをリアルタイムで処理できるだけでなく、バッチ処理された静的データセットを簡単に再処理できます。
このアプローチでは、バッチ処理を使用してバッチ データの包括的かつ正確なビューを提供すると同時に、リアルタイム ストリーム処理を使用してオンライン データのビューを提供することにより、待ち時間、スループット、およびフォールト トレランスのバランスをとろうとします。ラムダ アーキテクチャの台頭は、ビッグ データ、を活用した分析のレイテンシを軽減しようとする動きの着実な成長と相関しています。
Lamba アーキテクチャの 2 つのオプション
Lambda アーキテクチャには、2 つの異なるアプローチがあります。
最初のアプローチでは、統一されたサービング レイヤーが提供されました。統合されたサービング レイヤーは、リアルタイム レイヤーとバッチ レイヤーを結合します。
統合されたサービング レイヤーを使用した Lambda アーキテクチャ
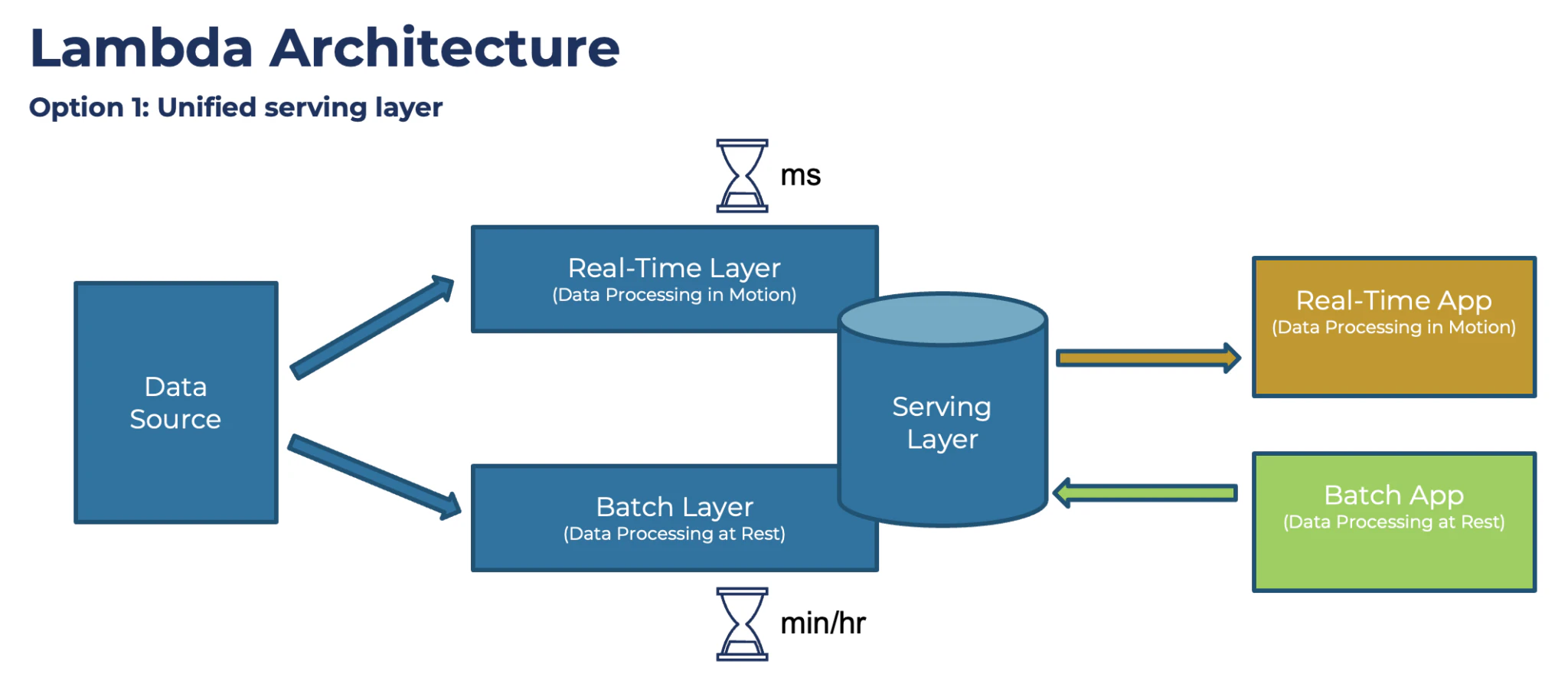
もう 1 つの方法は、2 つの別個のサービス レイヤーです。1 つのレイヤーはリアルタイム用で、もう 1 つはバッチ用です。
2 つの別個のサービング レイヤーを持つ Lambda アーキテクチャ
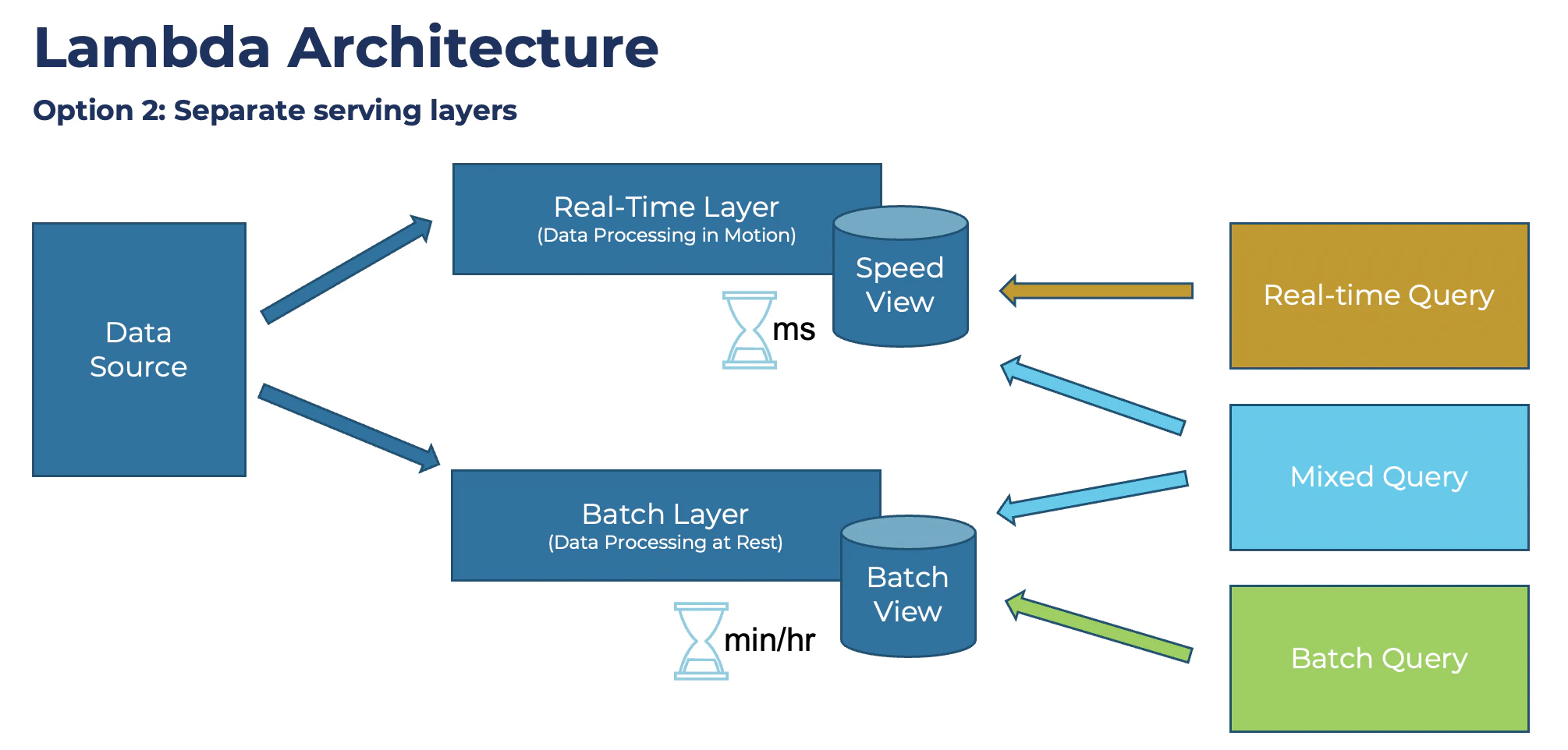
実際の現場では 2 番目のオプションをよく見かけます。
いずれにしろ、どちらのオプションも、データの取り込みと処理のために 2 つの別個のレイヤー(リアルタイムレイヤーとバッチレイヤー)を持つという意味で共通しています。
Lambda アーキテクチャの問題
Disney は、Lambda アーキテクチャに関する懸念事項を 1 つのスライドにまとめました。
Lambda アーキテクチャに関する Disney の懸念

バッチ側とストリーミング側にはそれぞれ、処理されたデータが両方のパスから同じ結果を生成するように、維持および同期を維持する必要がある異なるコードベースが必要です。さらに、バッチ、スピード、およびサービング レイヤーでは、すべてを (少なくとも) 2 回処理する必要があります。これにより、ストレージ、ネットワーク、およびコンピューティングのコストと運用作業が増加します。
Jay Kreps は、2014 年 (!) に Kappa アーキテクチャを提案したとき、すでに同様の議論をしていました。
では、Kappa アーキテクチャはどう違っているのか?
Kappa アーキテクチャ
Kappaアーキテクチャは、イベントベースのソフトウェア アーキテクチャであり、トランザクション ワークロードと分析ワークロードのすべてのデータをあらゆる規模でリアルタイムに処理できます。
Kappa アーキテクチャの背後にある中心的な前提は、単一のテクノロジ スタックでリアルタイム処理とバッチ処理の両方を実行できることです。インフラストラクチャの中心はストリーミング アーキテクチャです。
まず、イベント ストリーミング プラットフォームのログに受信データが格納されます。そこから、ストリーム処理エンジンがデータをリアルタイムで継続的に処理するか、リアルタイム、ニアリアルタイム、バッチ、リクエストベースなど、任意の通信パラダイムを介して他の分析データベースまたはビジネス アプリケーションにデータを提供します。
Kappa アーキテクチャ
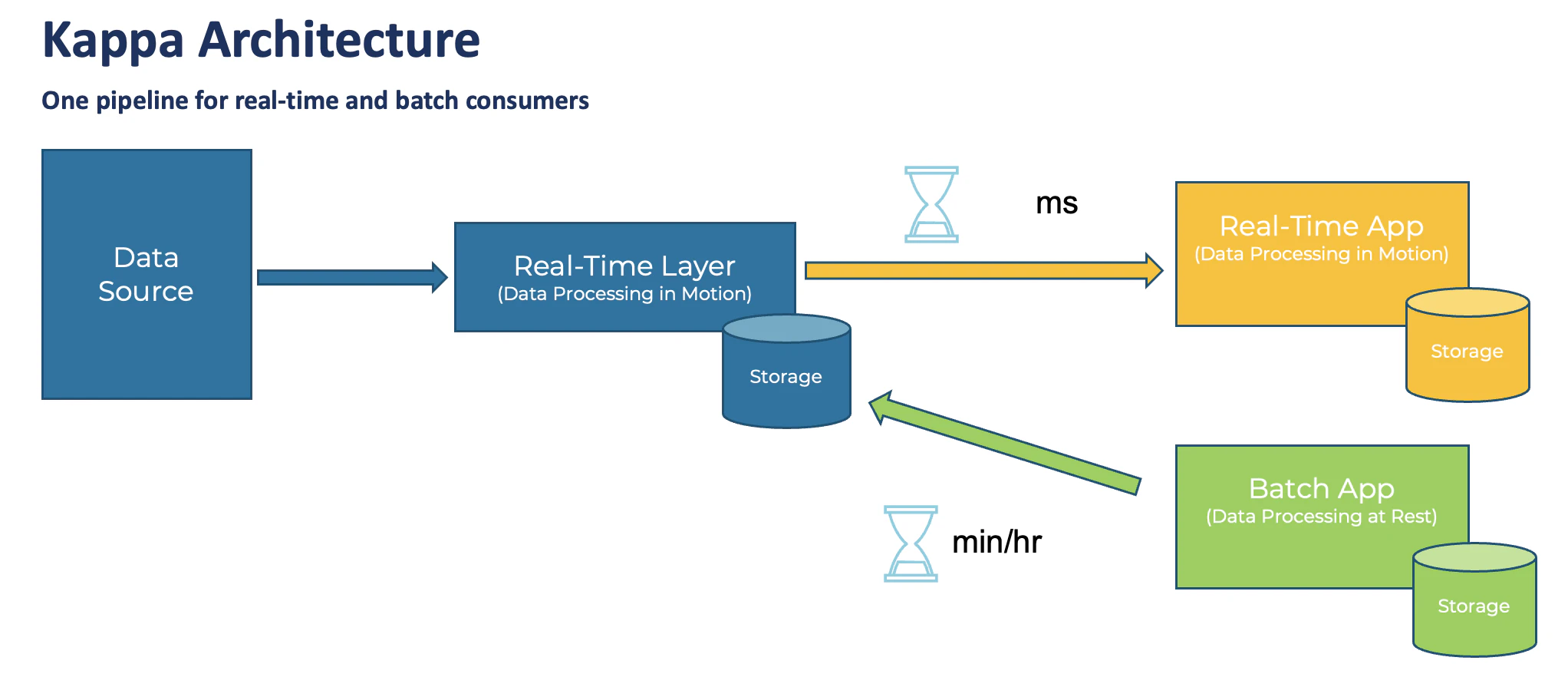
Kappa アーキテクチャの利点
Kappa アーキテクチャにはいくつかの利点があります。
- 単一のアーキテクチャですべてのユースケース (ストリーミング、バッチ、RPC) を処理します
- 常に同期している 1 つのコードベース
- インフラストラクチャとテクノロジの 1 つのセット
- インフラストラクチャの心臓部は、リアルタイム、スケーラブル、そしてリライアブル(信頼性を有する)です
- 順序が保証され、不一致がないため、データ品質が向上します
- 新しいユースケースのために再設計する必要はありません
トランザクションおよび分析ワークロードのための Kappa
データ レイクとは対照的に、イベント ストリーミングを利用したKappa アーキテクチャは、分析ワークロードに加えてトランザクション ワークロード も可能にします。
Apache Kafka を利用したトランザクションおよび分析ワークロード用の Kappa アーキテクチャ

たとえば、Kafka とそのエコシステムは exactly-onceセマンティクスのサポートにより、ミッション クリティカルな SLA、低レイテンシ、組み込みのフォールト トレランスを備えたアフターセールスまたは顧客とのやり取りのための支払いプラットフォームを構築できます。
同時に、データ サイエンス チームは、機械学習を使用してバッチ プロセスで洞察を見つけるために履歴イベントを使用します。
イベント ストリーミングというパラダイム シフト
Kappa アーキテクチャは、うますぎるように聞こえますか? まあ、基本的な経験則は今でも有効です。仕事に適したツールを使用してください!
イベント ストリーミングはパラダイム シフトです。以下は、Kappa アーキテクチャの導入についてディズニーが学んだいくつかの教訓です。
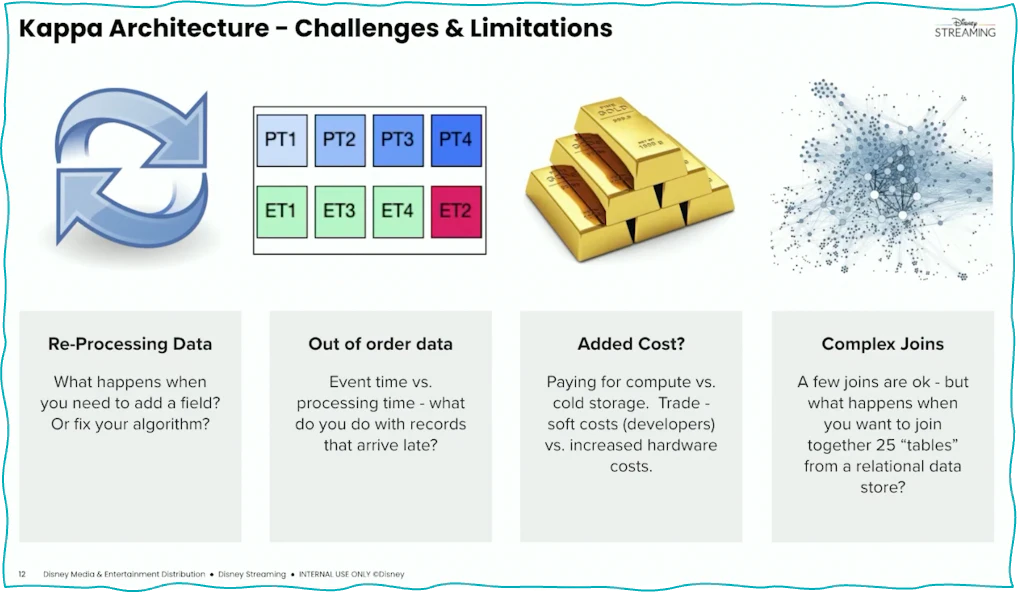
現実のKappaアーキテクチャへのアプローチ
現実のKappaアーキテクチャーの導入においては、自然、データとその管理(データベース)について再考することになります。
Martin Kleppmann はこれを「データベースを裏返しにする」と呼びました。
データベースを裏返しにするとは、インフラストラクチャの中心が、イベントベースのリアルタイムデータになることを意味します。
ここで、イベント ストリーミング プラットフォームについて考えてみます(Apache Kafkaを想定してもらうのが、わかりやすいでしょう)。イベント ストリーミング プラットフォームには、以下のような機能が必要とされます。
- データの可用性/保持
- データの一貫性と耐障害性
- 時間差を伴うデータの処理
- データの再処理とバックフィル
- データ統合
つまり、イベント ストリーミングプラットフォームは、Kappa アーキテクチャを構築するための多くの特性を提供します。ただし、特効薬とは呼べません。
一部のユースケースでは、追加のデータベースと分析ツールが必須です。たとえば、Kafkaは、動的にバーストするワークロードに対して適切にスケーリングしません。
複雑な SQL クエリと結合にも、別のデータベースが必要です。
以下の記事「Can Apache Kafka Replace a Database?(Apache Kafka をデータベースとして使用できますか?) 」は、Kafka をデータ ストレージとして使用することの観点とトレードオフの両方を理解するのにも役立ちます。
最後に
本稿では、下記記事の前半の内容について紹介しました。
以下に要約を試みます。
LamdaアーキテクチャーからKappaアーキテクチャへの移行により(原因)、イベントストリーミングプラットフォームのデータベースの代替としての側面に注目が集まっている(結果)。
上記記事に触れられているわけではありませんが、上記の「結果」の部分は、「リアルタイム、スケーラブル、そしてリライアブル(信頼性を有する)」な、別のデータベースに置き換えて考えてみることもできるでしょう。
また、記事では、Kafkaが引き合いに出されていますが、より現代的なイベントストリーミングプラットフォームを考えてみることもできるでしょう。
筆者の立場として、それぞれ、Apache Cassandra、Apache Pulsarという名前を与えてみたい気もしますが、その詳細については、別項に譲りたいと思います。