本記事は、 ドメイン駆動設計#1 Advent Calendar 2019 の12日目です。
レガシーシステムと現役でお付き合いされている方や、過去にお付き合いのあった方、いらっしゃるかと思います。
私も最近、本格的なお付き合いをはじめました。
レガシーなコードを掘削していると、
- ドメインモデルと思しきモデルに出会っても、命名が変な規則になっており、「ちょっと何言ってるか分かりません」状態になる…
- あっちこっちで同じ名前を使われているので、同じ意味なのか違う意味なのか分からない…
- レイヤー化されていないのでユースケースが色んなところに散らばっており、雨の日シナリオを拾い切れない…
- ひどい時は晴れの日シナリオですら迷子になる…
みたいなことがありました。
とにかくソースコードを読んでみるんだけど、実行してデバッグしないと分かんない…
そんなレガシーなコードから、ドメインモデルを抽出し、ユースケースがこれじゃね?と当たりをつけるに至るまでに取り組んだことを書いてみます。
なお、レガシーシステムにも色々あると思いますので、万物に共通する手法では無いと思います。
あくまで、私が最近取り組んだことの紹介となります。
また、現在、試行錯誤して実践中であり、仮説的なものもいくつか混ざって書かれています。
やったこと
ざっと、以下のステップを実施した。
- 既存のデータ構造をモデル化する
- 分かる言葉に置き換える
- パッケージにまとめる
- Getterを消してコンストラクタに着目する
- ユースケースを掘り起こす
- ユースケースをテストに書く
- ユースケースを満たすモデルにする
詳細は以下。
既存のデータ構造をモデル化する
本来でしたら、RDRA2.0を活用して、要件定義からブレークダウンしていって、ドメインモデルにアプローチをしたいところだったのですが、そのアプローチをまずやってみたところ、既存の業務を把握するのにとてつもない時間を要すことが分かったので、一旦、そっちの道は置いておいて、既存のデータ構造を見て、ドメインを予測していくアプローチを取りました。
データ構造としては、RDBのテーブルや、YAMLファイルなどがあります。
どれも、正規化されておらず、データのまとまりを理解することが困難でした。
そこで、今のテーブルやYAMLのフィールド名を、そのままJavaのクラスに書き起しました。
書いたクラスたの関連を俯瞰的に把握するために、 dddjava/jig: Java Instant-document Gazer を使って、関連をダイアグラムで見れるようにしました。

こちらが実際の図になりますが、何がどうなっているのか全然わかりませんでした。
(書かれている言葉はモザイクしてます…分かりにくいですがごちゃってなっていることをお伝えできれば…)
書かれている言葉の意味もよく分からないうえに、関連の線もごちゃごちゃしており…人間がさわるものじゃねぇぞ状態でした ![]()
分かる言葉に置き換える
ここまでは、分からないことが分かった状態ですので、各クラスの名前を「これってつまりこのことだよね」と一般的に意味の通じやすいと思われる言葉に置き換えていきました。
観点としては、
- 省略された言葉を正しい言葉にしたうえで分解する
- その言葉が必要とされるシーンに合わせて分解する
- つまりこういうことだよねと核心に迫る言葉に置き換える
- 単純に言い換える
といった感じです。
言葉の置き換えをしていくと、クラスを分解していくことになります。
IDEのリファクタリング機能を使い、クラスの名前を変更したり、分解して関連を途切れさせないようにしながら言葉を入れ換えていきました。
その結果を常にJigで出力して、どうなっているか状況を確認しながら取り組みました。
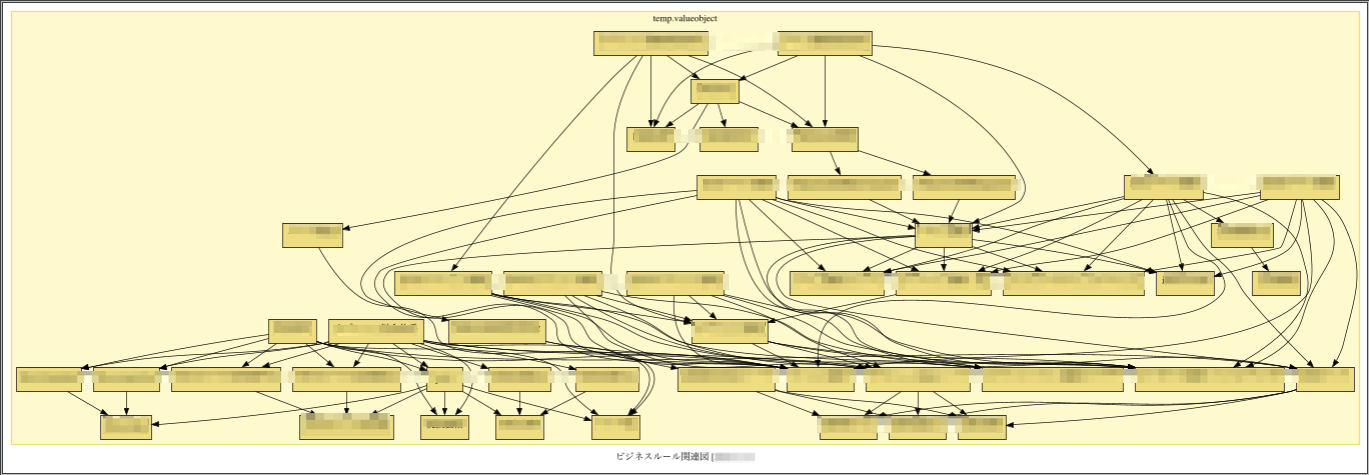
かなり関連の強弱がはっきりして、かたまりが可視化されてきました。
パッケージにまとめる
この時点では、ひとつのパッケージにフラットにクラスを並べている状態でした。
これを集約を意識してまとまりを作っていくことに取り組みました。
IDEを活用し、関連を途切れさせることなく、パッケージにまとめていきました。
観点としては、
- いきなり細かい単位に切らない
- 影響範囲が閉じている粒度で切る
- 相互参照になっているクラスは一旦commonパッケージに置いた
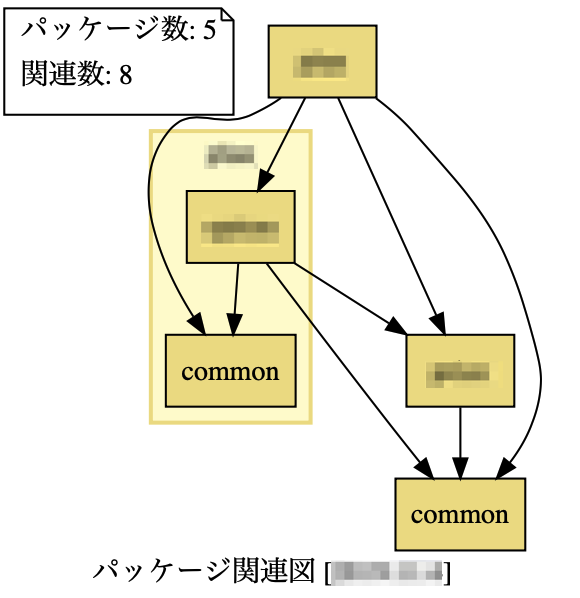
パッケージの関連だけを見るとかなり整理されたように見えます。
とはいえ、それぞれのパッケージにクラスがどかっと入っている状態ですので、さらにクラスを分割して、パッケージに分割していくことを検討していきます。
ちなみに、commonパッケージを置かなかった場合、どちらかのパッケージにクラスを置くことになるため、パッケージ間に相互に関連があることになります。Jigは、パッケージ間に赤い線を引いて相互に関連あるよって教えてくれます。
Jigすげぇです。
Getterを消してコンストラクタに着目する
関連が複雑になっている部分をさらに整理することと、パッケージ内に関心を閉じ込める境界を見つけていくことに取り組みました。
この時点ではデータ構造をクラスに落としていますので、何も操作を持っていないクラスになっています。
属性とGetterを持っているクラスが大半でした。
public class Foo {
private Bar bar;
public Bar bar() {
return bar;
}
}
とりあえず書いてあったGetterを消して、コンストラクタのみにします。
public class Foo {
private Bar bar;
public Foo(Bar bar) {
this.bar = bar;
}
}
このように書き換えても、関連に変更はないのですが、ソースコードに着目すると、コンストラクタにOptionalを渡す構造が見つかります。
コンストラクタにOptionalを渡す必要があるクラスは、ライフサイクルを見直すと別のモノを1つのクラスで表していたり、関連クラスに切り出すことで新なモデルの発見につながります。
ユースケースを掘り起こす
ここまでに出来たクラスは、データ構造を整理した結果なので、操作を持っていません。
操作を実装するにあたり、クラスに持たせた属性がカプセル化できているか確認していく必要があります。
既存のソースコードからユースケースを掘り起こし、クラスに操作を持たせていきます。
この工程はとにかく力技でコードを理解していくしかないのですが、今までのワークを通して、ドメインらしきモデルを作ってきましたので、翻訳力が培われています。
概念を理解するということは、レガシーなコードを読み解く助けになるのかなーという感想を持ちました。
なので、臆さずまずは、コードに書いてJigで見るということ、そこから言葉を置き換えるリファクタリングをする、パッケージにまとめるという工程を通すことが、第一歩なのかなと思います。
ユースケースをテストに書く
掘り起こしたユースケースをテストクラスに書きます。
ここまでJavaにモデルを書き起こしてきたメリットだなーと思ったのが、テストにユースケースを書いてモデルが正しいか確認できるというあたりです。
PlantUMLなどで、モデルを書き起こしてきたとすると、書いたモデルが正しいのか検証するのに、オブジェクトモデルを書いて検証するとか、シーケンス図を書いて検証するとか、図に図を当てていくしかないかなーと。
実際に動くコードとして、モデルを検証できるあたりが、すごいフィードバックだなと思いました。
ユースケースを満たすモデルにする
ユースケースをテストに書いて実行すると、ここまでで作成したクラスに操作がありませんので、操作を実装していくことになります。
操作を実装していくと、今まで概念として表現できていなかったクラスを書く必要に迫られたりします。
ここで、さらにモデルを見つけていくことになります。
まとめ
以上の取り組みを通して最後に出来た図が以下のようになります。

記事を書くにあたり、直近で取り組んでいたことを書き出していきましたので、まだ私自身整理できていない内容です。
実プロジェクトでの取り組みに進捗がでてくると、さらに整理できると思いますので、まとめる機会を別に持てればと思います。
また、今回の取り組みでとにかくすげぇってなりましたのは、 dddjava/jig: Java Instant-document Gazer を活用すると、レガシーコードをクラスに構造化した後の理解やフィードバックがすごくはかどりました。
モデルを整理すること、また、整理したモデルをそのままユースケースにあててテストできるというあたりは、今のところ最強じゃないかと思っています。
以上です。