はじめに
昨今AIの発達が目まぐるしく、エンジニアである以上AIがどういうものか何にもわからないというのはよろしくないなと思ったところです。
そこでまずAI、機械学習、ディープラーニングについて大雑把に理解することを目的に、「ゼロから作るDeep Learning」を読んでみました。
以下は読んだ内容について備忘録的にまとめた内容です。
AI、機械学習、ディープラーニング
ゼロつくを読むまでAI、機械学習、ディープラーニングをそれぞれ同じものを指した言葉だと思い込んでいましたが、実際には違います。
これらの違いが厳密に定義されているわけではないですが、多くの場合は以下のような関係性で説明されています。
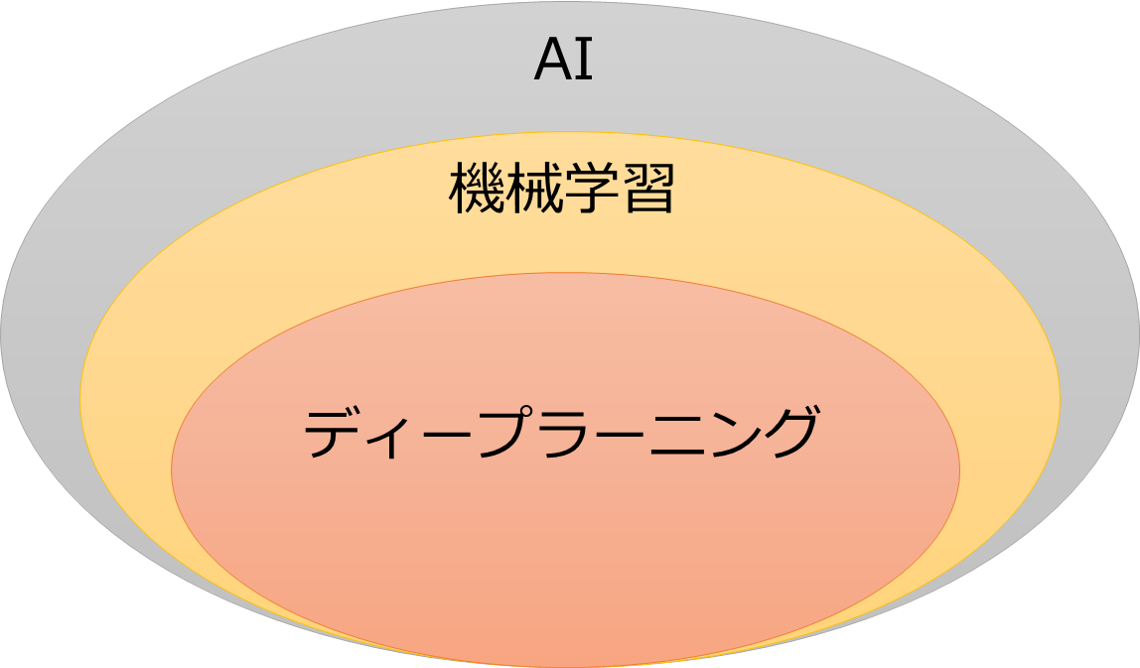
AIは自律的に行われる何かしらの処理と考えられます。なので、特定の閾値を設けて処理を2分するようなプログラムでもAIに含まれます。
機械学習はAIを作るための技術の一つで、機械的にデータの分類をするためのアルゴリズムであるSVMなどがあります。
そしてディープラーニングはこの機械学習の手法の一つに当たります。ニューラルネットワークと呼ばれる機械学習手法を発展させた手法です。ニューラルネットワークを機械学習の一手法ととらえる場合とディープラーニングの構成技術としてディープラーニングの一部と表現される場合があります。
パーセプトロン
ディープラーニングの構成技術である、ニューラルネットワークのおおもとになったアルゴリズムのことです。
二つの入力の和が閾値以下or上回ったときにそれぞれ0 or 1を出力します。
y=
\begin{equation}
\left\{ \,
\begin{aligned}
& 0 \quad(b + ω1x1 + ω2x2 + .... + ωnxn \leqq 0) \\
& 1 \quad(b + ω1x1 + ω2x2 + .... + ωnxn > 0) \\
\end{aligned}
\right.
\end{equation}
入力に対する係数を重み、閾値をバイアスと呼びます。
基本的にパーセプトロンは線形分離(0、1の判定)しかできないという性質があります。
しかしパーセプトロンは組み合わせることができ、多層のパーセプトロンによって線形でない問題の分離を行うこともできます。
ただし多層パーセプトロンというと一般的にはニューラルネットワークのことを指します。
パーセプトロンの組み合わせによってできるネットワーク形状事態はニューラルネットワークと同質のものですが、後述する活性化関数が異なります。
ニューラルネットワーク
パーセプトロンの場合、重みやバイアスは人の手で設定しますが、ニューラルネットワークは自動的に学習して重み・バイアスを設定します。
基本的には入力層(青)、中間層(黄色)、出力層(オレンジ)の3つの層からなるネットワークです。
入力層から中間層への重みとバイアスをω1・b1、中間層から出力層への重みとバイアスをω2・b2としています。
また括弧内は前層のノードから次層のノードへの計算を行う際の重みの対応位置を表しています。
この場合例えば入力nから中間mへの計算をするときの係数はω1(mn)、中間mから出力lへの計算をするときの係数はω2(lm)で表現します。
また、入力から中間mへの計算をするときのバイアスはb1(m)、中間から出力lへの計算をするときのバイアスはb2(l)で表現します。
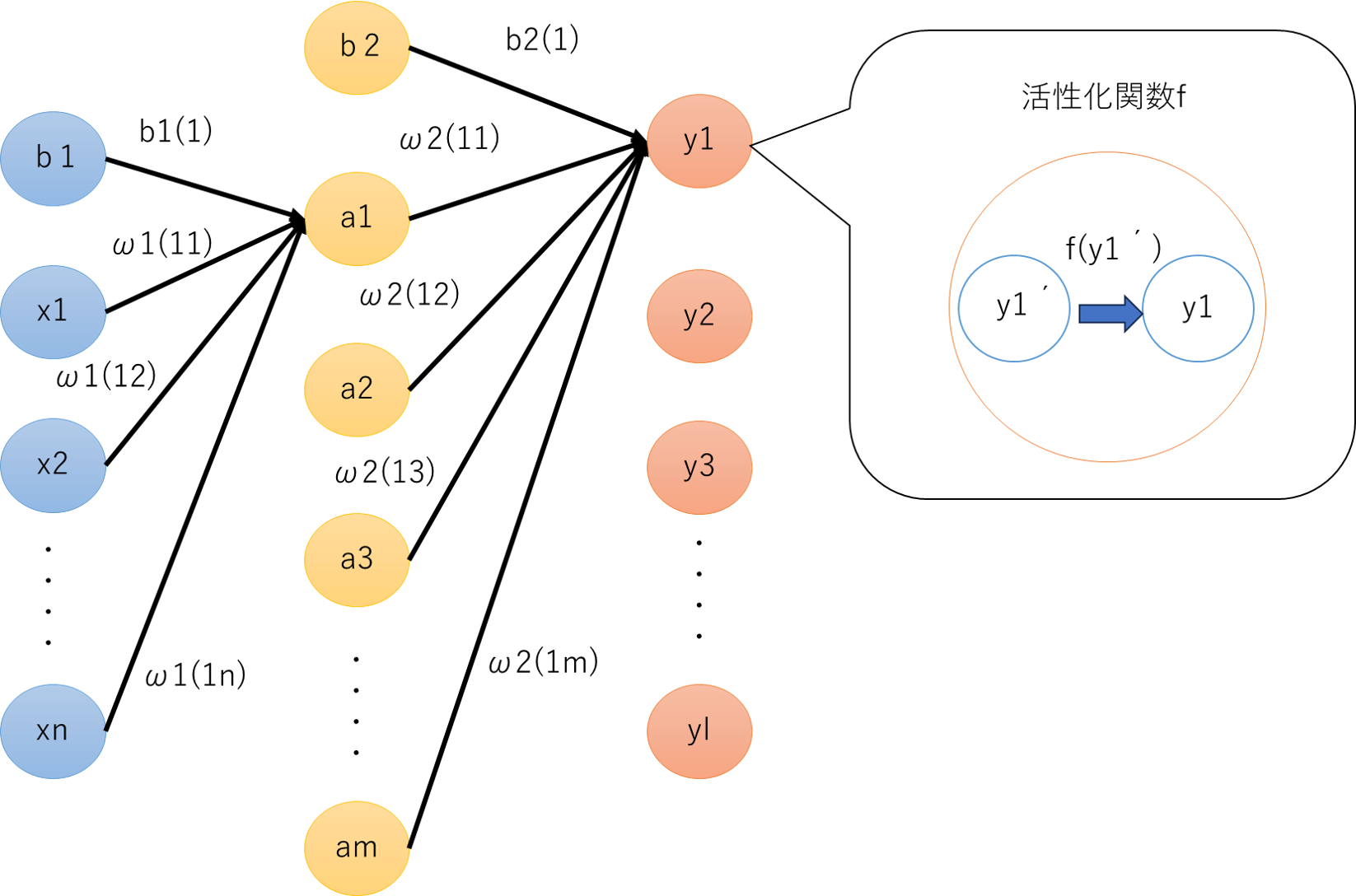
例えば中間層第一ノードa1への入力は以下のようになります。
a1 = b1(1) + ω1(11)x1 + ω1(12)x2 + ω1(13)x3 + ..... + ω1(1n)xn
amの場合は以下のようになります。
am = b1(m) + ω1(m1)x1 + ω1(m2)x2 + ω1(m3)x3 + ..... + ω1(mn)xn
また出力層の中で、中間層から出力層への計算を経て入力される値を最終的な出力に変換する(活性化させる)活性化関数が用いられます。
パーセプトロンの場合この活性化関数にステップ関数を用いていると考えることができます。
ニューラルネットワークにおいてはこの活性化関数にシグモイド関数やReLU関数が用いられます。
シグモイド関数
f(x) = \frac{1}{1+e^{-x}}
ReLU関数
f(x)=
\begin{equation}
\left\{ \,
\begin{aligned}
& x \quad(x > 0) \\
& 0 \quad(x \leqq 0) \\
\end{aligned}
\right.
\end{equation}
ニューラルネットワークではシグモイド関数などを用いることで、計算の結果を例えば0.7516のような微小な値へと変換できます。
これによって出力を確率的な数値として扱うことができるようになります。また活性化関数を用いることでパーセプトロンを使用する場合は出力値が1 or 0に強制的に落とし込まれてしまいますがそれを避けることができます。
またニューラルネットワークはこの活性化関数に線形関数を用いず、非線形関数を用います。
線形関数を用いると例えばy=Cxという関数を活性化関数とした場合、層を深くしてもy=CCCxなどのようになり、y=a(=CCC)xという活性化関数を用いる単層のネットワークと同義になります。つまり線形関数を用いると層を深くすることによるメリットを得られなくなります。
ニューラルネットワークの計算
ニューラルネットワークの計算は行列の積で行われます。
各パラメータを以下のような行列で表した場合
A =
\begin{pmatrix}
a1 & a2 & a3 & ... & am
\end{pmatrix}
\\
X =
\begin{pmatrix}
x1 & x2 & x3 & ... & xn
\end{pmatrix}
\\
B1 =
\begin{pmatrix}
b1(1) & b1(2) & b1(3) & ... & b1(m)
\end{pmatrix}
\\
W1 =
\begin{pmatrix}
ω1(11) & ω1(21) & ω1(31) & ... & ω1(m1)\\
ω1(12) & ω1(22) & ω1(32) & ... & ω1(m2)\\
\vdots & \vdots & \vdots & ... & \vdots\\
ω1(1n) & ω1(2n) & ω1(3n) & ... & ω1(mn)
\end{pmatrix}
入力層から中間層への計算は以下のように表すことができます。
A = XW1 + B1
例示しているニューラルネットワークでは、入力層→中間層の間で行列計算を1回、中間層→出力層の間で行列計算を1回行います。
その後、出力層内でシグモイド関数などの活性化関数(=ソフトマックス関数)に値を渡し、最終的な出力を得ます。ただし出力層の結果は活性化関数を使わずとも最大の値が基本的には変わらないため、省略されることがあります。
出力層のノード数は任意に設定しますが、ニューラルネットワークの用途によって決定します。例えば手書きの数字画像に対して1~10のどれに該当するか分類する場合は10個のノードを用意します。
バッチ処理
ニューラルネットワークは一度に入力するデータを複数個分まとめて入力して、その結果を得ることができます。これをバッチ処理といいます。
手書きの数字画像の分類の例でいえば、仮に画素数784の画像を入力とするニューラルネットワークの場合、これと同サイズの画像を100枚用意して行列形式で入力することができます。
こうした場合、出力も行列の形での出力となり100*10の形で出力されます。

学習
勾配法
ニューラルネットワークの学習でよく使われる手法に勾配法があります。勾配法では訓練データにおける入力と正解値を使い、ニューラルネットワークの重みとバイアスの値を更新する作業を行います。損失関数(=正解値と入力をニューラルネットワークに入れて得た出力とを比較した結果を算出する関数)の値が小さくなるように重みとバイアスの値を更新することで学習が行われます。
損失関数として使われる関数はいくつか存在し、有名なもので二乗和誤差や交差エントロピー誤差があります。
Eを誤差の値、ykをk番目の入力データに対する出力、tkをk番目の入力データに対する正解値とするとそれぞれ以下のように表されます。
二乗和誤差
E = \frac{1}{2}\sum_{k}(yk-tk)^2
交差エントロピー誤差
E = -\sum_{k}tk\log yk
損失関数の示す値は、正解値と出力の差の度合いを表し、この値が小さくなればなるほどそのニューラルネットワークの正答率が高くなるということになります。
学習を行う際は、訓練データ、出力、正解値を使い、損失関数の微分値を求めます。この時損失関数を、パラメータ(重みまたはバイアス)を変数とする関数として、各パラメータごとの偏微分値を求めます。これによって各パラメータの微小量変化時の損失関数の結果に対する影響がわかります。
この偏微分値をもとに重みとバイアスを更新していきます。この時重みごと・バイアスごとの偏微分をベクトルとしてまとめたものを勾配と呼びます。勾配はその重み・バイアスの値における関数の出力値がより小さくなる方向を示しています。そのためこの勾配が示す方向に従って重みを更新することで、損失関数の値がより小さくなる、つまり誤差が小さくなると考えられます。
更新する際は勾配に学習率を掛けた値で更新します。微分値が正の場合マイナスすることでより小さい値へと変化していくことが期待できます。
学習率をη、損失関数をfとしたときのω1(11)の更新は以下のようになります。
ω1(11) = ω1(11) - η\frac{∂f}{∂ω1(11)}
学習率は大きすぎても小さすぎてもうまくいかない可能性があるため、更新の結果を確認しながら学習を進めていきます。
損失関数で勾配を求め、勾配の値をもとに重みとバイアスを更新して、更新した重み・バイアスで再度損失関数の値を計算し、重み・バイアスの更新します。これを繰り返すことによって重み・バイアスの値を最適化するのが学習ということになります。
また学習回数や学習率、ノードの数などのことをハイパーパラメータと呼びます。
ミニバッチ学習
学習を行う際、学習データが膨大な量存在する場合、効率化のためにバッチ処理を導入します。
このように複数のデータに対する平均の損失を求めることで学習を効率化します。またこのように複数データを用いて損失関数を計算する場合は、無作為に母集団からデータの抽出を行って損失関数の計算に用います。このような学習方法をミニバッチ学習といいます。
評価
1エポックの学習が完了(=1回の勾配計算時に用いる訓練データをすべて学習に使った)時点でニューラルネットの評価を行います。10000個の訓練データを使って学習を行う場合に、1回の学習時に100データをミニバッチとして設定すると1エポック=100回となります。
評価する際はニューラルネットワークに評価用のテストデータを入力し、結果と正解値から精度を出力して評価します。
こうして学習と精度の出力を繰り返して学習の精度を確認していきます。訓練データでの精度とテストデータでの精度に著しい差がみられなければ過学習(=テストデータにのみ対応した学習)は起きていないと考えられます。
あらかじめ設定しておいた学習回数を超えたところで学習を完了します。
おわりに
ゼロつくの1~4章の内容について理解したことをまとめました。
最後まで読み終わってはいますが、全部書くと長くなるのでいったん前半部分について整理しました。
未知の分野の内容については本を読むだけだと理解が定着しないので、理解の定着を目的に記事にしました。
この記事を書く間にあれってどうなってるんだっけ?みたいなことがたくさん出てきたので、記事にするというのはやってよかったなと思います。
前半でいったん切りましたが、後半は画像の分類などで高い認識精度を出せるCNNや学習を高速化するための方法などが書かれており、より実用向けの内容でしたので、また時間を見て後半についても整理して理解の定着を図りたいと思います。